# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
对于美国的年轻人而言,networking 是一个很重要的工作。无论是获得职业指导、内推机会,还是建立自己的行业人脉,networking 都是必不可少的工作。
在欧美职场文化里,「Networking」不是单纯指「社交」或「人脉」——它更像是一种主动、策略性的关系构建,这些关系会成为每一个职场人未来的「资产」。
但是当下,以 LinkedIn 为代表的职业社交平台,却并不能真正高效地促成这种双向连接。在 Articuler.ai 创始人申哲先看来,LinkedIn 更像是上一个时代的电话黄页,只解决了「展示」,没有解决「匹配」。
申哲先想改变职业社交中人与人建立连接的方式。他想做一个 AI 驱动的 、像 Tinder 一样的 LinkedIn,让 AI 帮助用户更高效地去连接、被发现,进而构建一个承载双向关系的职业社交平台。
在职业社交的互联网化过程中,过去哪些信息完成了互联网化?哪些还没有?
职业社交中,找到对的人并建立联系,其中涉及哪些步骤?AI 能提升哪些环节的效率?
LinkedIn 和公开互联网上沉淀了大量用户的职业数据,这些数据在今天有怎样的价值?
以下是我们与申哲先的对话,经 Founder Park 编辑整理。
在我们访谈后不久,LinkedIn 发布了 AI 找人功能,Articuler.ai 团队测试了产品效果的对比。
Founder Park:介绍一下 Articuler.ai 在做什么?
申哲先:我们现在做的项目叫 Articuler.ai,现在的形态是一款职场社交的 AI 产品。
Articuler 的意思是把零碎的事物用逻辑组织起来。我们希望组织散布在互联网各个角落的信息,构建每个人的职业社交profile,帮助大家去连接、被发现,认识到本就应该相遇的人。我们希望能做到:
第一,在不同目的下,帮用户连接到正确的人;
第二,在交流过程中,不用再猜,见面之前就能了解对方的偏好和观点,实现更高效的撮合。
Founder Park:听起来像「约会」类产品。
申哲先:Dating 领域我们做了很多研究,团队也有人之前做过这个领域的产品。一开始的确思考过,到底约会软件还有没有机会?
但实际上,用户的约会习惯,尤其北美市场,这几年已经发生了很大的变化。Match Group(旗下 Tinder、Hinge 等),这几年股价掉了 70%,因为疫情之后,年轻人已经不想玩线上 dating 了。反而 Ins、Snapchat 这类社交媒体,承接了不少 dating 的需求,ins 就是年轻人的 profile,这些社交媒体上的个人信息,更加真实更加全面,不像 Tinder 上面那么刻意。另外,陌生人 dating 还是不如有一些间接关系的 dating。
