# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2025 年还有一周结束,年底,AI 视频圈又卷起来了。
今天我在 HuggingFace Daily Paper 上刷到一篇论文,vote 还很高,排到了当天第三名,仔细一看标题,讲的是视觉生成,作者竟然来自熟悉的老朋友 MiniMax。

论文地址:https://arxiv.org/html/2501.09755v1
顺着扒拉能看到,这个技术搞成开源的了。
熟悉的朋友都知道,MiniMax 今年已经是开源狂魔了,1 月开源 MiniMax-01,6 月开源 M1,11 月开源 M2…… 但有一个现象级产品,他们从来没开源过技术。
他就是海螺视频。
这次破天荒地开源了底层技术 ——「VTP(Visual Tokenizer Pre-training)」,是一个视觉分词器预训练框架。
更值得注意的是,论文里强调的一个发现:他们在 AI 视觉生成领域找到了 Scaling Law (缩放定律)。
在大语言模型领域,Scaling Law 早就是共识了,砸更多算力、数据、参数,模型就会变更强。
但是,在视觉生成领域一直没有找到这个规律。
而这,也是我第一次了解到,业内还有个广泛的 “悖论”——
视觉分词器(第一阶段)砸再多钱,生成模型(第二阶段)也不会变好,甚至还会变差。。
什么意思?
现在主流的视频生成模型像 Sora、海螺、可灵都是两阶段架构:
按理说,第一阶段训练得越好,第二阶段应该效果越好才对。但实际情况却很诡异。。论文里展示了一组实验数据:
传统做法是,随着训练算力增加,重建质量(rFID)从 2.0 降到 0.5,越来越好。但是生成质量(gFID)却从 55.04 升到 58.56,反而变差了。就像你花大价钱买了顶级食材,但是做出来的菜更难吃了。
(加粗的两个概念很重要,请记住)
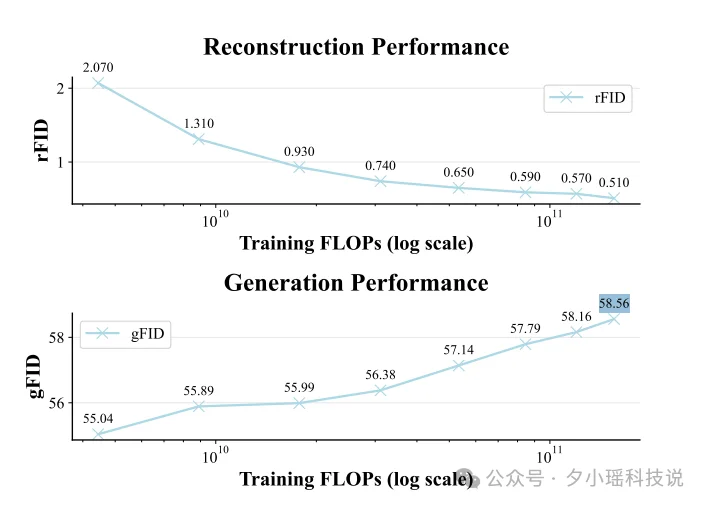
就因为这个悖论,才导致了在视频生成领域,砸钱训练视觉分词器 = 打水漂。
