# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近刷到了 Macaron 发布的一条技术视频。
本以为是常规的产品宣传片,结果看到一半发现不太对——视频里开始讲 1T 参数模型上的 LoRA 强化学习训练、Memory Diffusion 记忆机制,技术浓度远超预期。
更有意思的是视频结尾藏了个彩蛋:社交功能、Daily Spark、记忆打通,几个产品更新一笔带过,但每一个拎出来都值得单独聊聊。

看完之后我的感觉是,这次更新的信息量,比表面看起来大得多。
社交功能、Daily Spark、记忆打通——如果只是当作常规的功能迭代来看,可能会错过一些更重要的东西。
这次更新背后,其实藏着 Personal AI 这个品类正在发生的几个关键变化。
更值得关注的是,Macaron 背后的研究团队 Mind Lab 也正式亮相了。一个成员来自 OpenAI、DeepMind、Seed 的团队,刚刚做了一件让开源社区相当兴奋的事——全球首个在 1T 参数模型上实现基于 LoRA 的高效 RL 训练。
产品更新和技术突破同时放出,这个节奏本身就值得拆解一下。
这次更新最值得关注的变化,是 Macaron 开始做社交了。
不是那种「分享到朋友圈」的伪社交,而是真正把多人协作场景做进了产品核心。
具体来说,现在你可以在 Macaron 里建群,拉上朋友一起用。马卡龙会作为群成员参与对话,帮你们整理讨论要点、生成 Mini-App、设置提醒。你和朋友可以共同编辑同一个小应用,数据实时同步。
这个功能设计背后的产品判断很清晰:
Personal AI 的「Personal」,不应该只是「我一个人用」,而是「以我为中心的关系网络」。
如果你关注 AI 社交这个方向,会发现这和 Second Me 的思路有相似之处——都在试图让 AI 成为人与人之间的连接器,而不仅仅是单点的效率工具。
区别在于,Second Me 是让 AI 分身代替你去社交、去破冰;Macaron 是让 AI 作为第三方参与到你和朋友的真实互动中。
前者解决的是「社交启动成本」,后者解决的是「社交持续价值」。
从产品形态上看,Macaron 的社交更像是一个「共享工作区」的概念——朋友之间共同维护一个旅行计划、一个减脂打卡表、一个观影清单,AI 在其中扮演助理和协调者的角色。
这让我想到一个问题:
当 Personal AI 开始处理多人场景,它的记忆机制、上下文管理、权限设计,都会变得更复杂。Macaron 目前的方案是把群聊和 Mini-App 做了打通,群成员可以共同编辑同一个应用,AI 能同时理解多个用户的上下文。
这个技术实现的细节,后面会聊到。
第二个值得关注的更新是 Daily Spark。
表面上看,这是一个每日推送功能,和 ChatGPT 的 Pulse 类似。
但有个关键区别:ChatGPT Pulse 只对 200 美金的 Pro 用户开放——因为基于记忆做个性化总结的成本很高。而 Macaron 的 Daily Spark 对所有用户免费。
能做到这一点,是因为 Macaron 底层的记忆系统足够高效(后面会聊到 Memory Diffusion)。
不过更重要的差异,还是在设计哲学上。
Pulse 本质上是一个 AI 驱动的新闻聚合器——它收集热点信息,用 AI 做摘要,然后推给你。内容是「世界发生了什么」。
Daily Spark 的逻辑不一样。它会根据你在 Macaron 里的历史记录——你的情绪日记、你的兴趣偏好、你最近关注的话题——生成专属于你的内容。推送的不是「世界发生了什么」,而是「这个世界和你有什么关系」。
从技术角度看,这里的关键是记忆打通。
之前 Macaron 有一个明显的架构问题:Mini-App 和主对话是割裂的。你在「饮食记录」里记了今天吃了什么,但在聊天里问马卡龙「我这周摄入了多少卡路里」,它答不上来。数据在 App 里,但不在 AI 的上下文里。
这次更新把这层打通了。
你在任何 Mini-App 里记录的数据,都可以被 AI 在对话中调用。情绪日记、健身记录、旅行计划——所有这些「生活碎片」,都变成了 AI 可以理解和推理的上下文。
这直接影响了 Daily Spark 的效果:
它不是基于一个通用的推荐算法给你推内容,而是基于你在 Macaron 里积累的所有数据,做个性化生成。
如果你最近情绪记录里连续几天写了「有点累」,它可能会推一条治愈向的内容;如果你上周在不断和它聊 MBTI,它可能会给你推荐更多 MBTI 的内容。

这让我想到一个更大的问题:
Personal AI 的核心壁垒,可能不是模型能力,而是对用户的理解深度。
当你在一个 AI 产品里积累了足够多的生活数据——情绪、习惯、偏好、社交关系——这些数据本身就构成了一个难以迁移的护城河。
Macaron 通过 Mini-App 这个机制,其实在做一件事:让用户主动、持续地向 AI 输入结构化的生活数据。
这比被动抓取聊天记录的 Memory 方案,数据质量要高得多。
接下来是技术部分。
这次 Macaron 更新的同时,背后的研究团队 Mind Lab 也正式亮相了。

先说团队配置:
10 人核心研究团队,成员来自 OpenAI、DeepMind、字节 Seed。创始人Andrew是 MIT 背景,现在在清华深研院任研发中心主任。团队合计发表 200+ 篇论文,被引用超过 30,000 次。
这个配置在国内 AI 创业公司里算是顶级的。
更值得关注的是他们最近的技术突破:
全球首个在 1T 参数模型上,实现基于 LoRA 的高效强化学习训练。
这是什么意思?
