# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在文生图(Text-to-Image)和视频生成领域,以FLUX.1、Emu3为代表的扩散模型与自回归模型已经能生成极其逼真的画面。
但当你要求模型处理复杂的空间关系、多物体交互或精准的数量控制时,它们往往会“露怯”:不是把猫画到了窗户外面,就是把三个苹果画成了四个。
为了解决这个问题,学术界此前主要有两条路:
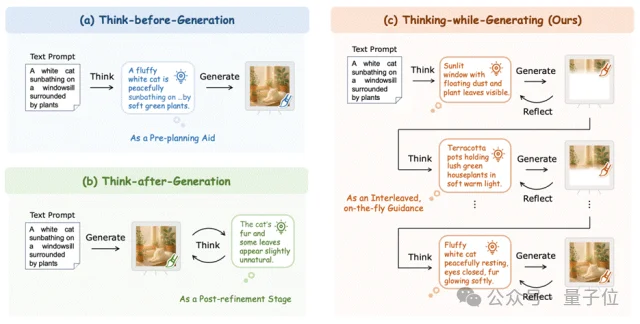
一条是“谋定而后动”(Think-before-Generation),即在画第一笔之前,先写好详细的布局计划。但这就像让画家在动笔前必须把每一笔都想得清清楚楚,一旦开画就无法更改,缺乏灵活性。
另一条是“亡羊补牢”(Think-after-Generation),即先把图画完,再通过多轮对话来挑错、修改。这虽然有效,但往往意味着巨大的推理开销和漫长的等待时间。
那么,有没有一种方法,能让模型像人类画家一样,在作画的过程中停下来看一眼,既能审视刚才画得对不对,又能为下一笔做好规划?
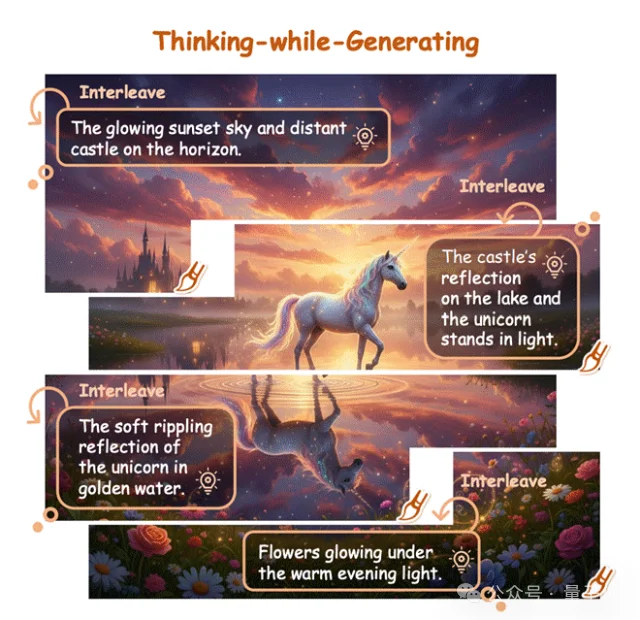
近日,来自香港中文大学、美团等机构的研究团队提出了一种全新的范式——Thinking-while-Generating(TwiG)。这是首个在单一生成轨迹中、以局部区域为粒度,将文本推理与视觉生成深度交织(Interleave)的框架。
如果说之前的视觉生成是“一口气跑到底”,TwiG则更像是一种“间歇性思考”。
研究团队受到大语言模型(LLM)中思维链(Chain-of-Thought)的启发,但他们反其道而行之:不再是用图片辅助推理,而是用推理来引导作画。
在TwiG的框架下,视觉生成不再是一个黑盒的连续过程,而是被拆解为“生成-思考-再生成”的循环。模型会在绘制过程中多次“暂停”,插入一段文本推理(Thought),用于总结当前的视觉状态,并指导接下来的生成。
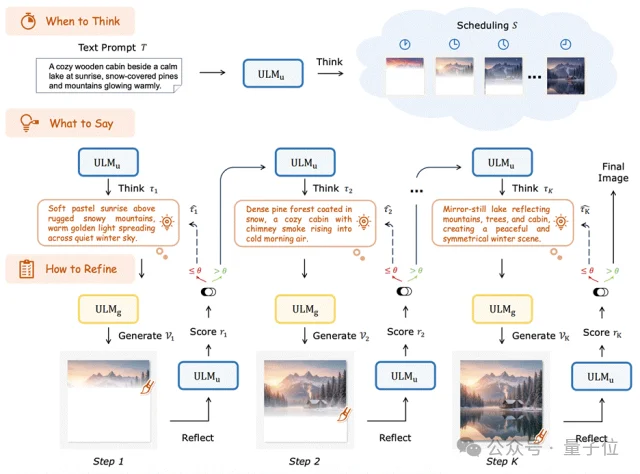
1. When to Think(何时思考):模型首先会根据用户的Prompt(提示词),规划出一个“思维时间表”。研究发现,将画面生成过程拆解为3个阶段效果最佳,这恰好符合图像通常包含“上部背景、主体内容、下部背景”的语义结构。
2. What to Say(思考什么):在每个暂停点,模型会生成一段“思维链”。这段文本不仅承接了上文的逻辑,更像是一个微型的路书,专门指导接下来的局部区域该怎么画。这种细粒度的引导,比那种“一句Prompt走天下”的方式要精准得多。
3. How to Refine(如何修正):在画完一个局部后,模型会立刻进行自我批判(Self-Reflection)。如果发现画歪了或者颜色不对,它会立刻触发“重画”机制,只修正当前的局部,而不需要推倒重来。
为了验证这一范式的潜力,研究团队在统一多模态模型(如Janus-Pro)上进行了层层递进的实验。
