# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
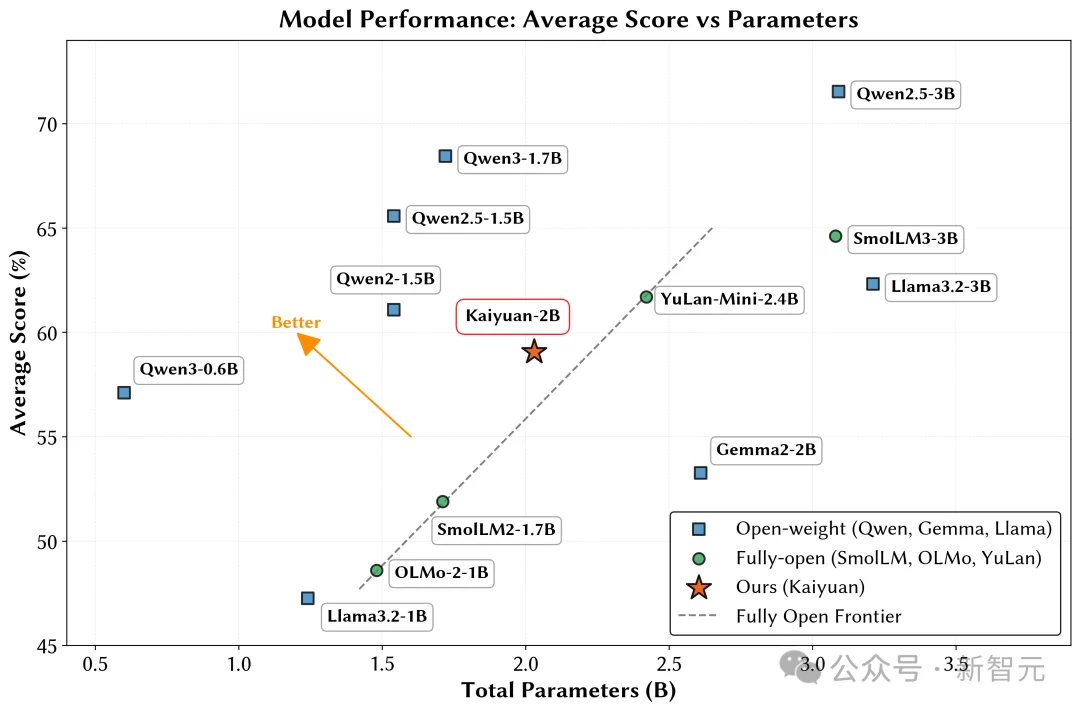
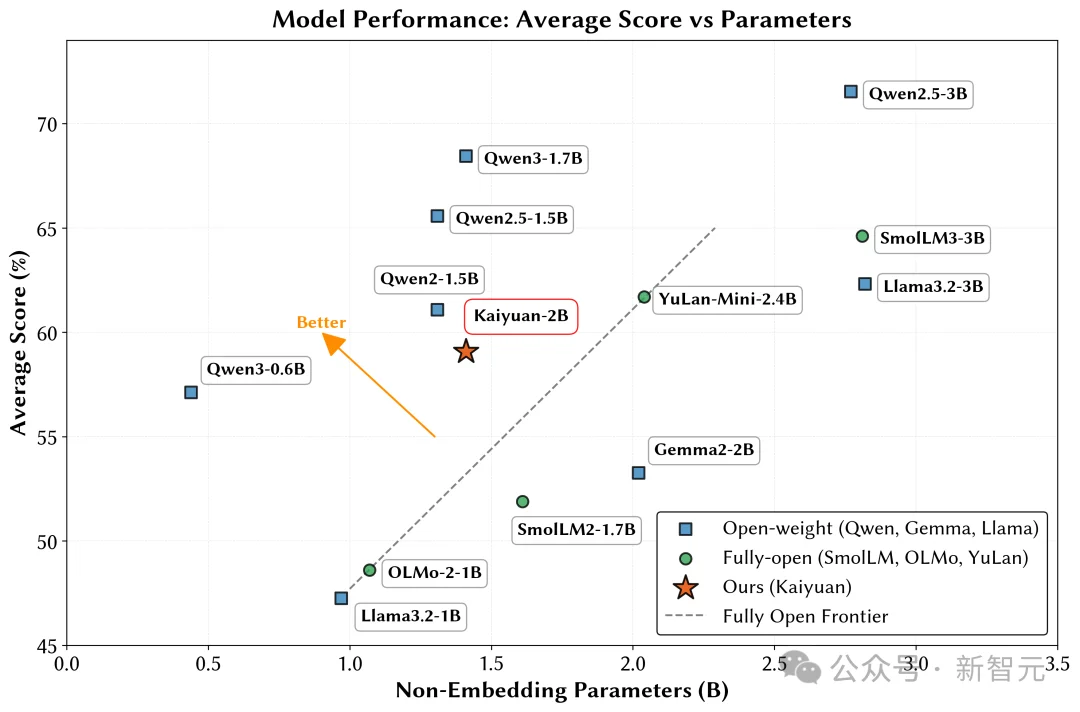
如果实验室只有国产算力、有限资源与开源数据,能否玩转端侧模型的预训练?
