# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
继续领跑!
Gemini 3本周一发布,便开启了横扫各大基准测试之旅,频繁登上各种排行榜的榜首。

Gemini 3不仅跑分领先,面对网友的各种刁钻实测也毫不拉胯。
用现实证明了自己就是目前最强模型!
这不,就在昨天,知名研究机构Epoch AI再添一力证——
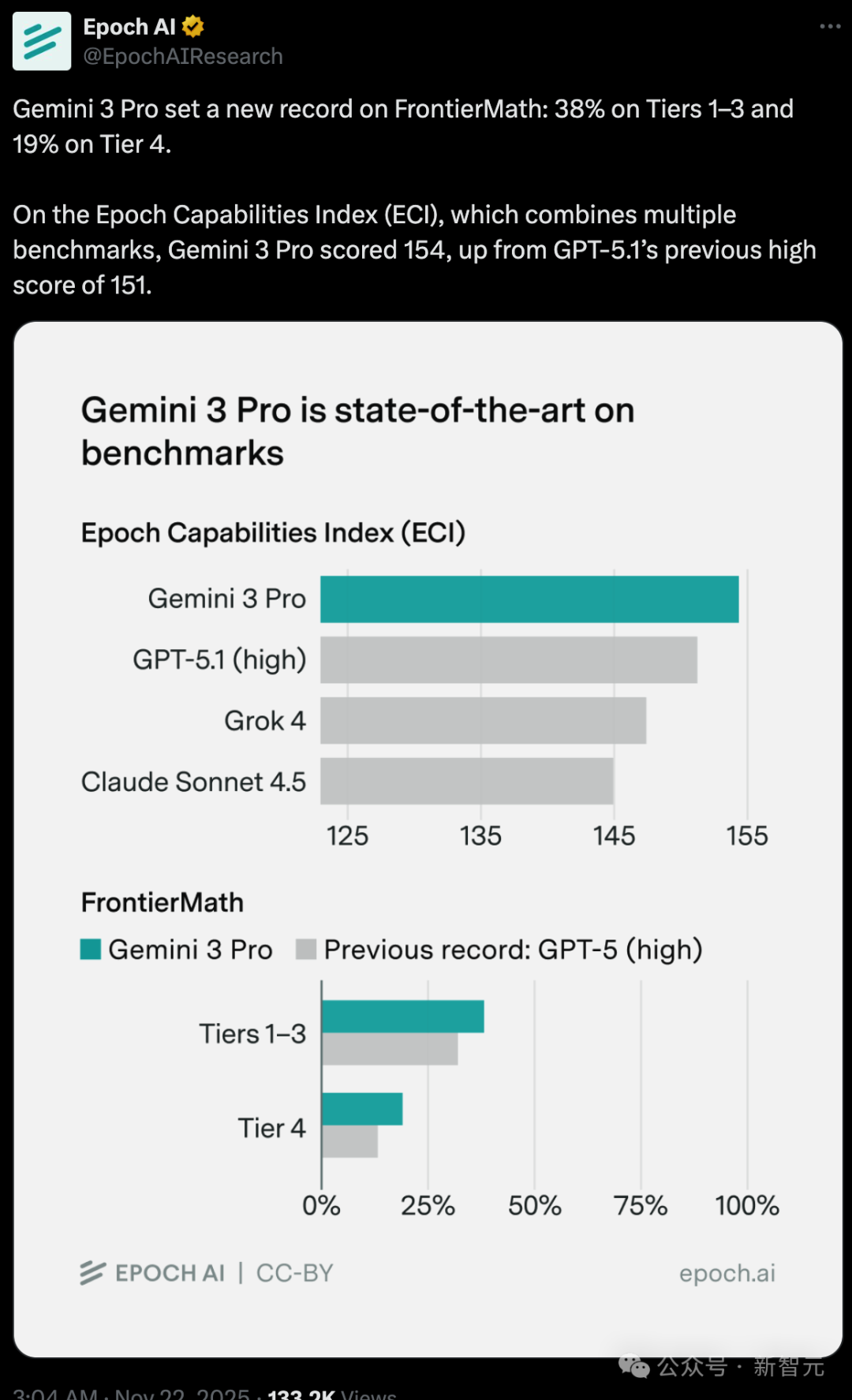
FrontierMath是由Epoch AI联合众多职业数学家打造的一个高级数学基准。
它由数百道原创、从未公开的难题构成,被设计成一块专门测量AI高阶数学推理能力的「试金石」。
这些题目几乎覆盖现代数学的主要分支:从需要大量计算的数论、实分析,到高度抽象的代数几何、范畴论。
普通一道题就足以让相关领域的研究者思考数小时甚至数天。
这些题目大概长这样,大家可以感受一下。

