# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型技术日新月异,MMLU、GPQA 等学术基准的分数不断被刷新。
然而,当这些「高分模型」进入到金融、法律等利害攸关 (high-stakes) 的专业领域时,它们真的能胜任吗?
现实应用中存在两大难题:
1.学术基准的视角局限:现有学术基准(如MMLU)提供的视角是有限的,更侧重于有标准答案的STEM推理,而忽视了在金融、法律领域中那些开放式、无唯一答案、且具有重大经济后果的真实任务 。
2.现有专业基准的局限:目前行业内的专业基准大多「要么私有、要么规模太小」 ,且往往缺乏可解释、可复现的评估标准。
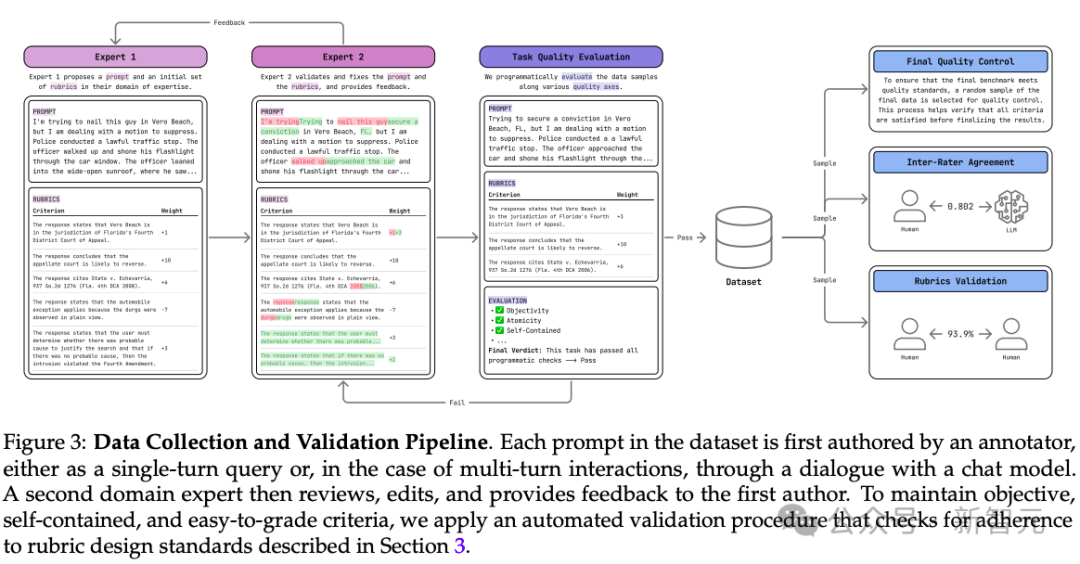
为突破这一瓶颈,Scale AI团队重磅推出了专业推理基准(Professional Reasoning Bench, PRBench) ,一个针对金融和法律领域的现实、开放且有挑战性的基准 。

论文链接:https://scale.com/research/prbench
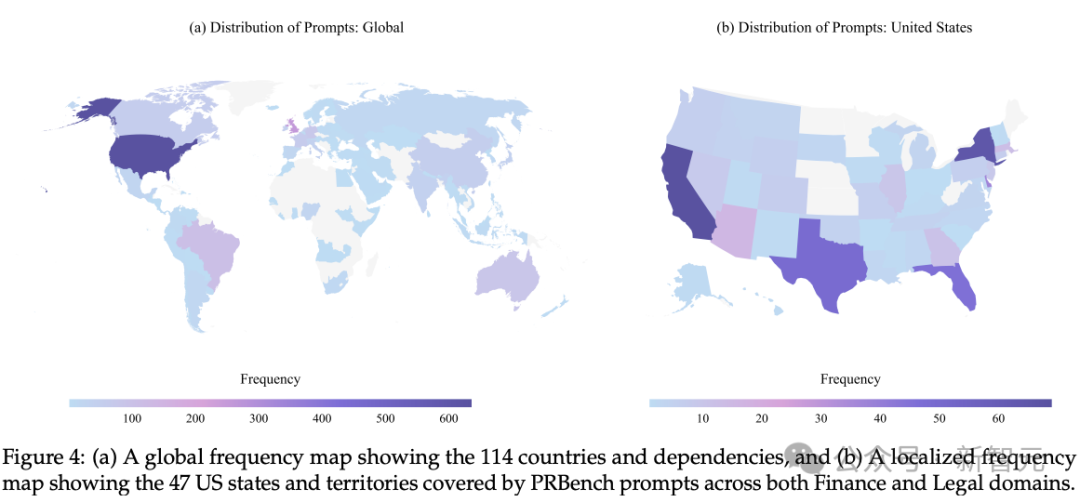
团队招募了182名持有JD、CFA或6年以上经验的合格专业人士 ,围绕他们实际客户工作中的真实需求 ,撰写了1100个专家级任务,任务覆盖范围极广,涵盖全球114个国家和47个美国司法管辖区。
PRBench的核心在于其19,356条专家评估准则 (rubrics) ,使其成为法律和金融领域规模最大的、公开的、基于准则的基准。
那么,顶尖大模型的表现如何?