鹏城实验室与清华大学PACMAN实验室联合发布了鹏城脑海‑2.1‑开元‑2B(PCMind‑2.1‑Kaiyuan‑2B,简称开元‑2B)模型,并以全流程开源的方式回应了这一挑战——从训练数据、数据处理框架、训练框架、完整技术报告到最终模型权重,全部开源。

模型链接:https://huggingface.co/thu-pacman/PCMind-2.1-Kaiyuan-2B
数据集:https://huggingface.co/datasets/thu-pacman/PCMind-2.1-Kaiyuan-2B
技术报告:https://arxiv.org/abs/2512.07612
数据处理框架:https://github.com/thu-pacman/Kaiyuan-Spark
训练框架:https://github.com/thu-pacman/kaiyuan-mindformers
此次开源不仅为国内研究者提供了一条可复现、可迭代的技术路径,也展现了在国产计算平台上实现高效、稳定预训练的完整解决方案。
开元‑2B的训练依托鹏城脑海 2计算平台,数据处理基于华为鲲鹏920,训练系统基于华为昇腾 910A。
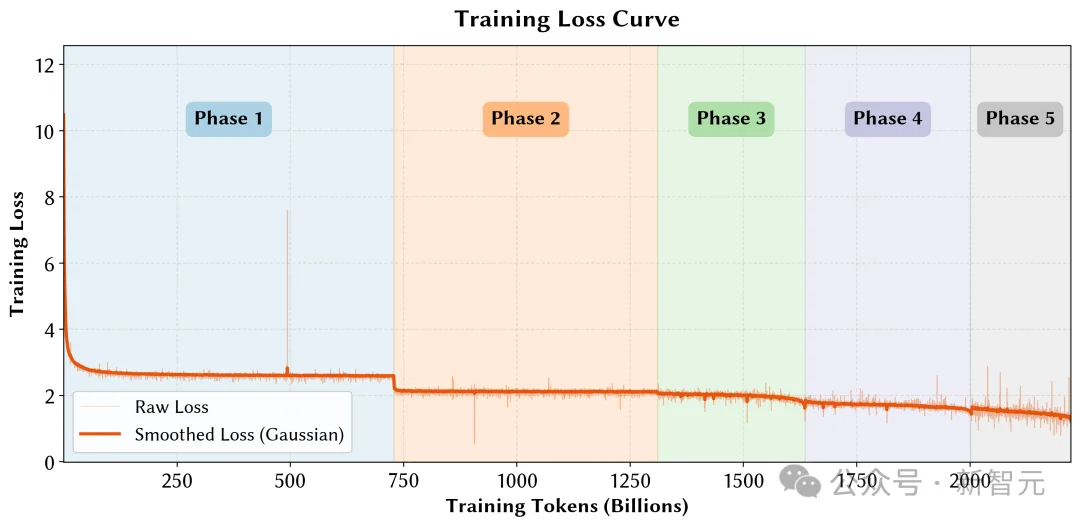
由于昇腾910A仅支持FP16精度(类似于NVIDIA V100),训练稳定性成为首要挑战。
为此,研究团队在 Qwen3‑1.7B 的架构基础上,引入了三明治范数(Sandwich Norm)与软裁剪(Soft Clipping) 两项关键技术。
三明治范数:在Transformer每层前后保留归一化层,有效控制梯度传播中的数值范围
软裁剪:通过对输出logits应用tanh非线性变换,将数值稳定在合理区间内,防止训练发散
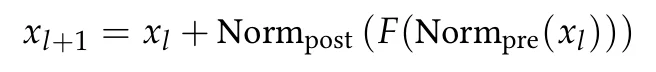
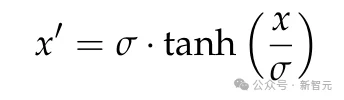
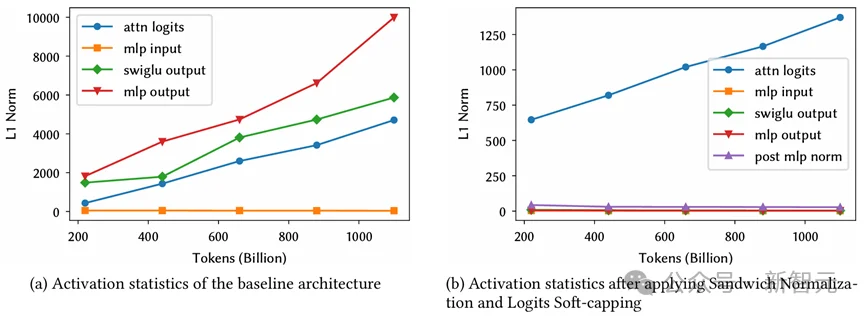
加上三明治范数和软裁剪前后的数值稳定性对比
这些技术不仅使训练在FP16环境下保持稳定,也为后续国产平台上的大规模训练提供了重要参考。
