# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文为Milvus Week系列第二篇,该系列旨在分享Zilliz、Milvus在系统性能、索引算法和云原生架构上的创新与实践,以下是DAY2内容划重点:
Struct Array + MAX_SIM ,能够让数据库看懂 “多向量组成一个实体” 的逻辑,进而原生返回业务要的完整结果
用向量数据库的人大概率都碰过这类问题:数据库里存的是被拆成片段的向量(比如一篇文档的段落向量、商品的单张图片向量),但业务要的是完整的实体(整个文档、整个商品)。
举几个真实场景中的案例:
知识库检索:存的是段落向量,然而用户想搜的是最相关的几篇文档,却因为搜到的多个段落匹配到的同一篇文档,导致去重后文档数量不足;
电商搜索:存的是商品图向量,结果召回的结果是同一商品的不同角度图占满检索结果,无法返回足量商品;
视频平台:存的是片段向量,导致最后搜到的都是同一部视频的不同切片;
这些问题本质上都是一回事:视角错位。数据库认为“一个向量 = 一条数据”,但业务看来 “多个向量 = 一个实体”。结果就是应用层需要额外加去重、分组、rerank,既麻烦又容易出 bug。
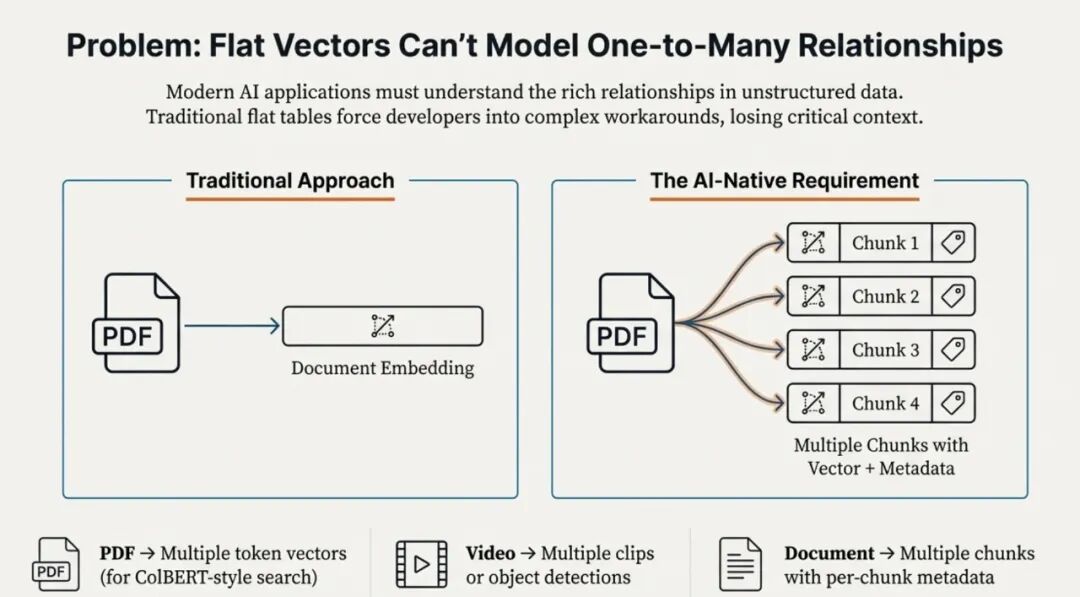
好在 Milvus 2.6.4 出了 Struct Array + MAX_SIM 功能,能够让数据库看懂 “多向量组成一个实体” 的逻辑,进而原生返回业务要的完整结果。
下面用Wikipedia 文档检索、ColPali 文档图像检索两个真实案例,做详细解读。(在本文场景中:我们用它来存储一个实体的多个向量,但它的能力远不止于此,你还能用它聚合任何类型的结构化数据。)