所以之前大家都放弃治疗了,第一阶段随便训练一下,把主要精力放在第二阶段的扩散模型上。
海螺这次反其道而行之,把精力放在了第一阶段 —— 视觉分词器预训练上。
而且还解开了一个困扰行业多年的问题 —— 第一阶段的视觉分词器终于展现出了 Scaling Law。
请看这张图 ——
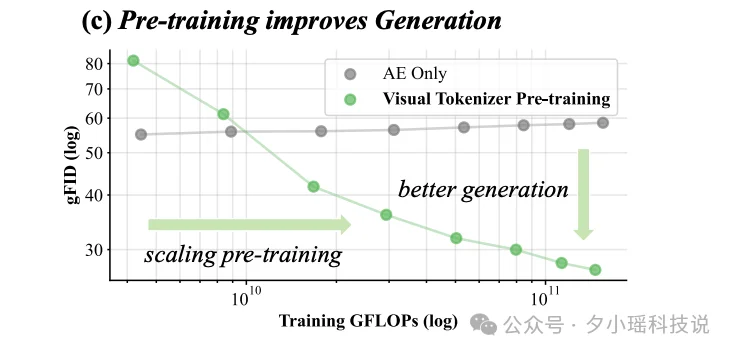
横轴是训练算力(GFLOPs),纵轴是生成质量 gFID(数值越低越好)。
灰色线代表传统的 Auto-Encoder,它几乎是一条水平线,即使算大扩大 10 倍,但是 gFID 基本没变,稳定卡在 55-58 之间。这就是之前说的 “打水漂” 现象。
但绿色线完全不一样。VTP 的曲线从左上角的 80 多,一路清晰地下降到右下角的 27 左右。
同样是扩大 10 倍算力,传统方法几乎没收益,而 VTP 能获得 65.8% 的性能提升。
这个数字可太关键了。它意味着投入和产出之间终于有了相对可预测的对应关系。
而且,scaling 不只体现在算力这一个维度。
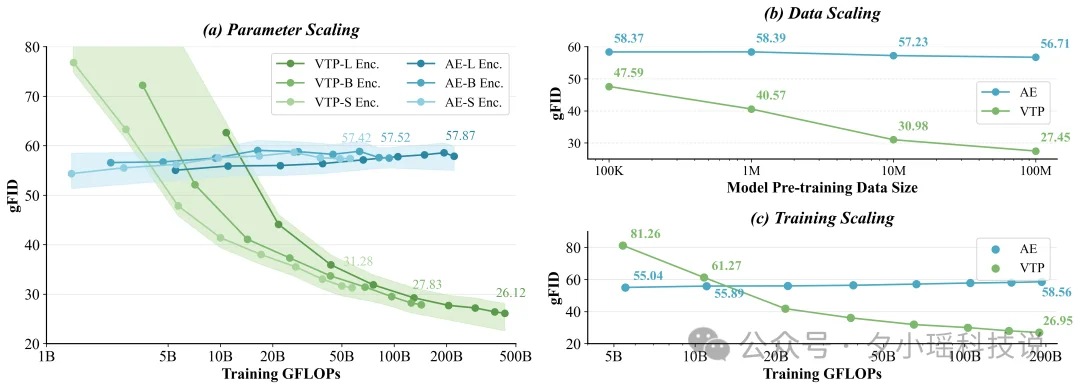
左边是参数缩放 Parameter Scaling。传统 AE 的三条蓝色线 (Small/Base/Large) 几乎重叠在一起,无论模型大小,性能都卡在 57 上下,完全没有分层。而 VTP 的三条绿色线则清晰地分开了,肉眼可见地下降。
右上角是数据缩放 Data Scaling。AE 从 10 万数据训练到 1 亿数据,gFID 只从 58.37 微降到 56.71,几乎可以忽略。而绿色线则从 47.59 大幅下降到 27.45—— 数据越多,效果提升越明显。
右下角是训练过程的 scaling。蓝色线 AE 在 5B GFLOPs 之后就完全平了,而绿色线一路从 81 持续降到 27。
这三张子图放在一起,传达的信息非常明确了。
VTP 在算力、参数、数据三个维度上都展现出了显著的 scaling 特性。