开源数据
去重、评价与高效利用
当前开源预训练数据规模已达TB级别,来源多样、质量不均,如何从中筛选出高质量部分并制定混合策略,是训练优质模型的基础。
开元‑2B面对两个核心问题:
全局去重的高效实现:Kaiyuan‑Spark框架
研究团队开发了Kaiyuan‑Spark数据处理框架,采用树状流水线设计,全程YAML配置管理,易于复现与扩展。
结合诸葛弩计算框架进行本地加速,在 MinHash 去重任务中实现端到端2.5倍的加速比,高效完成TB级数据的全局模糊去重。
分位标定(Quantile Benchmarking)
为解决数据集之间质量标签不可比的问题,团队提出分位标定:通过设计小规模探针实验,构建数据质量分数与下游任务表现之间的映射关系。
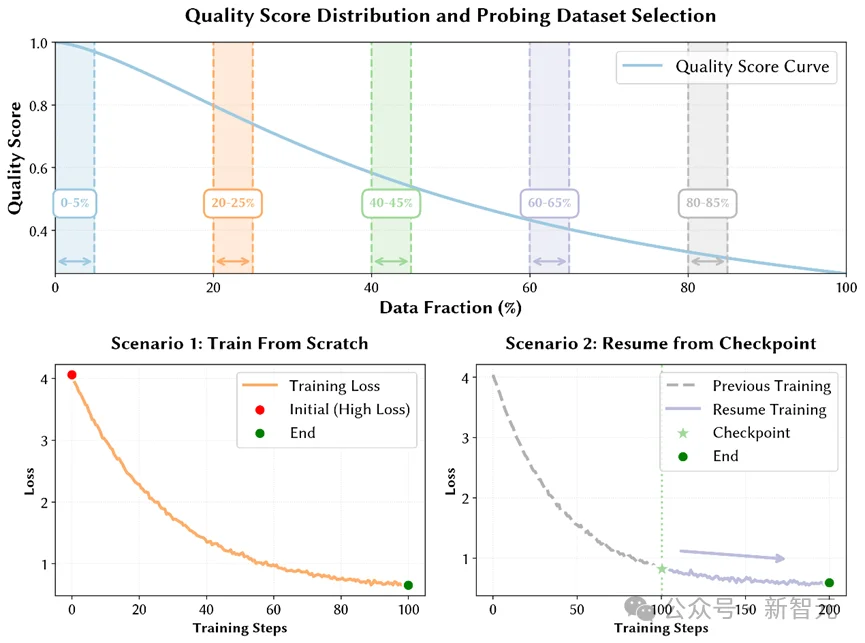
分位标定流程示意图
具体做法为:从不同数据集中按质量分位数抽取多个子集,然后使用小规模模型进行训练测试,最后根据下游任务表现反向标定各数据集的质量区间。
该方法成本低、可迁移,为后续大规模训练的数据配比提供了科学依据。
