# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在 Physical Intelligence 最新的成果 π0.6 论文里,他们介绍了 π0.6 迭代式强化学习的思路来源:

其中有我们熟悉的 Yuke Zhu 的研究,也有他们自己(Chelsea Finn、Sergey Levine)的一些研究,我们之前对这些工作一直有跟踪和介绍。此外,还有来自国内具身智能团队的工作,比如清华大学、星动纪元的研究。随着 π*0.6 的发布,VLA+online RL 成为了一个行业共识的非常有前景的研究方向(深扒了Π*0.6的论文,发现它不止于真实世界强化学习、英伟达也来做VLA在真实世界自我改进的方法了)大语言模型从SFT到RL的发展方向也逐渐在具身研究中清晰明朗。

图注:VLA模型依赖研读微调
在具身智能(Embodied AI)领域,科学家们正在尝试将强大的视觉-语言模型(VLM)应用到机器人的底层控制中,这就是所谓的VLA模型。通常,这些模型是通过模仿人类专家的示范数据(监督微调,SFT)来学习的。

图注:模仿学习的局限
但是,仅靠模仿是不够的。如果机器人遇到了从未见过的情况,或者专家数据不够完美,机器人就会不知所措。
而正如我们在深扒了Π*0.6的论文,发现它不止于真实世界强化学习所说的,模仿学习能让机器人成功做出动作,但是让它每次都成功是非常难的。如果想让机器人非常鲁棒、持久的工作,需要借助强化学习的力量。相较于离线强化学习通常受限于演示数据的质量,模型很难超越提供数据的专家,在线 RL 允许智能体通过试错来发现更优解。
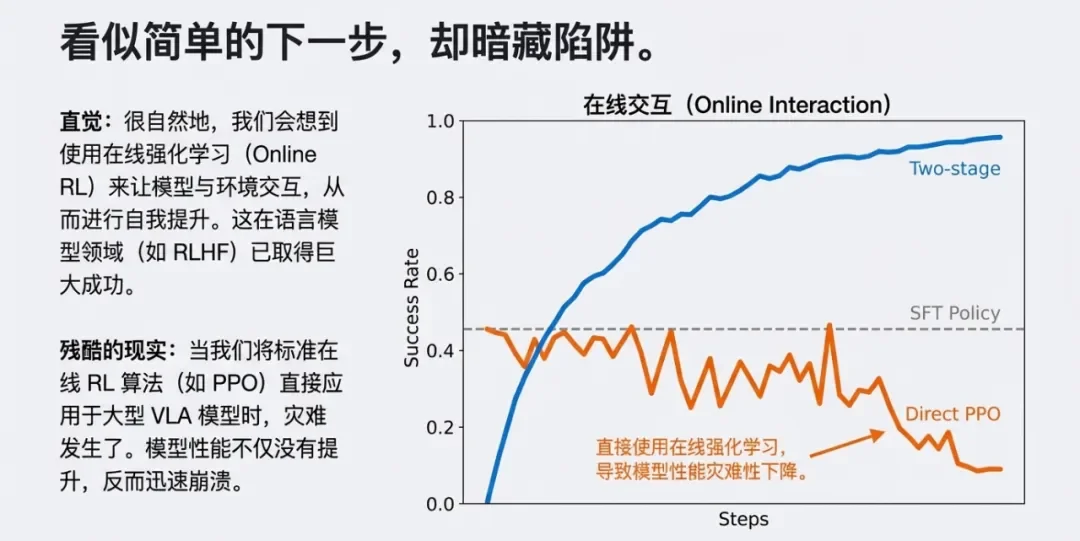
图注:VLA RL的难点
理论上,强化学习(RL)可以让机器人通过与环境互动、试错来持续进步,但是这其实不是一件容易的事情。
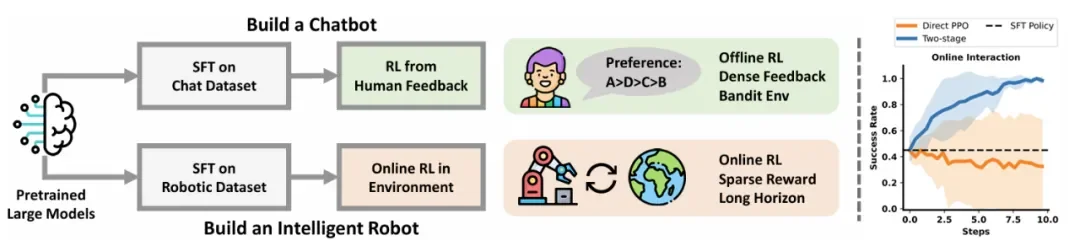
图注:LLM和具身在RL上的区别
将类似 GPT 这样的大模型与强化学习结合(如 RLHF)在聊天机器人领域非常成功,但在控制物理机器人时却困难重重:
对于VLA的强化学习困境,行业内其实有三种类型的解决方案:
这两篇文章代表了第三种路径。它们不再盲目地套用 RL 算法,而是利用监督微调(SFT)将 RL 探索出的高价值行为(成功轨迹或高优势动作)稳定地内化为模型的原生能力。
π*0.6 不在此详细赘述。我们来看下 iRe-VLA。

iRe-VLA 的作者设计了一个两阶段循环迭代的学习流程。这个流程的核心思想是:分而治之,动静结合。
VLA 模型由两部分组成:
VLM 主干(大脑):使用预训练的大型视觉-语言模型(如 BLIP-2),负责理解图像和指令,拥有丰富的世界知识。
Action Head(四肢):一个轻量级的动作输出层(由 Token Learner 和 MLP 构成),负责将 VLM 的深层特征转化为具体的机器人控制信号(如机械臂的移动、夹爪的开合)。
为了提高效率,作者还使用了 LoRA(低秩适应)技术,避免全量微调所有参数。
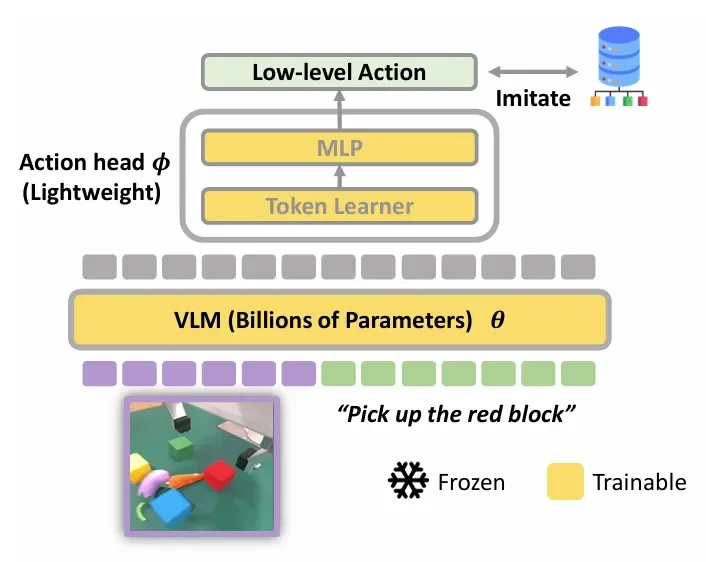
图注:模型架构
iRe-VLA 方法不是一次性训练,而是在以下两个阶段中反复迭代:

图注:稳定探索
在这个阶段,机器人的目标是去试错,探索如何完成新任务。
