# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
谷歌是真的底蕴深厚啊~
刚刚在「大模型」领域用Gemini 3 Pro➕Flash重挫了OpenAI锐气后,马不停蹄继续在端侧「小模型」发力!
昨天夜里,一口气又放出新的两个技术博客,全是和端侧相关的。
一个是T5Gemma 2,一个专门的底层架构创新,首个多模态长上下文码器-解码器模型开源,最小是270M–270M。
另一个是FunctionGemma,专为函数调用优化的270M(2.7亿参数)模型,可在手机、浏览器及其他设备上运行。


T5Gemma 2和FunctionGemma都来自Gemma 3家族,相对于Gemini这种「大模型」,Gemma就是「小模型」。
这两个虽然都是小模型,但是他们的关系有点类似同门师兄弟,但专攻方向不同。
T5Gemma 2专注于架构效率与多模态(Encoder-Decoder架构回归)。
而FunctionGemma专注于智能体与工具使用(Function Calling能力)。
T5Gemma 2和现在流行的LLM的架构不同,可以理解为AI技术领域「另一条路」。

论文地址:https://arxiv.org/pdf/2512.14856
谷歌开源了T5Gemma 2:270M–270M、1B–1B以及4B–4B三种规模的预训练模型。
开源地址:https://huggingface.co/collections/google/t5gemma-2
