# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
坏了,阿里这波是冲着Sora 2去的!
刚刚,阿里发布了新一代通义万相2.6系列模型,一次性覆盖文生视频、图生视频、参考生视频,以及图像生成和文生图,是目前全球功能最全的视频生成模型。
在视频创作上,万相2.6不仅推出了Sora2目前还没有的多音频驱动生视频能力,还同步引入了音画同步、多镜头叙事等能力。
像下面这个超火的一刀切ASMR,就是通过文本+音频直接驱动出来的:

再看这个由文本+图像+音频驱动的小猫沉浸式吃播,咀嚼声和嘴部动作基本能卡在点上,吃得那叫一个香:

文生图这条线也同步补强了,万相2.6在艺术风格控制、真实感人像、中英文长文本生图以及历史文化IP语义理解等方面的创作能力也都有明显提升,效果be like:

本着啥都测测的原则,我也专门用不同Prompt和参考素材实测了一轮,总的来说:
万相2.6在音视频参考、声画同步、风格理解方面表现确实不错,但在个别场景下仍会出现画面逻辑偏差的小问题,不过对日常短视频和二创来讲,已经是可用且好用的水平了。
模型到底表现如何,咱们边唠边测~
实测之前,我先帮大家快速捋一下这次万相2.6在视频生成上的几个核心升级点:
啧啧啧,说实话这次更新的能力维度确实蛮多,模型到底能不能打,咱们一一测测看!!!

先来测这次升级中我自认为最大的看头——视频参考生成功能。
这不最近快到年底了,各路短视频主播都在摩拳擦掌准备冲一波年终销量,我索性脑洞一开,直接把一段梵高的视频喂给了万相2.6,让梵高也趁年底一起冲一波KPI!
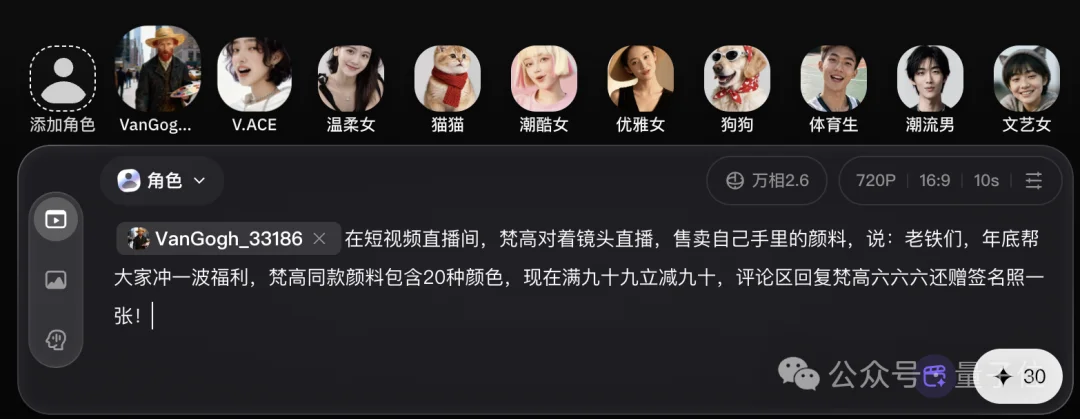
咱从主体一致性和声音一致性两个点来看效果。
整体表现是值得肯定的,万相2.6在视频主体一致性和提示词理解上确实做得比较扎实,梵高形象基本实现了1:1还原,口型匹配也较为准确,人物的动作、表情与台词语义能够对应得上,整体观感比较完整~
唯一的小瑕疵在声音上,生成结果中的声线并没有完全沿用原视频,有点AI自由发挥的意思。

咱们再来试试声画同步能力,最近二创兵马俑的AI玩法视频超级火,咱这次直接给万相2.6上点难度,让它roll一段双人剧情演绎的兵马俑对话小视频,看看效果咋样!
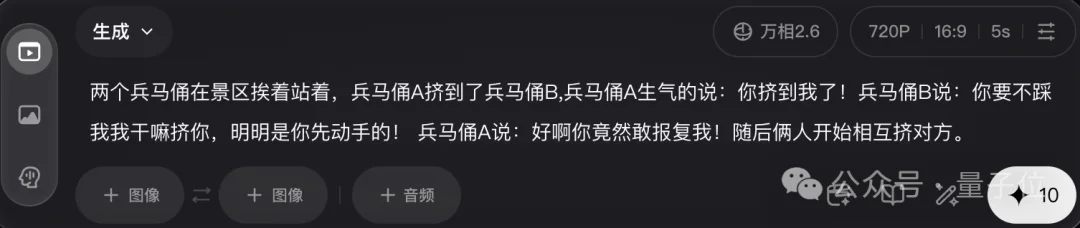
从下面生成的效果看,确实喜感满满,两尊兵马俑在相互推搡的同时进行对话,动作与语言形成了较为完整的互动。
颇有趣味的是,两尊兵马俑一边推搡一边对话,动作和语言形成了完整互动,更关键的是,模型不仅补全了台词,还加了和动作匹配的拟声细节,并能区分不同角色的情感变化,“愤怒感”的情绪还是立得住的~