在第一阶段,机器人可能只是碰巧学会了操作,为了让这种能力真正融入模型,需要进行第二阶段。
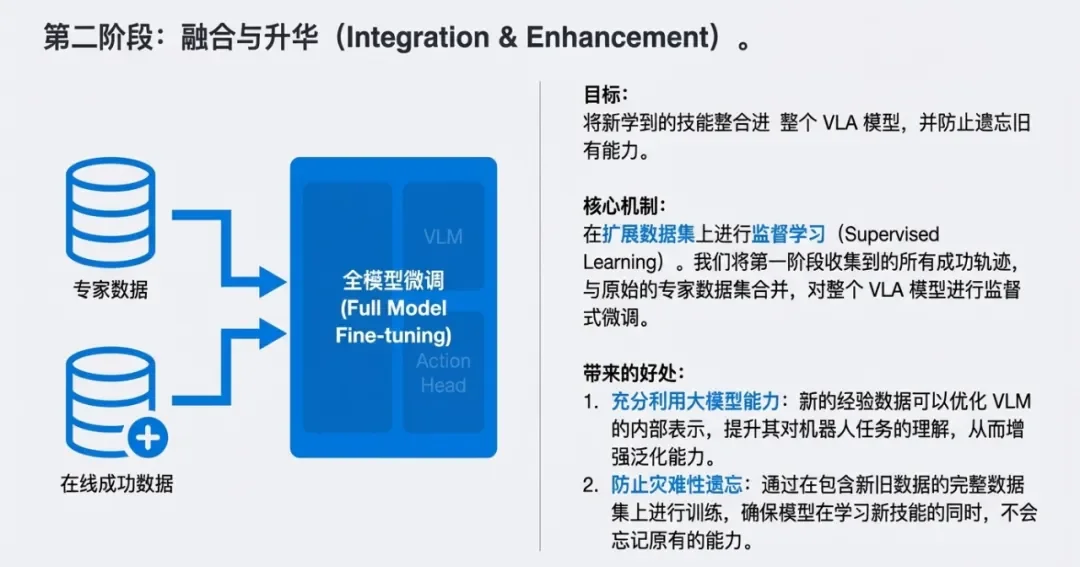
图注:融合与升华
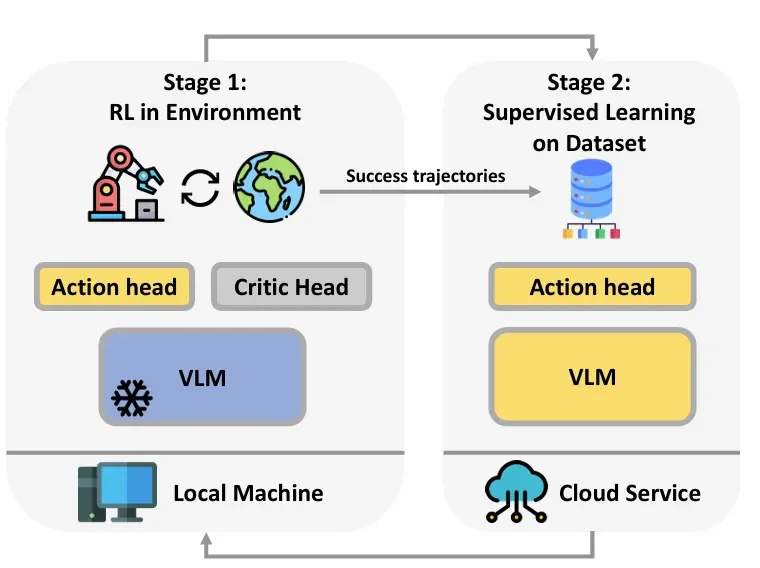
图注:两阶段
总结:机器人先在“小参数模式”下大胆探索(阶段1),找到方法后,再在“全参数模式”下把经验固化到大脑中(阶段2),如此循环往复。
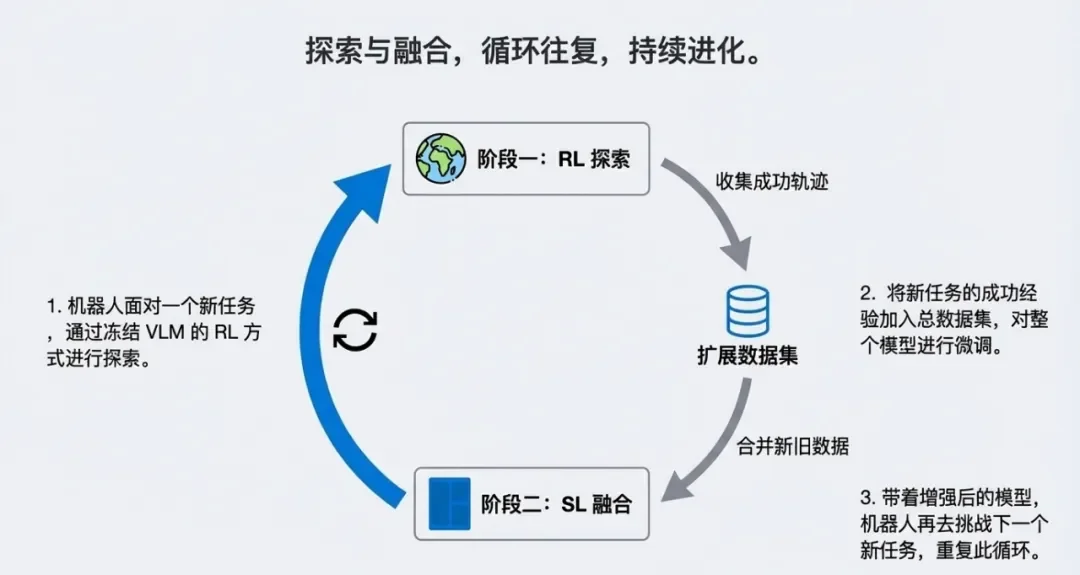
图注:循环往复
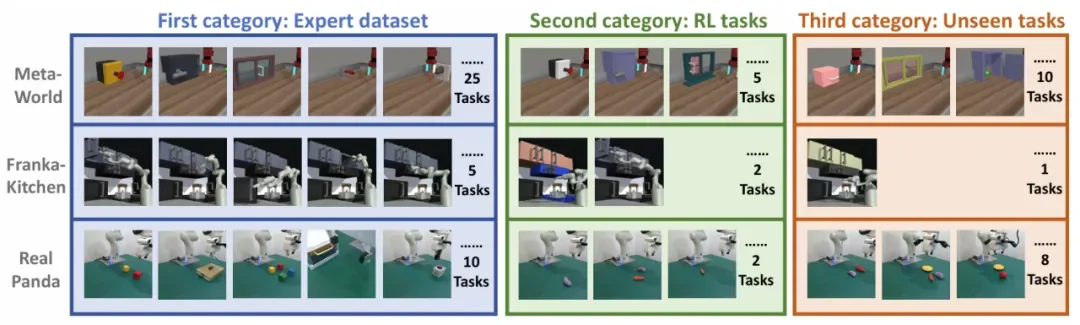
图注:三种情况的实验结果分析
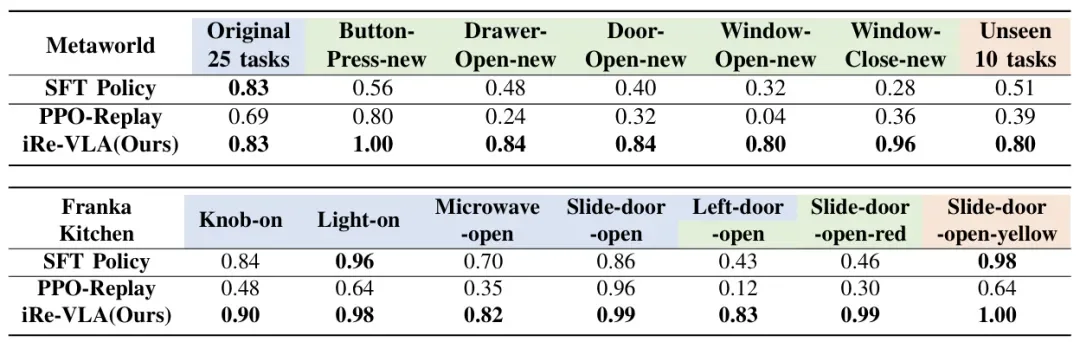
作者在仿真环境(MetaWorld, Franka Kitchen)和真实世界(Panda 机械臂)中进行了大量实验,验证了该方法的有效性。
