# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
仅用300B数据训练。
智东西11月28日报道,刚刚,快手开源其新一代旗舰多模态大模型Keye-VL-671B-A37B。该模型基于DeepSeek-V3-Terminus打造,拥有6710亿个参数,在保持基础模型通用能力的前提下,对视觉感知、跨模态对齐与复杂推理链路进行了升级,实现了较强的多模态理解和复杂推理能力。
Keye-VL-671B-A37B有多强?我们先用几个案例来感受下。下面的图中有几张电影票?多数人看完第一眼可能会脱口而出:“三张。”

不过,Keye-VL-671B-A37B的观察更为仔细,结合票据上的文字,它能判断出其实图中仅有两张电影票,最上面那一张是爆米花小吃券。查看思考过程后,可发现它不仅准确识别画面中每张票据的文字、标识和版式差异,更能进一步推理:左边和中间的票据符合电影票的核心特征,右侧票据无座位信息、无影片场次标注,实为叠放的食品兑换券,并非电影票。
除了图像理解能力以外,Keye-VL-671B-A37B同样拥有强大的视频理解和推理能力。当被问及下方视频的镜头是怎样变化时,它能识别出“蓝色双层电车”、“Louis Vuitton”、“Tiffany & Co”等核心元素,并输出镜头变化的细节。


快手公布了Keye-VL-671B-A37B与其他VL模型的性能对比。在通用视觉理解和视频理解两大核心领域,Keye-VL-671B-A37B的整体表现超过了字节的Seed1.5-VL think、阿里的Qwen3-VL 235B-A22B等前沿VL模型。

在涵盖STEM、推理、通用问答、视频理解、OCR和纯文本等能力的26项主流基准测试上,Keye-VL-671B-A37B斩获18项最高得分。

目前,Keye-VL-671B-A37B已经正式开源,可在Hugging Face和GitHub下载体验。
Github:
https://github.com/Kwai-Keye/Keye
HuggingFace:
https://huggingface.co/Kwai-Keye/Keye-VL-671B-A37B
三阶段完成预训练
仅使用300B高质量数据
Keye-VL-671B-A37B采用DeepSeek-V3-Terminus作为大语言模型基座初始化,具备更强的文本推理能力,视觉模型采Keye-ViT初始化,这一组件来自Keye-VL-1.5,二者通过MLP层进行桥接。Keye-VL-1.5是快手今年9月初开源的一款多模态大模型,拥有80亿个参数,支持128k tokens扩展上下文。
Keye-VL-671B-A37B的预训练涵盖三个阶段,以系统化构建模型的多模态理解与推理能力。模型复用Keye-VL-1.5的视觉编码器,该编码器已经通过8B大小的模型在1T token的多模态预训练数据上对齐,具备较强的基础感知能力。
快手筛选了大约300B高质量数据预训练数据,这与其他大模型动辄以“T(万亿)”计算的训练数据差异很大。快手称,希望以有限计算资源高效构建模型的核心感知基础,确保视觉理解能力扎实且计算成本可控。
Keye-VL-671B-A37B的预训练分三步走:
第一阶段:冻结ViT和LLM,只训练随机初始化的Projector,保证视觉、语言特征能初步做对齐
。
第二阶段:打开全部参数进行预训练。
第三阶段:在更高质量的数据上做退火训练,提升模型的细粒度感知能力。
Keye的多模态预训练数据是通过一套自动化的数据管线来构建的。快手对数据做了严格过滤、重采样,并加入VQA数据增强,让数据能覆盖像OCR、图表、表格这些常见且复杂的视觉格式,提升模型的感知质量和泛化能力。
在退火阶段,快手加入了DeepSeek-V3-Terminus生成的思维链数据,让模型在继续强化视觉感知的同时,不会丢掉原本强大的推理能力。
采用多阶段后训练策略
验证混合CoT数据效果更好
Keye-VL-671B-A37B的后训练由监督微调(SFT)、冷启动和强化学习三个步骤组成,训练任务涵盖视觉问答、图表理解、富文本OCR、数学、代码、逻辑推理等。
在SFT阶段,Keye-VL-671B-A37B技术团队使用了更多的多模态和纯文本长思维链数据,对模型的纯文本能力进行回火并增强多模态能力。在冷启动阶段,采用推理数据增强模型的推理能力,在强化学习阶段,采用复杂推理数据提升模型的think和no_think(思考与非思考)能力,并加入视频数据,增强模型的视频理解能力。
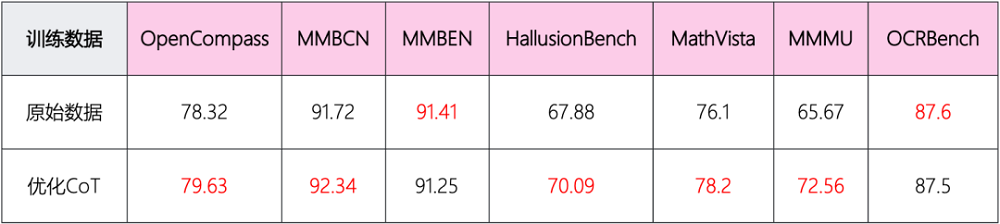
Keye-VL-671B-A37B技术团队对数据集中指令(Instruct)数据和长思维链(Long-CoT)数据的配比进行反复实验,以突破此前监督微调范式片面依赖指令数据的局限性。
这一过程中,快手验证了混合模式(Instruct + Long-CoT)相对于单一模式(Instruct)的优越性,即在SFT数据集中加入更多长思维链推理数据,有利于提升模型整体性能,以及改善后续训练稳定性。
loss曲线显示,在SFT阶段加入更多的CoT数据可以显著降低冷启动阶段的训练loss。



