# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
六个月的真实项目实践、重写 30 万行代码……这听起来像天方夜谭,但实际上,这正是一位开发者 JokeGold5455 的亲身经历。
他独自承担了一个复杂的 TypeScript 微服务项目的改造工作。为了让老板同意,他当场拍着胸脯保证六个月内完成。随后,他转身将 Claude Code 调教成得力助手,协助自己管理与重写工作。为此,他每月花费 200 美元(约 1422 元)开通 Max 20x 套餐,将原本约 10 万行的项目重构为 30~40 万行规模。
要知道,AI 用得好,效率可以翻倍;用不好,加班只会更多。为了充分挖掘 Claude Code 的潜力,JokeGold5455 做了大量调优工作,让 AI 的输出更准确、更可用。基于这些实践经验,他整理出了一个完整的 GitHub 参考代码库(https://github.com/diet103/claude-code-infrastructure-showcase),希望能为你优化 AI 编程环境和工作流提供实用启发。
来源:https://www.reddit.com/r/ClaudeAI/comments/1oivjvm/claude_code_is_a_beast_tips_from_6_months_of/
背景介绍
我是一名软件工程师,过去七年间主要从事生产环境下的 Web 应用开发。
自从 AI 浪潮来临后,我几乎是张开双臂地拥抱它的。
相比很多人的焦虑,我并不担心 AI 会取代我的工作——相反,我把它当作增强自身能力的工具。
借助它,我能更快地构建新功能、做演示方案,还能把 Claude 和 GPT-5 Thinking 等模型整合进我们的产品应用中。
这些项目的优化工作放在以前,我根本没时间去想。
现在,它们反而成了我“保住饭碗”的秘诀,也让我成为公司里那个“AI 顾问”——我觉得,其他同事在日常工作中应用 AI 的深度可能要比我落后大概一年。
有了这份信心,我提出对我们公司内部使用的一款 Web 应用进行一次较大规模的重构/改版。
起初,这个 Web 应用是某位大学生实习时写的,而它又是从我 7 年前刚实习时开发的另一项目上 Fork 出来的,所以不难想象这个应用的质量会有多么地粗糙。
不过,为了让公司的老板买账,我拍着胸脯答应要在几个月内独自完成整个项目的重新设计与重构(约 10 万行代码)。
我当时就知道这意味着要拼命加班,即使有 Claude Code 的帮忙也不会轻松多少。但我心里很清楚,这个项目如果能成功,会让大量手动流程自动化,为公司省下不少时间。
如今,六个月过去了……是的,我现在觉得当初自己给自己设定的时间安排确实太激进了。
为了完成这个项目,在过去这段时间里,我不仅把 Claude Code 的能力挖掘到了极限,也快把自己的理智推到崩溃的边缘。
在这次尝试中,我完全抛弃了旧的前端,一方面因为它太过时了,另一方面也是我想趁机体验一些新的技术栈。
下面就是我在改造的这款 Web 应用上使用的旧的和新的技术栈对比:
所有这些技术迭代其实都严格遵循了最佳实践。
现在这个项目的代码量涨到大约 30–40 万行,不夸张地说,我觉得“我的寿命也可能因此少了五年。”
但结果真的很棒——项目终于进入测试阶段,我对成品非常满意。
这个项目原本技术债堆成山,测试覆盖率为零,开发体验糟糕透顶(调试简直是地狱),各种奇怪问题层出不穷。
现在,我给它补上了可观的测试覆盖率,控制住了技术债,还写了一个命令行工具用于生成测试数据,并加上了“开发模式”,方便前端测试不同功能。
在这个过程中,我逐渐摸清了 Claude Code 的脾气,也知道在不同场景下能从它身上榨出多少“生产力”。
在用 Claude Code 六个月、独自重写 30 万行代码的过程中,我构建了这样一套系统:
在这篇文章里,我想聊聊自己使用 Claude Code 的一些实践经验,以及我在构建基础架构时的探索——包括 Skills 自动激活、Hook、Agent 等部分。
先说明一下:文中所有内容只是我目前觉得最顺手、最有效的配置,不代表这是唯一正确的做法。希望这些经验能给你在使用 AI 代理进行编程时带来一些启发。我不是专家,只是分享自己的思路和体会,仅供参考。
特别说明
工具说明
值得一提的是,我用的是 Claude Code Max 20x 套餐(200 美元/月,约 1422 元/月),所以你的体验可能会有不同。如果你只是想找那种“轻松随意写写代码”的 Vibe,这篇可能不适合你。但如果你想真正发挥 Claude Code 的潜力,那就得和它“协同工作”:一起规划、复盘、迭代、探索不同方案。
关于质量与一致性的一点说明
在论坛和各种讨论区里,我经常看到同一个话题:人们抱怨使用 Claude Code 的次数限制太苛刻,或者觉得这款模型的输出质量“越用越差”。
我想先说明一下——我并不是要否定这些体验,也不是说“只是你用错了”。每个人的场景和需求都不同,这些反馈都值得认真对待。
不过,我想分享一下我这边的情况。就我个人而言,Claude Code 在过去两个月的输出质量反而有了明显提升,我认为这主要得益于我不断调整和优化的工作流。
如果你能从我的系统中获得哪怕一点灵感,把类似的思路融入自己的 Claude 工作方式中,也许你也能让它发挥出更稳定、更令人满意的表现。
当然,话要说在前头——Claude 也确实会“翻车”。有时候,它就是没抓住重点,生成的代码质量一言难尽。
原因其实挺多的。首先,AI 模型是随机的,同一个输入可能得到完全不同的输出。有时只是“运气不好”,模型给出的结果确实不理想。
其次,提示词的表述方式也很关键。哪怕只改动几个词,输出结果也可能完全不同。Claude 对语言非常字面化,如果你写得模糊不清或歧义太多,它就很容易“跑偏”。
有时你得亲自出手
AI 很强大,但它不是无所不能的魔法。总有一些问题,人类的直觉和模式识别能力就是更胜一筹。
如果你看着 Claude 困在某个 bug 里折腾了半小时,而你两分钟就能搞定,那就直接自己修。没什么好丢脸的。
把它想成教别人骑车——有时候你得帮忙扶一下车把,等稳住了再放手。
尤其在逻辑推理题、现实常识相关的问题上,这种情况更常见。Claude 当然可以用“蛮力”穷举出答案,但人类往往能更快看出问题本质。
别陷入那种“AI 必须全自动搞定一切”的执念,那只会浪费你的时间。必要时果断介入,修好问题,然后继续前进。
我自己也经历过不少“灾难级提示词”——通常发生在一天快结束的时候,我懒得认真写提示,结果输出自然惨不忍睹。
所以如果你觉得 Claude 这阵子输出质量下降、怀疑是 Anthropic 暗地里“削弱了”模型,不妨先冷静下来,反思一下自己最近的提示写得怎么样。
多试几次。你可以按两下 ESC 调出历史提示,从中选一个重新分支。
你会惊讶地发现,在明白“自己不想要什么”之后,用同样的提示往往能得到更好的结果。
总之,输出质量下降的原因可能有很多——保持一点自省,想想自己能否提供更好的上下文和引导,往往比单纯抱怨更有效。
正如某个智者大概说过的那句话:
“不要问 Claude 能为你做什么,问问你能为 Claude 提供怎样的上下文。” ——某位智者
好了,讲道时间结束,接下来进入真正的干货部分。
我的系统
在过去六个月里,我针对 Claude Code 对整个工作流做了大量调整。效果非常好——至少我自己这么认为。
一、Skills Auto-Activation 系统(真正的游戏规则改变者!)
这一节必须单独讲,因为它彻底改变了我与 Claude Code 的协作方式。简单来看,可以将它翻译为“技能自动激活系统”。
问题出现
不久之前,Anthropic 推出 Skills(https://www.anthropic.com/news/skills) 功能时,我第一反应是:“这也太棒了吧!”