Struct Array 的本质,就是允许在一个字段里存储多个结构化对象(可以包含标量、向量、字符串等任意类型),然后把它们组织成一个整体。
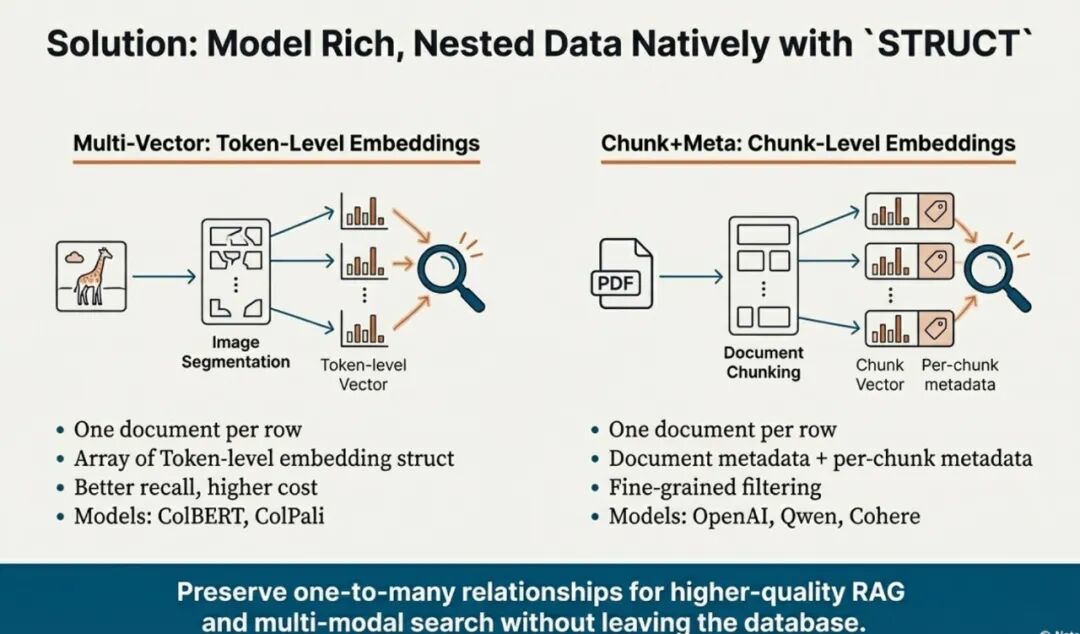
Struct Array的核心价值在于打破传统数据结构的限制:允许在单个字段中存储多个结构化对象(可包含标量、向量、字符串等任意数据类型),并将这些对象组织为一个逻辑整体。这种结构特别适用于处理 “多向量组合” 场景(如文本分词后的 embedding list)。
而 MAX_SIM(最大相似度求和)算法则是基于 Struct Array 实现语义级检索的核心实现路径 。 它解决了传统检索依赖词形完美匹配的痛点,通过向量语义相似度实现更灵活的匹配逻辑。
接下来我们通过一个案例,来详细拆解 MAX_SIM 的计算逻辑(所有向量均通过相同的 embedding 模型生成,相似度采用余弦相似度计算,取值范围 [0,1])。
假设用户输入的query是“机器学习入门课程”,由4个向量组成,"机器", "学习", "入门", "课程"。数据库中有两篇doc,[1]新手深度神经网络python实战; [2]理论进阶之大模型paper详解; 也分别tokenization后按向量储存。
我们先来计算query和doc_1的相似度。首先,我们计算query中的每个向量和doc内的每个向量之间的cosine相似度,如下表所示。
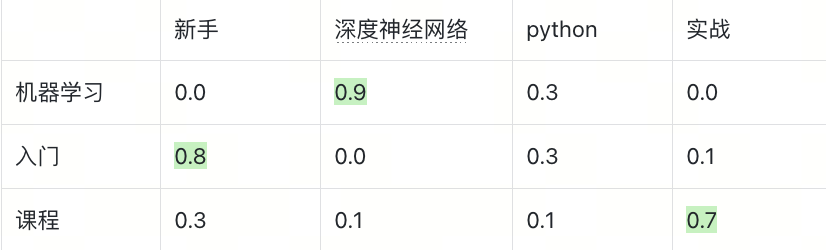
对于query中的每个向量,我们都会从doc中找到最为匹配的向量。例如query中的“机器学习”将匹配doc_1中的“深度神经网络”,“入门”将匹配“新手”,“课程”将匹配“实战”,最终query和doc_1的相似度为以上最佳匹配的相似度之和,0.9 + 0.8 + 0.7 = 2.4.