关键发现
基于分位标定,团队得出若干有趣发现:
数据集的优势与任务类型相关
Fineweb‑Edu在知识问答与阅读理解类任务上表现更好,DCLM‑Baseline 在常识推理类任务中略有优势。
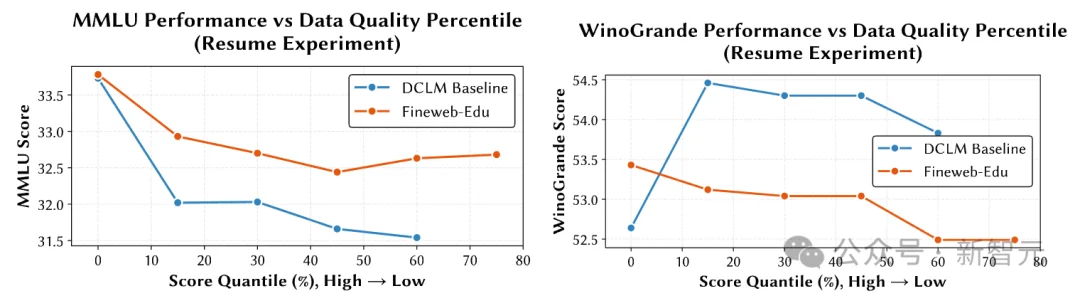
DCLM Baseline和Fineweb-Edu在MMLU和WinoGrande上的分位标定结果
同一数据集内部质量差异巨大
最高与最低质量数据在ARC‑Easy上的表现相差可达8%‑15%
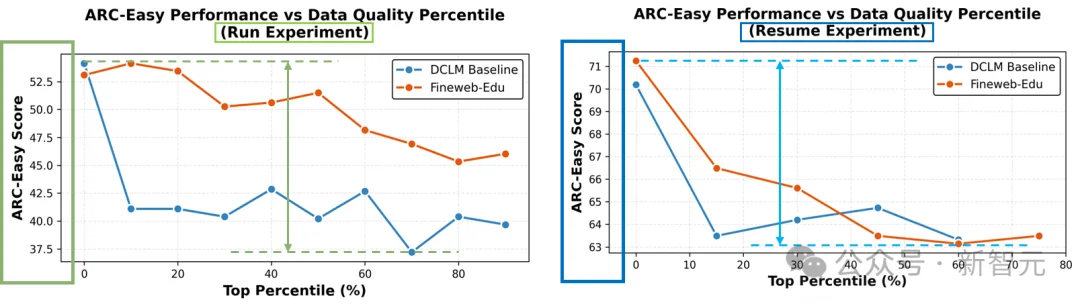
DCLM Baseline和Fineweb-Edu在ARC-Easy上的分位标定结果
可以看到,高质量数据占比虽小,却是提升模型能力的关键。
数据利用策略
动态调整与课程学习
针对数据分布不均的问题,开元‑2B提出三个策略。
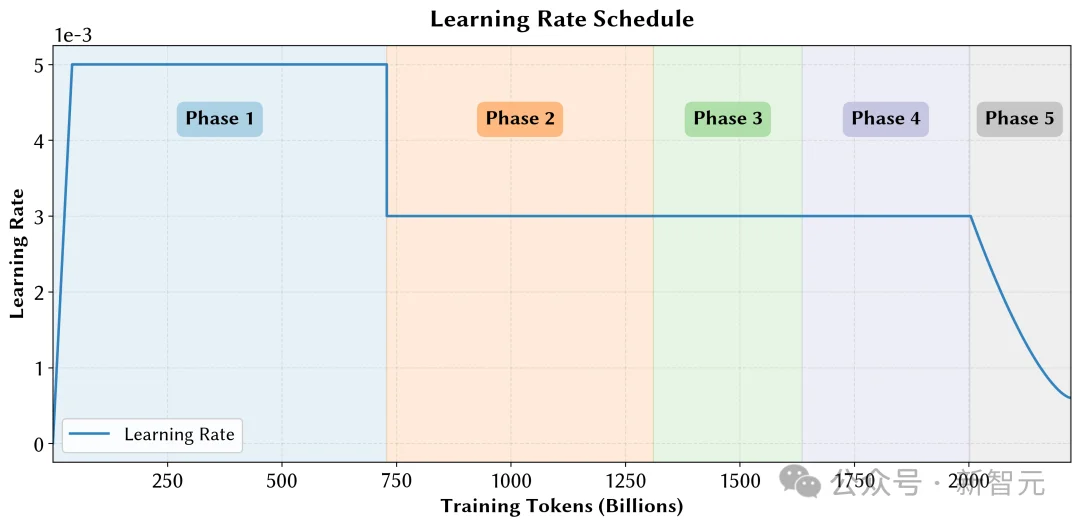
多阶段动态比例调整
随着训练推进,逐步提升数学、代码、中文等领域数据的比例,缓解模型遗忘,使关键领域在训练后期得到充分学习。
