# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如果AI的终极使命是拓展人类认知的边界,那么“研究”——这项系统性探索未知的核心活动,无疑是其最重要的试金石。2024年,AI Agent技术迎来突破性进展,一个名为 Deep Research(深度研究) 的方向正以前所未有的速度站上风口,成为推动“AI应用元年”的真正引擎。 但热潮之下,我们更需要深度的思考:Deep Research 究竟是什么?它从何而来,又将去往何处?其背后的技术架构有何精妙之处?我们又如何客观评价一个系统的优劣?
本篇近万字的深度剖析,将为你彻底理清Deep Research的“前世今生”,拆解其核心架构与方法论,建立一套清晰的评测视角,并直言不讳地指出当前顶尖系统的优势与缺陷。这是一份为你准备的AI研究进化论地图,请坐好,我们马上发车!
自 2023 年 AutoGPT、GPT-Engineer 等原型工程引爆“Agent”概念以来,大模型的应用落地从“问答和摘要”迅速升级为“自治任务执行”。所谓 AI Agent,是可以在最小人工干预下完成「感知 → 规划 → 行动 → 反馈」闭环的智能体,既能解析自然语言目标,又能调用搜索引擎、数据库等外部工具。随着互联网等领域陆续跑通第一批端到端 PoC,企业级需求出现了三条明显的技术主诉:
● 实时性:Agent 必须随时接入最新数据而不依赖百亿参数中 “冻结” 的旧知识;
● 可追溯性:Agent 的每一步决策都需要有可 audit 的依据,方便合规审计与灰度调参;
● 稳定性:多轮规划链 + Tool 调用若全部依赖大模型长上下文,会让推理结果不可控;
上述三点恰好暴露了“仅靠参数记忆”范式的软肋,指引着 AI Agent 向“知识增强、检索驱动、成本可控”的新方向演进。

Deep Research Agent 的演变历程
步入 2025 这一被誉为 “AI 应用元年” 的关键节点,OpenAI ,Google 和 Perplexity 等头部厂商相继推出了各自的 Deep Research 系统,以满足上述需求。面向复杂且多步骤的研究任务,用户只需输入待解的问题,原本需要数小时甚至数天才能完成的深度分析,如今往往在几分钟内即可交付,极大节省了时间与人力成本,真正把 “AI Agent × Deep Research” 推向规模化落地的新拐点。
那么它究竟是如何做到像专家一样,对一个领域的问题进行分析和研究的?本文将带你:
● 快速拆解 Deep Research 的由来、通用框架以及各模块的制胜技巧;
● 了解 Deep Research 的相关评测方法、现有系统及其局限性;
● 最后带大家认识下 Dola —— 具备整合非结构化公域数据 ✚ 结构化私域数据的数据助手;
尽管大语言模型(LLMs)在处理复杂任务方面展现出卓越的能力,但其内部知识存在明显的边界性限制。这些限制主要体现在三个方面:
1.知识的时效性问题,模型训练数据存在截止时间,无法获取最新信息;
2.专业领域知识的深度不足,在特定垂直领域可能缺乏足够的专业性;
3.容易产生"幻觉"现象,即生成看似合理但实际错误的信息;
这些局限性严重制约了大模型在实时性要求高和专业性要求强的场景中的有效应用。为了克服这一挑战,检索增强生成(Retrieval-Augmented Generation, RAG)技术应运而生。