FunctionGemma则是技能变体,它是对模型「技能」的专项训练。
有点类似把一个大模型里所有知识类的能力都剥离掉,只保留针对性的函数调用功能。

开源地址:https://blog.google/technology/developers/functiongemma/
T5Gemma系列深层技术解析
先看下T5Gemma 2这种「新结构」的优势:

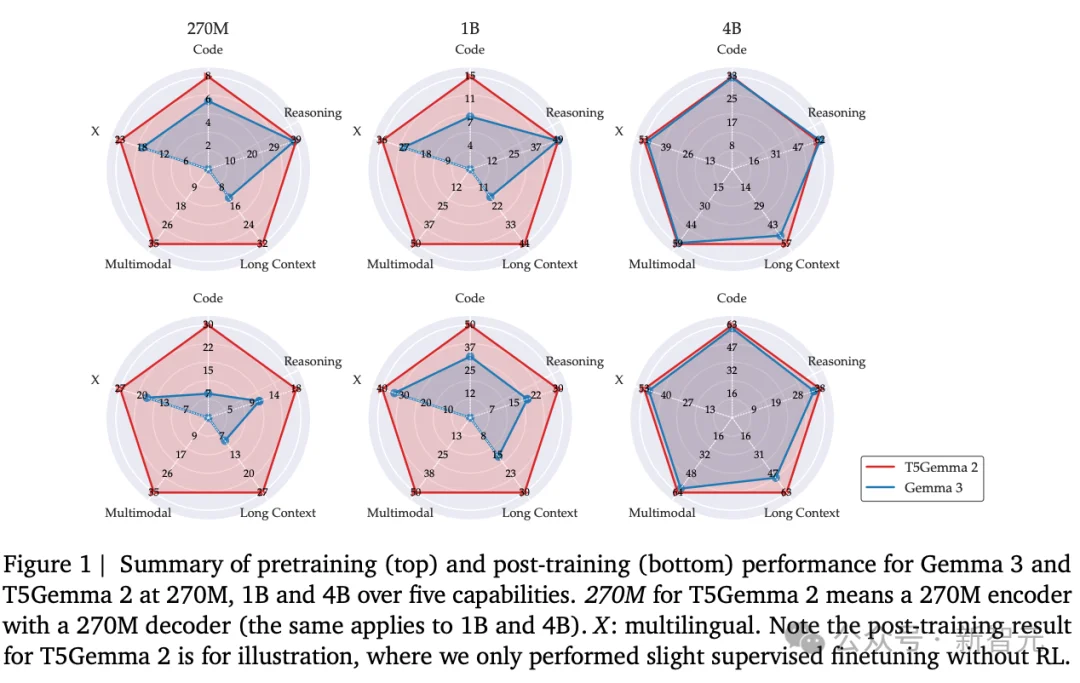
与T5Gemma类似,T5Gemma 2在预训练阶段的性能或超过Gemma 3对应体量模型,而在后训练阶段则取得了显著更优的表现。
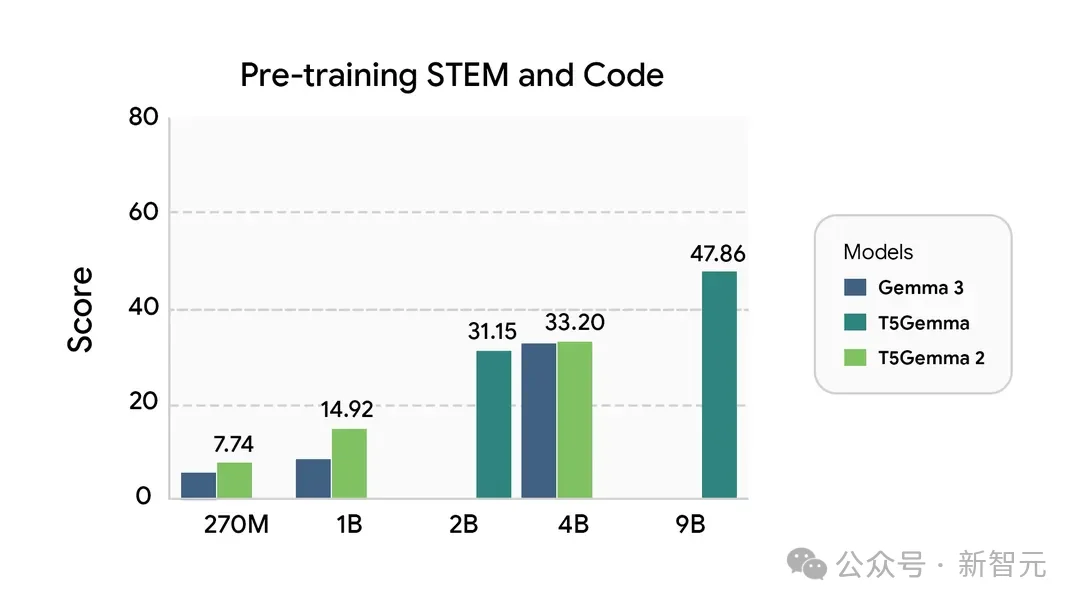
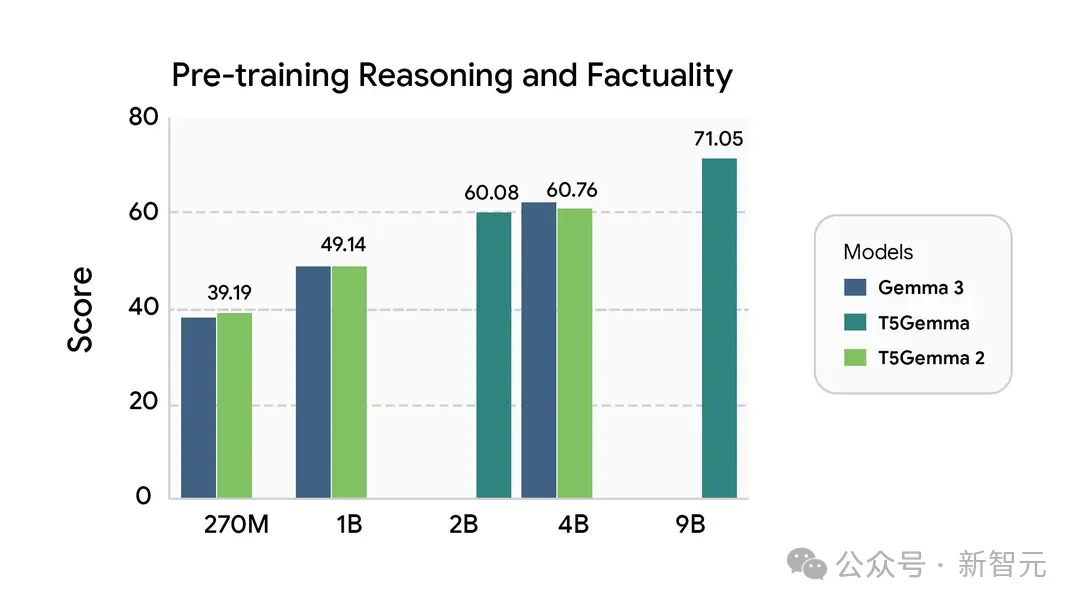
左右滑动查看

想要理解为什么谷歌要搞T5Gemma,就需要看看目前大模型技术路线演变的核心脉络。
T5Gemma算得上是大模型领域的「古典主义复兴」。
在当今GPT、Llama等Decoder-only(仅解码器)架构占主导的时代,T5Gemma 2是对经典Transformer架构中Encoder-Decoder(编码器-解码器)路线的回归与现代化改造。
我们现在熟知的GPT、Gemini、DeepSeek都是Decoder-only(仅解码器)架构。
目前叫得上名字的、用来「聊天」的超级模型,几乎清一色全是Decoder-only。
为什么说T5Gemma 2是「回归」?