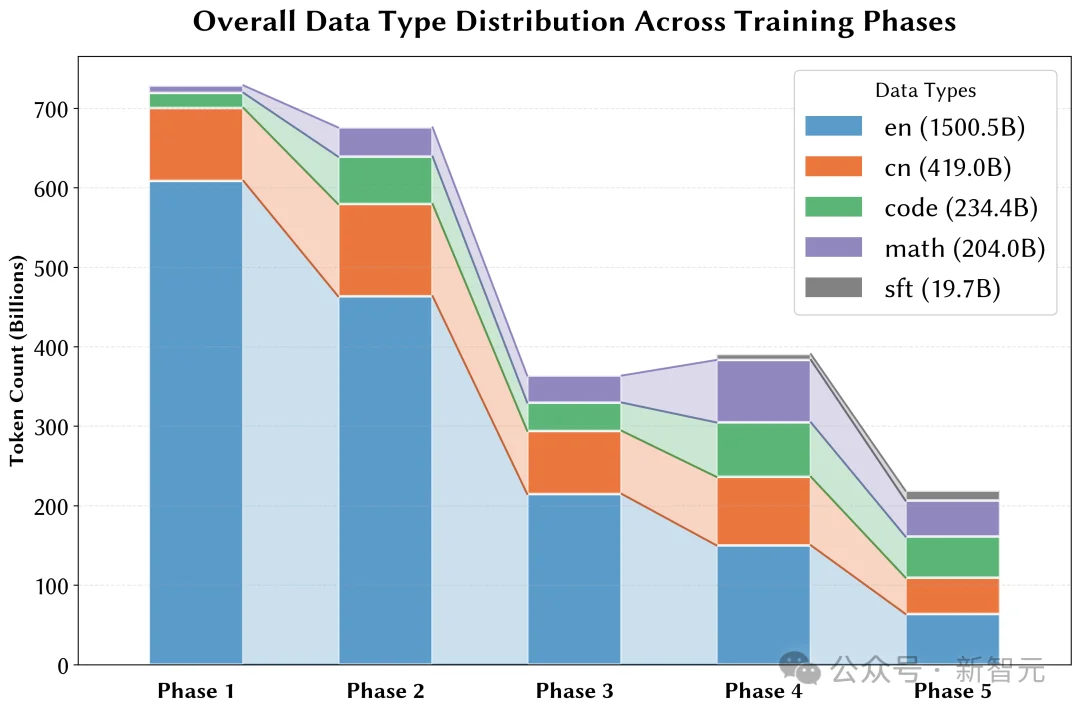
多阶段调整数据比例
策略性数据重复

小规模实验表明,对高质量数据进行适度重复训练,效果优于单轮训练。开元‑2B在训练后期逐步提高高质量数据的重复比例。
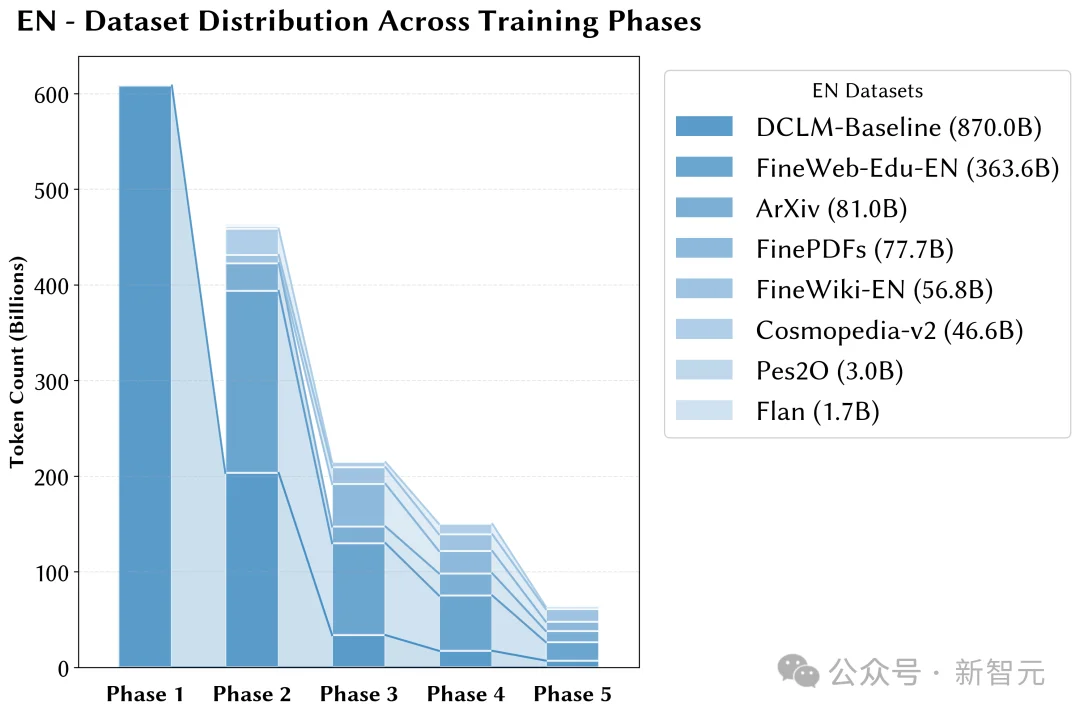
以Fineweb-Edu为例:Top 10%的高质量数据在整个训练过程中出现多次,中低质量数据仅出现一次,从而优化数据效用分布。
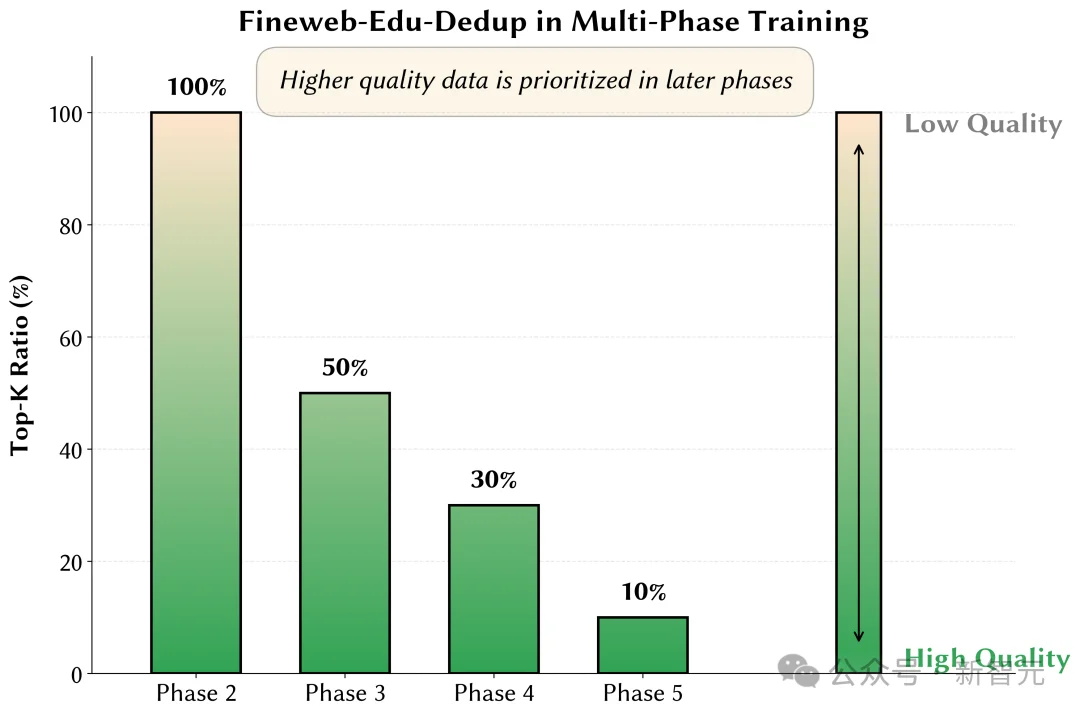
Fineweb-Edu在多阶段训练中采样比例变化
多领域混合课程学习
研究团队提出Curriculum Decay Model Average,在课程学习的基础上引入权重平均,缓解训练噪声,提升收敛稳定性。

论文链接:https://arxiv.org/abs/2511.18903
该方法通过领域内质量排序与领域间比例均衡的结合,实现多领域数据的渐进式学习。