同理,我们计算query和doc_2的相似度,“机器学习”将匹配“大模型”,“入门”和“课程”都会匹配“详解”,但是我们注意到,“入门”和最佳匹配“详解”的相似度只有0.6,所以最终相似度得分只有0.9 + 0.6 + 0.8 = 2.3,低于doc_1,这符合我们的预期。
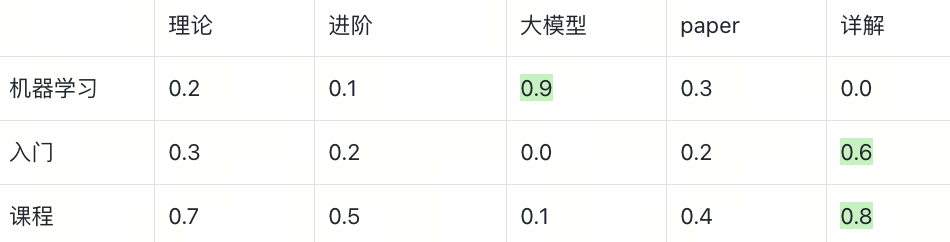
基于上述案例,可总结 MAX_SIM 的三大关键特性:
目前,Milvus 作为开源向量数据库,依托其高效的向量检索引擎,已扩展支持基于 Struct Array 的 MAX_SIM 算法:
Struct Array的核心能力概括来说,有三点:
因此,如果你的数据存在 “整体 - 部分” 结构(如一篇文章包含多个段落、一个商品对应多张图片),业务需要返回完整实体而非碎片化向量(如用户需获取文章列表而非零散段落),且正面临应用层需手动实现复杂去重、分组与重排逻辑,或是向量检索结果中同一实体反复占据 Top 位导致冗余的问题时,Struct Array 正是适配这类需求的解决方案。
在需要多向量检索的AI应用场景中尤其适合:ColBERT 模型将一个文档拆分为 100-500 个 Token 向量,适用于法律文档、学术论文的细粒度检索;ColPali 模型把一个 PDF 页转化为 256-1024 个 Patch 向量,可满足财报、合同、发票等跨模态检索场景的需求。
拿电商商品举例子就懂了:
再看知识库的场景:
目标:将段落数据转换为文档数据,实现文档级检索。
核心流程:数据分组 → 创建 Schema → 插入数据 → 创建索引 → 搜索
{
"wiki_id": int, # WIKI ID(主键)
"paragraphs": ARRAY<STRUCT< # paragraph 数组
text:VARCHAR # 每个段落的文本
emb: FLOAT_VECTOR(768) # 每个段落文本的向量
>>
}
1. 数据分组转换
数据集来源: https://huggingface.co/datasets/Cohere/wikipedia-22-12-simple-embeddings
import pandas as pd
import pyarrow as pa
# 加载数据并按 wiki_id 分组
df = pd.read_parquet("train-*.parquet")
grouped = df.groupby('wiki_id')
# 为每篇文章构建段落数组
wiki_data = []
for wiki_id, group in grouped:
wiki_data.append({
'wiki_id': wiki_id,
'paragraphs': [{'text': row['text'], 'emb': row['emb']}
for _, row in group.iterrows()]
})
2. 创建 Milvus Collection
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
schema = client.create_schema()
schema.add_field("wiki_id", DataType.INT64, is_primary=True)
# 定义 Struct Array
struct_schema = client.create_struct_field_schema()
struct_schema.add_field("text", DataType.VARCHAR, max_length=65535)
struct_schema.add_field("emb", DataType.FLOAT_VECTOR, dim=768)
schema.add_field("paragraphs", DataType.ARRAY,
element_type=DataType.STRUCT,
struct_schema=struct_schema, max_capacity=200)
client.create_collection("wiki_docs", schema=schema)
3. 插入数据并创建索引
# 批量插入
client.insert("wiki_docs", wiki_data)
# 创建 HNSW 索引
index_params = client.prepare_index_params()
index_params.add_index(
field_name="paragraphs[emb]",
index_type="HNSW",
metric_type="MAX_SIM_COSINE",
params={"M": 16, "efConstruction": 200}