Fun fact,LinkedIn 也承接了一部分约会需求,因为上面有真实的教育和工作背景,有共同好友,也有真实照片和帖子。
Founder Park:「查户口」的步骤省了。
申哲先:荷尔蒙驱动的约会,已经没有太大的增量市场了。它不是一个真正的双向匹配,更像「选美」,最受欢迎的人会吸引到所有的注意力,大部分中腰部的用户匹配不上,这个场景的根本问题很难解决。
但在大模型出来之后,它能对一个很复杂的用户背景进行解析,理解用户的偏好和背景。这种能力,用在主观且荷尔蒙驱动的约会场景上其实不太适用——但它非常适合做目的性明确的匹配,比如严肃的婚恋,因为它看的指标更客观,不是一些像长相这样比较主观的东西。
如何能利用 AI,让人与人之间在职业社交中实现更高效的匹配?这才是我们真正想用技术去解决的事情。我们在做一个像 Tinder 一样的 LinkedIn,帮助用户去连接到他本来就应该认识的人。
过去平台理解一个人,是把他压缩成一组标签,这个过程损失了太多信息模态。
我们是把一个人的所有资料,包括简历、观点、项目经历等等,在做完 embedding 之后,完整地变成一个高维度的向量数据。我们做的匹配,是基于语义理解的、向量和向量之间的匹配,这样能更准、更高效。
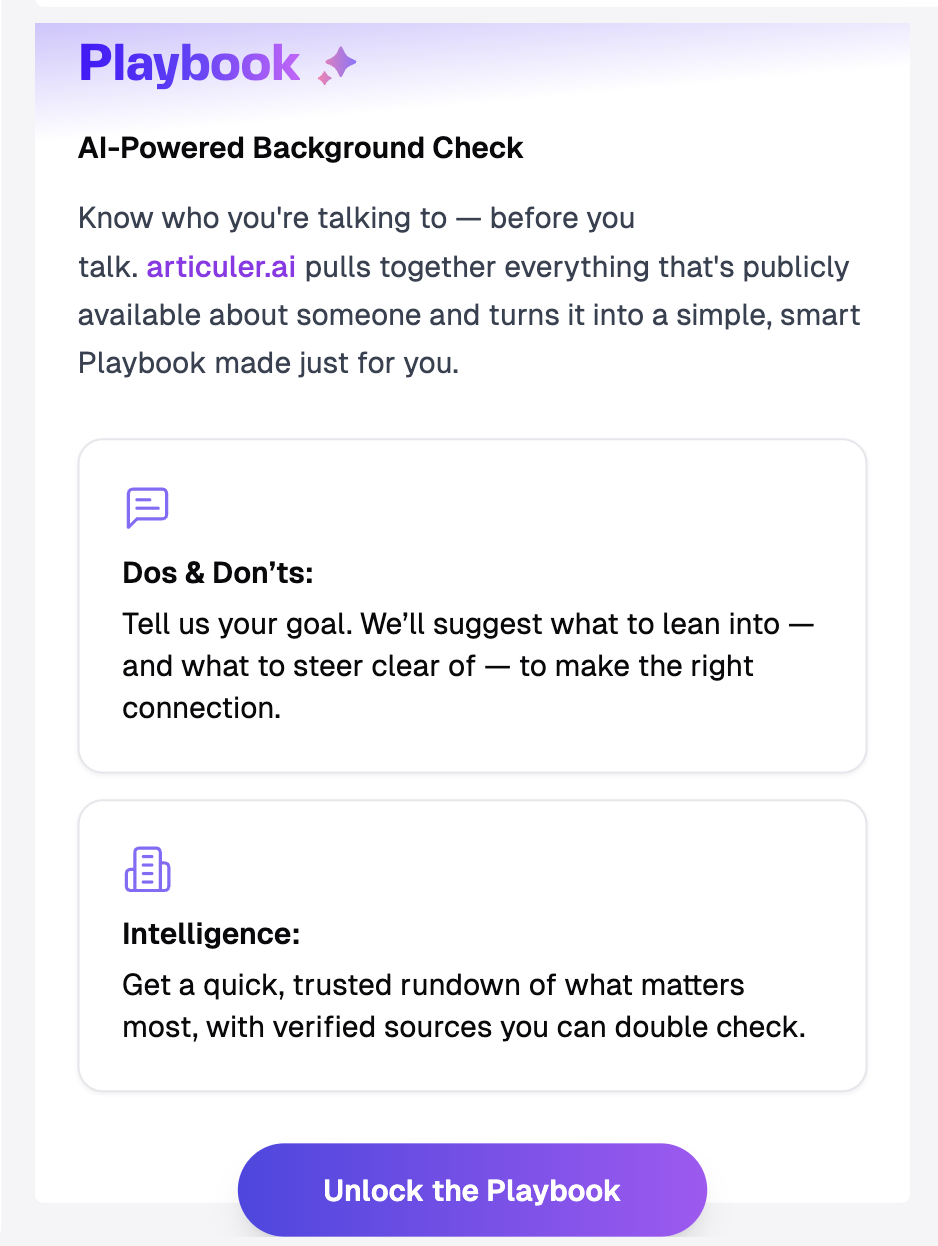
articuler.ai的Playbook功能入口
Founder Park:这个创业想法是什么时候开始的?
申哲先:最开始是 GPT-4o 实时语音互动的发布。当时 OpenAI 那场发布会,AI 对人的语气、对交流背后的 context 都有很好的理解,能够很丝滑地参与到人的对话中。
这对我的启发是,AI 能够参与到社交中,它会不会能够去解构人与人之间的交流和关系?
另一个产品,Plaud,在这方面也对我们有所启发。我个人非常喜欢 Plaud,它的切入点很妙,用硬件的「超级按钮」取代了原本手机里三四次操作才能做到的功能,掌握了线下信息的入口。我经常基于 Plaud 的记录来分析我开会/见客户时的表现,比如我们跟投资人聊完,哪里聊得好,哪里不够好,AI 都能分析出来。
当时我们并没有特别考虑硬件的方向,反而想到了一个比较好的高频打低频的点:发 Cold Email。
(Cold Email:破冰信,指跟对方关系并不熟,但试图得到对方帮助或让对方留下印象的 email,是职业社交里非常常见的手段。常见的 cold email,包括客户或投资人的邮件、初次联络客户的介绍信,以及求职自荐信等。)