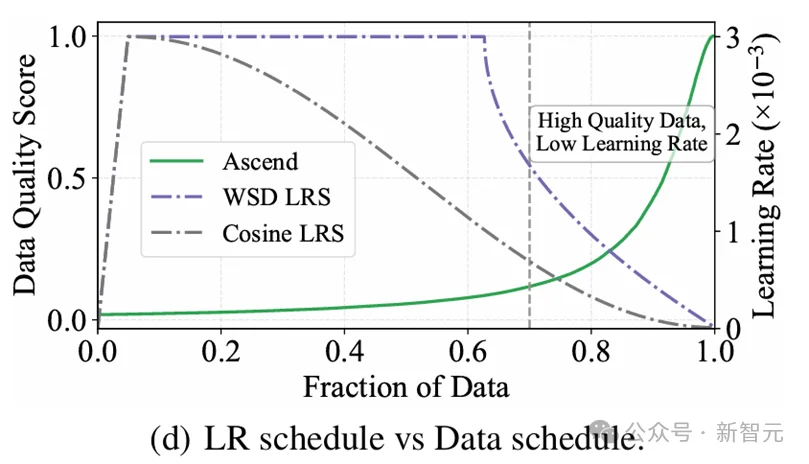
学习率衰减会影响课程学习效果
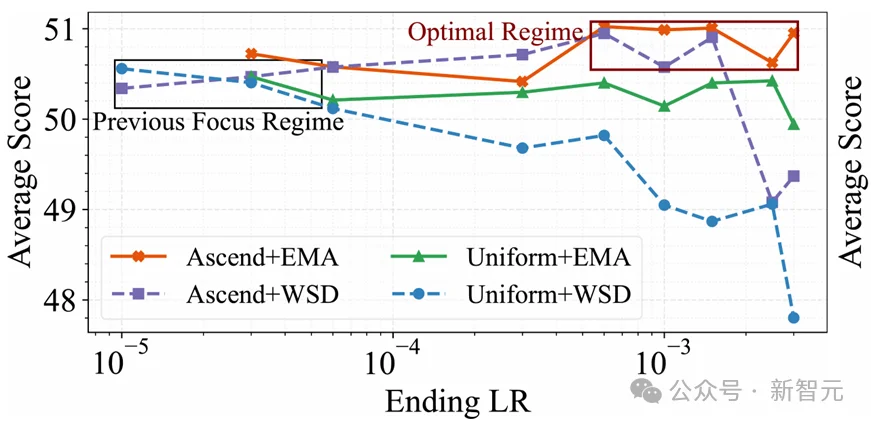
不同学习率衰减条件下,最优的课程学习+权重平均配置(Ascend+EMA)要强于最优的常见做法(Uniform+WSD)
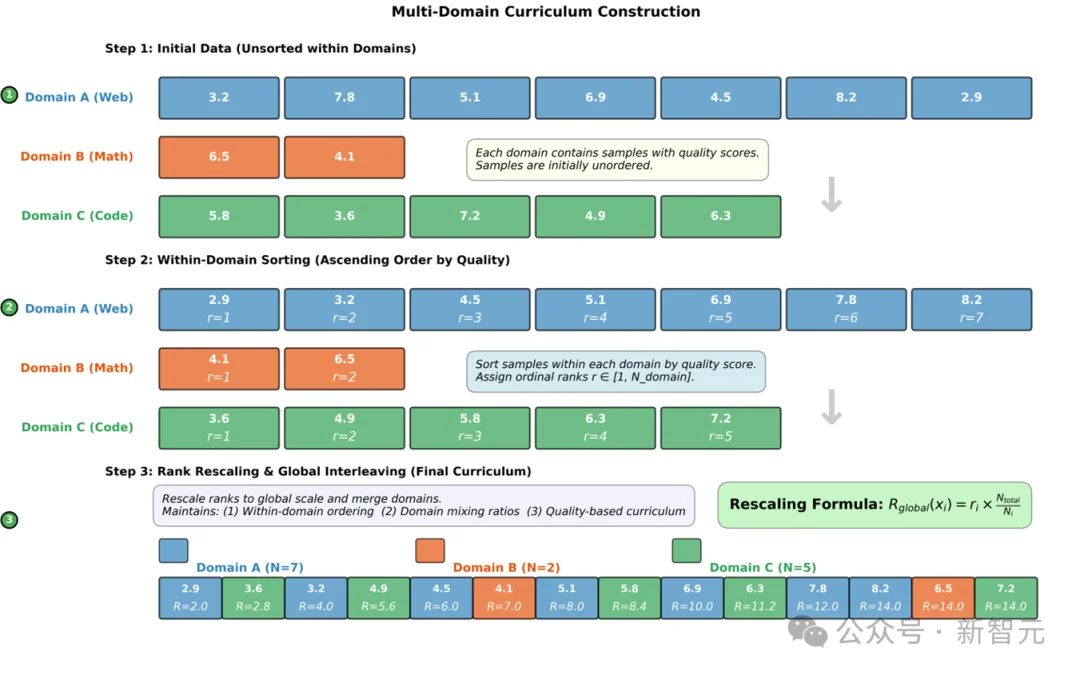
多领域课程的实现
配合精心设计的学习率调度方案,模型在高质量数据上得以充分学习,最终在多类评测中接近千问系列(仅开源权重)的模型表现。
全流程开源
推动国产AI生态共建
开元‑2B不仅是一次端侧模型训练的实践,更是一次全栈开源、全流程透明的技术示范。
从数据处理框架Kaiyuan‑Spark、训练数据集,到数据评价体系、课程学习策略,所有环节均公开可复现。训练中涉及的所有原始数据集均具有宽松的开源协议(如CC、Apache、MIT、ODC等,详细列表技术报告附录B),个人、院校、企业均可自由使用,进一步提升了训练的可复现性。