这三组实验里第二阶段的扩散模型训练配置完全相同,所以改进都来自第一阶段视觉分词器的预训练。
所以不是第一阶段不能 scaling,而是方法不对。
那 VTP 是用了什么方法才有了 scaling 呢?为什么传统方法不行。
原因在于海螺团队发现了一个有意思的规律:
理解力是驱动生成的关键因素。
论文里有张图 ——
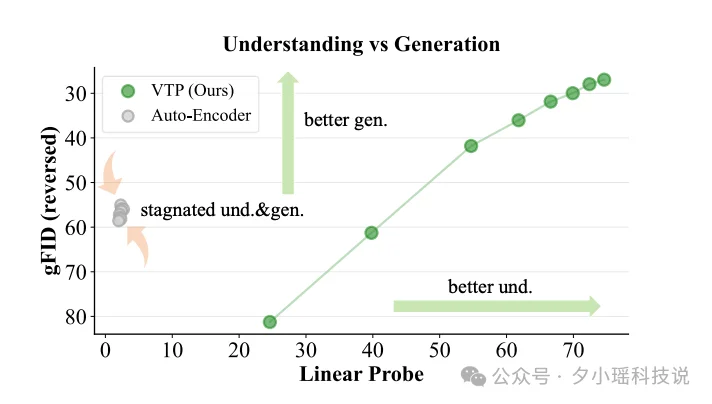
横轴表示理解能力,数值越高,说明模型越懂图像的语义。纵轴是生成质量 gFID,这里做了个 reversed 处理,所以数值越高代表生成越好。
灰色代表传统 AE,全部挤在左上角,意思就是理解和生成都停滞了。
绿色的点则相反地形成了一条漂亮的斜线,从左下角一路上扬到右上角 —— 理解能力从 20 多飙升到 70 多,生成质量也同步大幅改善。
这条斜线揭示了一个关键规律:理解能力和生成能力几乎是完美的正相关。
你让模型更 "懂" 图像,它就能生成得更好。反过来,如果只追求重建不追求理解,理解能力上不去,生成能力也永远卡在那里。
so,海螺在训练过程中注入了「理解」这个维度。也是整篇论文最核心的技术方法。
这里不得不提一下,之前的视觉分词器几乎只被要求做好一件事:重建。
就是给它一张图,它把图压缩,再尽可能一模一样地还原出来。还原得越像,loss 越低,训练就越成功。
所以你能感觉到,图像生成的分辨率越来越高,纹理越来越干净,边缘越来越锐利,连头发丝都越来越逼真。
但是这种训练目标,会悄悄把模型的注意力,全部引向低层细节(纹理、边缘、噪点、色块变化、像素之间的微小差异)。
这些东西,对 “还原一张图” 很重要,但对 “生成一段有意义的视频”,现在这个阶段,并没有那么重要了。
现在生成模型需要的是另一类信息:
这是一个人,他在跑,动作从左到右连续变化,背景是花园,这是一个 “跳跃” 的动作....
这些都是语义级、结构级的信息,而传统的重建训练,并不会主动去保留它们。
海螺在 VTP 里,让视觉分词器不仅学重建,还学理解。
因为设计了一个三管齐下的训练方案,整体架构可以就是这张图。
