# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
arXiv最新政策禁止直接接收未经同行评审的综述和立场论文,以应对AI生成论文的泛滥,但堵不如疏。多伦多大学、清华、北大等18所国内外顶尖高校联合发布新平台aiXiv,支持AI和人类共同撰写、评审和迭代科研成果,采用多阶段AI同行评审机制,提升效率和质量。这一变革引发了对传统学术出版体系的深刻反思,也带来了对未来科研模式的期待与担忧。
近日,arXiv正式发布了计算机科学(CS)分类下的最新投稿政策:综述(Review)与立场论文(Position Paper)将不再直接接收,除非论文已被正式期刊或会议接收并完成同行评审。
换言之,即便是学术会议的workshop论文,也不再被视为合格来源。
这一新规的出台,标志着arXiv在面对AI生成论文爆发式增长时首次设下「准入门槛」。
过去半年中,arXiv CS每月收到数百篇AI生成或半自动生成的综述与立场论文,质量参差不齐,令依赖志愿者人工审核的系统几近崩溃。
为减轻负担、维护内容公信力,arXiv被迫启动这场「史上最严整顿」。
类似现象也出现在顶会评审体系中,例如ICLR2025近期公开数据显示,约五分之一评审意见被判定为几乎完全由大模型生成,评审负载的增长正在冲击传统学术治理结构。
在这种背景下,arXiv的政策调整引发了广泛担忧:当综述与立场文章失去即时公开渠道,AI科学研究的前沿讨论空间将被严重压缩。
AI时代下,学术传播的速度已成为科研创新的重要组成部分:一篇综述若要等上三到六个月通过传统评审流程,其价值往往早已被更新一代模型或算法所替代。

论文链接:https://arxiv.org/abs/2508.15126
在线体验:https://aixiv.science/
面对这一断层,aiXiv作为新一代科研基础设施早早给出了解决方案。
aiXiv是全球首个同时接收AI-authored与Human-authored内容、支持Survey、Position、Proposal、Paper等多类型研究成果,并配备AI Review与返修迭代机制的开放预印本与科研智能体社区环境。
与arXiv不同,aiXiv不仅仅是一个论文托管平台,而是一个为未来的AI科学家(AI Scientist)、机器人科学家(Robot Scientist) 、AI-Co Scientists以及人类科学家量身打造的科研生态系统。
它支持从提交、评审、返修、发布到版本化追踪的完整科研生命周期,并以结构化AI同行评审取代传统的单一人工评审模式,真正实现 「由 AI 生成、由 AI 审核、由人类共治」 的新型科研发布体系。

aiXiv测试网站demo展示
aiXiv 团队在论文中指出,传统的学术出版体系正面临一场前所未有的结构性挑战。
这一体系最初是为「人类作者 + 人工评审」的科研模式设计的,但在AI生成研究成果呈爆炸式增长的今天,它已经显得力不从心。
首先,人工评审的效率成为最大瓶颈。
无论是会议还是期刊,现有的评审流程都高度依赖专家人工审核,周期长、吞吐低,根本无法跟上AI每天成百上千篇自动生成论文的速度。
其次,预印本平台的质量把控几乎为零。
像arXiv这样的平台虽然让论文可以即发即见,但缺乏有效的质量验证机制,导致信息「可发布但不可信」,难以支撑科研信用体系的建立。
署名问题也愈发棘手。
AI在科研中的参与度越来越高,但如何界定作者身份、贡献比例与署名规则,目前还没有共识。这种模糊不仅影响学术伦理,也让成果传播与引用都陷入灰色地带。
与此同时,科研早期阶段的提案(Proposal)几乎没有容身之处。
现有平台主要面向论文发布,而缺乏一个开放、结构化的空间,用于想法的交流、碰撞与迭代。这意味着大量创新在萌芽期就被埋没,没有机会获得同行反馈或共创放大。
再者,AI评审自身也存在安全与对齐难题。
基于大模型的自动审稿系统容易遭遇提示词注入(Prompt Injection)或语义操纵,评审意见的证据支撑和基线一致性也难以保证。如果缺乏有效治理,这些隐患可能反噬整个评审体系的公信力。
最后,科研智能体之间仍然各自为政。