这就要说到Transformer的分家史。
要理解「回归」,得先看它们当初是怎么「分家」的。
2017年谷歌发布《Attention Is All You Need》论文提出Transformer时,祖师爷原本是Encoder-Decoder(编码器-解码器)全套架构。
但后来,家族分成了三个流派:
流派A:Encoder-only(只用编码器)
代表人物:BERT。
特长:只能「读」,不能「写」。它极其擅长做选择题、分类、情感分析,但你让它写作文,它憋不出来。
流派B:Decoder-only(只用解码器)
代表人物:GPT。
特长:只能「猜下一个字」。虽然它看上文不如Encoder那么全面(只能看左边,不能看右边),但它天生会说话,而且人们发现只要把这玩意儿做得足够大,它居然产生了智能(涌现)。
也就是「意外的」开启了我们这个AI时代(笑。
流派C:Encoder-Decoder(全套保留)
代表人物:T5(谷歌),BART。
特长:既能读又能写。也就是现在的T5Gemma 2所在的流派。
T5的全称是Text-to-Text Transfer Transformer,连着5个T,所以叫T5。
那为什么Decoder-only(GPT流派)后来一统天下了?
所以也只有财大气粗的谷歌能有精力回归这个经典模型,继续投入搞研发。
谷歌在全世界都疯狂卷Decoder-only的时候,突然杀了个回马枪。
既然Decoder-only这么强,为什么要改回Encoder-Decoder?
因为谷歌发现了Decoder-only的几个死穴,而这些死穴正好是Encoder-Decoder的强项:
「幻觉」问题(瞎编):
Decoder-only(GPT)
是边写边想,有时候写嗨了就收不住,容易一本正经胡说八道。
Encoder-Decoder(T5)
是「先读懂(Encoder)-再动笔(Decoder)」。
Encoder会强迫模型先把你的输入彻底消化一遍,生成一个完整的「中心思想向量」,然后再让Decoder翻译出来。
这种机制天生更严谨,幻觉更少。
在多模态方面的天然优势:
你要让模型看图,Encoder(编码器)是最好的「眼睛」。
T5Gemma 2可以直接把图像信号喂给Encoder,这比强行塞给Decoder-only处理要顺畅得多。
端侧效率(手机上跑):
在手机这种算力有限的地方,如果你只是做翻译、摘要、指令执行,Encoder-Decoder往往能用
更少的参数(更小的显存)
达到和巨大Decoder-only模型一样的效果。
T5Gemma 2的出现,不是要推翻GPT,而是在特定领域(比如手机端、翻译、工具调用、严谨推理)复兴了Encoder-Decoder架构。

谷歌并未从零开始训练T5Gemma,而是采用了一种被称为「模型适配」(Model Adaptation)的高效技术。
该技术的核心在于利用已经过数万亿标记训练的Gemma 2或Gemma 3解码器模型作为种子,将其权重映射到新的编码器-解码器结构中。
这种做法极大地降低了计算成本,同时让模型能够继承原有的语言理解能力。
FunctionGemma:智能体的专用大脑
如果T5Gemma是从底层架构的创新,那么FunctionGemma就是从功能实现上的创新。
FunctionGemma是为了解决大模型落地中最痛的点——「不仅要能聊,还要能干活」而设计的。