现在在 LinkedIn 上,每个月花 30 美金订阅费,只能发 5 封 InMail(站内信)。cold email 如何写,是个挺有趣的课题。
去年我做用户访谈,一个做医疗器械销售的朋友给了我一个特别反直觉的观点,他写一封 cold email 平均要半小时。我问为什么这么久,他说:「在医疗器械的销售圈子里,大家其实都会有千丝万缕的关系,你得找到这些关系。」比如你们是不是同一个导师,有没有在同一个期刊发过论文。ChatGPT 可以帮你写一封语言优美的邮件,但它找不到这些点。
在实际场景里,你写得内容比你的语言要重要得多得多。于是我们做了一个小插件,用户在 LinkedIn 上点一下对方,我们就能结合双方的背景,帮他写一封高效的 cold email。这个产品跑得相当不错,今年上半年月度环比增长达到了 110%。
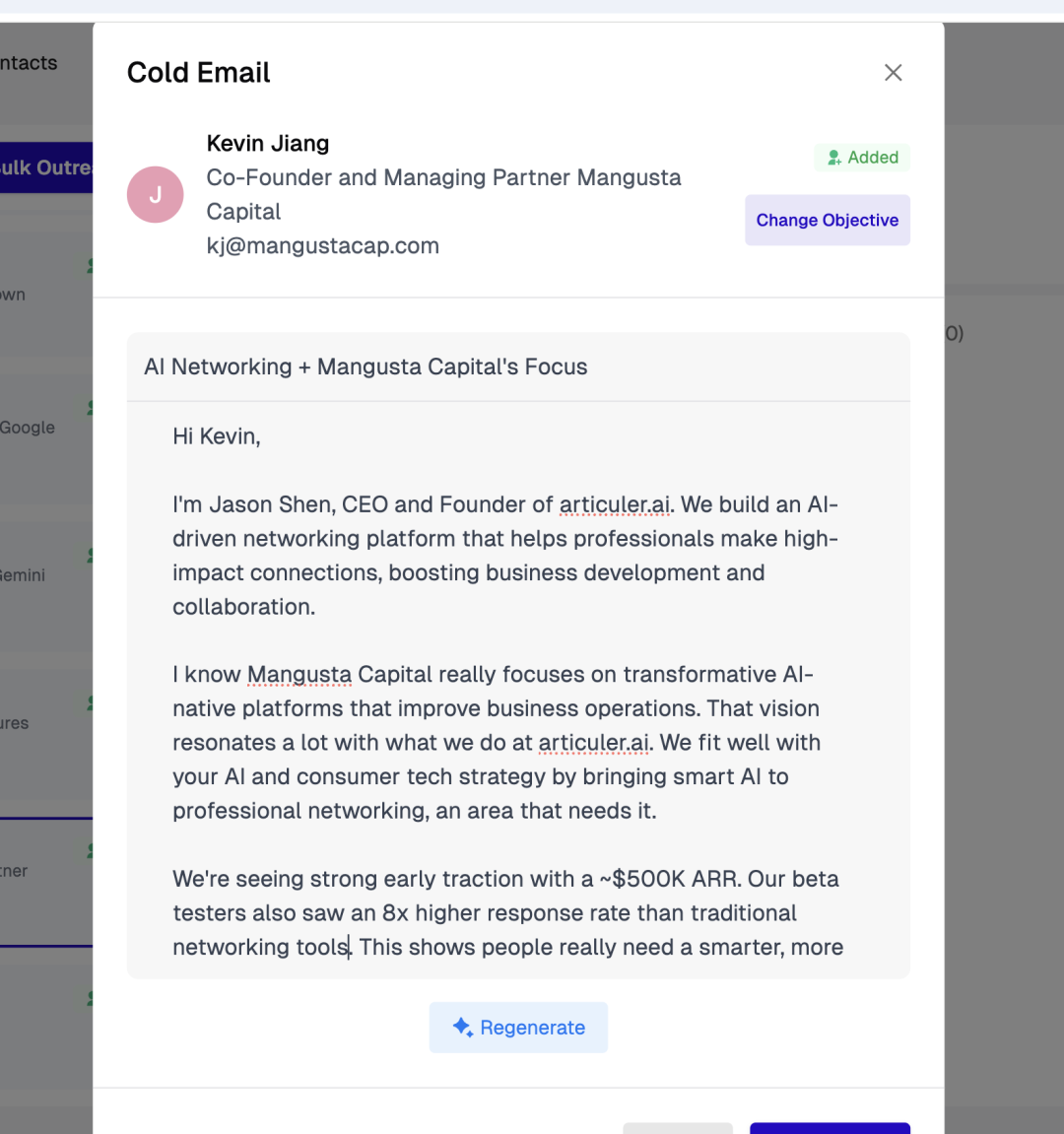
articuler.ai为申哲先生成给投资人的cold email
Founder Park:发 cold email 的时候,这个人已经「匹配」到了。
申哲先:对,到了今年的 3 月份,我们又去做了第二次的用户访谈。
我没有直接问问题,而是让用户投屏给我看,当他们不用我们的软件时,是怎么在 LinkedIn 上做 networking 或者跟人建立连接。当时我们很惊讶地发现,其实写 cold email 不是第一步,是很靠后的步骤。他们在整个流程里面 60% 到 70% 的时间是用来找人的。
比如说,假设我是一个 founder,我想找个投资人。在 LinkedIn 上搜「VC」,会出来一大堆人,但你根本不知道他们投不投你的领域和阶段。用户需要一个一个点开看,甚至要跳出去用 Google 搜索,查找对方机构的投资阶段、投资方向等等。所以我们当时在想,其实发 cold email 和找到对的人是同一件事。「如果你没有找到对的人,你这个 cold email 写得再好,对方都不可能给你回复。」
所以从今年 4 月底开始,我们做了现在的版本。我们希望能把全世界的人都变成一个高维度的向量数据,做到知己知彼。换句话说,全天下的白领我都认识了,你只需要告诉我你是谁、想干嘛,我们能帮你找到最匹配、最相关的这个人。
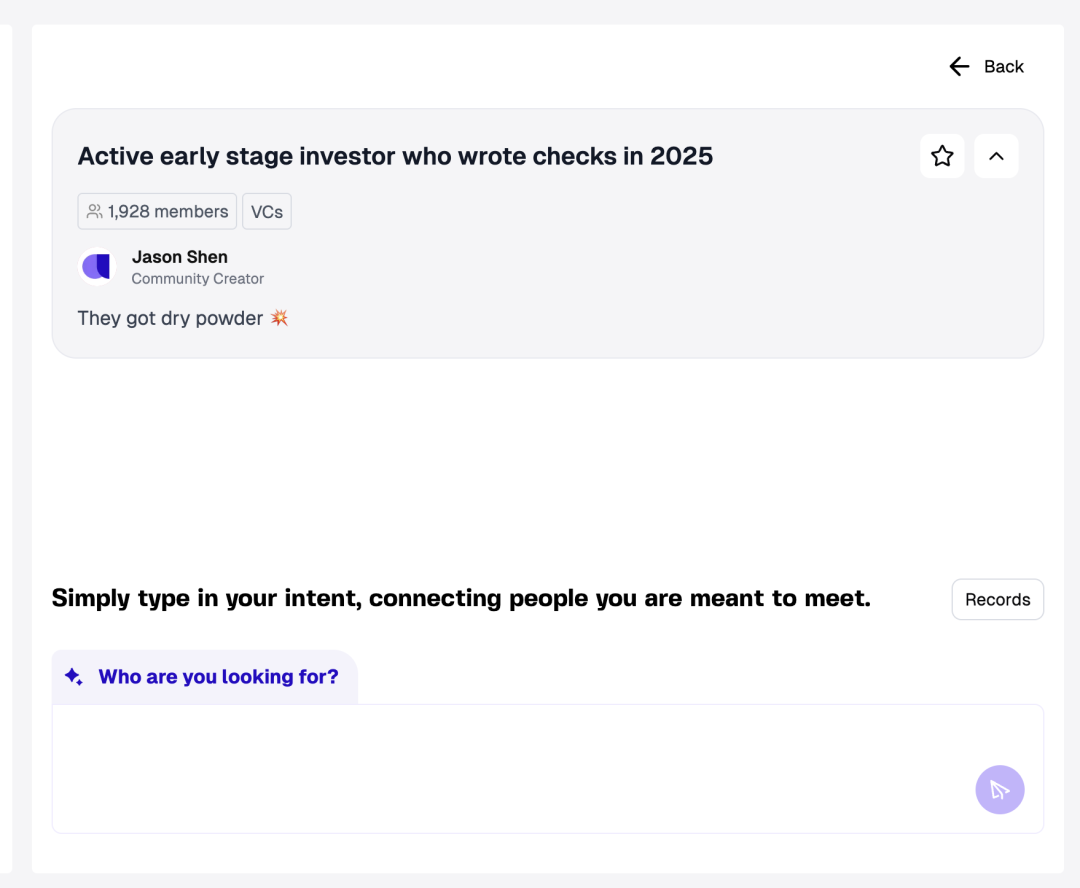
articuler.ai的社群搜索入口
Founder Park:职业社交这些年发生了什么样的变化?过去的模式是怎样的?
