# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
我们习惯了AI在屏幕上侃侃而谈、生成美图,好像它无所不知。但假如把它“扔”进一个真实的手术室,让它用主刀医生的第一视角来判断下一步该用哪把钳子,这位“学霸”很可能当场懵圈。
针对此类问题,EgoCross项目团队聚焦跨域第一人称视频问答评测。新工作系统揭示现有MLLM在外科、工业、极限运动与动物视角等场景下的泛化瓶颈。
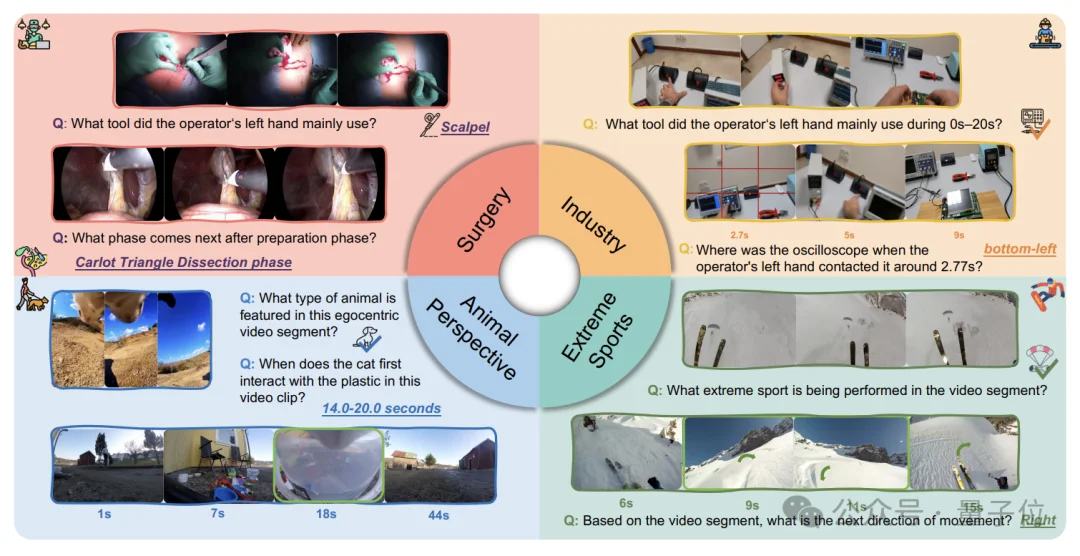
目前大多数第一人称视频基准均集中于日常生活活动,而忽略了真实世界应用中巨大的领域差异。
来自华东师范大学、INSAIT的研究团队,首次提出跨域第一视角视频问答基准EgoCross,覆盖4个高价值专业领域、包含近千条高质量QA对,同时提供闭卷(CloseQA)和开卷(OpenQA)双评测格式,彻底填补了该领域的评估空白。
同时,团队通过8款主流MLLM的全面测试,揭示了现有模型的跨域短板,并验证了微调(SFT)、强化学习(RL)等方法的改进潜力。
目前该项研究已入选AAAI 2026,所有数据集、代码已全部开源。
Egocentric Video Question Answering(EgocentricQA)的目标,是让模型在“第一视角视频+问题”的输入下,给出正确自然语言回答。
已有大量工作在这一方向取得了进展,但几乎都只在日常生活场景里评测模型:做饭、切菜、整理房间……
现实中,更具挑战的场景往往来自:
手术领域:不仅要识别“切割工具”,还需要区分“抓钳”、“手术刀”和“双极镊”等精细器械。同时,手术流程长,风险高,识别识别及预测错误带来的风险极大;
工业领域:涉及复杂的电路板维修流程和精细物体识别;
极限运动:第一视角相机剧烈抖动、视角切换频繁,画面模糊严重;
动物视角:相机随动物做不规则运动,视角高度和关注区域与人类完全不同。
这些场景在视觉风格和语义内容上都与“日常家务”大相径庭,构成天然的领域差异(domain shift)。
这引出了本研究的核心问题:
✦ 现有在日常场景上表现优秀的MLLM,能否在这些陌生领域中依然可靠?
✦ 如果不能,问题出在哪?又能如何改进?
1. 首个跨域EgocentricQA基准
2. 全面模型评估与分析
3. 前瞻性改进研究

EgoCross从五个高质量开源数据集中精选视频,涵盖四个专业领域,每个领域都设计了四类核心任务:识别(Identification)、定位(Localization)、预测(Prediction)和计数(Counting),共15种子任务,全面评估模型能力。
识别(Identification):如动作序列识别、主导手持物体识别。如“视频中是哪种动物?”“手术中未出现的器械是什么?”
定位(Localization):包括时间定位和空间定位。如“操作员何时首次接触示波器?”“螺丝刀在画面哪个区域?”
预测(Prediction):如预测下一个动作、方向或阶段。如“手术准备阶段后下一步是什么?”“极限运动的下一个运动方向?”
计数(Counting):对动态对象的计数能力。如“视频中可见多少种不同组件?”
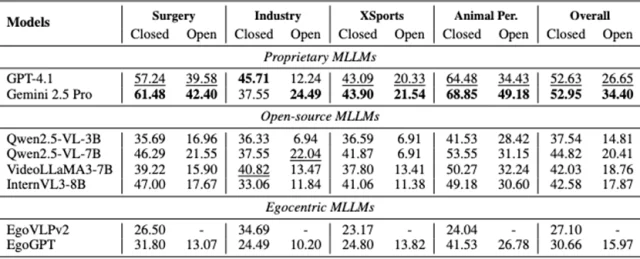
研究团队的实验揭示了几个关键发现:
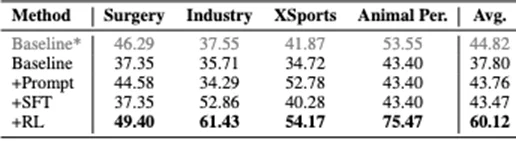
“*”表示没有vLLM加速的Baseline,由于vLLM加速会导致轻微的性能下降,因此它以灰色标记。
研究团队探索了三种改进方法:
提示学习:不改模型参数,只在推理阶段加入领域特定的提示和示例,例如在问题前增加“这是一个手术/工业/极限运动/动物视角的视频,请结合该领域特点回答”,用“提词”方式挖掘模型已有的跨域能力。
监督微调(SFT):以Qwen2.5-VL-7B为基座,在目标领域的少量标注视频问答数据上全参数微调,使模型参数适应新领域分布;在工业领域上,微调后性能相对基线提升接近20%。
强化学习(RL):基于GRPO(Generative Reward-based Policy Optimization)搭建RL框架,具体做法是:对每个问题采样多条候选回答(每条样本约8个),再用一个奖励模型判断答案是否正确并打分,以此作为奖励信号对Qwen2.5-VL-7B的策略进行优化。RL在四个领域上平均带来约22个百分点的CloseQA准确率提升,是三种方法中效果最明显的。
这些研究初步揭示了当前大模型的能力边界,为未来构建更具泛化能力的多模态系统提供了宝贵见解。
看来,要培养一个不仅会做家务、还能在专业场景“扛事”的AI助手,还需要更多沉淀。毕竟,真正的世界,可远不止厨房那么大。
论文链接:https://arxiv.org/abs/2508.10729
项目主页:https://github.com/MyUniverse0726/EgoCross
挑战赛主页:https://egocross-benchmark.github.io/
文章来自于“量子位”,作者 “EgoCross团队”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