Anthropic 的 Skills 功能,可以理解为一套让 Claude 自动调用特定“技能模块”的系统:每个 Skill 封装了一组可复用的任务指令、脚本或资源,当 Claude 遇到相关任务时,它能自动识别并触发相应 Skill 来完成工作,从而实现自动化、模块化和可扩展的任务处理,而无需用户每次手动指定操作。
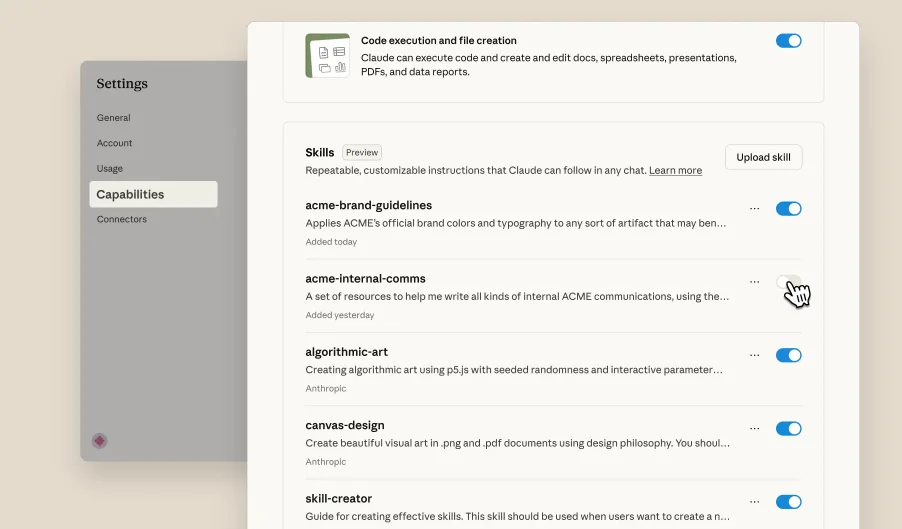
这项功能可以让 Claude 引用可移植、可复用的指令集,用来保持整个庞大代码库的一致性——听起来简直完美。
于是我花了不少时间,和 Claude 一起编写了一整套详尽的 Skills 配置,包括前端开发、后端开发、数据库操作、工作流管理等模块,内容涵盖上千行最佳实践、设计模式和示例代码。
然后……什么也没发生。
Claude 根本不会自动调用它们。我甚至在提示里写了 Skills 描述里的关键词——最终,还是没反应。
我打开本该触发 Skills 功能的文件——依旧没反应。
这种情况真的让人抓狂:我能清楚看到这个功能的潜力,但这些技能就像摆设一样,放在那儿一动不动,就像装饰品一样。
“啊哈!”时刻
那时我就想到了用 hooks。如果 Claude 不会自动使用 Skill,那我何不自己搭一个系统,让它在执行任何操作前先检查是否有相关 Skills 可用呢?
于是我开始研究 Claude Code 的 hook(钩子)系统,并用 TypeScript 构建了一个多层次的自动激活架构。
结果是真的——它能用!