)
client.create_index("wiki_docs", index_params)
client.load_collection("wiki_docs")
4. 搜索文档
# 搜索查询
import cohere
from pymilvus.client.embedding_list import EmbeddingList
# 数据集的向量是通过 cohere的 embedding 模型multilingual-22-12,query文本也需要使用相同的模型生成
co = cohere.Client(f"<<COHERE_API_KEY>>")
query = 'Who founded Youtube'
response = co.embed(texts=[query], model='multilingual-22-12')
query_embedding = response.embeddings
query_emb_list = EmbeddingList()
for vec in query_embedding[0]:
query_emb_list.add(vec)
results = client.search(
collection_name="wiki_docs",
data=[query_emb_list],
anns_field="paragraphs[emb]",
search_params={
"metric_type": "MAX_SIM_COSINE",
"params": {"ef": 200, "retrieval_ann_ratio": 3}
},
limit=10,
output_fields=["wiki_id"]
)
# 结果:直接返回 10 篇不同的文章!
for hit in results[0]:
print(f"文章 {hit['entity']['wiki_id']}: 相似度 {hit['distance']:.4f}")
效果对比:

当然,以上Wikipedia 案例展示了基础的段落检索场景。Struct Array 的真正威力在于支持各种多向量场景:
传统检索场景
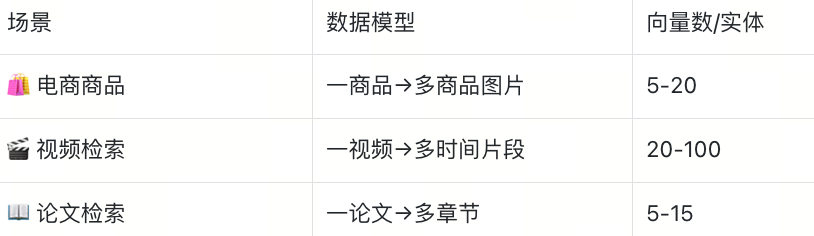
AI模型场景(重点)

ColPali 是现在做 PDF 跨模态检索的热门模型,它会把一页 PDF 切成 1024 个 Patch,每个 Patch 一个向量。要是用传统方式存,一页 PDF 得拆成 1024 行,搜的时候根本没法聚合 ——Struct Array 刚好能解决这个问题。
此外,传统 PDF 检索靠 OCR 转文本,会丢图表、布局信息;ColPali 直接从图像切 Patch,保留所有视觉和文本信息,但需要数据库能处理 “一页 = 1024 个向量” 的聚合需求。
Struct Array 在ColPali文档图像检索领域的典型场景是Vision RAG。比如:财报检索(在数千份PDF中找到包含特定图表的页面)、合同审查(从扫描的合同中检索特定条款)、发票处理(检索特定供应商或金额的发票)、 演示文稿(找到包含特定图示的幻灯片)。

{
"page_id": int, # 页面ID(主键)
"page_number": int, # 页面在文档中是第几页
"doc_name": VARCHAR, # 文档名称
"patches": ARRAY<STRUCT< # Patch数组
patch_embedding: FLOAT_VECTOR(128) # 每个patch的向量
>>
}
1. 数据准备
https://huggingface.co/vidore/colpali-v1.3
可以参考这个文档获取colpali如何将图片/文本转成多向量
import torch
from PIL import Image
from colpali_engine.models import ColPali, ColPaliProcessor
model_name = "vidore/colpali-v1.3"
model = ColPali.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="cuda:0", # or "mps" if on Apple Silicon
).eval()
processor = ColPaliProcessor.from_pretrained(model_name)
# 假设有2个文档,每个文档5页,共10张图片
images = [
Image.open("path/to/your/image1.png"),
Image.open("path/to/your/image2.png"),
....