RAG 流程
RAG 通过检索相关的外部文档,为大模型提供额外的信息源,从而显著提升生成文本的时效性和专业性。
然而,传统RAG方法存在一个根本性问题:大模型只是被动地运用检索得到的结果,缺乏更为深入的推理能力。例如,当搜索得到的结果与查询不相关时,系统无法自主调整搜索关键词重新获取信息源,也无法进行多轮迭代优化检索策略。
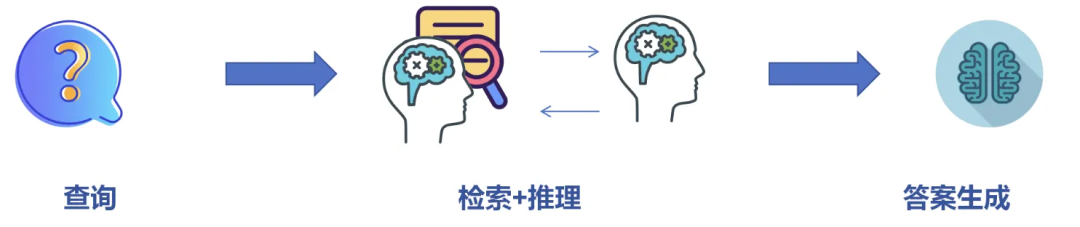
Deep Research 流程
随着 LLMs 技术的蓬勃发展,LLMs 开始具备反思推理等智能体(agentic)能力,这标志着搜索范式从原来的“被动检索”转为“主动探索”。基于此,研究人员提出了 Deep Search,开启了模型主动探索的道路。
整个 Deep Search 流程如上图所示:用户输入相关问题后,系统会初步检索,并阅读检索的结果,然后推理判断目前的检索结果是否足以很好的回答当前的问题,如果分析发现依然存在信息缺口后触发二次检索,直至满足预设终止条件,最后生成答案。从上述流程可以看到,Deep Search 最大的特点就是能自适应的在 Web 上主动进行多轮检索,以不断获取与任务目标匹配的高质量信息,充分体现了从“被动检索”到“主动探索”的变化。
然而,Deep Search主要专注于搜索结果的优化,对于需要多步骤执行深度分析、证据整合和结构化输出的复杂研究任务仍显不足。为此,Deep Research 在 Deep Search 的基础上进一步发展,结合了主动探索和结构化分析框架的优势。
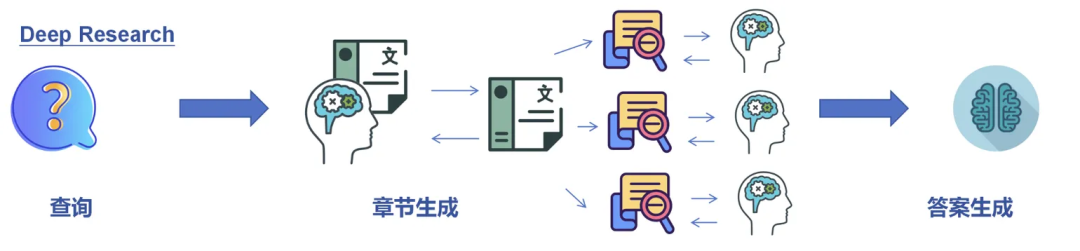
Deep Research 流程
从上图可以发现,Deep Research 继承了 Deep Search 的主动探索能力,且增加了任务规划和报告生成模块。
1.任务规划:负责将复杂的问题进行拆解,生成多个对应的子问题,以支持不同分支的探索;
2.报告生成:将多源证据整合为连贯、可信的结构化输出,真正满足复杂研究任务的需求。
讲到这里是不是已经对 RAG 到 Deep Research 的发展历程有了初步了解了?下面我们再通过一个例子来直观展示下 DR 与传统信息检索方法的区别:

信息检索方法对比:(左上) Query:在 2024 巴黎奥运期间,看完 100 米决赛后,当晚赶去伦敦看音乐剧,最晚能坐哪趟 Eurostar?(左中) 传统的搜索方法:直接通过浏览器或 API 进行检索;(左下角) RAG:将检索结果与生成式模型结合,以自然语言输出答案;(右侧) Deep Research:通过检索和显式推理生成复杂的决策或分析。
1、传统搜索工具调用:难以理解用户意图,进行搜索后只回答了 100 米决赛时间。这体现了传统搜索工具调用依赖预定义的工作流,灵活性差的缺陷;
2、RAG:相比传统搜索,RAG 一次性搜索了多个关键词,取回若干片段后给予 LLMs 回答,但由于缺乏深入的推理能力,只回答了 Eurostar 的末班车时间,依旧不是用户想要的答案;
3、Deep Research:先 “think”:显式列出求解任务的子目标,再 “search”:针对每个子目标逐步检索、验证、更新假设,最后 “answer”:整合所有已验证信息并给出行动可行性判断和方案。

Deep Research 通用架构
下面我们将对 Deep Research 的工作流程进行介绍,让大家可以清晰的了解其原理。Deep Research 架构主要由四个模块组成,分别是 “规划”、“问题演化”、“网页探索” 和 “报告生成”,下面将对四个模块进行功能介绍:
● 规划:此模块将用户问题转换为一系列可执行的子目标或子步骤,以指导后续的推理和检索;
● 问题演化:基于规划部分给定的子目标,将其转换为一组符合目标需求的查询关键字;
● 网页探索:基于“问题转换”的关键字,此模块自驱动地进行迭代式的搜索以获取相关和可信的信息;
● 报告生成:基于检索到的与研究问题相关的信息,本模块对其进行汇总并生成一篇连贯且可靠的报告;
Planning 模块是 Deep Research 流程的第一阶段,其核心作用包括:
1.将用户意图转化为可执行计划:将高层次研究问题分解为结构化子目标序列;
2.提供结构化路线图:生成明确的、任务感知的执行路线图;
3.克服被动检索局限:实现主动规划和系统化推理;