Zero-Shot潜力惊人
仅仅通过精心设计的Prompt,而不需要任何参数更新,模型就已经展现出了强大的“边画边想”能力。
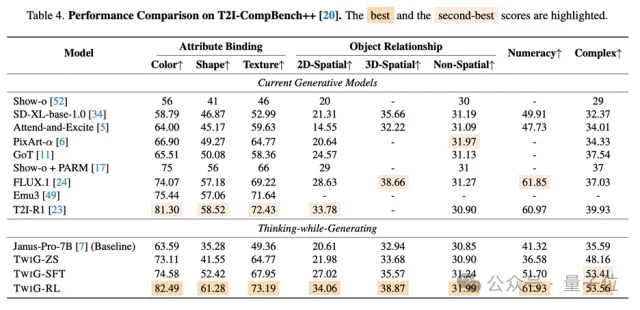
在T2I-CompBench基准测试中,Zero-Shot版的TwiG(TwiG-ZS)在属性绑定、空间关系等多个维度上显著超越了基准模型。
结果表明,在合适的interleave约束与提示下,现有多模态模型已具备一定的在生成过程中进行推理的潜力。
SFT提升稳定性
团队进一步构建了包含50K数据的高质量数据集TwiG-50K,对模型进行监督微调(SFT)。结果显示,SFT有效减少了模型“胡思乱想”产生的幻觉,让生成的思维链更加简练、可控。
RL突破上限
团队采用了针对TwiG优化的GRPO策略(Group Relative Policy Optimization),让模型在“何时思考、思考什么、如何修正”的策略上进行自我博弈和进化。
实验数据显示,经过RL训练的TwiG-RL,在T2I-CompBench++的多个关键组合与空间指标上,展现出与Emu3、FLUX.1等模型具有竞争力、甚至在部分维度上更优的表现。

TwiG的提出,不仅是一种技术上的优化,更是一种观念上的转变。它试图打破视觉生成模型的“黑盒”属性,通过引入可读的文本推理,让生成过程变得透明、可控且具有逻辑性。
研究团队的结论可以总结为以下几点:
1. 生成需要逻辑:单纯的像素概率预测难以处理复杂的逻辑约束,引入显式的文本推理是必经之路。
2. 修正优于重绘:相比于画完再改的“大动干戈”,在生成过程中进行局部的即时修正是更高效的策略。
3. RL是关键:强化学习不仅能优化最终的图像质量,更能教会模型如何思考,是挖掘多模态模型推理潜力的关键钥匙。
目前的TwiG中的具体实现与实验验证主要基于自回归ULM(如Janus-Pro),但框架在设计上对扩散模型同样兼容。这种“边生成边思考”的范式有望扩展到视频生成、3D建模等更复杂的领域,为通往真正的通用视觉智能提供新的拼图。
论文题目:Thinking-while-Generating: Interleaving Textual Reasoning throughout Visual Generation
论文链接:https://arxiv.org/abs/2511.16671
项目主页:https://think-while-gen.github.io
文章来自于“量子位”,作者 “TwiG团队”。



【开源免费】LGM是一个AI建模的项目,它可以将你上传的平面图片,变成一个3D的模型。
项目地址:https://github.com/3DTopia/LGM?tab=readme-ov-file
在线使用:https://replicate.com/camenduru/lgm
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
