# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
站在2025年的尾巴上回望,这绝对是 AI 历史上最具割裂感的一年。
一方面,Google 刚刚发布的 Gemini 3 再次以一种近乎暴力美学的方式验证了 Scaling Law 的有效性。更庞大的参数、更狂野的算力堆叠、更低的数据 Loss。只要卡够多,奇迹似乎就能发生。
但在这之前,整个硅谷却弥漫着浓重的焦虑气息,很多从业者都认为,AI 已然撞上了一堵看不见的墙。
这种焦虑在两位行业巨擘的言论中体现得淋漓尽致。强化学习之父 Richard Sutton 在今年多次发出警告,重申他著名的观点:现有的模型缺乏真正的强化学习(Real RL)和持续学习(Continuous Learning)机制,如果只是在静态数据集上预训练,无论数据量多大,永远无法达到真正的 AGI。
而 AI 大牛 Andrej Karpathy 则更加务实地指出了问题的症结:目前的 Agent(智能体)依然无法可靠地完成复杂的长程任务。
他悲观地预测,人类与 AI 之间存在一个巨大的“认知鸿沟” (Cognitive Gap),我们需要至少 5 到 6 年的时间,才能在架构层面补足由于缺乏系统性思考而导致的短板。

此前,Yoshua Bengio 曾尝试定义 AGI,将人类智能与 LLM 在因果推理、世界模型等十个维度上进行对比,指出了宏观上的差异。而今天,来自 UIUC、华盛顿大学等机构的一群研究人员,通过一篇重磅论文《推理的认知基础及其在大型语言模型中的体现》,为这个“认知鸿沟”画出了一张精确的微观解剖图。

论文链接:https://arxiv.org/abs/2511.16660
他们用认知科学的手术刀,解剖了包括 DeepSeek-R1、Qwen3 在内的17万条推理轨迹。
结论令人不安:目前的 AI 在解决问题时,其思维方法发生了严重的错配。
为了理解这个错配,这篇论文建立了一套包含 28 个认知要素的分类学,这有点像 Bengio AGI定义的更专注于思维能力的深度拆解。

结果显示,AI 患上了一种严重的认知强迫症。
研究团队发现,无论面对什么类型的问题,当今的大模型都极其痴迷于展示逻辑连贯性(Logical Coherence)和前向链式推理(Forward Chaining)。
在论文生成的能力热力图中,AI处理问题,这两项指标在所有任务中都呈现出高频(红色)。模型像是一个辩论赛辩手一样,非常在意每句话之间是否有因果连接词(因为……所以……)步骤是否环环相扣。

逻辑严谨按理说是好事,但残酷的数据揭示出这些 AI 最爱用的招数,与做对难题之间几乎没有相关性。
论文指出,在处理复杂的两难困境(Dilemma)或设计问题(Design)时,逻辑连贯性的成功相关性(NPMI)仅为 0.090 。
这意味着,AI 实际上是在进行一种表演性推理。它们生成这些步骤是为了让这些答案看起来更有模有样,而非为了解决问题。
为了直观地展示这种差异,论文绘制了一张极具冲击力的认知结构图,专门分析了在处理诊断-解决类难题时,AI 的脑回路到底长什么样 。

这张图中圆圈的大小 (Prob) 代表出现频率。圆圈越大,说明模型越喜欢做这个动作。而边框的粗细/颜色 (NPMI)则代表成功相关性。边框越粗、颜色越深,说明这一步对做对题目越重要。
在AI 的默认模式中,最大的圆圈是 前向链式推理(概率 0.748),而且放在了第一步。这意味着,模型在没分析的情况下,就开始盲目计算或推导。
第二大的圆圈是 “逻辑连贯性”(概率 0.906)。模型花费了巨大的算力去维持废话的通顺,但这一项的成功相关性(NPMI)只有可怜的 0.090,典型的“又大又没用”。
而更离谱的是,选择性注意被扔到了流程的末尾。这就好比医生已经把药开完了,才想起来去问病人哪里不舒服。
那么,Karpathy 所说的完成复杂任务到底需要的是什么?论文给出的答案是:选择性注意(Selective Attention)、网络组织(Network Organization) 和 抽象化(Abstraction)。
选择性注意是指在面对海量信息时,先忽略 90% 的噪音,只抓这 10% 的重点。网络组织是指理解事物之间不是简单的线性关系,而是像蜘蛛网一样错综复杂的相互作用。而抽象化,则是从具体的示例中领悟出通用物理法则的能力。