目前主流的大模型后训练(Post-training)方法,主要有两条路:
1. 全参数微调:效果好,但需要海量 GPU 资源,成本极高;
2. LoRA:参数高效,成本低,但在大规模模型上做 RL 训练一直有技术瓶颈。
第二条路线的难点在于:LoRA 本身是为高效微调设计的,但当你想在千亿甚至万亿参数的模型上跑强化学习,原有的架构很难撑住。
目前全球能在这个量级上把 LoRA + RL 跑通的,只有两家:一家是 Thinking Machines Lab,另一家就是 Mind Lab。
Mind Lab 的方案是在 1T 参数的 MoE 架构上实现了这套训练流程,而且只用了传统方法 10% 的 GPU 资源。
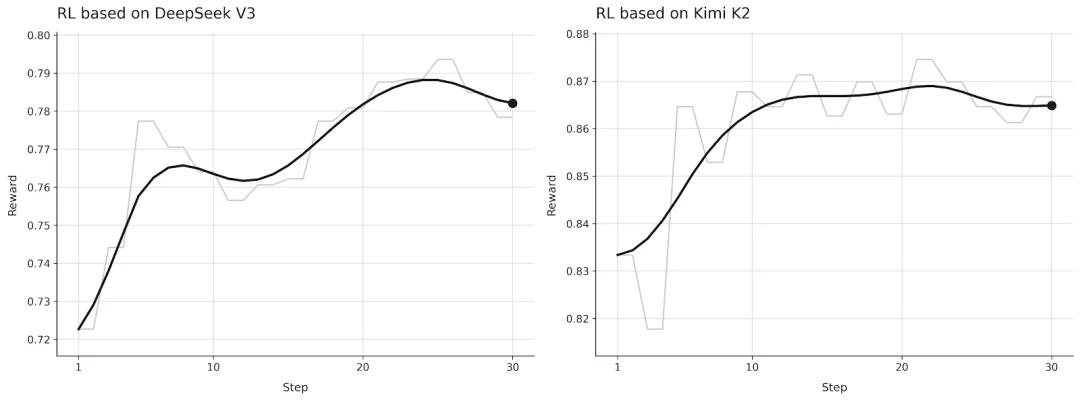
他们在 1T 参数级别的 MoE 架构模型上,成功跑通了基于 LoRA 的强化学习训练,而且只用了传统方法10% 的 GPU 资源。
这意味着什么?