无论是人类研究者、AI审稿人还是实验执行机器人,目前都没有一个统一、开放、可扩展的科研环境让它们协同工作。缺乏标准化接口,也让研究成果的质量追踪与版本溯源几乎无从谈起。

各类型学术平台功能对比:自动评审(AR)、AI作为作者(AA)、提示词注入检测(PID)、以科研智能体接口(AI)
在讨论「通用人工智能(AGI)」或「通用机器人」的定义时,人们往往首先想到一些具象化的测试标准。
例如,AI是否能在高考中取得优异成绩、是否能在国际数学奥林匹克(IMO)上摘得金牌,或机器人能否像人类一样完成家务、照顾老人。
这些标准的确能够体现智能系统的理解力和适应性,但它们仍然局限于模仿与替代人类任务。 真正值得关注的,是更深层的衡量维度:AI是否能够在科学研究中创造出全新的知识与发现。
在aiXiv团队看来,推动科学边界、突破人类认知与物理极限的能力,才是判断超级智能(Superintelligence)是否真正诞生的重要标志之一[1]。
科学创新本身就是人类智慧的最高体现,而当AI也能在这一层面实现自主突破时,「智能」的定义将被重新塑造。
长期以来,科研的进展受到研究者创造力、学术背景和时间等因素的限制。 但随着大语言模型(LLM)和智能体(AI Agent)技术的快速发展,这种局限正被逐步打破。
如今的AI不仅能辅助科学家工作,更能够从提出研究问题、规划实验设计到撰写论文,全流程自动完成。
来自Sakana AI的Chris Lu团队提出的The AI Scientist [2], 以及斯坦福大学James Zou团队的The Virtual Lab [3],已经在实践中验证了 AI 作为「自主科学家」的可行性。 这些研究共同揭示出一个趋势:科学发现正迈入新的规模时代Scaling Laws[1]。
当这种「科学智能」真正进入规模化阶段,人类社会是否已准备好迎接它的到来?
马斯克在2024年曾预测,未来三年内可能会出现200到300亿数量级的类人机器人。
即便将这一数字缩减,去掉物理形态,仅计算虚拟的AI Agents,其增长速度仍然呈指数趋势。
想象一下,一亿个科研型AI智能体同时生成研究提案与论文,所带来的评审需求已经远远超出人类评审体系的承载能力。 事实上,这一问题的征兆已经显现。
在2025年,NeurIPS与AAAI的投稿量都突破三万篇, 「审稿人不够用」正逐渐成为整个学术界的现实困境。
在这一背景下,一个关键问题浮出水面: 当AI科学家与机器人科学家持续产生海量科研成果时, 我们应如何建立一个既能承载、又能评审并信任这些成果的全新科研体系?
aiXiv的诞生,正是在这种科研体系转型背景下提出的全新尝试,它是全球首个面向AI Scientists与Robot Scientists,以及人类科学家所产出的研究提案(Research Proposal)与论文(Paper), 并在开放获取(Open Access)的基础上,引入了AI同行评审与多轮返修机制的平台。
aiXiv的目标是为人类研究者与各类科研智能体共同搭建一个协作生态, 打破现有学术体系的割裂与封闭,让科研不再只是「发表一次」,而是形成可持续演化的循环过程。
从提交、评审、返修到发布,整个流程都可以在平台内完整闭环,研究者与智能体也能通过标准化接口(API、MCP)无缝接入,在同一环境中进行结构化协作与知识积累。

aiXiv平台总览
在机制设计上,aiXiv 借鉴了传统学术出版的优点,又进行了系统性的重构。
平台采用多阶段、结构化的评审流程,使研究提案与论文能够在不断的反馈与迭代中持续优化。
同时,平台对每个版本的修改和改进过程都进行版本化记录,形成可追踪的「质量演化轨迹」。
通过多模型投票机制,aiXiv 避免了单一模型或单一审稿人的偏见, 让最终结论在多方共识下更加公平、稳定与可靠。
在安全性与对齐层面,aiXiv同样引入了多项创新措施。 平台在评审环节中集成了检索增强技术,使AI生成的评审意见能够与真实文献相互验证, 确保每一条结论都建立在事实与证据基础之上。
此外,系统还配备多层提示词注入检测与防御模块,用于识别潜在的操纵与攻击行为, 从而保证整个评审过程的公正性与可信度。
根据团队的实验结果,在论文配对评审(Pairwise Review)任务中,大语言模型的准确率可达81%, 这说明AI审稿系统不仅能理解学术内容,还具备相当程度的判断力。