工作原理
我创建了两个核心 Hook:
1. UserPromptSubmit Hook(在 Claude 看到你的消息前运行)
2. Stop Event Hook(在 Claude 回复完成后运行)
skill-rules.json 配置
基于此,我还创建了一个中央配置文件,用来定义每个技能的触发逻辑,包括:
示例片段:
{
"backend-dev-guidelines": {
"type": "domain",
"enforcement": "suggest",
"priority": "high",
"promptTriggers": {
"keywords": ["backend", "controller", "service", "API", "endpoint"],
"intentPatterns": [
"(create|add).*?(route|endpoint|controller)",
"(how to|best practice).*?(backend|API)"
]
},
"fileTriggers": {
"pathPatterns": ["backend/src/**/*.ts"],
"contentPatterns": ["router\\.", "export.*Controller"]
}
}
}
效果展示
现在,当我在开发后端代码时,Claude 会自动完成以下步骤:
结果堪称翻天覆地的变化:
遵循 Anthropic 官方最佳实践(艰难的教训)
在自动激活系统跑通之后,我去认真研究了 Anthropic 的官方最佳实践文档。
结果发现我之前用的方法是错的。
官方建议每个主 SKILL.md 文件应控制在 500 行以内,并通过“渐进式加载”来引用外部资源文件。
而我当时的情况是,frontend-dev-guidelines 足足 1500 多行;另外几个 Skills 也都超过了 1000 行。
这些庞大的“Skills 巨石”文件彻底违背了 Skills 系统“按需加载”的初衷。
于是我对整个结构进行了重构:
现在,Claude 会优先加载轻量级的主文件,只有在确实需要时才调入详细的资源文件。
结果:token 使用效率提升了 40–60%,大多数请求的响应速度和稳定性也明显改善。
我创建的技能列表
以下是我目前的技能阵容:
指南与最佳实践类
领域专用技能
这些技能会根据我正在编辑的文件或任务自动激活。
感觉就像有一个经验丰富、记忆力超群的高级工程师在 Claude 身后随时提醒它:“嘿,这里要用那个模式哦。”
为什么这很重要
在使用 Skills + Hooks 之前:
在使用 Skills + Hooks 之后:
如果你也在维护一个大型、有明确规范的代码库,我强烈推荐这套体系。
最初搭建确实花了两三天时间,但回报至少是十倍的。
CLAUDE.md 与文档体系的演进
我在六个月前发的那篇帖子里提到过一个观点:“规则是你最好的朋友”,这个观点我至今依然坚持。
但我的 CLAUDE.md 文件当时已经快要失控了——它承担了太多功能,
再加上一个 1400 多行的 BEST_PRACTICES.md 文件,Claude 有时候会读,有时候完全忽略。
于是,我花了一个下午和 Claude 一起重新组织并整合了整个文档体系。
调整后的结构如下:
什么被迁移到了 Skills
原本的 BEST_PRACTICES.md 中包含:
这些内容现在全部迁移进 Skills 系统中,并由自动激活 Hook 确保 Claude 真的会使用。再也不用祈祷它能“记得去读那份文档”了。
保留在 CLAUDE.md 的内容
现在的 CLAUDE.md 仅聚焦于项目特定信息(约 200 行):
新的文档结构:
Root CLAUDE.md (100 lines)
├── Critical universal rules
├── Points to repo-specific claude.md files
└── References skills for detailed guidelines
Each Repo's claude.md (50-100 lines)
├── Quick Start section pointing to:
│ ├── PROJECT_KNOWLEDGE.md - Architecture & integration
│ ├── TROUBLESHOOTING.md - Common issues
│ └── Auto-generated API docs
└── Repo-specific quirks and commands
精髓在于:Skills 负责 “怎么写代码”,CLAUDE.md 负责 “这个项目是怎么运作的”。真正实现了关注点分离。
开发文档系统
在所有改进中(除 Skills 外),这个系统带来的收益最大。Claude 有点像一个“自信满满但健忘至极”的初级工程师,总是容易忘记自己刚才在干什么。
这个系统就是专门为了解决这个问题。
来自 CLAUDE.md 的 Dev Docs 片段:
### Starting Large Tasks
When exiting plan mode with an accepted plan:
1.**Create Task Directory**:
mkdir -p ~/git/project/dev/active/[task-name]/
2.**Create Documents**:
- `[task-name]-plan.md` - The accepted plan
- `[task-name]-context.md` - Key files, decisions
- `[task-name]-tasks.md` - Checklist of work