Planning 框架
在上图的框架中,Planning 模块通常包含三个核心组件:任务规划器(task planner)、计划执行器(plan executor)以及环境(environment)具体而言:
● 任务规划器:LLMs 负责生成解决目标任务的完整计划,该计划可以采用多种形式呈现,例如用自然语言描述的一系列动作序列或用编程语言编写的可执行程序,为了应对长流程任务,通常还会结合记忆机制来存储与检索计划;
● 计划执行器:负责按照计划执行各项动作:对于文本类任务,可由 LLMs 等模型实现,对于编程类任务,则可利用代码解释器等工具来完成;
● 环境:指计划执行器执行动作的场所,例如基于大模型内部知识以及外部知识(知识图谱等)来进行规划,环境会以自然语言或其他多模态信号的形式向任务规划器反馈执行结果;
总的来说,在解决复杂任务时,任务规划器首先需要充分理解任务目标,并基于 LLMs 的推理能力生成合理的计划。随后,计划执行器按照计划在环境中执行相应动作,环境再将执行的反馈返回给任务规划器。任务规划器可以结合这些反馈,对最初的计划进行调整与优化,并迭代地重复上述流程,以获得更优的任务解决方案。

更多关于 Planning 的方法还可以参考 Agent :Understanding the planning of LLM agents: A survey

在现实应用中,可以将为了更好地响应用户需求,Planning 动态工作流通常采用以下三种工程手段来进一步优化规划策略:
● 仅规划 (Planning-Only):直接根据用户初始提示生成任务计划,不进行意图澄清,大多数 DR 智能体(如 Grok、Manus)采用此策略;
● 意图到规划 (Intent-to-Planning):在规划前通过提问主动澄清用户意图,再生成定制化计划,OpenAI DR 是典型代表;
● 统一意图规划 (Unified Intent-Planning):先生成初步计划,然后与用户交互以确认或修改该计划,Gemini DR 采用此策略,有效结合了自主规划和用户引导;
Planning 模块标志着 AI 从被动提示到主动规划的范式转变。通过两大方法论——结构化世界知识和可学习过程,以及三种额外工程手段来优化该模块,为后续的 Question Developing、Web Exploration 和 Report Generation 阶段奠定了坚实基础,是实现端到端自主研究的关键环节。
要完成多步推理、信息综合等深度研究任务,仅依赖一次性的静态查询往往不够,系统必须动态地产生更加针对性、更具上下文、或经过拆分的查询,以便从检索模块或互联网中提取有价值的证据,此过程便是 Question Developing。
Question Developing 模块是 Deep Research 流程的关键转换阶段,其核心作用包括:
1.将结构化计划转化为可执行查询:将规划阶段生成的子目标转换为具体的搜索查询序列;
2.实现上下文感知的查询生成:根据累积证据和任务演变动态调整查询策略;
3.平衡查询的特异性与覆盖范围:确保查询既精确又全面,避免信息遗漏;
4.指导后续检索过程:为网络探索阶段提供高质量的检索指令;

ManuSearch 架构图
以 ManuSearch 为例来进行介绍,采用基于智能体、模块化的体系结构,通过三类协作 Agent 完成 Web 级复杂推理任务:
● 规划智能体(Solution Planning Agent):依托 LLM,对用户查询进行解析,制定整体策略(即一系列子问题或步骤),并在每一步决定需要检索的信息;
● 互联网搜索智能体(Internet Search Agent):根据规划器的请求执行网络搜索,从开放互联网收集相关证据;
● 网页阅读智能体(Webpage Reading Agent):负责阅读检索到的网页,提取回答问题所需的关键信息。
此处我们重点关注 Solution Planning Agent,从图中可以观察到,基于用户 Query 和中间执行结果,该阶段分别生成了对应的待执行步骤,后续便进入了 Extract Problems 阶段,该阶段便是基于执行步骤来对问题进行转换,转变为后续可执行搜索的问题,且该转换内容随着证据的积累和任务演变动态调整。