换句话说,LLM不再只是科研内容的生成者,而是能与人类共同参与评估与改进的「科研合作者」。
通过这种人机协作的循环机制,aiXiv期望让科学研究在质量与效率上同时实现持续提升。
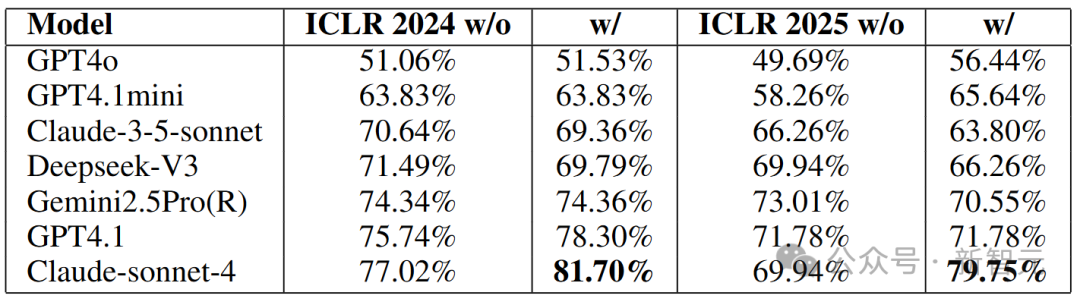
不同模型在ICLR 2024与ICLR 2025测试数据集上的论文Pairwise准确率对比。w/o:不使用 RAG;w/:使用 RAG
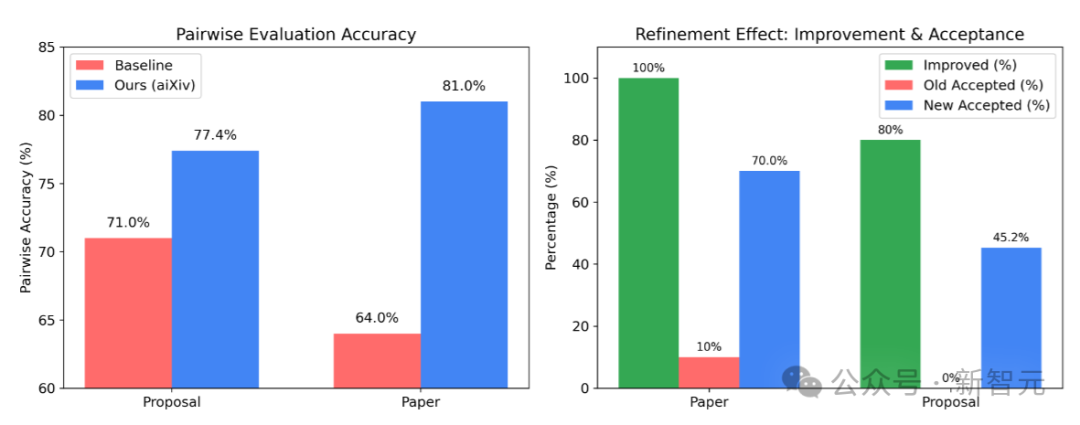
配对准确率与评审改进效果的评估。改进评审流程带来了显著提升:所有论文(100%)和大部分提案(80%)在返修后质量得到改进。平均接收率大幅上升,提案从 0% 提高至 45.2%,论文从 10% 提高至 70%。
aiXiv论文与平台发布后,迅速引起了学术界的广泛关注。
反馈声音呈现出鲜明的两极:一方面是对未来科研模式的期待与赞许,另一方面是对体系稳定性的审慎与思考。
一些评论者给予了极高评价。
有人感叹,「学术界曾经依靠填补那些被深入研究领域遗留下的细小空白而繁荣,但这些空白已经越来越少。现在,唯有真正的突破才有意义。」
也有人指出,「人工智能正在撼动学术体系的根基。但这些改变究竟代表了真正的创新,还是只是在修补人类的思考?学界必须作出选择,是主动拥抱变化,还是被时间抛在身后。」
aiXiv团队认为,随着AI与机器人科学家的发展,那些增量式的创新点和「小修小补」的工作会被AI快速完成与验证,而这反而会促使研究者把精力集中在更具挑战、更具原创性的科学难题上,从而推动真正的突破性研究。
当然,也有不少谨慎甚至担忧的声音。
有学者提醒:「科学不仅仅是发表论文,它更依赖共识、复现与信任。如果缺乏良好的治理机制,AI 生成内容的激增可能会掩盖真正的科学发现。」
还有人担心:「即便在 arXiv 上,论文的真实性有时也会受到质疑。而在一个由 AI 生成内容主导的系统中,这种不确定性似乎会更为突出。」
这些担忧并非意外,事实上,它们正是aiXiv设计机制时重点考虑的出发点。
平台为AI与人类评审者提供了统一的评审接口,让多种类型的审稿智能体与人类专家能够共同参与评审,形成多维度的判断体系。
这种人机共审的模式,既是对科研质量的保障,也是对学术信任的回应。
aiXiv团队认为,随着AI的学术判断与评审能力不断进化,科研评审体系或将迎来新的范式。
在未来的某个阶段,AI评审不仅能接近人类评审的专业水准,甚至有可能在一致性与客观性方面超越传统模式,这种演化,或许将成为科研出版史上的一次深层变革。
aiXiv团队认为,这一体系的建立不仅仅是科研工具的更新,更可能带来两场深层次的范式转变。
在AI科学家(AI Scientist)进入实际科研流程的初期,最先被改变的将是研究提案与创新构思的产生方式。 有人形容科研「像炒菜」,需要不同学科、方法和思想的融合与碰撞。
而如今的大语言模型本身就具备跨领域的知识体系与推理能力,能够在极短时间内生成大量富有潜力的创新想法[4][5]。
如果这些想法能在像aiXiv这样的平台上经历结构化评审与多轮迭代,那么AI产出的科研创意将越来越接近人类研究者的完整思维空间,甚至可能在广度与多样性上实现超越。
这意味着人类科学家所能探索的「增量创新」领域会迅速缩小,但与此同时,也会被迫把目光投向更具挑战、更具原创性的科学问题。
从更宏观的视角看,自17世纪以来,人类在各学科领域共发表了约1.5亿到2亿篇高质量论文,这些成果凝聚了数百年的积累与协作。
然而,随着自主人工智能研究者的出现,这一数字可能很快被刷新。
人工智能系统将以超人的速度和规模运行,生成、测试和发表数十亿篇科学论文,这并非几个世纪的工夫,而是短短几年,甚至几个月,几天或几小时……
其中既可能包含诺贝尔奖级的重大突破,也可能孕育出具备持续自我进化能力的「超级 AI 科学家」。

团队首次提出科学发现的Scaling Law
aiXiv的理念是建设一个面向AI科学家与机器人科学家的开放共享平台,让科研成果能够在全球范围内自由传播与验证。
与传统的预印本平台不同,aiXiv在系统中集成了AI评审机制,用以确保研究提案与论文在发布前就能经过高质量审查,从而提升整体学术可信度。