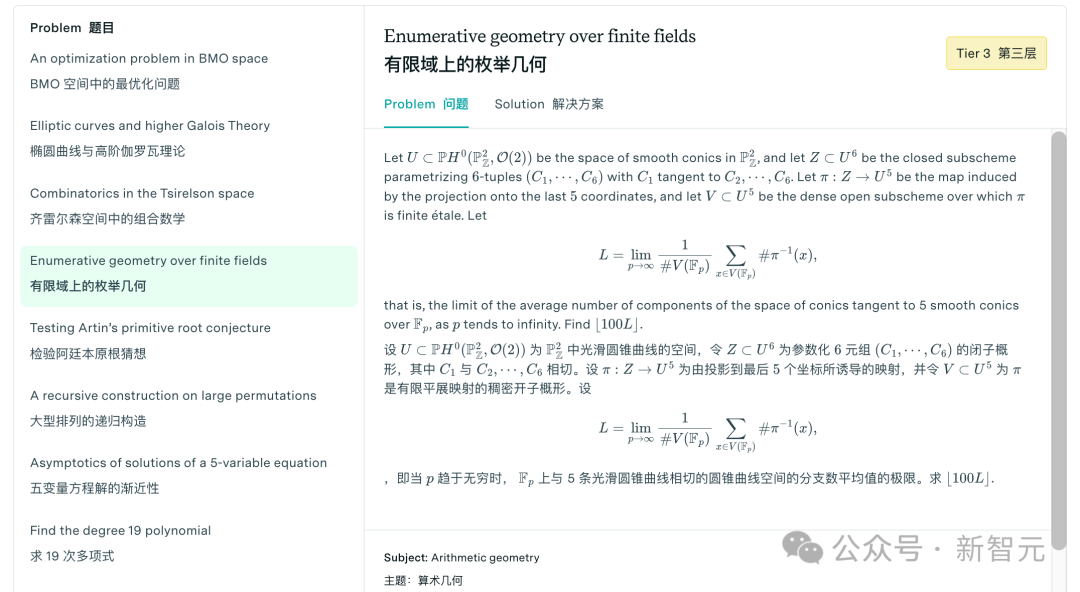
完整数据集包含350道题:其中300题构成Tiers 1–3,难度大致对应从高年级本科到初级研究生水平。
另外50题被归入极端困难的Tier 4,接近乃至达到数学的前沿研究问题。
为便于社区实验,FrontierMath只开放了少量公开子集,其余题目则严格保密,用于评测。
在评测时,模型必须为每道题提交一个Python函数answer(),返回整数(通常)或SymPy等Python对象,由系统自动运行与校验。
这一设计既允许模型调用代码深度推理,又用程序化判分确保结果客观可重复,使FrontierMath成为当前衡量AI数学前沿能力最严苛、也最具说服力的基准之一。
截至目前,FrontierMath排行榜上的领先模型,都是由Gemini和GPT系列占据。
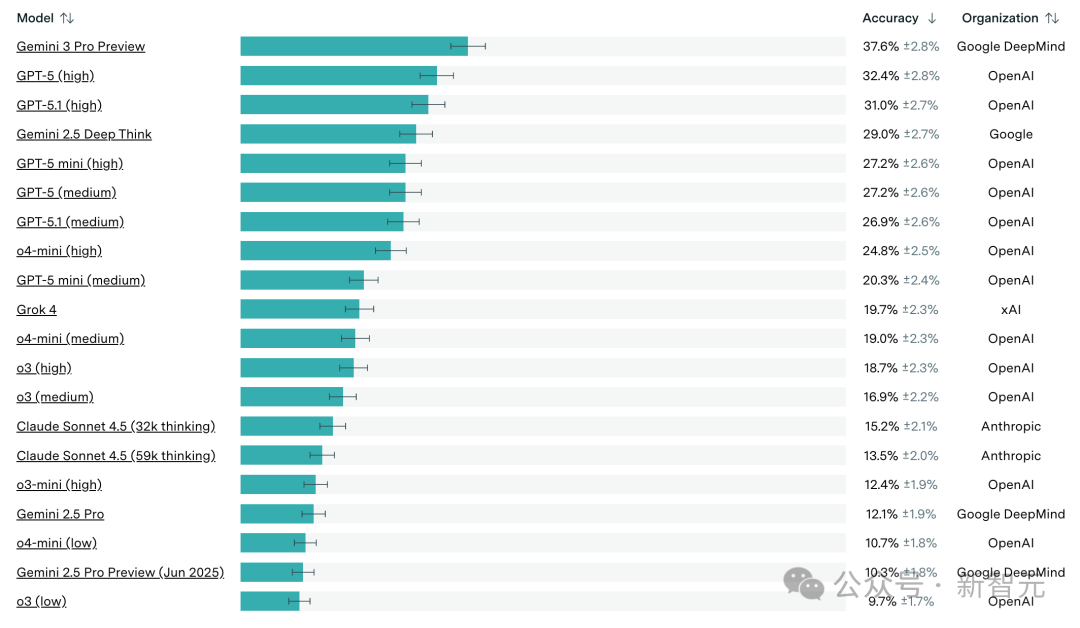
从「跑分最强」到「实战破题」
虽说Gemini 3确实很强,但只是一味的霸榜基准测试,还是差点意思。
至少,缺少点说服力。
还好,Gemini 3很快就在实战中证明了自己。
就在昨天,数学大神陶哲轩发帖表示,他用Gemini Deepthink模式十分钟,便解决了埃尔德什问题#367 的关键证明!