申哲先:我去年和一个快 50 岁的老前辈聊天,他是上世纪 90 年代就在华尔街做投行。那时候没有互联网,更没有 LinkedIn。想进去投行,就得靠 networking。他当时在华尔街街头站了两个礼拜,在每个投行的楼下堵着人聊,做 coffee chat。
在前互联网时代,职业社交就是以线下为主。比如,投行在美国都有所谓的「目标学校」,校友之间有一个强纽带,在面试之前,他们通过一些线下聚会和关系网络就已经相互认识了。这种是「强关系」,人与人之间的关系质量比较高。通过地理和活动的筛选,筛掉了很多人。
但存在两个问题:一是地理限制严重,二是信息也严重不对称。你不知道对方是谁,看不到对方的简历,只能通过在活动上半个小时的交流去相互了解。
之后进入互联网时代,就是 LinkedIn 的时代。它在早期只干了一件事情:把每个人的简历搬到网上。
简历其实是一种社交货币,是个人品牌的呈现。在 LinkedIn 上,我们可以看到你的第二度和第三度的人脉关系,它通过这个能打破地理和已有社交圈的限制,帮你找到更多和你相关的人。LinkedIn 就像是一个超级电话本或黄页,你可以通过关键词找到任何人。
Founder Park:但 LinkedIn 似乎并没有完全满足用户的需求,它存在什么问题?
申哲先:LinkedIn 最大的问题是,只解决了「展示」,没有解决「匹配」。
LinkedIn 现在的收入大头来自 B 端,比如卖销售线索的 Sales Navigator 和卖人头的 LinkedIn Recruiter。它并不在意你想不想看对方给你发一条消息,它只是把你去当做一个这个整个人头去卖出去。
所以在「知己知彼」这件事情里,LinkedIn 只做了一半,这也导致很多人打开 LinkedIn 之后,能看到很多广告邮件、骚扰邮件,浪费时间,浪费注意力。这些垃圾信息的双方,产生不了价值交换。你并不想要对方 offer 的服务、产品、岗位,但系统并不知道这件事。
用户想要的可能是找到最合适的 10 个人,但 LinkedIn 通过把一个人强行压缩成一组标签,给你推出 1000 个满足最低要求的人,你需要做大量的筛选工作。而且,在 LinkedIn 的职业社交中,我们都是被动地等待被连接,如果别人不知道搜索我的关键词,就永远找不到我。
所以在这样的情况,我觉得 LinkedIn 更像是上一个时代的产物,像一个电话黄页。但我们想做的是一个 Tinder 版的 LinkedIn,不仅能让用户展示自己的品牌,并且能帮助用户去连接、被发现。
Founder Park:你们在做的匹配和 LinkedIn 的「匹配」有什么本质区别?