实验显示,如果使用标准的 PPO 算法直接微调 VLA 模型,成功率曲线震荡剧烈,甚至在很多任务上性能下降(变差了)。而 iRe-VLA 的曲线则稳步上升,证明了“分阶段冻结参数”对于稳定训练至关重要。
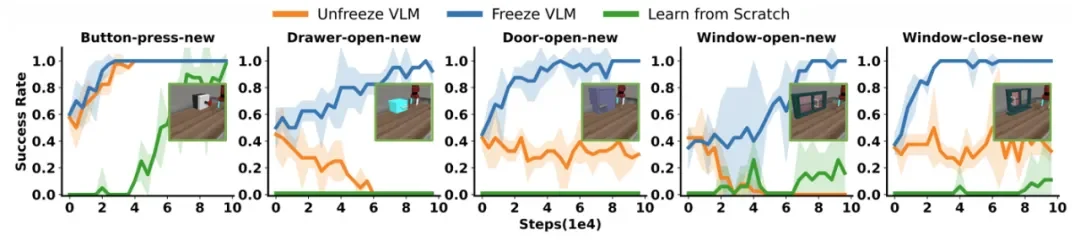
图注:曲线对比
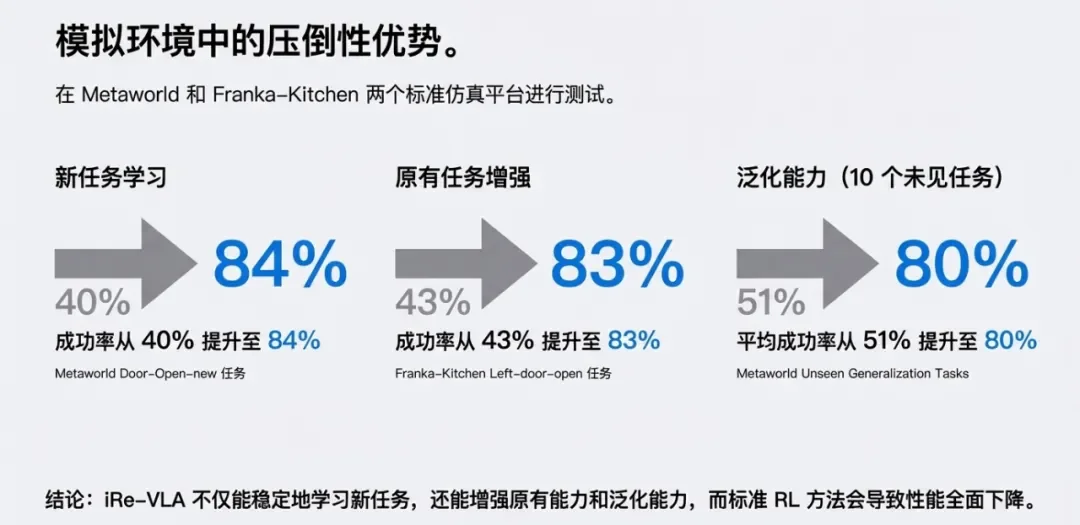
图注:仿真环境中具备压倒性优势
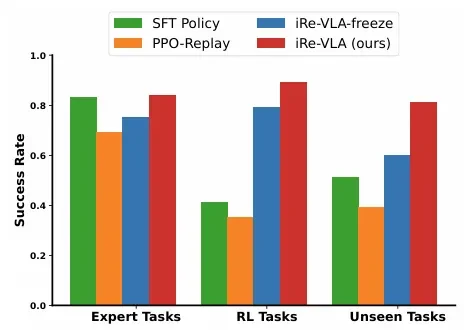
MetaWorld & Franka Kitchen:在这些基准测试中,iRe-VLA 不仅在原本学过的任务上表现更好(例如从 43% 提升到 83%),还能通过在线探索学会完全没见过的任务。
对比 SFT:相比仅进行监督微调的模型,经过 iRe-VLA 迭代后的模型在所有任务类别(专家任务、RL 训练任务、未见过的测试任务)上的成功率都有显著提升。
图注:不同后训练策略的对比
这是最令人印象深刻的部分。作者让机器人去抓取它从未见过的物体(如形状不规则的茄子、胡萝卜)。
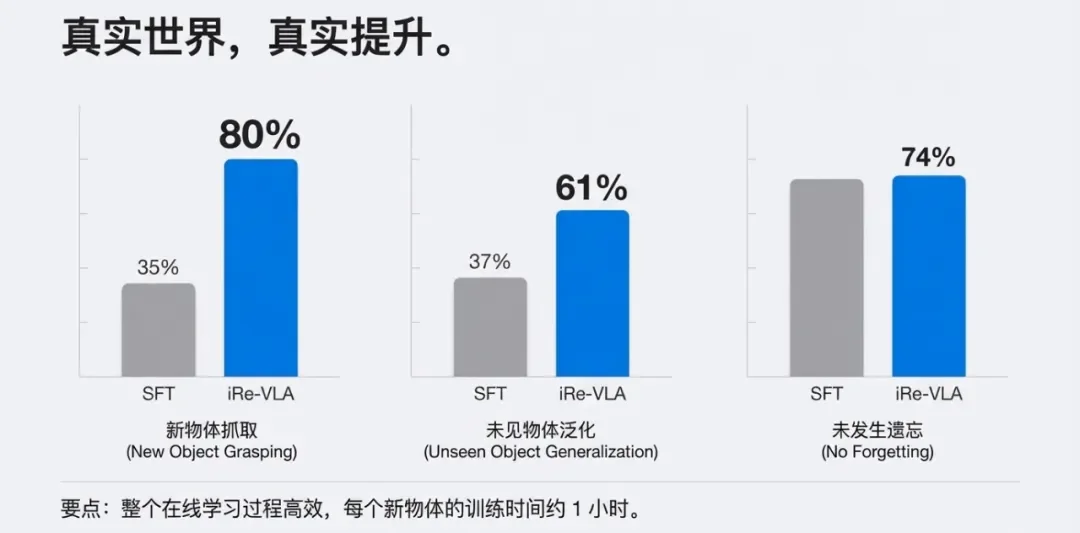