再来玩点有意思的,这回我给了万相2.6一段小猫小狗对话的台词,让它帮我生成一段相声表演,效果be like:

整体来讲,声画同步效果确实做到位了,但也暴露了一些小bug:比如小猫说了本该是小狗的台词,最后一个镜头字幕和语音没完全对齐,模型在多角色绑定上还有提升空间。
除了音视频参考和声画同步能力外,万相2.6在画面质感和美学呈现方面也有了不少提升,比如下面这段我生成的第一人称赛博城市飞行视角的视频:
第一人称视角,无人机高速飞行视角,夜晚赛博朋克城市,密集高楼林立,霓虹灯与全息广告在两侧快速掠过。镜头低空穿行于城市街道与高架之间,连续急转弯、俯冲与拉升动作,掠过悬浮屏幕、楼宇天桥与空中管线。城市灯光在镜头边缘产生运动模糊,玻璃幕墙反射出飞行轨迹,雨后路面泛起冷色反光。整体节奏紧凑、速度感强,画面稳定但具有真实飞行惯性,科幻感强烈,偏冷色调,高对比度,电影级画面质感。

从视频生成效果看,飞行视角、快速掠过、急转弯、俯冲拉升这些关键词都呈现到位了,而且确实赛博感满满,有点末日大片的感觉,看来这AI还是有点美学天赋的。
最后我们来测一把万相2.6的多镜头叙事能力,这次我交代给AI的任务是让它生成一个包含3个镜头的多动作剧情视频:

从生成效果来看,万相2.6对多镜头叙事的理解较为到位,三个镜头中的主要动作和转场均得到了完整呈现,镜头之间的衔接也相对自然,并未出现明显生硬的跳切。

但由于提示词中对具体场景描述不够充分,像「探头观察」这类较为抽象的动作,对模型来说仍存在一定理解难度,以至于大家会发现视频中的男子是对着墙面观察的,还是有点不太符合正常人的动作逻辑,大家在写多镜提示词时可以多给AI一些补充信息~
除了视频能力外,这次万相2.6在图片生成功能在美学理解、人像生成、文字处理、历史文化&知识ip语义理解上也带来了一些新升级。
咱们先来说说风格化能力,其实风格化生成对于AI来说不是难事,但难就难在AI能不能及时掌握一些新的美学风格。
最近我在社交软件上刷到星露谷风格插画很火,我们也让万相2.6做个同款风格的插画看看效果~
星露谷风格,地铁上坐满站满了各种打工人,有的人忙着用电脑打字,有的人忙着打电话,有的忙着听音乐等等,展现出不同的车厢人物状态。

高饱和的色块拼接、稍许像素风的处理确实有星露谷内味儿了,而且还有点像最近短视频特火的蒸汽波风插画vlog~
再来试试「人像生成」能力,官方介绍说这次万相2.6在人像光影方面的处理也更好了,我们来roll一把!
年轻男性半身人像,室内窗边场景。侧前方自然光照亮面部,明暗过渡柔和,轮廓立体;背景压暗,肤质真实,电影级摄影光影质感。

整体生成效果不错,光影表现是亮点。侧窗光形成了清晰的明暗分区,面部结构被很好地勾勒出来,肤质细节自然,没有明显过度磨皮,画面还是有较强的电影感和空间层次的~
最后再来浅浅测一下中英文处理能力,咱们直接让万相2.6生成一个中英文对照排版的美食宣传海报!
中式餐厅宣传海报,纵向构图,中英文排版,海报主体为一碗热气腾腾的招牌菜,背景干净。海报文字内容如下:中文主标题:“招牌牛肉面”,英文副标题:“Signature Beef Noodles”,中文副文案:“每日现熬汤底 · 新鲜食材”,英文副文案:“Fresh ingredients, slow-cooked broth”文字排版清晰,中文在上,英文在下,层级分明,整体风格温暖、有食欲感,适合餐厅宣传海报。

其实对于这张图而言,最难的不是中英文生成,而是构图排版,对于美食海报来说,主体占比最大的一定是食物本身,从输出效果看,模型在美学判断上是靠谱的,这一张已经完全达到成品水准。
这波整体测下来,万相2.6给我的最直观的感受就是:有小瑕疵,但是整体表现还不错的。
毕竟,有些地方它确实还会犯迷糊,比如多角色台词偶尔对不上、复杂动作理解有时不到位,但声画同步、视频参考这些核心能力已经挺稳了。
至少对我这种平时做点视频、二创、测试玩法的人来说,这一代已经是敢多跑几次、不用每次都碰运气的状态了。
除了刚才测到的一些能力外,万相2.6在多图融合、美学要素迁移、历史知识语义理解上也做了提升,感兴趣的朋友可以直接去官网试试~
文章来自于“量子位”,作者 “梦瑶”。


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