申哲先:能让我们产品变得更好的,肯定不是公开数据。你只用公开数据,讲得粗俗一点,「其实就是在别人的数据库上做了个交互层」。 了解用户隐性的偏好,才是我们的「壁垒」。用户在我们平台上的每一步交互,推荐人、建立连接、见面的准备、见面后的管理,我们能接收到用户真实交互的反馈信号。通过这个信号,在我们下次做匹配时,就知道用户的偏好性到底是什么样的。
比如,我想找投资人,系统给我推了 15 个,但我最终只联系了其中 4 个。为什么我选了这 4 个,没选另外 11 个?这背后反映了我很多隐性的偏好,这些甚至是用户自己都说不清楚的。
这些交互数据会沉淀下来,让我们的平台,越用越好用,推荐越来越准。而且这个数据是别人拿不到的。你可以把我们理解成一个关于白领的「大众点评」,你每一次交互的反馈,都会成为你的一个社交标签。

articuler.ai的联系人状态管理
Founder Park:听起来和推荐系统有点像,和传统推荐系统的区别是什么?
申哲先:我们用户的背景信息更丰富。传统的推荐,比如淘宝,它一开始其实不知道你是谁,需要你产生上百次购物行为后,才能大概猜出你的偏好。但我们不一样,用户一进来,我们就能知道 ta 的背景是什么,通过我们的大盘数据,能推测出这类背景的用户通常有哪些共通的喜好,所以我们的冷启动阶段给用户的推荐质量很好,用户很满意。
其次是,我们在中间加了一层大模型,我们把用户在产品上的交互作为强化信号,比如 ta 选择了和谁联系,拒绝了和谁联系,都通过 embedding 模型,加入到了用户自己的向量化的 profile 中。
Founder Park:在美国职场文化中,networking 是一个很普遍的需求吗?
申哲先:我本科的教授给我讲过一句话,让我特别难忘。他说:「Your network is your net worth.」
在美国,networking 是一个非常常见的文化。比如我爸爸朋友的女儿,刚上大一,因为没有提前联系社团的学长学姐做 coffee chat,结果开学后想加的社团名额都满了。
所以你会发现,networking 这件事情,本身就是人与人之间去充分了解信息、建立联系的方式。在美国的传统职场文化里面,这已经是一个很重要的文化组成部分了。
从数据上看,美国社招中超过 85% 以上的工作在每个公司的官网都没放出来,是通过人与人之间的推荐来拿到工作机会。我们今年上半年在美国这边做了一些研究,访谈样本有 200 多个人,主要是大厂员工和一些做专业服务(professional service)的白领,里面超过 95% 的人都做过 networking 这件事情。
LinkedIn 今年第一季度的 C 端订阅收入已经突破 20 亿美金了,年增速达到 50%。在一个渗透率 95% 的产品上还能有这样的增长,是一件很恐怖的事情,说明这个需求非常强劲。用户每月花 30 美金,核心就是为了能看到更多人的资料和发送更多站内信,都是为了 networking。它的主要用户是 18-35 岁的年轻人,占比 75%,因为年轻人在一段工作中的平均在职时间越来越短,他们需要建立自己的职业社交形象,连接到关键的人和机会,同时能被别人发现。
Founder Park:在职业社交的线上化进程中,已经做好的是什么?还没做好的是什么?
申哲先:第一步被互联网化的,其实是每个人的身份信息。互联网就是一张巨大的网,把人都连到一块了。你可以在这个网上去找到所有的人。第二步出来,其实是在这个网上去加入更多模态的信息。
比如说,这个人发了帖子,这个人发了一些照片等等,它会让一个人更加丰富起来。那站在 2025 年看这个事情,我们经过互联网这么几十年的发展之后,你会发现每个人的社交身份是散布在各个平台或者互联网的各个角落里的。
那我们现在的问题是,如何把这些散布在各个角落里面的身份信息充分利用,同时整合成一个更好用的新产品?我们认为,现在这个时代,用户需要的不是「我要看见」,而是「我要一个结果」。我要的东西就是要跟一个关键的人产生连接、建立连接、发生关系。但是我们现在都只能看到他的帖子,只能去关注他,他不知道我是谁,也不知道跟我这个人之间有哪些关系的互动。
但不可否认,LinkedIn 是一个很值得尊敬的产品,因为但凡能起网络效应的产品都有着最强的「壁垒」,没有之一。LinkedIn 现在有这个网络效应,所有人都加入这个网络了,你不加就享受不到。那我们能干的是什么?我们希望在我们的平台上去建立起小的「原子网络」。
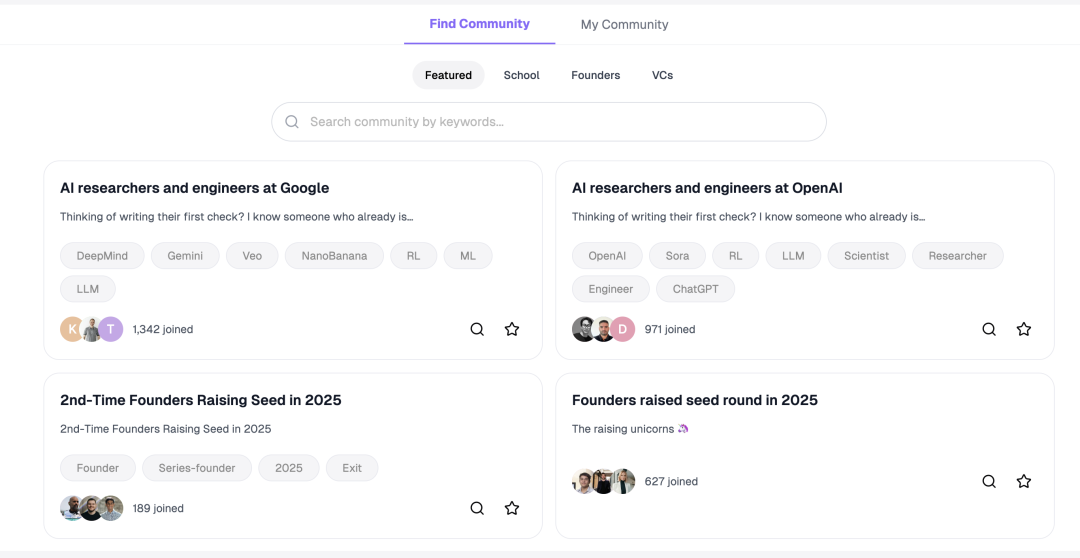
articuler.ai的社群首页
Founder Park:最开始做了一个基于 LinkedIn 的写作 cold email 的插件,当时是怎么想的?