图注:真实世界的提升
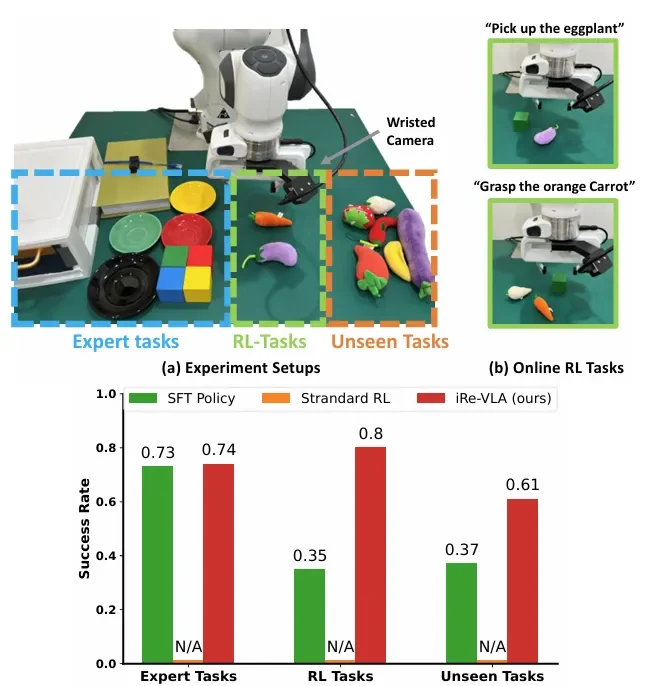
图注:实验和成功率
作者做了一个对比实验:如果在第二阶段依然冻结 VLM,只训练 Action Head(即 iRe-VLA-freeze),效果如何?
结果显示,如果不解冻 VLM,模型的性能提升会遇到瓶颈。这证明了在第二阶段解冻大模型参数是必要的,这样才能利用大模型深层的特征表示能力来彻底掌握复杂技能,并提升泛化性。
图注:消融实验
这篇文章提出了一种切实可行的方案,解决了大模型在机器人控制中落地难的问题。
图注:该架构的优点
国内的星动纪元的iRe-VLA 的基础上,海外的PI π*0.6,都为我们揭示出了VLA在线强化学习技术的发展前景。这条路还有很多未尽的研究话题,比如如何高效探索与稀疏奖励下的新技能学习,如何面向大规模 VLA 构造稳定可扩展 RL 算法等。
未来发展,我们拭目以待。
文章来自于“机器之心”,作者 “机器之心编辑部”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