3.**Update Regularly**: Mark tasks complete immediately
### Continuing Tasks
- Check `/dev/active/` for existing tasks
- Read all three files before proceeding
- Update "Last Updated" timestamps
这些文档会在每次开发新功能或大型任务时自动生成。
在此之前,我经常遇到这样的情况——Claude 在开发过程中“走偏了”,30 分钟前刚制定的计划完全被遗忘,因为它被某个随机想法带走了。
我的规划流程
一切从“规划”开始。规划是核心。
如果你在让 Claude 实现某个功能之前不先进入计划模式(planning mode),那你很可能要吃苦头。
就像不会让一个建筑工人直接开工盖楼,而是要先画好图纸一样。
当我开始规划某个功能时,我会先进入 planning mode,即使我之后会让 Claude 把计划写入 markdown 文件中。
我不确定这个步骤是否绝对必要,但在我看来,进入 planning mode 能让 Claude 更好地研究代码库、获取正确上下文,
从而制定出更完整的方案。
我创建了一个子代理(subagent)——strategic-plan-architect(战略规划架构师),它简直是个规划怪兽:
但我发现有两点很烦:
1. 你看不到子代理的输出;
2. 如果你拒绝了它的方案,代理会直接被销毁,无法继续讨论。
所以我自己做了一个自定义命令 /dev-docs,在主 Claude Code 实例上使用相同提示来实现相同功能。
一旦 Claude 输出了那份漂亮的计划,我会花时间仔细审阅。
这个步骤非常重要。
认真看一遍,你会惊讶地发现它经常会犯一些低级错误,或者完全误解了请求中的关键点。
通常,在退出计划模式后,我的上下文剩余量会少于 15%,但没关系——接下来我们会把所有需要的信息都存入开发文档系统中,从而“重置上下文”。
Claude 往往急于直接开写,我就立刻按下 ESC 中断它,运行 /dev-docs 命令。
该命令会使用已批准的计划,自动创建那三个文档,并在上下文足够的情况下补充缺漏。
完成后,我几乎可以完全放心让 Claude 实现整个功能,它不会走神、不会忘记计划,即使经历了自动压缩也能保持方向正确。
我会偶尔提醒 Claude 更新任务清单与上下文文件。
当当前会话的上下文不足时,只需运行 /update-dev-docs 命令,Claude 会记录所有相关上下文、下一步计划,并在压缩前更新任务状态。
新会话中只需一句话:“continue”,即可无缝衔接。
在具体实现过程中,根据任务规模,我会让 Claude 一次只实现一到两个部分。
这样我能及时审查中间结果,防止错误扩大。
同时我还有一个子代理负责定期代码审查,以便提前发现潜在的大问题。
如果你还没有让 Claude 审查自己的代码,我强烈建议你试试看——它帮我避免了大量麻烦,发现了关键错误、缺失实现、不一致逻辑,甚至一些安全漏洞。
PM2 进程管理(后端调试的终极利器)
这是我最近才加上的一环,但它让后端调试的体验简直提升了一个层级。
问题所在
我的项目同时运行着七个后端微服务。问题是——Claude 在服务运行时无法直接查看日志。
也就是说,我不能直接问它:“邮件服务出错了,你看看怎么回事?” 因为 Claude 没法自己读日志,除非我手动复制粘贴到对话里。
临时解决方案
有一段时间,我让每个服务通过一个 devLog 脚本把输出写入带时间戳的日志文件。
虽然能用,但很笨拙。Claude 可以读取日志文件,却无法实时更新。服务崩溃后不会自动重启,管理起来也非常麻烦。
真正的解决方案:PM2
直到我发现了 PM2 ——彻底改变了游戏规则。
我用一条命令就让所有后端服务通过 PM2 运行:
pnpm pm2:start
这带来的好处包括:
PM2 配置示例:
// ecosystem.config.jsmodule.exports = {
apps: [
{
name: 'form-service',
script: 'npm',
args: 'start',
cwd: './form',
error_file: './form/logs/error.log',
out_file: './form/logs/out.log',
},
// ... 6 more services
]
};
调试流程的前后对比
以前:
我: “邮件服务报错了。”
我: [手动查找并复制日志]
我: [粘贴到聊天框]
Claude: “让我分析一下……”
现在:
我: “邮件服务报错了。”
Claude:执行 pm2 logs email --lines 200
Claude:读取日志后说,“问题在于数据库连接超时……”
Claude:执行 pm2 restart email
Claude: “已重启服务,正在监控是否仍有错误。”
差别堪比天壤之别。现在 Claude 能自主完成调试,我再也不用当“人工日志搬运工”了。
唯一的缺点:PM2 不支持热重载(hot reload),所以前端我仍用 pnpm dev 运行。但对不需频繁热重载的后端服务来说,PM2 简直完美。
Hooks 系统(不留烂摊子)
我这个项目是 multi-root 结构,根目录下有八个不同的 repo ——一个前端,七个后端微服务和工具服务。我经常在多个 repo 之间来回切换开发。
最让我头疼的,是 Claude 编辑完文件后经常忘记运行构建命令。
于是代码里会残留十几个 TypeScript 错误,等我几个小时后再让它构建时,它才若无其事地说:
“有几个 TypeScript 错误,但它们无关紧要,所以没问题!”