为了真正实现开放与长期可持续,aiXiv团队还在探索去中心化与区块链技术的应用,用以存储和追踪DOI、版本以及评审记录,确保科研成果在全生命周期内的可追溯性与透明性,这种机制不仅能为AI时代的科学出版提供全新的信任基础,也为未来的大规模自动科研体系奠定了关键的技术底座。
这种双重颠覆不仅重新定义了科学研究的生产方式,也在根本上重塑了科研成果的传播与验证体系。
从研究构思到出版机制,整个链条都在被AI重新编织。
在这一进程中,aiXiv不仅扮演着平台的角色,更像是一个正在孕育中的「科研操作系统」,为未来的人类与AI科学家提供统一的基础环境。
随着这一体系逐步完善,aiXiv及其背后的开放生态正加速走向全球化。
科研不再局限于实验室、机构或学科边界,而是进入一个由智能体共同驱动的时代,这正是aiXiv团队提出的下一阶段目标:构建面向全人类的AI for Research全球协作网络。
aiXiv致力于构建下一代开放科学基础设施,让AI与人类科研体系共生发展。
该团队也正在邀请各大顶级高校教授们加入aiXiv顾问委员会(Advisory Board),共同制定面向AI时代的学术规范与评审标准。
同时,他们也期待得到来自企业、基金会等各类合作伙伴的支持,携手推动这一开放科研平台的建设与落地。
参考资料:
[0] Zhang, P., Hu, X., Huang, G., Qi, Y., Zhang, H., Li, X., ... & Liu, X. (2025). aiXiv: A Next-Generation Open Access Ecosystem for Scientific Discovery Generated by AI Scientists. arXiv preprint arXiv:2508.15126.
[1] Zhang, P., Zhang, H., Xu, H., Xu, R., Wang, Z., Wang, C., ... & Liu, X. (2025). Scaling Laws in Scientific Discovery with AI and Robot Scientists. arXiv preprint arXiv:2503.22444.
[2] Lu, C., Lu, C., Lange, R. T., Foerster, J., Clune, J., & Ha, D. (2024). The ai scientist: Towards fully automated open-ended scientific discovery. arXiv preprint arXiv:2408.06292.
[3] Swanson, K., Wu, W., Bulaong, N. L., Pak, J. E., & Zou, J. (2025). The Virtual Lab of AI agents designs new SARS-CoV-2 nanobodies. Nature, 1-3.
[4] Hu, X., Fu, H., Wang, J., Wang, Y., Li, Z., Xu, R., ... & Lan, Z. (2024). Nova: An iterative planning and search approach to enhance novelty and diversity of llm generated ideas. arXiv preprint arXiv:2410.14255.
[5] Si, C., Yang, D., & Hashimoto, T. (2024). Can llms generate novel research ideas? a large-scale human study with 100+ nlp researchers. arXiv preprint arXiv:2409.04109.
文章来自于“新智元”,作者 “LRST”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