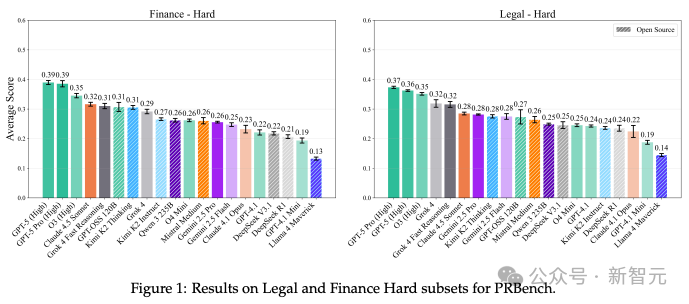
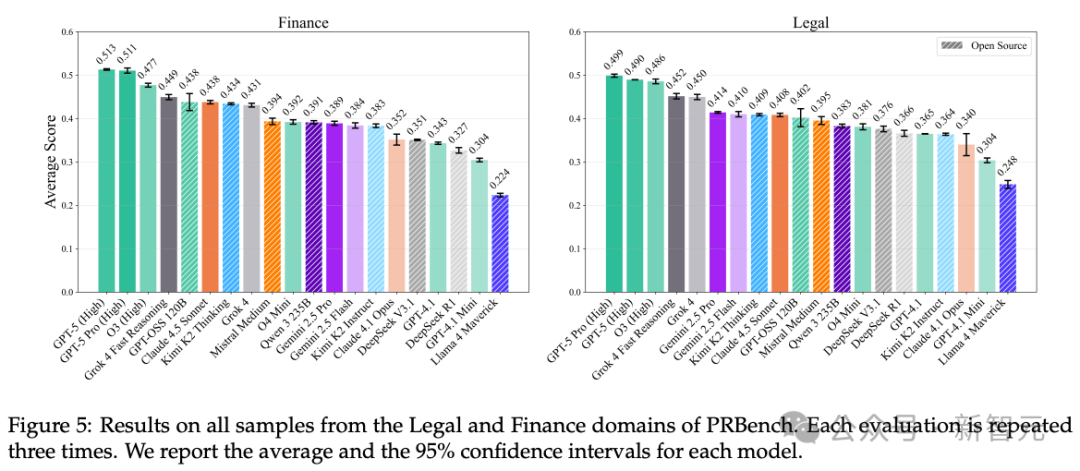
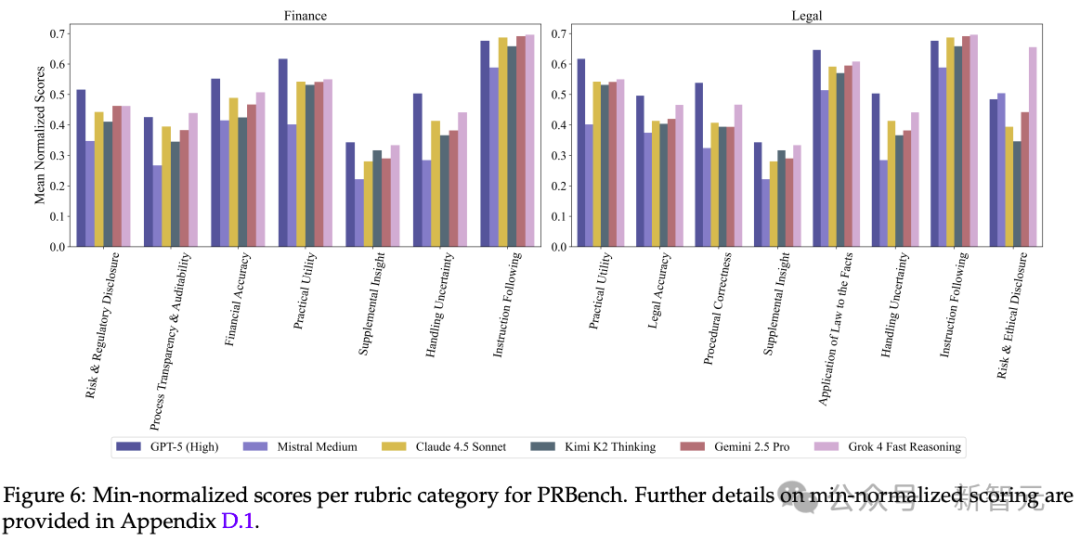
在代表最具挑战性案例的「困难子集」 (Hard subset)上 ,表现最好的模型(GPT-5 Pro/GPT-5)在金融和法律上的得分也仅为0.39和0.37。
这揭示了一个核心差距:尽管AI正被用于辅助「利害攸关」的决策,但模型的常见失败模式,例如 「判断不准确」、「过程缺乏透明度」 和 「推理不完整」 , 使其在处理这些具有重大经济后果的任务时,显得并不可靠。
直指「经济路径」,拷问真实决策力
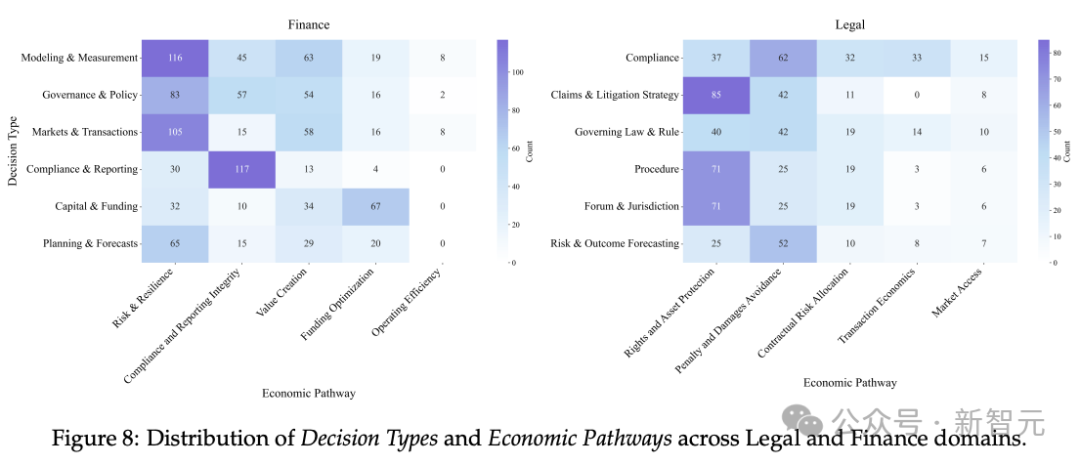
PRBench不再满足于评估「答案是否正确」,而是独创了「经济路径」(Economic Pathway)分析维度,旨在评估模型处理那些「能直接导致真实经济后果」(如降低风险、创造价值)的决策任务的能力 。
例如,在金融领域价值创造 (Value Creation)、风险管理与韧性 (Risk & Resilience)
在法律领域规避处罚与赔偿 (Penalty and Damages Avoidance)、合同风险配置 (Contractual Risk Allocation)
分析发现,这些「经济后果」越重大的任务,模型失败的风险就越高 ,这也正是PRBench所要拷问的核心能力。
模拟真实场景,30%的多轮对话
与许多「一问一答」的基准不同,PRBench中约30%的任务是多轮对话 。
这模拟了专业人士(如律师或金融分析师)的真实工作流:他们不会一步到位,而是通过「迭代式提问」来「逐步建立上下文或做出澄清」 。
例如,在图12的金融任务中 :
这种设计迫使模型不仅要懂知识,还必须能像真实的专家那样,在复杂的多轮对话流中逐步建立并深入理解上下文,进而施展严谨的深度推理能力。
结语
PRBench的发布,为「利害攸关」的专业AI应用提供了一个急需的、透明且可靠的评估框架。
它揭示了一个明确的事实:尽管大模型在通用能力上进步神速 ,但在真正辅助现实世界决策,尤其是金融和法律等专业领域,它们还远未达到可靠的标准。
通过开源这一规模最大的Rubric基准 ,团队希望能推动研究界共同努力,开发出更透明、更可靠、真正具有经济价值的AI系统。
参考资料:
https://scale.com/research/prbench
文章来自于微信公众号 “新智元”,作者 “新智元”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