不,Claude,我们现在很不妙。
Hook #1:文件编辑追踪器(File Edit Tracker)
首先,我创建了一个 post-tool-use hook,在每次 Edit / Write / MultiEdit 操作后运行。
它会记录:
起初我让它在每次编辑后立刻运行构建,但那太低效了。Claude 经常先改坏,再马上修好。
Hook #2:构建检查器(Build Checker)
于是我添加了一个 Stop hook(在 Claude 回复结束后运行),它会:
自从启用这个系统后,Claude 再也没留下过未修复的错误。
hook 会立刻发现问题,Claude 会在继续前先修好。
Hook #3:Prettier 格式化器
这个简单但好用。Claude 回复完后,自动使用每个 repo 的 .prettierrc 配置运行 Prettier 格式化所有被编辑的文件。
再也不用手动打开文件运行格式化,也不用看到 Prettier 改动二十个尾随逗号因为 Claude 上次忘了加。
不过,现在我不再推荐这个 Hook。因为当我分享这篇文章之后,有读者留言提供了详细数据——文件修改会触发 <system-reminder> 提示,消耗大量上下文 tokens。
他们仅仅因为自动格式化,在 3 轮对话中消耗了 16 万个 tokens。
这个影响会因项目大小和格式化规则而异。
但我最终还是把这个 hook 移除了——格式化手动执行即可,没必要牺牲 tokens 换一点点方便。
想保留自动格式化的,可以在会话间手动运行 Prettier,而不是在 Claude 对话期间执行。
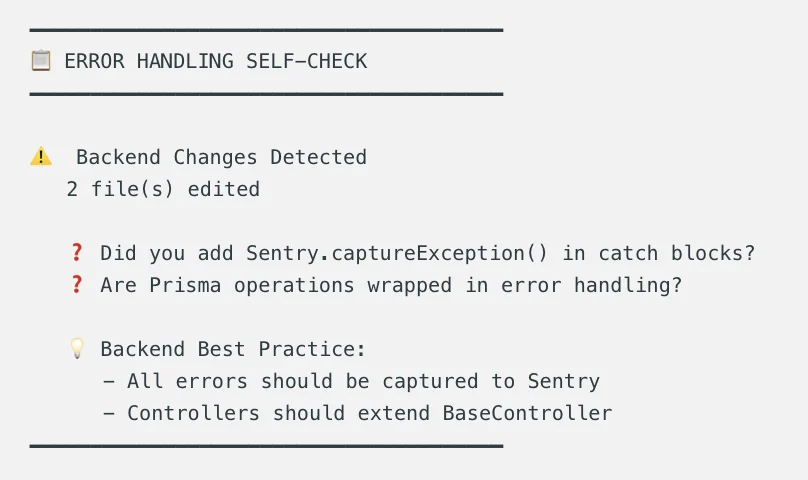
Hook #4:错误处理提醒
这就是我前面提到的“温柔提醒型” hook。
它会在 Claude 回复结束后:
示例输出:
完整 Hook 流程
Claude 每次回复时,都会经过以下流程:
Claude 回复结束
↓
Hook 1:Prettier 格式化器 → 自动格式化编辑文件
↓
Hook 2:构建检查器 → 立即捕捉 TypeScript 错误
↓
Hook 3:错误处理提醒 → 进行自检提示
↓
若发现错误 → Claude 立即修复
↓
若错误过多 → 启动 auto-error-resolver agent
↓
最终结果:干净、格式统一、无错误的代码
此外,UserPromptSubmit hook 会在 Claude 开始工作前自动加载相关技能。
结果:不留烂摊子。完美。
附加在 Skills 上的脚本
我从 Anthropic 官方 GitHub 上的技能示例里学到一个超酷的模式:把实用脚本附加到 Skills 上。
举例来说,我的 backend-dev-guidelines 技能里有一节是关于测试认证路由的。
Skills 不仅解释了认证流程,还引用了一个实际脚本:
### Testing Authenticated Routes
Use the provided test-auth-route.js script:
node scripts/test-auth-route.js http://localhost:3002/api/endpoint
