# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
腾讯混元大模型团队正式发布并开源HunyuanOCR模型!
这是一款商业级、开源且轻量(1B参数)的OCR专用视觉语言模型,模型采用原生ViT和轻量LLM结合的架构。

具体而言,其感知能力(文本检测和识别、复杂文档解析)优于所有公开方案;语义能力(信息抽取、文字图像翻译)表现出色,荣获ICDAR 2025 DIMT挑战赛(小模型赛道)冠军,并在OCRBench上取得3B以下模型SOTA成绩。
目前,该模型在抱抱脸(Hugging Face)趋势榜排名前四,GitHub标星超过700,并在Day 0被vllm官方团队接入。

团队介绍,混元OCR专家模型实现了三大突破:
(1)全能与高效统一。
在轻量框架下支持文字检测和识别、复杂文档解析、开放字段信息抽取、视觉问答和拍照图像翻译,解决了传统专家模型功能单一和通用视觉理解大模型效率低下的痛点。
(2)极简端到端架构。
摒弃版面分析等前处理依赖,彻底解决流水线错误累积问题,大幅简化部署。
(3)数据驱动与RL创新。
验证了高质量数据价值,并证明强化学习可显著提升多项OCR任务性能。
目前模型参数已在抱抱脸和ModelScope等渠道开源,并提供基于vLLM的高性能部署方案,旨在助力科研与工业落地。
作为一款具备商业级性能的开源多语言VLM,混元OCR专家模型的核心动机在于构建一个真正统一、高效的端到端OCR基础模型。
其核心技术主要聚焦于以下几个方面:
轻量化模型结构设计、高质量预训练数据生产、重应用导向的预训练策略和OCR任务定制的强化学习。
下图为HunyuanOCR架构示意图。
不同于其他开源的级联OCR方案或专家模型,混元OCR模型贯彻端到端训推一体范式,各项任务仅需单次推理即可获取完整效果。

HunyuanOCR采用由原生分辨率视觉编码器、自适应MLP连接器和轻量级语言模型构成的协同架构。
视觉部分基于SigLIP-v2-400M,引入自适应Patching机制支持任意分辨率输入,有效避免了长文档等极端长宽比场景下的图像失真与细节丢失。
连接器通过可学习的池化操作充当桥梁,在自适应压缩高分辨率特征的同时,精准保留了文本密集区的关键语义。
语言模型侧则基于Hunyuan-0.5B,通过引入创新的XD-RoPE技术,将一维文本、二维版面(高宽)及三维时空信息进行解耦与对齐,赋予了模型处理多栏排版及跨页逻辑推理的强大能力。
与依赖多模型级联或后处理的传统方案不同,HunyuanOCR采用了纯粹的端到端训练与推理范式。
该模型通过大规模高质量的应用导向数据进行驱动,并结合强化学习策略进行优化,实现了从图像到文本的直接映射。这种设计彻底消除了传统架构中常见的“错误累积”问题,并摆脱了对复杂后处理模块的依赖,从而在混合版面理解等高难度场景中展现出远超同类模型的鲁棒性与稳定性。
为了系统性提升HunyuanOCR在多语言、多场景及复杂版面下的感知与理解能力,研究团队构建了一个包含超2亿“图像-文本对”的大规模高质量多模态训练语料库。
通过整合公开基准、网络爬取真实数据及自研工具生成的合成数据,该数据库覆盖了9大核心真实场景(包括文档、街景、广告、手写体、截屏、票据卡证、游戏界面、视频帧及艺术字体)以及超过130种语言的OCR数据。
这套完整的数据生产与清洗流水线,为模型提供了坚实的高质量多模态训练资源,具体揭示如下:

(注:图为高质量预训练数据,(a)(b)(c)展示了数据合成和仿真增强的效果,(d)(e)展示自动化QA数据生产的案例)
在数据合成方面,研究人员基于SynthDog框架进行了深度扩展,实现了对130多种语言的段落级长文档渲染及双向文本(从左到右和从右到左两种阅读顺序)支持,并能精细控制字体、颜色、混合排版及手写风格,有效提升了跨语言泛化能力。
同时,引入自研的Warping变形合成流水线,通过模拟几何变形(折叠、透视)、成像退化(模糊、噪声)及复杂光照干扰,逼真还原自然场景下的拍摄缺陷。
这种“合成+仿真”的策略显著增强了模型在文本定位、文档解析等任务中的鲁棒性。
针对高阶语义理解任务,团队开发了一套集“难例挖掘、指令式QA生成与一致性校验”于一体的自动化流水线。
遵循“一源多用”原则,该流水线实现了对同一图像进行文本定位、结构化解析(Markdown/JSON)及多维推理问答(信息抽取、摘要、计算)的统一标注。系统优先挖掘低清晰度或含复杂图表的难例,利用高性能VLM生成多样化问答对,并通过多模型交叉验证机制确保数据质量。
这一流程有效解决了复杂场景下高质量VLM训练数据稀缺的问题,大幅提升了模型的数据利用效率。
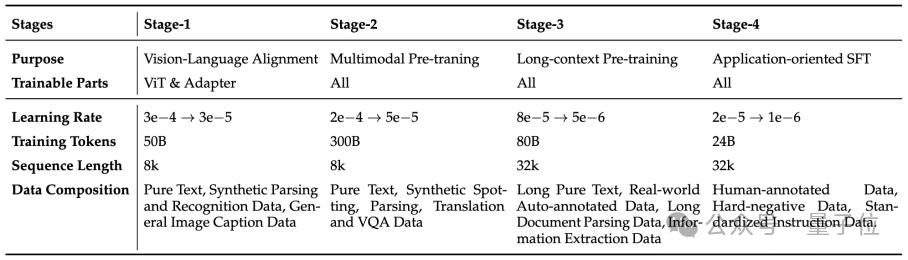
HunyuanOCR采用循序渐进的四阶段预训练策略:
前两阶段聚焦视觉&语言对齐与通用理解能力构建。
其中Stage-1为热身阶段,冻结LLM并仅训练ViT与MLP适配器,通过Caption和OCR数据实现视觉特征与文本语义空间的对齐,强化基础感知与结构化理解。
Stage-2解冻所有参数进行端到端学习,依托约300Btoken数据及涵盖文档解析、文字检测和识别、图片翻译、VQA的多任务合成样本,深度增强模型对文档、表格、公式、图表等复杂结构化内容的感知和理解能力。
后两阶段则侧重长文档处理能力与实际应用场景适配。
Stage-3将上下文窗口扩展至32k,通过长窗口数据训练满足长文档图像解析与理解需求。
Stage-4开展应用导向的退火训练,结合精心筛选的人工标注真值数据与高质量合成数据,通过统一指令模版与标准化输出格式规范模型响应模式,既提升了复杂场景下的鲁棒性,也为后续强化学习阶段奠定了坚实基础。
下面的表格展示了混元OCR模型四阶段预训练:
尽管强化学习已在大型推理模型中取得显著成功,Hunyuan视觉团队创新性地将其应用于注重效率的轻量级OCR专家模型。
针对OCR任务结构化强且易于验证的特点,采取了混合策略:
对于文字检测识别和文档解析等具有封闭解的任务,采用基于可验证奖励的强化学习。
而对于翻译和VQA等开放式任务,则设计了基于LLM-as-a-judge的奖励机制。这种结合证明了轻量级模型也能通过RL获得显著性能跃升,为边缘侧和移动端的高性能应用开辟了新路径。

以下是三个主要注意事项:
第一,严苛的数据筛选。
数据构建严格遵循质量、多样性与难度平衡原则,利用LLM过滤低质数据,并剔除过于简单或无法求解的样本以保持训练的有效性。
第二,自适应奖励设计。
文字检测和识别任务上,综合考虑IoU与编辑距离。
复杂文档解析任务聚焦于结构与内容的准确性;VQA采用基于语义匹配的二值奖励;而文本图像翻译则引入经过去偏归一化的软奖励(例如0~5的连续空间),特意扩展了中段分数的粒度,以便更敏锐地捕捉翻译质量的细微差异。
第三,GRPO算法与格式约束优化。
训练阶段采用群组相对策略优化(GRPO)作为核心算法,为了确保训练的稳定性,团队引入了严格的长度约束与格式规范机制,任何超长或不符合预定义Schema(如结构化解析格式)的输出将直接被判为零奖励。
这一强约束机制迫使模型专注于生成有效、规范且可验证的输出,从而在受限条件下习得精准的推理与格式化能力。
项目主页:
https://hunyuan.tencent.com/vision/zh?tabIndex=0
Github:
GitHub-Tencent-Hunyuan/HunyuanOCR
抱抱脸:
https://huggingface.co/tencent/HunyuanOCR
论文:
https://arxiv.org/abs/2511.19575
文章来自于微信公众号 “量子位”,作者 “量子位”