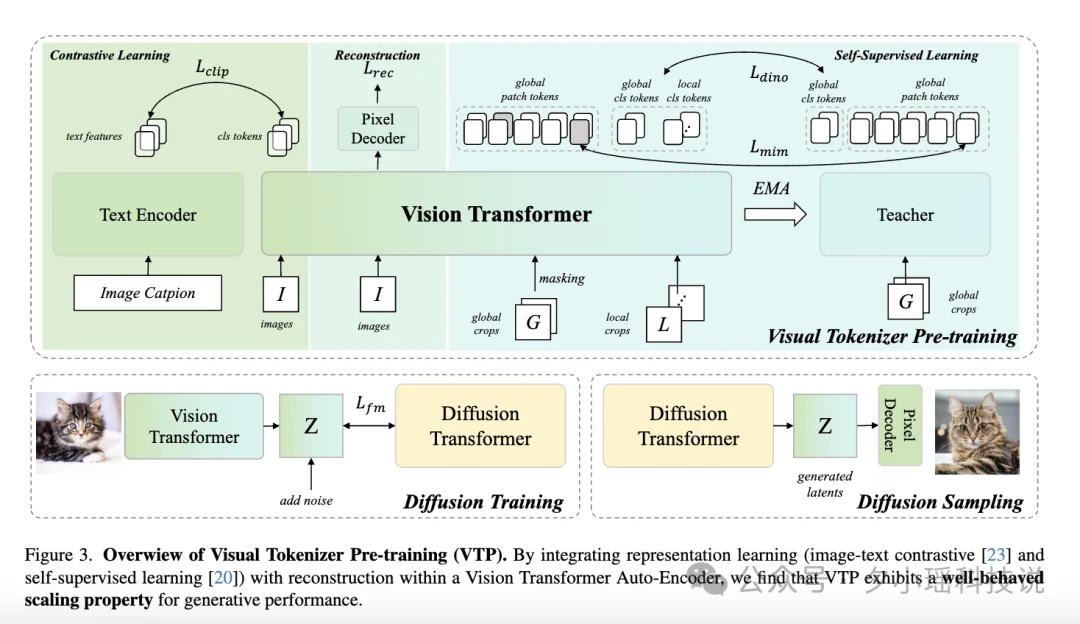
策略上做了三个 loss 的联合优化:
1.重建任务 (Reconstruction)
保留传统的图像压缩 - 还原训练,图像 → 编码 → token → 解码 → 像素还原,确保 latent 空间依然能稳定对应真实世界,保证基础质量。
2. 图文对比学习 (CLIP)
让模型学习图像和文本的语义对齐 —— 比如一只猫在草地上,这段文字和对应图像要在语义空间里靠近。这逼着模型去理解语义而不只是像素。
3. 自监督学习 (SSL)
包括两个技巧:
这三个任务联合训练,逼着视觉分词器学会既能重建细节,又懂高层语义。
实际效果如何?论文也给出了详细的 benchmark:
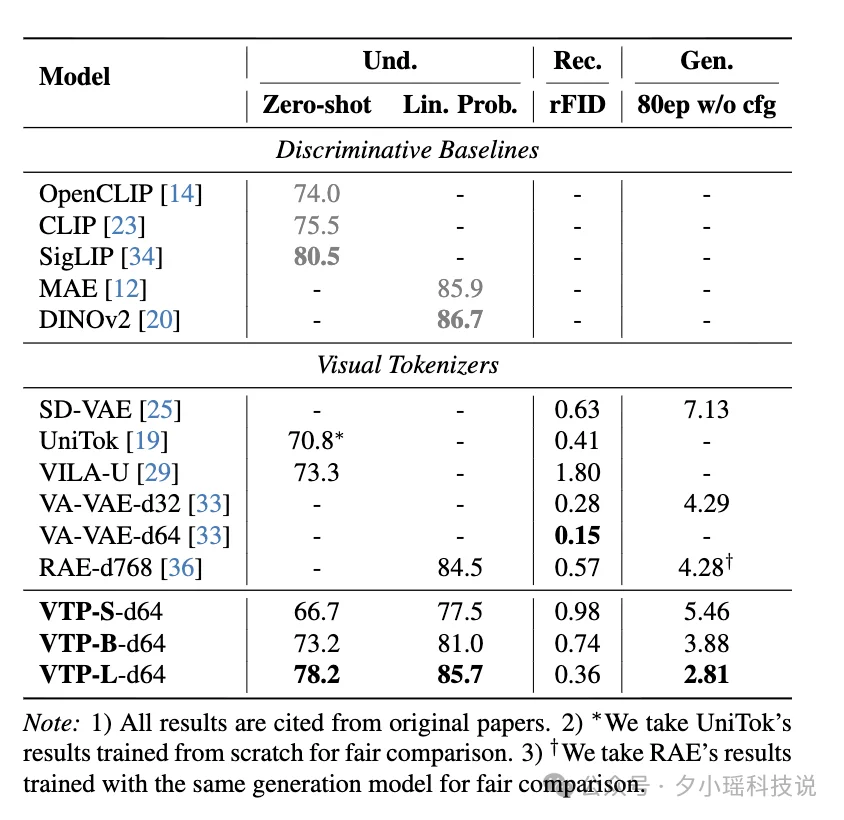
从结果来看,VTP-L(Large 版本)是少数几个在“理解、重建、生成”三项指标上同时交出成绩的模型。
在理解能力上,VTP-L 的 ImageNet zero-shot 达到 78.2,Linear Probe 达到 85.7,已经接近部分主流判别式视觉模型。而这在过去几乎不会发生在一个 tokenizer 身上。
最后说一点:
大家都在盯着 Sora 2、可灵 2.6、Seedance 1.5 这些应用层的更新——更长的视频、更高的分辨率、音画同步,很重要。
但是技术革新更重要。否则没了地基,其他免谈。
Minimax 这篇论文不只适用于视觉生成,对整个多模态 AI 都有启发。模型不只是要完美还原,也需要语义级的深度理解。
海螺这次开源了完整的模型权重、训练代码和详细技术报告。
Codes:https://github.com/MiniMax-AI/VTP
Paper:https://arxiv.org/abs/2512.13687v1
以后第一阶段的 tokenizer 也不再是「拿来主义」,可以做更深入的研究。从这个角度看,VTP 的开源可能比某个新视频模型的发布更有长期价值。
文章来自于“夕小瑶科技说”,作者 “夕小瑶编辑部”。