这个脚本会帮你处理所有复杂的认证步骤:
当 Claude 需要测试路由时,它完全知道该用哪个脚本以及如何使用。
再也不用每次都“让我来写一个测试脚本”,重复造轮子了。
我计划把这种模式扩展到更多技能上,让 Claude 直接使用现成工具而不是每次从零生成。
工具和其他辅助
SuperWhisper(Mac)
当手疲劳时,可以用语音转文字输入,Claude 对我的语音输入理解得很好。
Memory MCP
随着 Skills 功能处理大部分“记忆模式”的工作,我现在使用得少了。
但它仍适合跟踪项目特定的决策和架构选择,这些不属于 Skills 的内容。
BetterTouchTool
说实话,仅仅是不用在各个应用间来回切换,就能节省大量时间,这一点就足以让 BTT 的购买物有所值。
脚本覆盖一切
任何繁琐任务几乎都能找到脚本解决,譬如:
小技巧:当 Claude 帮你写了有用脚本,立刻记录在 CLAUDE.md 或附加到相关 Skills 里,未来的你会感谢现在的自己。
文档记录(仍然重要,但已进化)
我认为,除了规划,文档几乎同样重要。我会在开发过程中实时记录,包括每个任务或功能生成的 dev docs。
从系统架构、数据流图,到开发者文档和 API 文档,都有涵盖。
但变化在于:文档现在是和 Skills 协作,而不是替代 Skills。
举例说明:
我仍有大量文档(850+ Markdown 文件),但现在专注于项目特定的架构,而不再重复 Skills 中已有的通用最佳实践。
当然你不必如此极端,我建议大家可以设置多层次文档:
这样 Claude 才能更高效地导航你的代码库。
Prompt 使用技巧
在写 Prompt 时,尽量具体明确地说明想要的结果。就像不会让建筑工直接开工建新浴室而不先讨论设计图一样。
如果不确定细节也没关系:
这样你可以根据 Claude 的计划判断好坏并调整,否则就是纯粹盲打“vibe-coding”,可能连该包含哪些文件的上下文都不清楚。
另外,避免引导式提问以获得客观反馈:
这样得到的答案会更平衡。
Agents、Hooks 与 Slash Commands(三位一体)
Agents(代理)
我创建了一小队专业的代理:
质量控制:
测试与调试:
规划与策略:
专项功能:
使用代理的关键:明确角色和返回内容。避免代理“去干自己想干的事”然后只告诉你“我修好了!”
Hooks(前文已覆盖)
Hooks 系统是整个体系的粘合剂:
Slash Commands(斜杠命令)
我有很多自定义 slash 命令,常用的包括:
规划与文档
质量与审查
测试
斜杠命令的美妙之处在于:
结语
经过六个月的高强度使用,我总结出一些心得:
必备要素:
可选加分项:
差不多就是我现在能想到的全部。就像我开头说的,我只是一个普通开发者,也非常愿意听大家的经验、技巧,甚至批评指正——因为我总想不断优化自己的工作流程。
我写这篇分享,只是想把对我有用的方法告诉别人,因为在现实生活中我几乎找不到合适的人交流(我的团队很小,而且大家对 AI 的接受速度都很慢)。
文章来自于微信公众号 “CSDN”,作者 “JokeGold5455”



【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