这些才是解决现实难题的屠龙技。然而,在 AI 的行为热力图中,这些区域是一片冰冷的蓝色。模型几乎不会自发地使用这些高级认知策略。

这说明,模型也许根本不会抽象和总结经验,只是在机械地匹配模式。至少这部分能力,没有被当下的训练方式所激活。
此外,论文中最具讽刺意味的发现,是所谓的逆向关系(Inverse Relationship) 。
如果人类遇到简单的算术题,我们可能随手一算,用线性思维就解决了。但遇到复杂的公司战略制定,其解决结构并不清晰时,我们会停下来做思维导图、反思策略。问题越难,我们的思维工具箱打开得越宽。
但AI 却恰恰相反。
数据显示,当问题从结构良好的算法题变成结构不良的两难困境时,模型的行为库反而收窄了。它的思维丰富度从 0.3652 降到了0.2787。面对未知的复杂性,模型似乎直接慌了,本能地退回到了舒适区,死死抱住前向链式推理这根救命稻草。
这完美契合了Karpathy 描述的 Agent 困境。AI在简单的 Demo 里表现完美,一旦被扔进混乱的真实世界,Agent 就开始死循环、幻觉、或者机械地执行错误的计划。
这正是因为它缺乏在混乱中重构和策略选择的能力。
对于成功的思维,论文也给了一张图。流程的第一步是 选择性注意。虽然它的圆圈不大(模型不爱用),但边框极粗(NPMI 0.272,任务成功相关性最高)。这意味着,起手先抓重点,过滤噪音,是成功的绝对前提。
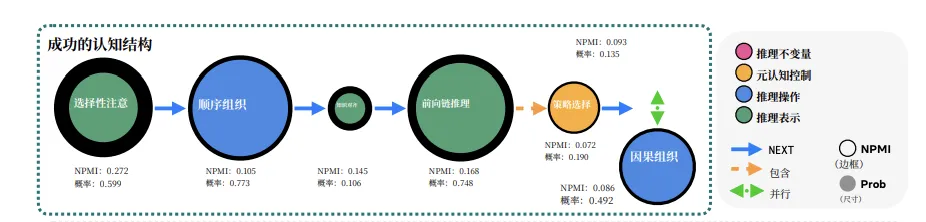
而且在模型动手推导之前,有一个知识对齐的环节,即调用相关的专业图式,保证用对方法。
在推导过程中,出现了一个关键节点策略选择。这就是在半路反思方法是否正确。
为什么我们会制造出这种“高分低能”的AI?论文将矛头指向了AI 界的Benchmark上。
我们目前的评估体系,比如GSM8K或HumanEval,本质上都是结果导向的。只要最终答案是对的,或者代码能跑通,我们就认为模型会推理了。
在这种想要出成功,作出符合提升Benchmark得分的比赛思维下,研究难免会跑偏。
论文作者对 arXiv 上的 1598 篇推理论文进行了元分析,结果令人汗颜:55%的研究都在关注序列组织(因为它好量化),只有 16% 的论文关注自我意识,仅 10% 关注空间组织。

因为Benchmark的结果导向,科学家们可能一直在奖励模型去模仿表面上的推理步骤,却忽略了上一章我们提到的那些更能决定任务成功的能力。
而且,由于这种Benchmark导向,训练的过程也受到了影响,这导致目前的RLHF训练中普遍忽略思维的质量。
比如,DeepSeek R1采用的结果导向奖励(ORM)只在最后给一个"对/错"的反馈,这使得中间的思考步骤没有细粒度奖励,导致AI学会碰运气推理,而非有策略地思考。
而过程密集型RL(PRM),关注的也是纯粹的步骤是否正确,却没有考虑其解题思路是否符合复杂问题处理的逻辑。
结果就是AI掌握了表演性推理(看起来在思考),却缺乏功能性推理(真正解决问题)。
那么现在的问题就变成了,是不是模型本身在预训练过程中,在底层就缺乏有效进行结构化、抽象化思考的能力呢?
论文的作者为此设计了一个实验。
研究人员提取了各类问题中成功案例的思维图谱(Consensus Subgraphs)。比如,对于诊断类问题,成功的思维路径应该是: 选择性注意(抓重点) -> 序列组织(理思路) -> 知识对齐(查医书) -> 前向推理(下判断) -> 策略选择(再想想)。
研究人员在测试时,通过 Prompt 显式地要求模型遵循这个特定的认知结构。结果在最让模型头疼的两难困境和诊断类问题上,经过引导的模型(如 Qwen3-14B 和 R1-Distill 版本)性能提升了高达 60%。

这证明了 AI 其实潜藏着处理复杂逻辑的能力,只不过在过往的训练中,这些能力被浅层路径(前向链式推理)抑制了 。
这个实验还证明了结构(Structure)比单纯的算力(Scale)更关键。只要思维路径对了,现有的模型参数就足够解决难题。
上面提出的方法很好,确实能助力模型提升。但具体的思路需要针对每个case不同去写不同的思维导图,再告诉AI。这效率太低了,本质上还是一种上下文工程,一个临时脚手架。
那有没有什么方法可以把它们内化到模型自身呢?那就只能在训练阶段就改革奖励信号,让模型自发激发出藏在其中处理复杂逻辑的能力。
论文建议,把这次实验中挖掘出的成功思维图谱作为奖励信号(Reward Signal)。在强化学习(RL)阶段,如果模型遇到诊断题,它自发地跳出了“选择性注意 -> 知识对齐”的步骤,奖励模型;如果它一上来就瞎算,则惩罚模型。 久而久之,模型就会把这种外部的 Prompt 内化为自己的参数权重。以后不需要你提示,它遇到难题时会下意识地先抓重点再理思路。
另外一种论文给出的建议方法,是设计课程训练模型的抽象化分析能力。人类之所以能泛化处理问题,是因为我们形成了抽象的图式(Schema)。需要让模型也识别出图式,并学会用它。
因此可以在训练数据中,故意设计一系列结构相同但表面叙述不同的问题,强迫模型去识别底层的结构。并针对性地奖励那些使用了特定认知结构(如网络化组织、层级组织)的回答 。
虽然论文作者本身并没有完整开发一个真正可用的框架。他们证明了药方(思维结构)是有效的,但还没把这副药方炼成药(内化到参数里)。
把这个过程从 Prompt Engineering 变成 Model Training,可能正是 Karpathy 所说的未来 5-6 年行业需要填补的空白,也是 DeepSeek、Google 等公司接下来的核心工作。
文章来自 “ 腾讯科技 ”,作者 “ 博阳 ”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