原本需要千张卡才能做的大规模后训练,现在可以用百张卡搞定。对于资源有限的创业团队来说,这是一个巨大的成本突破。
这套方案已经开源,并被 NVIDIA Megatron-Bridge 和字节 Seed verl 官方合并——这在开源社区是相当高的认可度。
说句题外话:强化学习的训练成本一直是中小团队的噩梦,很多产品公司想做 RL 但根本烧不起那个 GPU。Mind Lab 这套方案如果能降低行业的整体门槛,让更多团队都能跑得起强化学习,对整个生态都是好事。
期待他们后续能放出更完整的技术文档和实践指南。
除了训练效率的突破,Mind Lab 还提出了一个很有意思的概念:Memory Diffusion。
这是他们设计的一种新型记忆机制,核心理念和传统方法完全不同。
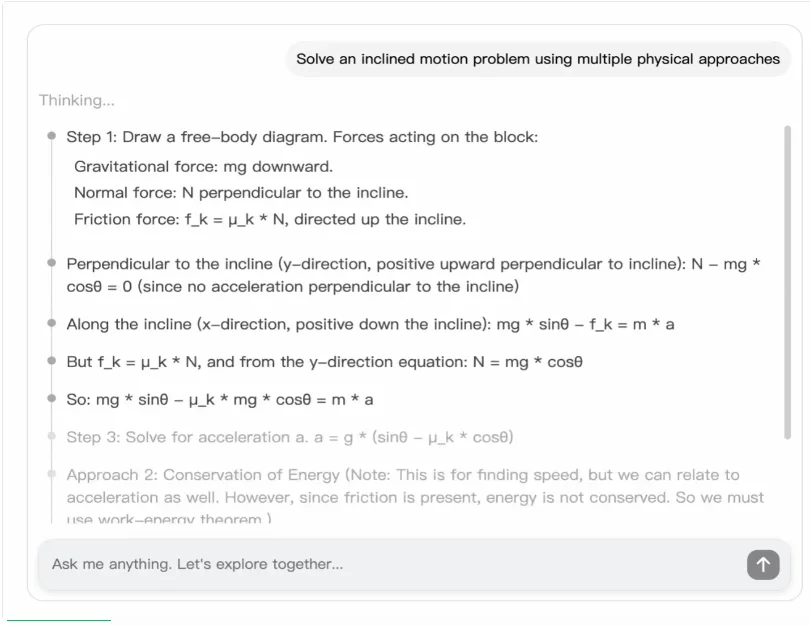
传统的 AI 记忆方案,基本思路是「尽可能记住一切」。然后通过各种 Context Engineering 技术——RAG、压缩、摘要——来管理不断膨胀的上下文。
Mind Lab 的思路相反:
Memory isn't about remembering everything. It's about forgetting wisely.记忆不是记住一切,而是智慧地遗忘。
他们用了一个很直观的类比:
人开车上班的时候,会瞬间遗忘路过的广告牌、无关的行人、不重要的细节,只保留目的地、关键路口这些核心信息。大脑是一个高效的信息过滤器,而不是一个无限容量的硬盘。
Memory Diffusion 试图让 AI 学会这种「选择性遗忘」的能力。
从技术角度看,这是一种用于自回归 LLM 轨迹的新型序列建模方法。它不是在 Context 层面做工程优化,而是在模型层面让 AI 学会判断什么信息值得保留、什么应该丢弃。
这和 Karpathy 最近的观点有呼应。他提到:
"Human thought naively feels a bit more like autoregression but it's hard to say that there aren't more diffusion-like components in some latent space of thought."
人类思维可能并不是纯粹的自回归,在某些潜空间里可能存在类似 Diffusion 的成分。
Memory Diffusion 算是这个方向上的一次实验。
聊了这么多底层技术,最后回到产品体验层面。
这次更新有一个很直观的变化:Mini-App 的生成时间从 20 分钟缩短到了 2 分钟。
这不是简单的工程优化 —— 加个缓存、优化下代码路径 —— 能做到的。
20 分钟到 2 分钟,是量级上的变化。背后是模型推理效率的真正提升。
Mind Lab 的说法是,这直接受益于他们在强化学习训练效率上的突破。更高效的训练方法,产出了更高效的模型。
这让我想到一个经常被忽视的问题:
AI 产品的技术壁垒,可能不在于你用了多强的基座模型,而在于你能否基于场景做高效的定制化训练。
大家都能调用 GPT-4、Claude 3。但谁能在自己的场景里,用更少的资源、更快的速度,训练出更好的专用模型——这才是真正的差异化。
Mind Lab 给出的答案是:不从头做预训练,而是在强大的基座模型之上,通过高效的 RL 方法做 Agentic 扩展。用真实用户的反馈做训练信号,形成「Research Product Co-Design」的飞轮。
他们把这条路线叫做 Experiential Intelligence —— 经验智能。
把这次更新的几个信号串起来,能看到一条比较清晰的产品路径:
从单人工具 → 多人协作从孤立记忆 → 全局上下文从通用推送 → 个性化理解从调用模型 → 定制化训练
Macaron 试图构建的,不是一个更聪明的聊天机器人,而是一个真正理解你、记住你、能和你的朋友们一起互动的 AI 伙伴。
这需要解决的技术问题很多:多用户场景下的记忆管理、跨 App 的上下文打通、高效的个性化训练方法。
Mind Lab 的亮相,至少说明 Macaron 在技术层面是有储备的。
至于这条路能走多远,可能还需要更多时间来验证。
但从这次更新来看,Personal AI 这个品类,正在变得比我们想象的更有意思。
网站:macaron.imiOS:App Store 搜索「Macaron AI」安卓:官网直接下载 APKMind Lab 技术文档:macaron.im/mindlab
文章来自于“特工宇宙”,作者 “宇宙编辑部”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