申哲先:我们一开始的野心更大,想成为每个人的「超级通讯录」或者「个人 CRM」。不管是 Notta 还是 Plaud,它们都是以「一场会议」为最小单元。但我们认为,你所有的会议、通话,最终都是和「人」有关系的。所以我们想做一个更上一层的东西,能沉淀所有交互,帮用户维护关系网络。
但这条路,我们在今年 3 月份的时候发现走歪了,有点往 CRM 偏得太多。我们研究了美国市场后发现,这个方向最终只能做 ToB,因为愿意为个人关系管理付费的 ToC 用户太少了。而且中国团队,在美国做 ToB 销售没有优势。
我们当时选择做 LinkedIn 的插件,因为它是一个无法绕开的生态,在北美的白领中,LinkedIn 的渗透率高达 95%。在这样的基础上,完全没有必要再去搞一个新的个人资料平台。
Founder Park:这个插件和你现在的产品是什么关系?
申哲先:原来那个插件现在已经成了产品的二级功能。我们后来想明白了,在职业社交中,「匹配」才是价值最高的点,它应该是一切交互的入口。数据也证明了这一点,我们加上「找人」和推荐功能后,cold email 的回复率从 6% 提升到了 12%-15%。
Founder Park:直接翻了一倍,怎么做到的?
申哲先:最关键的一点是:我们帮你找的人,是对的人。在内容生成上,我们用了一套比较复杂的 Agent 框架。我们会输入用户和对方的背景信息,包括公开的 profile、search agent 从全网找到的相关信息,以及针对融资、销售、求职等不同场景的 know-how。这里包括针对不同场景判断共同点的逻辑,以及长度限制。比如针对销售场景,邮件内容就不能太长,150 字以内能让对方感兴趣。
一个 Agent 负责生成草稿,然后第二个「审查员」Agent,会参考行业里的 best practice 来给草稿打分。最后,还有第三个 Agent 会根据评分结果,再重写一遍,保证最终产出的邮件质量。
Founder Park:「找人」这个动作,怎么通向一个更完善的产品?
申哲先:「找人」只是我们冷启动的方法,背后真正的逻辑是「匹配」。因为职业社交的本质是一个双向关系,一个是主动地以某个目的为索引去找人;另一个是被动地等着被别人连接。
所以,如果要做下一代的职业社交平台,它必须有两层。

articuler.ai为申哲先推荐的投资人列表
Founder Park:不只想做一个找人工具,而是想沉淀人与人之间真实的交互数据。
申哲先:对。如果只是一个找人工具,它就停留在建立连接上。但我们希望能做一个平台,用户可以主动连接别人,也能被别人发现。人与人之间交互的上下文也能在我们的平台上沉淀下来。
天底下有新技术、有新产品,但天底下几乎没有新生意。我们做的不是一个新生意,而是一个撮合平台,底层是一个双边网络。我们的任务就是让供需双方的匹配更高效、更高质量。
我们把整个流程拆分成四个阶段,每一个环节 AI 都能交付价值:
Founder Park:刚才提到要把白领变成一个高维度的向量数据,怎么理解?
申哲先:我们最重要的任务是把一个人的信息和背景做最全面的还原。
现在每个人的职业身份信息散布在互联网的各个角落,只看 LinkedIn 是不够的。我们的数据源分为两部分,一是像 LinkedIn、Twitter、GitHub、Google Scholar 这样的 public profile;二是我们做了一个 Search Agent,能抓取全网和这个人相关的动态,比如他发的帖子、所在公司的新闻、行业趋势等等。
在数据源的选择方面,我们更看重有效信息的密度,会选择一些职场属性比较强的平台。
拿到这些信息后,我们用 embedding 模型把它变成一个高维度的向量,存在我们的向量数据库里。当用户告诉我们他想找什么样的人时,他的需求也会被转化成一个向量化的查询(query),我们再去数据库里做基于语义理解的匹配。
Founder Park:用户散落在互联网上的数据,你们是怎么获得的?