注:目前部分声称「开放」的公开数据集,事实上本身并非使用自由许可证授权,或者间接混入了带有非自由许可证的原始数据;另有大量的公开数据集,对来源数据的许可证未加任何筛选或说明。在模型训练中使用此类数据集并发布或使用,都可能带来潜在的法律合规风险。
这为国内研究者在国产算力平台上开展模型预训练提供了完整工具箱,也为构建开放、协作的 AI 研发生态迈出坚实一步。
模型权重、技术报告与相关代码已在官方平台发布,欢迎开发者、研究者共同参与测试、改进与拓展。
结语
真正的技术进步源自开放的协作与共享,开元‑2B是一个起点,未来与社区一起,在国产算力的土壤上,生长出更多创新的AI成果,从开元系列,开启国产算力训练的「开元盛世」。
附录
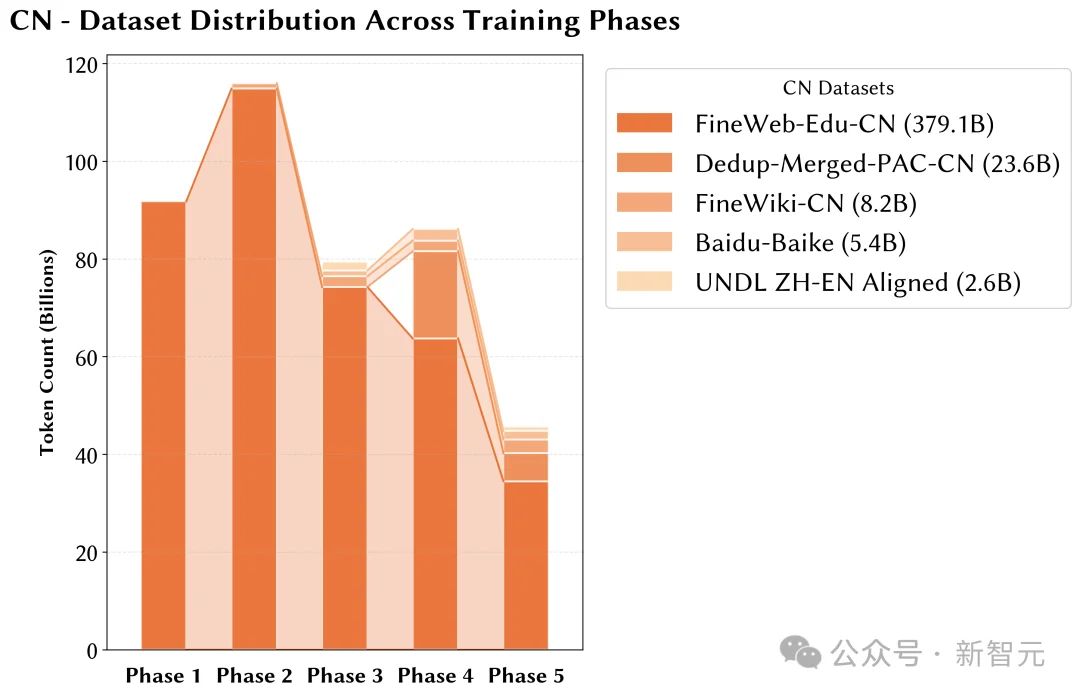
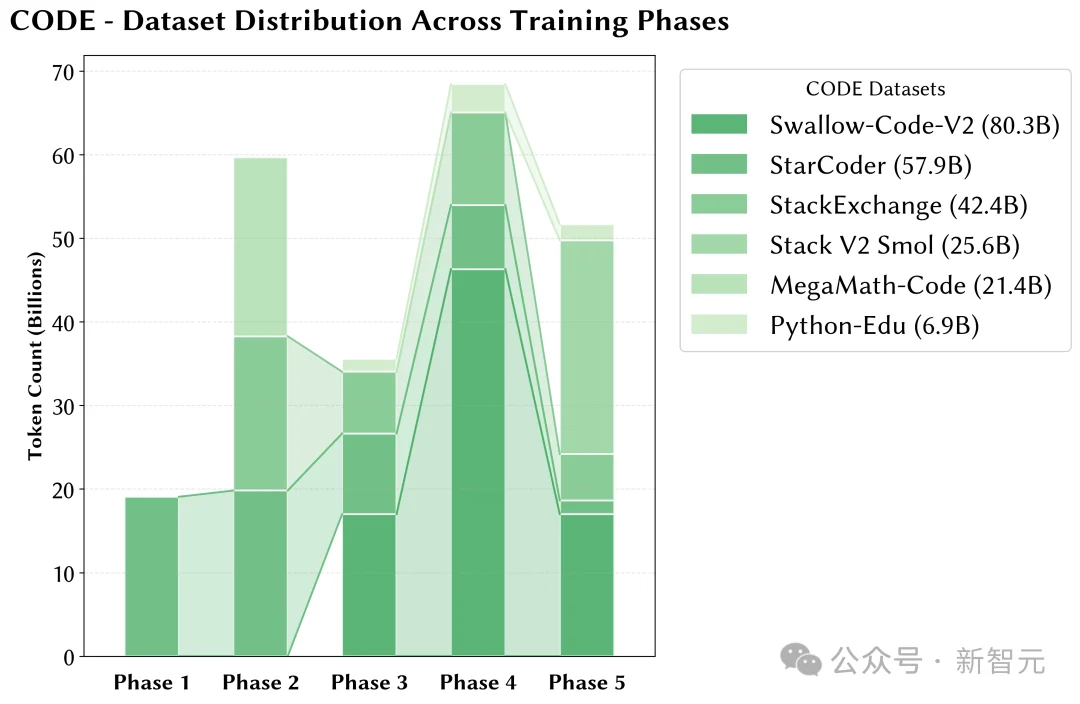
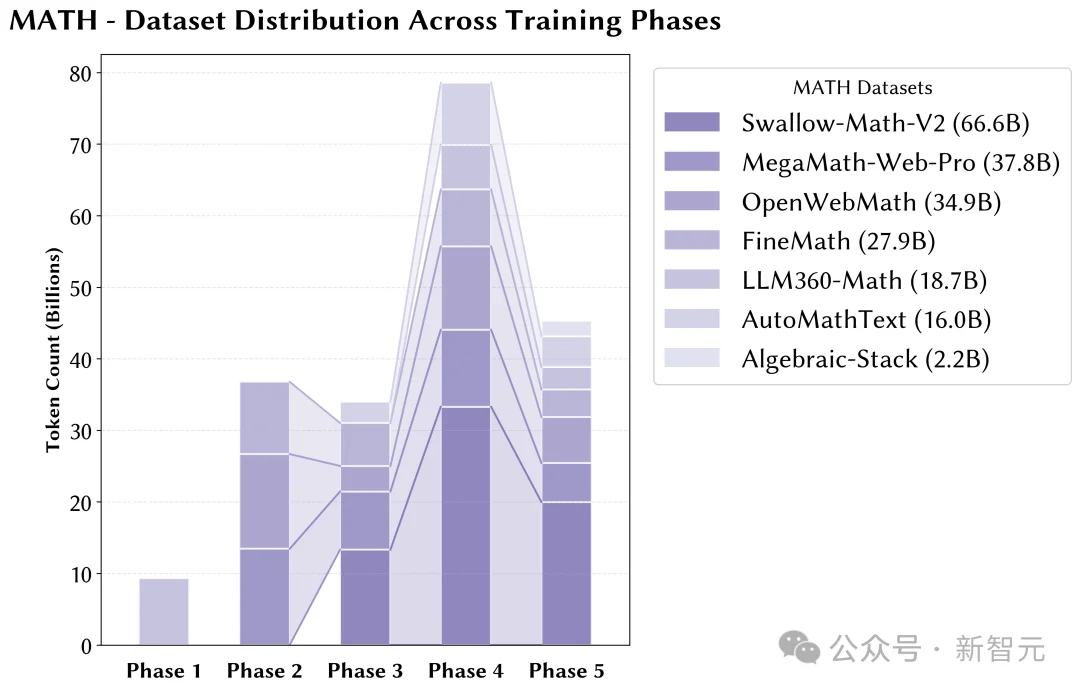
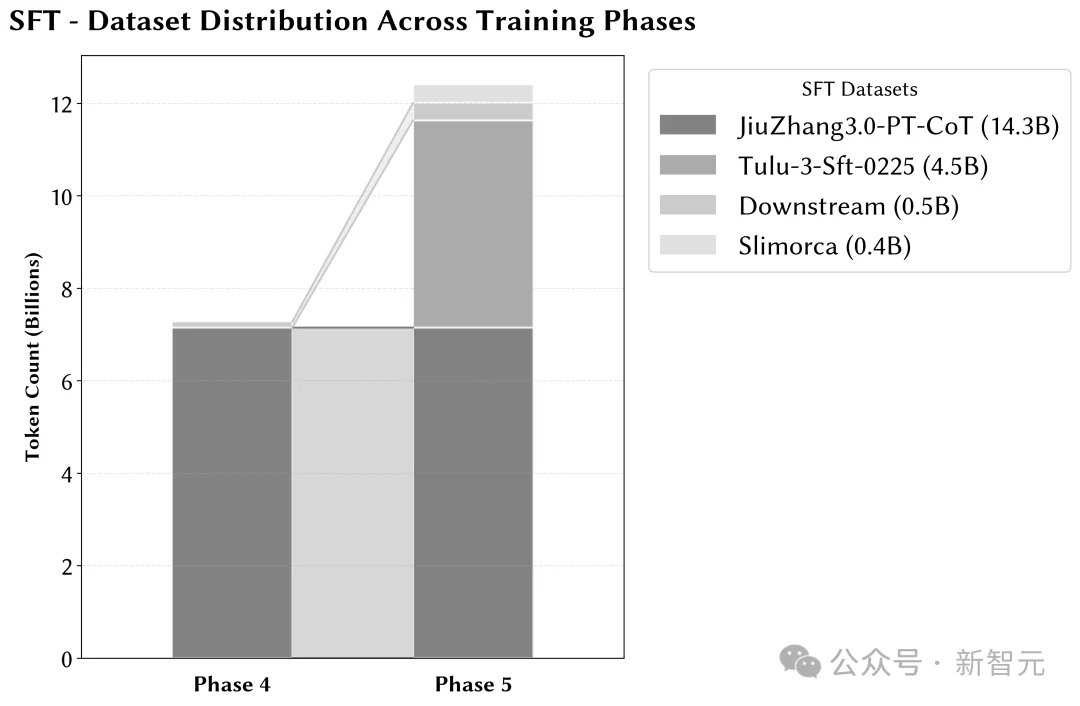
文章来自于微信公众号 “新智元”,作者 “新智元”