FunctionCalling(函数调用):普通模型在被要求「定个闹钟」或「查天气」时,往往只能瞎编。FunctionGemma经过专门的微调,能够精准地输出结构化的数据(如JSON),去调用外部的API或工具。
Agent(智能体)优化:它是为AIAgent设计的,擅长多步骤推理和执行任务。
极致轻量化:这意味它可以直接跑在手机、甚至更低功耗的边缘设备上,作为系统的「控制中枢」。
适用场景:手机语音助手、家庭自动化控制、端侧AI Agent、API调度中心。
FunctionGemma并非仅仅是Gemma家族的一个「缩小版」,而是一个专门设计的「神经路由器」,旨在解决云端大模型在延迟、隐私和成本上的固有缺陷。
从对话到行动的范式跃迁
在过去的一年中,大语言模型(LLM)的发展主要集中在提升模型的对话能力、知识广度以及多模态理解力上。
然而,随着应用场景的深入,开发者社区最迫切的需求已从「能聊天的AI」转向「能干活的AI」。
这种从「对话式接口」向「主动体」的转变,要求模型不仅要理解自然语言,还要能精准地操作软件接口、执行多步工作流并与物理世界交互。
FunctionGemma的推出正是为了响应这一需求。

作为Gemma 3家族中最小的成员,它抛弃了通用知识的广度,换取了对函数调用(Function Calling)这一特定任务的极致优化。
这种「特种兵」式的模型设计思路,代表了AI工程化的一个新方向:即通过模型的小型化和专业化,将智能下沉至网络的边缘——用户的手机、IoT设备乃至浏览器中。
FunctionGemma之所以能在极小的参数规模下实现高性能的函数调用,依赖于其独特的架构设计和训练策略。
它不是通过简单的压缩得到的,而是基于Gemma 3架构进行了针对性的「压缩」,专注于句法结构的精确性和逻辑判断的确定性。
FunctionGemma拥有2.7亿(270M)参数。
在当今动辄数千亿参数的模型时代,这一数字显得微不足道,连「大模型」零头都不到,但其设计哲学却极具颠覆性。
通常模型的推理能力随着参数量的增加而涌现(Scaling Laws)。
然而,FunctionGemma打破了这一常规,证明了在特定领域(Domain-Specific),小模型可以通过高质量数据的微调达到甚至超越大模型的表现。
虽然官方未披露具体的蒸馏细节,但270M的规模暗示了大量的通用世界知识被剔除。
模型不再需要知道「法国的首都是哪里」或「莎士比亚的生平」,它只需要知道如何解析JSON、如何匹配函数签名以及如何处理参数类型。
发力移动端
「在手机上能运行吗?」这是用户最关心的问题。
答案不仅是肯定的,而且FunctionGemma正是为此而生。
在移动设备上,随机存取存储器(RAM)是最宝贵的资源。
Android系统的低内存查杀机制会毫不留情地关闭占用内存过大的后台进程。
FunctionGemma 270M在FP16精度下的权重大小约为540MB。
对于拥有8GB或12GB内存、甚至24GB的现代Android旗舰机,这仅占总内存的5%-7%,完全可以在后台常驻。
Int8/Int4(量化):为了进一步降低功耗和内存占用,端侧部署通常使用量化技术。
Int8量化:模型大小降至约270MB。
Int4量化:模型大小降至约135MB。
这意味着它可以在入门级设备甚至嵌入式设备上流畅运行。
谷歌为何要发布这样一个「小」模型?
这背后隐藏着其对未来AI计算架构的深刻思考,以及在移动操作系统控制权争夺战中的防御性布局。