申哲先:比想象的要简单。美国没有像微信那样封闭的生态,信息都是公开的。很多美国销售都在用的一个方法是:见客户前,把对方的「名字 + 公司名」扔到 Google 里搜一下,能发现很多有意思的东西。这些能在公开互联网上找到的痕迹,就是我们还原一个人的拼图。
举个例子,我们最近在帮一个做无人叉车的中国公司找美国客户。我们推给他的人,不仅仅是 title 符合,还能告诉他,根据新闻,这个人的公司最近刚买了一套仓储自动化系统。说明他们对仓库自动化已经有了很好的认知基础,你现在去找他,就是事半功倍。如果我们只拿 LinkedIn 上他相关的 profile 信息,是解析不到这一层的。

articuler.ai推荐的无人叉车客户(机器翻译)
Founder Park:LinkedIn 几百万的付费用户,是你想切入的目标人群吗?
申哲先:是的。我们主要是在这群人里再细分出两类画像。但我想先说一点,我们做获客,不仅在意用户增长,更在意的是用户密度。因为我们不是一个单向的找人工具,是要促成双向连接,平台上的用户彼此之间就能直接匹配。
基于这个观点,我们现在只做两群人:
第一,是年轻白领,包括在校大学生和刚工作 1-5 年的人。他们想换工作、找导师,或者寻求职业发展,我们能帮他们撮合。
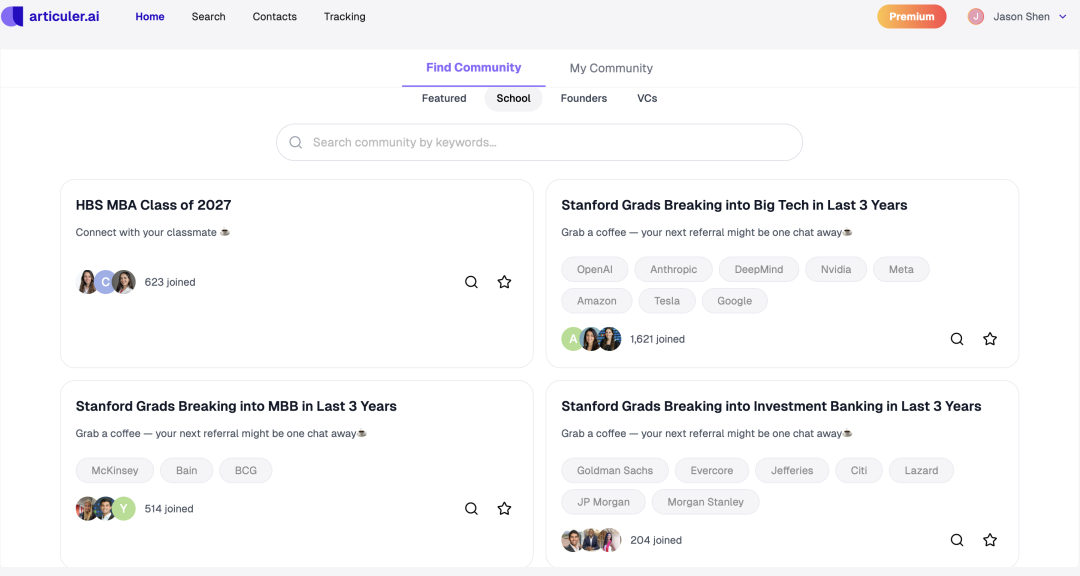
年轻白领与在校大学生看到的社群首页
第二,是整个北美的创投圈。这里有个很有趣的点:北美创投圈是没有财务顾问(FA)的。所以创始人能聊到哪个投资人,完全看他自己能联系到谁。我们做的是直接帮助这个圈子的供需两侧,做更好的匹配。
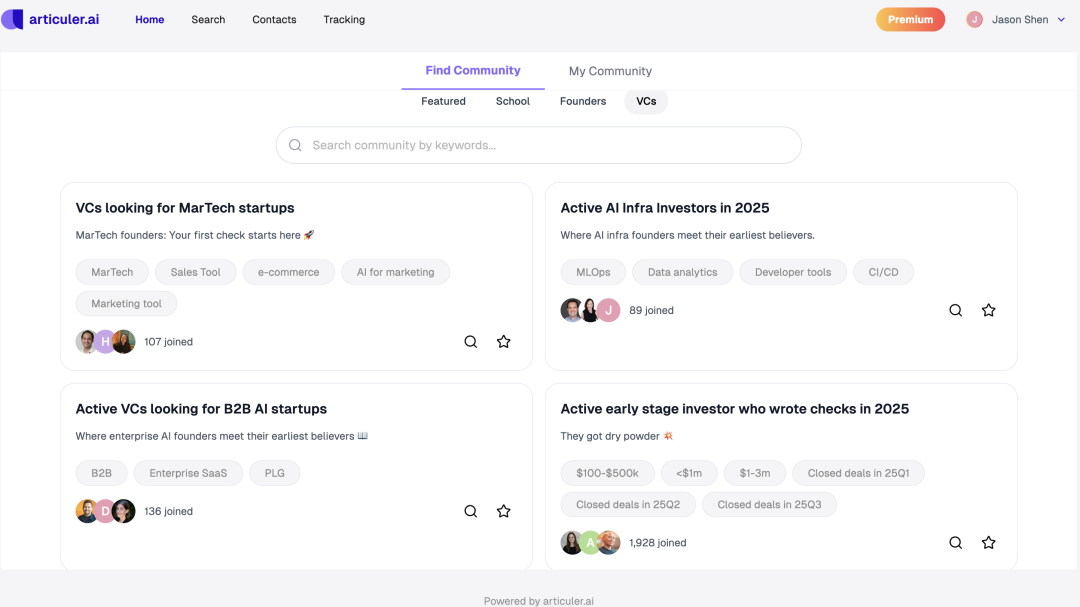
北美创投圈用户看到的社群首页
Founder Park:LinkedIn 现在也是一个社交媒体平台,用户在上面消费别人发的东西。你们会像 LinkedIn 一样鼓励大家发 Post,用内容来辅助社交吗?