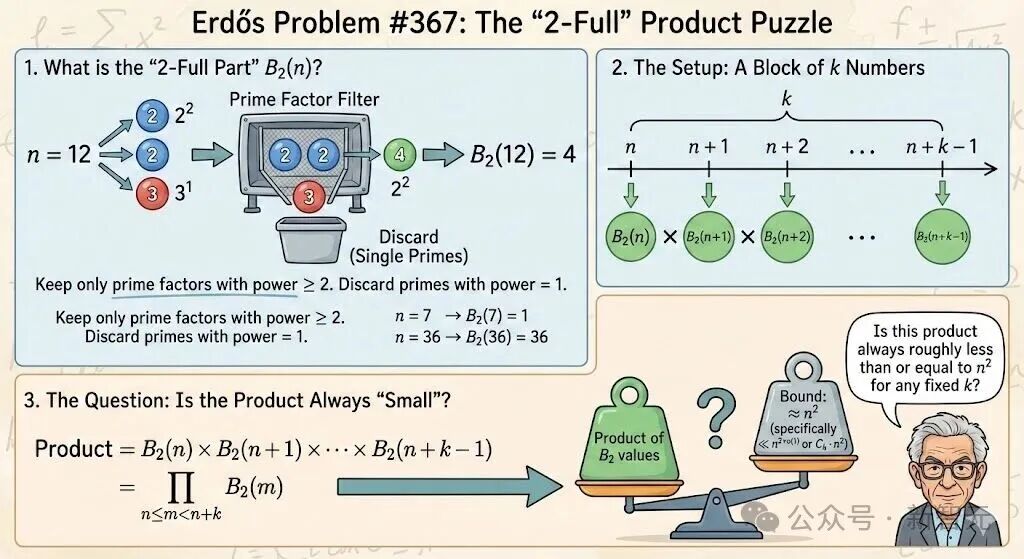
为了更清楚地说明这个过程,我们先来简单了解一下埃尔德什问题#367。
简单说就是把每个整数拆成积木,凡是只出现1次的积木丢掉,只留下能成对出现、能拼成平方的那一部分,叫B₂(n)。
比如12=2×2×3,只留2×2,所以B₂(12)=4。
现在看一小段连续整数n,n+1,…,n+k-1,对每个数算出B₂,再把这些B₂全部相乘。
埃尔德什问题#367 的问题是:不管这段连续整数多长,这个乘积是不是都不会比n²增长得更快?
也就是说:整数里「平方因子扎堆」的程度,天花板究竟在哪里?