Question Developing 模块是 Deep Research Agent 的核心组件,负责将子目标转化为一系列具体的检索查询。这些查询既要准确反映子目标的意图,又需具有足够的广度,以便从外部信息源获取全面且相关的内容。它本质上是 Agent 探索信息空间的起点,直接影响后续检索与答案生成的质量。 目前主要通过基于奖励和监督驱动的方式来进行优化,旨在让 Agent 更“聪明地提问”,以满足复杂的研究需求。
从科学发现、文献综述到事实核查等各类专家级调研流程,都高度依赖于在浩瀚且异构的互联网信息中检索精确、具备上下文且可信的证据。然而,由于相关资料零散地分布在无数网页之中,如何让 Agent 准确定位并提取最有价值的内容,便是 Web Exploration 模块需要完成的任务。
Web Exploration 模块作为 Deep Research 流程的第三阶段,其核心作用包括:
1.信息检索与获取:从在线资源中高效检索相关且可信的信息;
2.动态导航能力:在复杂网络环境中进行自主导航和交互;
3.多模态内容处理:处理文本、图像、结构化数据等多种内容形式;
4.质量过滤与验证:确保检索内容的相关性和可信度;
当前的 Web Exploration 模块分为两种形式:
● 基于 API 的搜索:基于 API 的搜索引擎通过与结构化数据源(如搜索引擎 API 或科学数据库 API)交互,实现对结构化信息的高效检索;
● 基于浏览器的搜索:通过模拟人类的网页交互行为,能够实时提取动态或非结构化内容,从而提升外部知识的全面性;

基于 API 检索流程
基于 API 的搜索方式,因其速度快、效率高、结构化好且具备可扩展性,成为深度研究智能体获取外部知识的常用方式,所需时间和计算成本相对较低;例如,Gemini DR 通过多源接口——尤以 Google Search API 和 arXiv API 为代表——在数百到上千个网页中进行大规模检索,大幅扩展了信息覆盖范围。尽管这些 API 驱动的方法在结构化、高吞吐的数据获取方面表现优异,但面对深层次的客户端 JavaScript 渲染内容、交互组件或身份验证壁垒时往往捉襟见肘,促使研究者开发能够全面抓取和分析动态及非结构化信息的浏览器级检索机制;

基于浏览器检索流程
浏览器级检索通过模拟人类的浏览操作,为深度研究智能体提供了动态、灵活且可交互的多模态与非结构化网页访问能力。例如,Manus AI 的浏览智能体在每次研究会话中都会启用隔离的 Chromium 实例,编程式地打开新标签、发起搜索、点击结果链接、滚动页面(直至达到内容阈值)、必要时填写表单、执行页面内 JavaScript 以展开懒加载区块,并下载文件或 PDF 以供本地分析。虽然浏览器级检索能捕获 API 无法触及的实时和深层内容,但其延迟、资源消耗更高,且需处理页面差异和错误。

● Web Exploration 模块是深度研究系统的信息获取引擎,通过两大架构范式——Web Agent系统和 API 检索系统——实现了从简单检索到复杂交互的全方位网络探索能力;
● 未来的 Web 探索将依赖混合式架构,把上述两种方法的长处整合到同一系统中,以系统化方式解决核心挑战。高级系统需内置专门模块,用于证据抽取、正确性验证和内容质量评估,先实现快速的初步检索,再进行深层交互分析;
● 多模态处理技术与实时验证框架的突破也至关重要,可确保系统跟上 Web 生态的快速演变。通过为不同模块建立完善的分类框架,并系统性地攻克这些技术难题,Web 探索将成长为深度研究的坚实基础,提供更精准且更可靠的证据检索能力。
在深度研究场景中,文本生成的目标已超越传统的问答任务,而是要产出一份全面、具有分析性的报告,此过程就是“报告生成”(report generation),旨在将从网络检索到的零散信息整合为结构连贯、逻辑清晰、且忠于底层证据的报告。
Report Generation 模块是 Deep Research 流程的最终阶段,其核心作用包括:
1.信息整合与综合:将零散的检索证据转化为结构化、连贯的分析报告;
2.知识合成与推理:从多源信息中提取洞察,生成新的知识和结论;
3.结构化输出:按照特定格式和逻辑组织内容,确保报告的可读性和专业性;
4.事实性保障:确保生成内容的准确性、可信度和可追溯性;
同样可以将该模块的方法进行分类:

LongWriter 章节式合成流程
1.结构控制:
● 旨在生成在整体结构上连贯且一致的长篇文本,这类长篇输出往往包含多个章节,因而必须兼顾有效的整体规划、主题对齐以及版式/层级结构的遵循;
● 此块研究主要从三个维度来解决这一问题:基于规划的生成,约束引导的生成以及结构感知的对齐;
● 以基于规划的生成为例,如上图所示,LongWriter 通过将超长的生成任务拆分为多个子任务,并对每个子任务生成对应的长文本内容,将此思路应用于构建数据,经过此数据训练后的 LLMs 能够生成超过 20,000 词、且连贯一致的长文本;