Image.open("path/to/your/image10.png")
]
# 将图片转换成多向量
batch_images = processor.process_images(images).to(model.device)
with torch.no_grad():
image_embeddings = model(**batch_images)
2. 创建Collection:
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
schema = client.create_schema()
schema.add_field("page_id", DataType.INT64, is_primary=True)
schema.add_field("page_number", DataType.INT64)
schema.add_field("doc_name", DataType.VARCHAR, max_length=500)
# Struct Array for patches
struct_schema = client.create_struct_field_schema()
struct_schema.add_field("patch_embedding", DataType.FLOAT_VECTOR, dim=128)
schema.add_field("patches", DataType.ARRAY,
element_type=DataType.STRUCT,
struct_schema=struct_schema, max_capacity=2048)
client.create_collection("doc_pages", schema=schema)
3. 插入并索引
# 插入数据
page_data=[
{
"page_id": 0,
"page_number": 0,
"doc_name": "Q1财报.pdf",
"patches": [
{"patch_embedding": emb} for emb in image_embeddings[0]
],
},
...,
{
"page_id": 9,
"page_number": 4,
"doc_name": "产品手册.pdf",
"patches": [
{"patch_embedding": emb} for emb in image_embeddings[9]
],
},
]
client.insert("doc_pages", page_data)
# 创建索引
index_params = client.prepare_index_params()
index_params.add_index(
field_name="patches[patch_embedding]",
index_type="HNSW",
metric_type="MAX_SIM_IP",
params={"M": 32, "efConstruction": 200}
)
client.create_index("doc_pages", index_params)
client.load_collection("doc_pages")
4. 跨模态搜索:文本查询→图像结果
# 搜索
from pymilvus.client.embedding_list import EmbeddingList
queries = [
"quarterly revenue growth chart"
]
# 将查询文本转换成多向量
batch_queries = processor.process_queries(queries).to(model.device)
with torch.no_grad():
query_embeddings = model(**batch_queries)
query_emb_list = EmbeddingList()
for vec in query_embeddings[0]:
query_emb_list.add(vec)
results = client.search(
collection_name="doc_pages",
data=[query_emb_list],
anns_field="patches[patch_embedding]",
search_params={
"metric_type": "MAX_SIM_IP",
"params": {"ef": 100, "retrieval_ann_ratio": 3}
},
limit=3,
output_fields=["page_id", "doc_name", "page_number"]
)
print(f"查询: '{queries[0]}'")
for i, hit in enumerate(results, 1):
entity = hit['entity']
print(f"{i}. {entity['doc_name']} - 第{entity['page_number']}页")
print(f" 相似度: {hit['distance']:.4f}\n")
输出示例:
查询: 'quarterly revenue growth chart'
1. Q1财报.pdf - 第2页
相似度: 0.9123
2. Q1财报.pdf - 第1页
相似度: 0.7654
3. 产品手册.pdf - 第1页
相似度: 0.5231
这里的输出结果直接是 PDF 页面,我们不用管背后 1024 个 Patch 的细节,数据库已经自动搞定了聚合。
传统数据库将数据打散成一行行记录,而 Struct Array 让数据库真正支持结构化聚合:通过灵活组合标量、向量、字符串等多种类型,让一行数据真正对应一个业务实体。
这意味着,复杂的数据聚合直接应用层的工程问题变成了数据库的原生能力,而这也是数据库的长期进化方向。
作者介绍

朱文星
Zilliz Senior Software Engineer in Quality Assurance

田敏
Senior Software Engineer at Zilliz
文章来自于“Zilliz”,作者 “朱文星、田敏”。


【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