为了更方便理解,我用最近最火的Nano Banana Pro画了张信息图。
大家看看怎么样?
言归正传。关于这个问题,陶哲轩在帖子中给出了一条时间线。
11月20号,Wouter van Doorn用AI提出了该问题第二部分的反证,他的论证基于一个还未被证明的同余恒等式。
几个小时后,陶哲轩将这个不等式交给了Gemini Deepthink。
只用了大概十分钟,Gemini Deepthink便解决了这个证明。
太夸张了!
陶哲轩还附上了整个的论证过程。

论证地址: https://gemini.google.com/share/81a65aecfd70
看来这种问题对于Gemini 3还真算不上什么。
随后,陶哲轩手动把证明转化为了一个更加基础的版本,花费了他半个小时的时间。
两天后,Boris Alexeev最终完成了这个证明的Lean形式化,耗时2、3个小时。
陶哲轩用Gemini 3来研究埃尔德什难题,厉害之处不只是「AI 超会算」。
更重要的是:世界顶级数学家,真的把大模型当成工作伙伴了。
以后做数学,不再只是一个人苦苦推导。
而是把枯燥的枚举、尝试、检验丢给AI,人类集中精力抓核心思路、做关键判断。
谁先学会和这类工具高效协作,谁就等于多了一个「超级合作者」。
数学之外的物理「试金石」
在登顶数学基准测试的同时,Gemini也霸榜了一项最新的物理基准测试——CritPt。
CritPt的诞生基于研究者们开始追问一个问题:大模型真的能像物理学家那样,完整推进一场前沿研究吗?
其全称为 「Complex Research using Integrated Thinking – Physics Test」,要测的,正是 AI 从「像样回答」跨越到「真正推理」的那道临界线。
目前已在Artificial Analysis平台上线。

与以往基于教科书或公开题库的物理题库不同,CritPt是首个专门面向「未公开、真研究级」物理问题的大模型基准。
它由来自阿贡国家实验室、伊利诺伊大学厄巴纳-香槟分校等三十多家机构的五十余位活跃物理学者共同打造,涵盖凝聚态、量子、原子分子与光学、天体物理、高能物理等现代物理的十一大分支。
每道题目都像是交给一名优秀物理学博士新生的一次独立小课题:需要建模、推导、近似与跨领域联想,却又保证答案可机读、可自动严格判分。
CritPt测试的挑战示例如下图所示。

不出意外,Gemini 3 Pro再次霸榜该项物理研究测试。
同样的,GPT-5.1紧随其后。
看来,这两模型还真是代表了当前最前沿的模型水平。
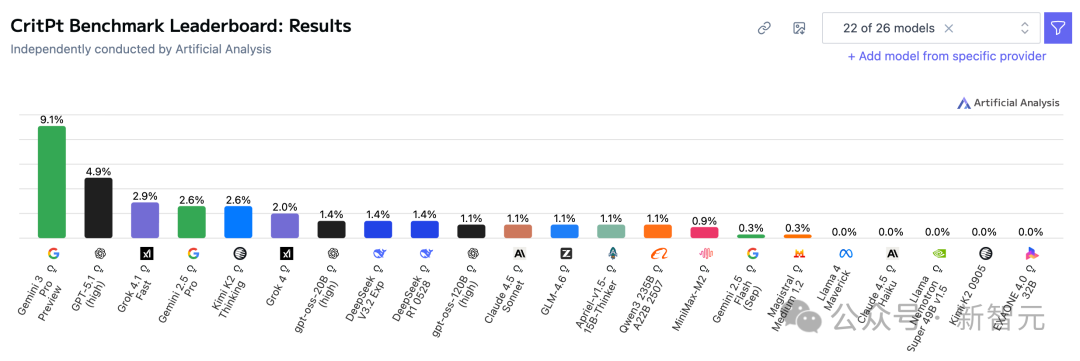
不过,虽然登顶了CritPt,Gemini 3 Pro的成绩也才有9.1%,与满分表现还有些距离。
参考资料:
https://x.com/EpochAIResearch/status/1991945942174761050
https://x.com/ArtificialAnlys/status/1991913465968222555?s=20
https://x.com/kimmonismus/status/1991968861747339508?s=20
https://mathstodon.xyz/@tao/115591487350860999
https://mathstodon.xyz/@tao/115585571504291318
https://www.kaggle.com/competitions/ai-mathematical-olympiad-progress-prize-3/overview
文章来自于微信公众号 “新智元”,作者 “新智元”