这是FunctionGemma最核心的战略价值。
在当前的AI应用中,将所有请求都发送到云端大模型既昂贵又缓慢。
移动互联网的下一个阶段
移动互联网的下一个阶段是意图驱动(Intent-Driven)的。
意图驱动(Intent-Driven),用户不再通过点击图标打开APP,而是直接表达意图。
现状:Siri和谷歌Assistant,以及类似手机助手长期以来受限于硬编码的指令集,只能通过特定接口调用APP的有限功能。
FunctionGemma通过让模型直接学习APP的API定义,FunctionGemma试图让AI成为通用的UI。
开发者只需要暴露工具(Tools),FunctionGemma就能理解并操作这些工具。
谷歌的野心是通过开源FunctionGemma,谷歌实际上是在制定一套AI与APP交互的标准协议。
如果所有Android开发者都按照FunctionGemma的格式定义工具,那么谷歌的Android系统将成为世界上最强大的智能体平台,进一步加深其护城河。
为了验证FunctionGemma的能力,谷歌提供了两个典型的参考实现,展示了其在游戏和系统控制领域的潜力。
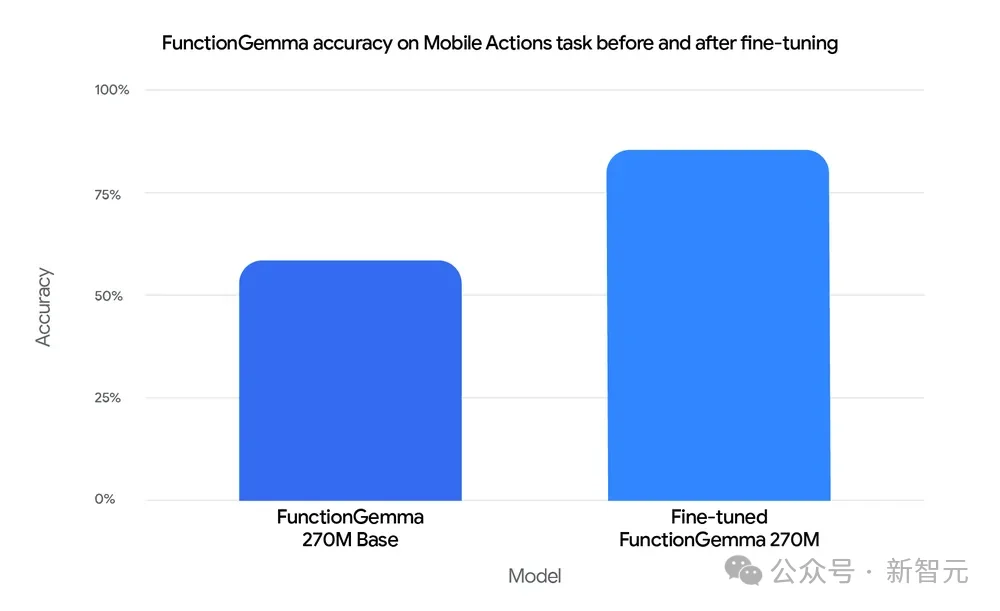
场景描述:用户用自然语言发出指令,模型将其转换为Android系统意图。
技术细节:
性能对比:经微调的FunctionGemma在此任务上的准确率达到85%,远超未微调的基座模型(58%)。这证明了在端侧垂直领域,小模型完全可以替代大模型。
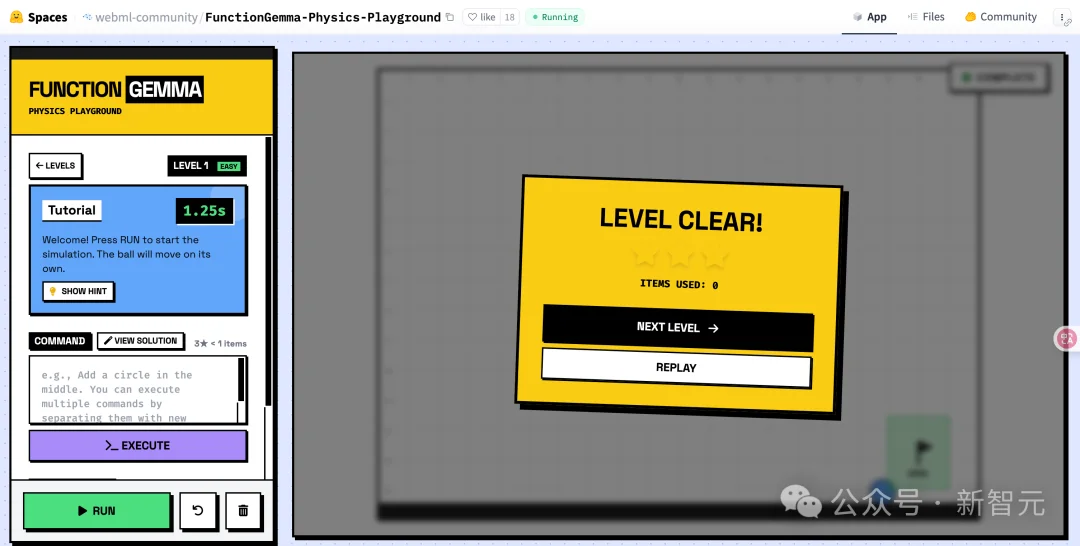
「Tiny Garden」这个Demo展示了FunctionGemma如何驱动游戏逻辑。
场景:一个语音控制的种田游戏。用户说「在顶排种满向日葵,然后给它们浇水」。
任务分解(TaskDecomposition):模型不仅要识别意图,还要进行逻辑推理。它需要将这一句话拆解为一系列函数调用:
完全离线:整个过程无需联网,这对于手游体验至关重要,因为网络延迟会导致游戏操作的不流畅。

对于开发者而言,FunctionGemma提供了一种低成本、高隐私的方案,将Agent能力集成到普通APP中,无需昂贵的服务器开销。它使得「语音控制一切」不再是巨头的专利,而是每个APP都能拥有的标准功能。
对于手机厂商而言,270M的参数量是完美的「甜点」——它既能利用现有的NPU硬件,又不会过度挤占系统资源,为打造「AI原生OS」提供了理想的地基。
对于谷歌而言,这是其在AI时代捍卫Android生态控制权的关键一步。
未来,可以预见,基于FunctionGemma的变体将无处不在:在你的智能手表里处理健康数据,在你的路由器里优化网络设置,甚至在你的汽车里调节空调温度。
AI将不再是一个需要「访问」的网站,而是一种像电力一样,无形却无处不在的基础设施。
参考资料:
https://blog.google/technology/developers/functiongemma/
https://blog.google/technology/developers/t5gemma-2/
文章来自于微信公众号 “新智元”,作者 “新智元”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