申哲先:Post现在不在我们的 roadmap 上。LinkedIn 做 Post,是因为它是一个展示个人职业「品牌」的平台,你发的内容是你品牌的一部分。但我们想做的是两个人真实的链接。
要不要做 post,就像 Sora 出来了,有必要专门去做一个 for AI-generated video 的抖音吗?我干嘛不在抖音上发呢?
我们现在更想做的是一个「聚合器」。你但凡在任何平台发了和你职业相关的内容,我们把这个信号捕捉到,它就会成为你个人资料(profile)里的一个偏好性信号。我们通过这些信号,帮你匹配到更多你本该认识的人,去交付一个「连接」的结果,而不是再造一个内容消费的平台。
Founder Park:你之前提到,最后要做的是社区?
申哲先:对,双向连接,一定会通向社区。现在从工具切入,是因为找人这个环节效率最低,目标是建立一个个小的「原子网络」。
比如一个 MBA 项目的 700 多个学生,他们彼此之间有强烈的 networking 需求。我们可以把这些人组成一个社群,在里面做精准匹配。一个线下活动、一个校友组织,都可以成为一个原子网络。当这样的小社群越来越多,我们就可以把它们打散再重组,最终形成一个大的、流动的「社交网络」。
我们甚至不需要这些人都注册我们的平台。因为他们的公开信息都在网上,我们可以主动给他们创建社群,比如「过去三年加入 Meta 的 CMU 校友」,然后用这个社群作为内容去吸引真正有需求的用户。
我们最近就在用这种方式做营销邮件做了效率验证,比如告诉创始人「我们平台有 72 个投资人上周刚投过你这个方向」,或者告诉投资人「昨天有 63 个创始人在找像你这样的投资人」,他们就来了,转化率很高。
因为人其实只对与自己强相关的东西才感兴趣。我们知道他的职业背景和 intention,我们是可以直接找到他感兴趣的内容,我们先给他创造出来,然后给到他。
Founder Park:介绍下你过往的经历,创业前在做什么?
申哲先:本科在南加州大学(USC)读数学。读书时就在创业,当时做了一个量化模型,出发点是想把美国升学这套很玄幻的东西变得「可解释」,可以根据用户的背景给出对应的升学建议,在哪个专业、哪个学校有更高的录取率。
这个项目赚了钱,但它没法规模化,需要靠人力交付。我当时最大的感触是:这是一个现金流特别好的生意,但不是事业,因为它没有办法 scale up。如果 21 岁能做这事,31 岁、41 岁也能干,那我现在就不应该干这个。
当时还是想创业,但没见过好东西,肯定就做不出来好东西。所以我想去全世界最厉害的公司看看,我当时给自己的答案是做管理咨询。我大三去了麦肯锡实习,帮顶尖的互联网企业做战略,但我发现管理咨询太不落地,只出一个报告,浮于表面。
毕业以后,我去做了投资,先后在两家机构,从一家早期机构到一家覆盖更全面的机构,也赶上了 GenAI 的这波浪潮,看了很多基模、infra 和应用层公司。
投资人的工作本身就是跟人打交道。不光是我的老板、同事,还有我投过的一些成长期创始人,大家每天都在干一件事:跟人建立关系。不管是找下轮投资人、找客户、招聘、找合作伙伴,无一例外都特别耗时间。在看项目的时候我就一直在想,AI 怎么能让我们的工作更简单?怎么给两个人做一个更高效的撮合?于是慢慢有了创业的想法。
Founder Park:回过头来看,当初做投资有什么可以做得更好的?
申哲先:现在回头看,我觉得在美国,很少有年轻人能做好早期投资人,是有道理的。因为做早期需要经验,你再名校毕业,再聪明,你没经验、没创过业,你没有看过整个公司从成立一步一步走到上市,或者走到退出,或者是走向死亡的全过程,判断不了。你看到的永远是别人想让你看到的最好的东西。
我觉得做投资本质就是一个消除噪音、发现价值的过程,如果连事情的本质都不知道,很难做。
Founder Park:创业以来,最重要的 learning 是什么?
申哲先:凡事都要有敬畏之心。创业之后我发现,一个公司能成功是因为各种各样“不起眼”的事情堆积起来,而每件小事都有学问在。这一年来最大的领悟就是要把自己的过去“清零”,当作一个小学生来快速学习、快速试错、快速迭代。创始人不能有ego,后面需要学习的事情有很多,这是一场自我的修行。
文章来自于“Founder Park”,作者 “Founder Park”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