BRIDGE 整体流程
2.事实完整性:
● 旨在确保生成的报告忠实于检索到的证据,通常通过证据对齐机制或生成后的验证环节来实现;
● 此块研究同样从三个维度来解决这一问题:忠实建模、冲突解析与事实评估;
● 以忠实建模为例,其侧重于确保生成文本与经过验证且具有上下文相关性的证据保持一致。如上图所示,BRIDGE 在检索与生成之间插入了验证层,使 LLMs 能够动态决策并输出综合应答策略。BRIDGE 首先利用一种自适应加权机制——soft bias——来指导知识收集;随后通过“最大软偏置决策树”评估内外部知识的可靠性,并在“信任内部知识 / 信任外部知识 / 拒绝回答”三种策略中选取最优方案;
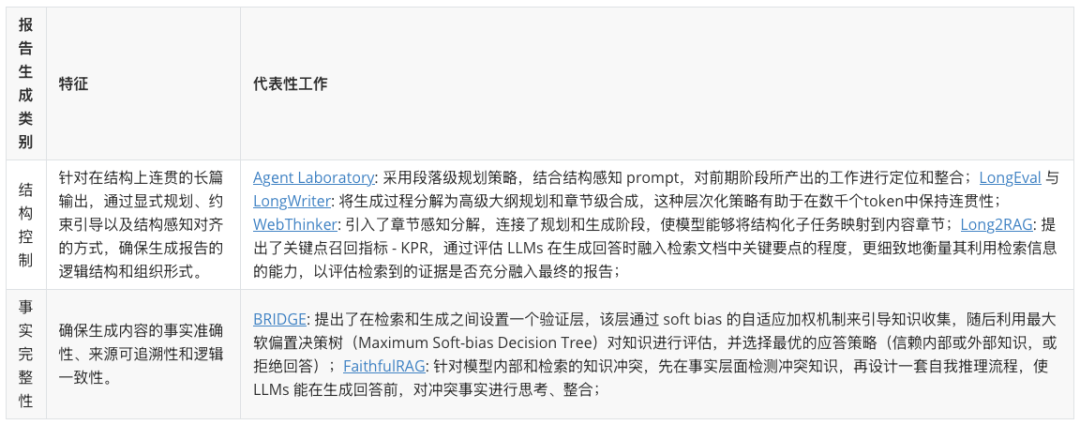
Report Generation 模块是深度研究系统的知识合成引擎,任务是将各子问题所得的零散证据转化为结构化且可信的完整报告。为了确保报告质量,现有方法主要通过结构控制和事实完整性方法实现了从零散信息到结构化知识的转化。
如何验证 Deep Research 系统的效果也是一个重要的研究课题,这驱动着 Deep Research 的不断优化改进。当前不少工作设计了一些 benchmark 来评估上述四个核心技术模块的性能,我们可以将这些 benchmark 根据其任务范围大致分为两类:
下面我们将通过表格的形式来对上述两种类型进行总结。


OpenAI 于 2025 年 2 月发布了其深度研究能力,采用单智能体框架。当系统接收到研究查询后,会先进行简短的交互式澄清步骤,以精准界定用户意图和研究目标。随后,智能体将自主制定并执行一套复杂的多步研究策略,涵盖多模态信息检索、网页浏览,以及通过浏览器工具进行数据分析与可视化等计算任务。在技术层面,该方案带来三项重要创新:
1.动态自适应的迭代研究工作流:在任务执行过程中可不断优化自身策略;
2.增强的上下文记忆与强大的多模态处理能力:能够高效整合多元信息来源;
3.完整的工具链整合:将网页浏览功能与内置编程工具相结合,输出结构化且附带精准引用的权威报告;
案例展示(查看完整案例请点击:链接)


阿里巴巴推出的 Qwen Deep Research 系统,采用统一智能体框架,并通过强化学习优化的任务调度机制,提升了自主规划与自适应执行能力,可高效完成复杂的研究工作流。其关键技术亮点包括:
1.动态研究蓝图绘制:支持交互式计划迭代与细化,确保研究路径随需求实时调整; 2.并行化任务编排:可同时进行信息检索、证据验证与综合生成,从而加速研究流程并增强结果一致性与可靠性。
案例展示:


除前文提到的先锋级深度研究服务外,微软、字节跳动、Jina AI、H2O、智谱 AI 等企业也相继推出了自家的 DR 平台。这些解决方案的涌现迅速在全球范围内激起了广泛关注,既彰显了 DR 技术的吸引力,也折射出其巨大的市场潜力。
尽管 DR 领域已取得可观进展,但从上述的案例展示中其实我们可以发现,现有的 DR 系统存在着以下缺陷:
当前的 Deep Research 在很大程度上依赖于公开可用的互联网数据进行信息检索和知识获取。尽管互联网提供了海量信息,但这种单一的数据来源存在显著局限性,尤其是在需要特定领域知识或企业内部信息时。其中企业私有数据访问障碍是最为突出的问题;
依赖互联网数据也带来了固有的数据质量挑战,这直接影响 Deep Research 输出报告的准确性和可靠性。大模型幻觉问题是 Deep Research 面临的一大挑战。当 Deep Research 在互联网上检索到不准确、矛盾或误导性的信息时,LLMs 可能会基于这些信息产生幻觉,从而导致研究报告中出现不实内容,严重损害研究结果的可靠性。
针对单一数据源问题,以“分析 2025 年美联储降息对美股的影响”为例——前文提到的 OpenAI 与 Qwen Deep Research 均主要依赖互联网上的非结构化资讯来完成综合判断,却缺乏对结构化数据的定量支撑(如 2025 年实时美股价格走势)。为了突破这一“单一数据源”局限、获得更深入的洞察,Dola 团队提出并实践了“非结构化公域数据 ✚ 结构化私域数据”的融合方案:通过将SQL 工具获取结构化资产与搜索获取的外部公开信息有机整合,为专业、可靠的分析/研究报告提供坚实保障。接下来,让我们看看 Dola 是如何做到的吧!

Dola —— 是腾讯PCG大数据平台部的新一代数据分析AI助手,是一款基于Agentic AI能力开发的数据分析助手:用户只需要引入个人的数据表,就能得到一枚专属的AI分析师。

它不仅能够完成日常的取数、跑数等基础任务,还能自主规划并执行复杂场景的数据分析,例如异动归因、画像对比分析、股票基金回测、房价预测等。Dola可以自行编写SQL、纠正SQL错误、执行查询、使用Python进行数据处理与可视化,并最终生成一份完整的分析报告。全程无需编写一行代码,只需通过自然语言对话,你就能拥有一个全自动工作的“数据小黑工”。目前已经能自己自主完成数据/产运同学的部分工作。
这里以1个股票回测的例子看看dola的效果:

接下来让我们看下dola是如何解决deep Research缺陷的
Dola 的产品定位是“面向数据分析场景的智能助手”。这一定位决定了它在信息获取与推理环节上的两条核心策略:
1、有条件地调用 Web 探索模块
a)时效性与相关性优先:当用户提出的是“近 24 小时股价异动原因”“本周新出的监管文件对某行业的影响”这类依赖实时动态的查询时,Dola 会主动触发 Web 探索模块,抓取最新网页、公告、新闻源等实时数据,为后续分析提供及时补充;
b)噪声控制:如果用户的问题高度依赖内部数据仓库或历史沉淀(例如“2023Q4 在XX业务上的高价值用户画像”“过去三年各渠道的 GMV 增⻓率拆解”),Dola 会判定 Web 结果的增量价值低且容易引入噪声,因而不会调用 Web 探索。这样既保证了答案的聚焦度,也避免了无关信息稀释结论;
2、以知识库为主、Web 为辅的多源融合
a) 层次化信息结构:Dola 把企业内部的数仓、报表、API 结果等“结构化知识”视为一级数据源;Web 抓取的内容归为二级数据源。回答问题时先自上而下检索,保障内部权威信息优先;
b) 可信度加权:当相同指标在知识库与网页中均有展示时,Dola 会自动为知识库赋予更高置信权重,Web 结果则作为补充验证或细节说明;若二者冲突,则默认内部数据为准;
c)结果融合策略:对于“宏观+微观”或“定量+定性”混合型分析,例如“近一年渠道 A 与渠道 B 的市场份额变化,并结合最新合规政策给出建议”,Dola 会先从数仓拿到月度或季度等份额做数据分析,再调用 Web 模块抓取政策解读与专家观点,并利用大模型推理能力将两部分内容进行串联,最终输出带有数据图表与要点摘要的综合报告。
通过以上两条策略,Dola 能做到:
● 快速响应实时、突发性问题,而不会因“无关联网”增加时延;
● 在深度业务分析场景中保持结论的专业度与一致性;
● 把外部公开信息转化为洞察补丁,而不是干扰源;
● 最终为用户提供“既准又新、既深且稳”的数据分析决策支持;
针对第四节提到的案例,我们引入了美股市场的股票数据到数据库中,以此作为本次案例的知识库内容。针对问题“分析下2025年美联储降息,对美股的影响如何”,Dola 先规划后续步骤:

由于美联储降息属于实时新闻,模型并无相关知识,为此调用了搜索获取最新降息日期,并进行简单总结:

基于获取的降息日期,通过执行一系列 SQL 获取部分代表性美股降息前后的指标情况:
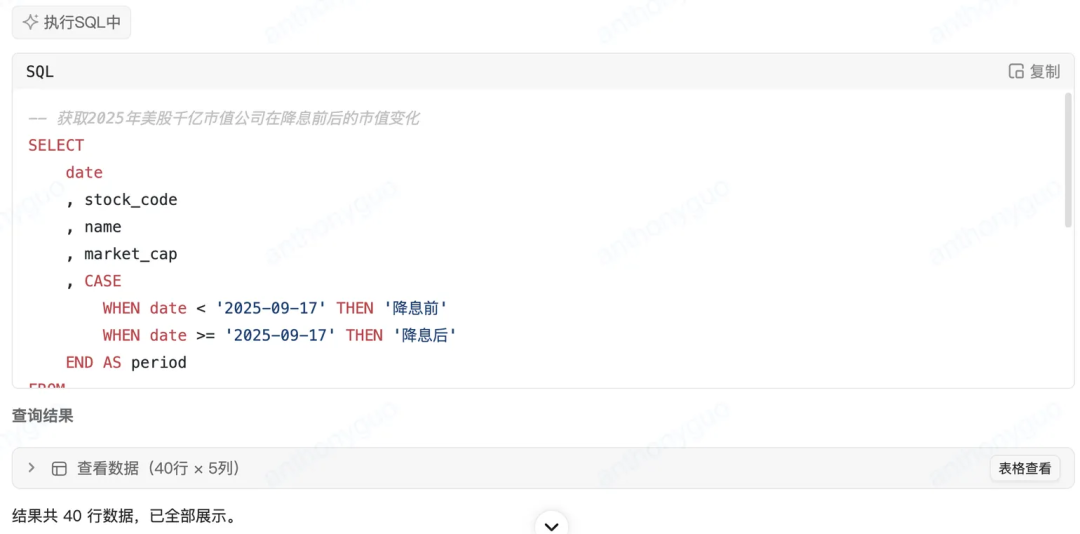
之后同样顺畅衔接 Python 🔧进行数据加载,下钻分析和可视化:
数据加载与下钻分析:

分析结果可视化:
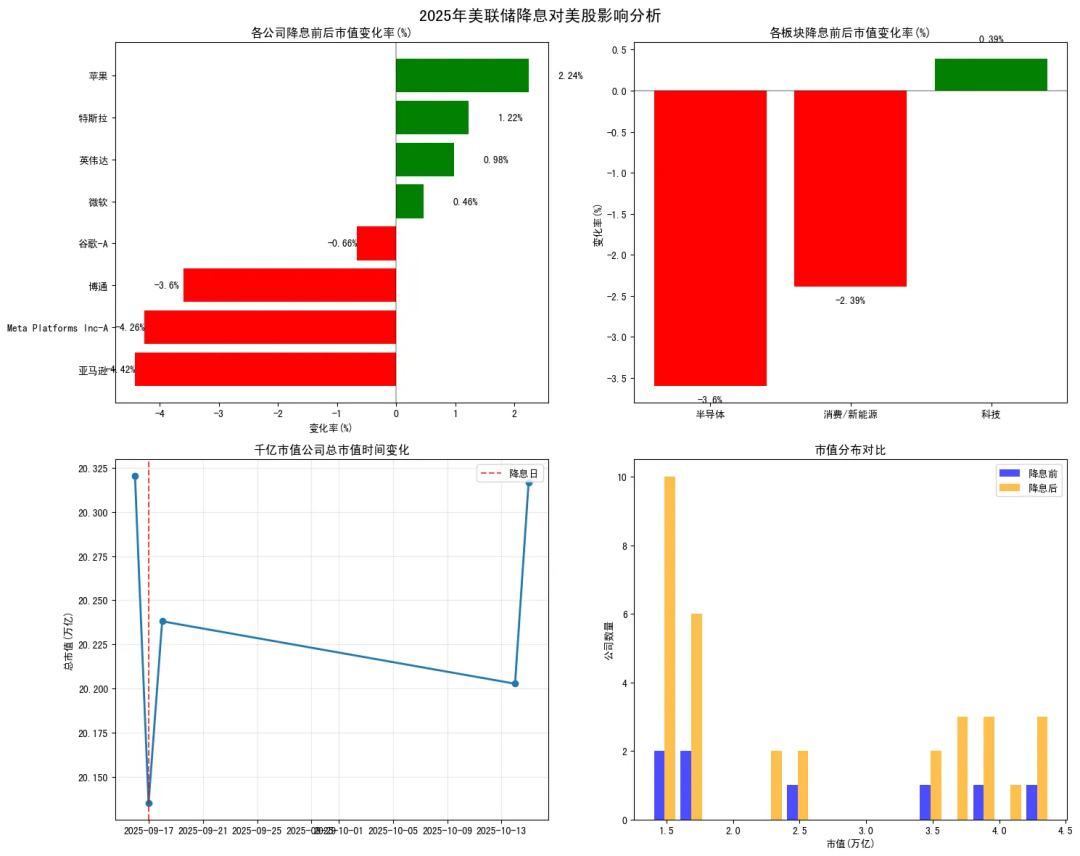
最终结合两种数据源内容,形成总结报告:

...... (此处省略总结内容)

本篇主要介绍了 Deep Research 的相关概念(从 RAG 到 Deep Research 的技术演变)、通用架构(四大核心模块:planning、Question Developing、Web Exploration 和 Report Generation)、现有评测 Benchmark 以及主流系统,最后我们针对当前 Deep Research 系统单一数据源的局限性,介绍了 Dola 团队的方案 —— 充分结合结构化私域和非结构化公域数据,让分析报告更可靠。
[1] Deep Research: A Survey of Autonomous Research Agents
[2] A Comprehensive Survey of Deep Research: Systems, Methodologies, and Applications
[3] DEEP RESEARCH AGENTS: A SYSTEMATIC EXAMINATION AND ROADMAP
[4] Is Your LLM Secretly a World Model of the Internet? Model-Based Planning for Web Agents
[5] Agent Planning with World Knowledge Model
[6] Thought of Search: Planning with Language Models Through The Lens of Efficiency
[7] AGENTSQUARE: AUTOMATIC LLM AGENT SEARCH IN MODULAR DESIGN SPACE
[8] InSTA: Towards Internet-Scale Training For Agents
[9] WEPO: WEB ELEMENT PREFERENCE OPTIMIZATION FOR LLM-BASED WEB NAVIGATION
[10] DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments
[11] ZEROSEARCH: Incentivize the Search Capability of LLMs without Searching
[12] Scent of Knowledge: Optimizing Search-Enhanced Reasoning with Information Foraging
[13] Reinforced Internal-External Knowledge Synergistic Reasoning for Efficient Adaptive Search Agent
[15] Process vs. Outcome Reward: Which is Better for Agentic RAG Reinforcement Learning
[16] WebGPT: Browser-assisted question-answering with human feedback
[17] MM-REACT : Prompting ChatGPT for Multimodal Reasoning and Action
[18] Introducing deep research | OpenAI
[20] Agent Laboratory: Using LLM Agents as Research Assistants
[21] LongEval: A Comprehensive Analysis of Long-Text Generation Through a Plan-based Paradigm
[22] LONGWRITER: UNLEASHING 10,000+ WORD GENERATION FROM LONG CONTEXT LLMS
[23] WebThinker: Empowering Large Reasoning Models with Deep Research Capability
[24] LONG2RAG: Evaluating Long-Context & Long-Form Retrieval-Augmented Generation with Key Point Recall
[25] After Retrieval, Before Generation: Enhancing the Trustworthiness of Large Language Models in RAG
[26] FaithfulRAG: Fact-Level Conflict Modeling for Context-Faithful Retrieval-Augmented Generation
[27] Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
[28] Browsecomp: A simple yet challenging benchmark for browsing agents
[29] Browsecomp-zh: Benchmarking web browsing ability of large language models in chinese
[30] Gaia: a benchmark for general ai assistants
[31] Humanity’s last exam
[32] Webarena: A realistic web environment for building autonomous agents
[33] MedBrowseComp: Benchmarking Medical Deep Research and Computer Use
[34] Gpqa: A graduate-level google-proof q&a benchmark
[35] InfoDeepSeek: Benchmarking Agentic Information Seeking for Retrieval-Augmented Generation
[36] DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents
[37] Deepresearchgym: A free, transparent, and reproducible evaluation sandbox for deep research
[38] Understanding the planning of LLM agents: A survey
文章来自于“腾讯技术工程”,作者 “anthonyguo (郭沛)、 karolinaliu(刘恩婕)”。


【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】OpenManus 目前支持在你的电脑上完成很多任务,包括网页浏览,文件操作,写代码等。OpenManus 使用了传统的 ReAct 的模式,这样的优势是基于当前的状态进行决策,上下文和记忆方便管理,无需单独处理。需要注意,Manus 有使用 Plan 进行规划。
项目地址:https://github.com/mannaandpoem/OpenManus
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