强化学习采用Qwen3同款算法
并打造专用Verifier模型
强化学习阶段,快手没有使用传统的GRPO强化学习算法。GRPO是token-level(token层)的建模,在训练MoE模型时存在不稳定性。
在Keye-VL-671B-A37B的训练中,快手采用GSPO(Group Sequence Policy Optimization)作为底层强化学习算法,进行sequence-level(序列层)的建模,提升可验证奖励强化学习(RLVR)训练的稳定性。值得注意的是,该算法是阿里Qwen3系列模型的核心算法之一。
对于强化学习而言,奖励信号的质量至关重要。在Keye-VL-671B-A37B的强化学习系统中,快手首先训练了专门的Verifier(验证器),用于验证模型输出思考过程的逻辑性,以及最终答案与标准答案的一致性,Verifier模型采用Keye-VL-1.5 8B作为基座,训练过程包括SFT和RL两个阶段。
在SFT阶段,既有简单的二分类任务,即直接判断生成的答案是否与参考答案一致,也有更复杂的分析任务,需要Verifier模型采用think-answer的格式分析模型生成的回复的逻辑性和正确性。
在RL阶段,技术团队首先在大规模偏好数据上训练,然后利用人工标注的高质量数据集进行退火,提高Verifier模型的精度。
为了考察Verifier模型对于生成结果的检测精度,技术团队抽取了10000条训练数据以及模型生成的答案,对比Verifier模型和Qwen-2.5-VL 72B Instruct模型的检测精度,在人工抽样的150条Keye-Verifier与Qwen判别结果不一致的数据中,Keye正确的数目达到了128条,Qwen占22条。
基于Keye-VL-preview的预实验显示,Keye-Verifier提供的奖励信号,相对于基于规则匹配的奖励信号,使Keye-VL-preview在多个开源感知benchmark上的平均准确率提升了1.45%,在三个多模态数学数据集上的平均准确率提升了1.33%。
为了筛选高难度样本,快手利用Keye-VL-1.5-8B作为过滤器,在候选数据集上采样并用Verifier模型计算准确率,仅保留正确率在25%~75%之间的数据用于训练。在RL数据集中,快手加入了更多视频数据以提升模型的视频理解能力。
结语:多模态模型
迈向会“办事儿”的未来
快手称,未来,Keye-VL系列模型将在提升基础模型能力的同时,进一步融合多模态Agent能力,走向更“会用工具、能解复杂问题”的形态。模型的多轮工具调用能力会得到增强,让它能够在真实任务中自主调用外部工具,完成搜索、推理、整合。
同时,快手也会推进“think with image”、“think with video”等关键方向,使模型不仅能看懂图像与视频,还能围绕它们进行深度思考与链式推理,在复杂的视觉信号中发掘关键信息。最终,快手希望打造出更通用、更可靠、更强推理的下一代多模态系统。
文章来自于微信公众号 “智东西”,作者 “智东西”


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
