# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
为什么Agent在演示时无所不能,到了实际场景却频频拉胯?
一篇长达51页的论文研究了自ChatGPT以来的主要智能体,给出参考框架:适应性是其中关键。
智能体定义上不是只会被动回答的AI,而是能自己规划、用工具(比如搜索引擎、代码编译器、数据库)、记东西,一步步完成复杂任务。
当遇到新任务、新环境时,不需要重造一个新的智能体,而是通过 “微调自己” 或 “优化工具”,快速适配需求(比如从写普通代码适配到写垂直行业代码)。

这篇论文作者阵容豪华,来自UIUC、斯坦福、普林斯顿、哈佛、UC伯克利等12所高校的三十多位研究者联手,由UIUC的韩家炜教授团队领衔,共同一作Pengcheng Jiang,Jiacheng Lin,Zhiyi Shi为UIUC博士生。
团队认为,当前Agent系统的核心瓶颈在于适应性:模型如何根据反馈信号调整自身行为。
为此,他们提出了一个2×2的分类框架,把现有的适应方法切成了四大范式。
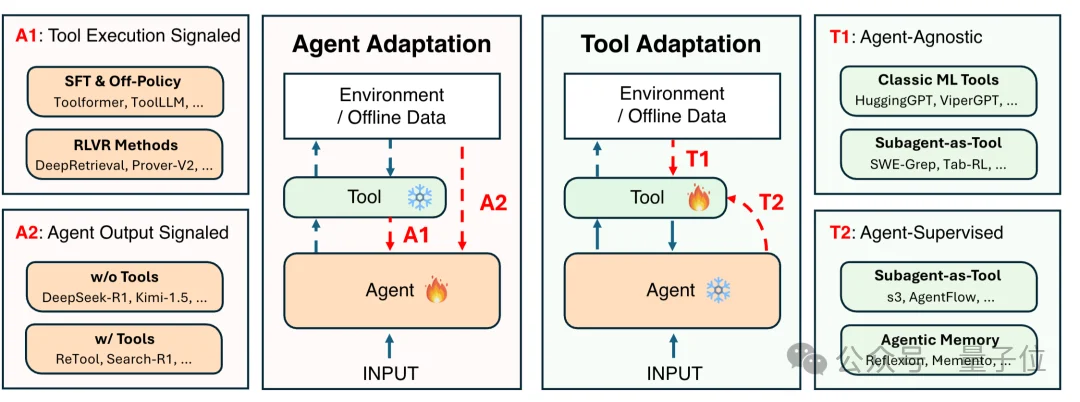
第一个维度是“优化谁”:是优化Agent本身(Agent Adaptation),还是它调用的工具(Tool Adaptation)。
第二个维度是“信号从哪来”:是来自工具执行的结果,还是来自Agent最终输出的评估。
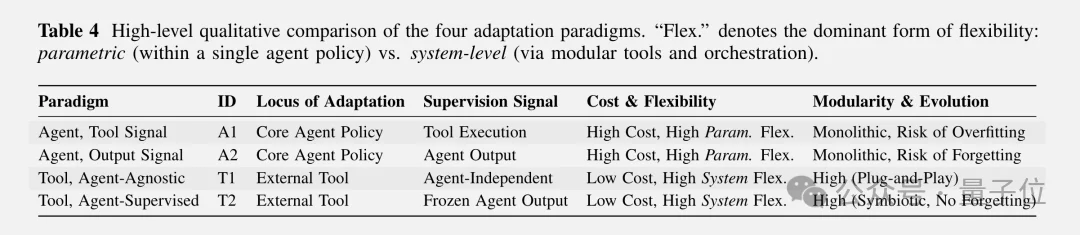
据此分成四类:
A1范式让Agent根据工具执行的反馈来学习,比如代码能不能跑通、检索结果准不准。
A2范式则是用Agent的最终答案作为优化信号,典型代表就是DeepSeek-R1这类用强化学习训练推理能力的工作。
T1范式是即插即用:工具独立训练好,Agent直接调用,比如SAM、CLIP这些预训练模型。
T2范式让工具反过来根据Agent的输出来优化自己,形成一种共生适应的关系。

这样分类之后,有两个好处:
开发遇到问题时,不用盲目试错。想让AI更擅长工具的使用细”,就选 A1;想让整体推理更靠谱,就选A2;想让工具通用好用,就选T1;想让工具适配特定AI,就选 T2。
另外也明确了trade-off。改AI(A1/A2)灵活但成本更高,需要重新训练模型。改工具(T1/T2)省钱,但受限于 AI 本身的能力。
论文中还有一个关键发现:T2范式的数据效率远超A2范式。
以检索增强生成任务为例,Search-R1采用A2范式端到端训练Agent,需要约17万条训练样本。
而采用T2范式,只训练一个轻量级的搜索子智能体来服务冻结的主模型,仅用2400条样本就达到了相当的效果。数据量减少了约70倍,训练速度快了33倍。
更值得注意的是泛化能力的差异。在医学问答这种专业领域测试中,T2训练的智能体达到了76.6%的准确率,而A2训练的Search-R1只有71.8%。
论文分析认为,这是因为A2范式要求模型同时学习领域知识、工具使用技能和任务推理三件事,优化空间过于复杂;而T2范式下,冻结的大模型已经具备知识和推理能力,小模型只需要学习“怎么搜”这一项程序性技能。
论文最后指出了Agent适应性研究的四个前沿方向。
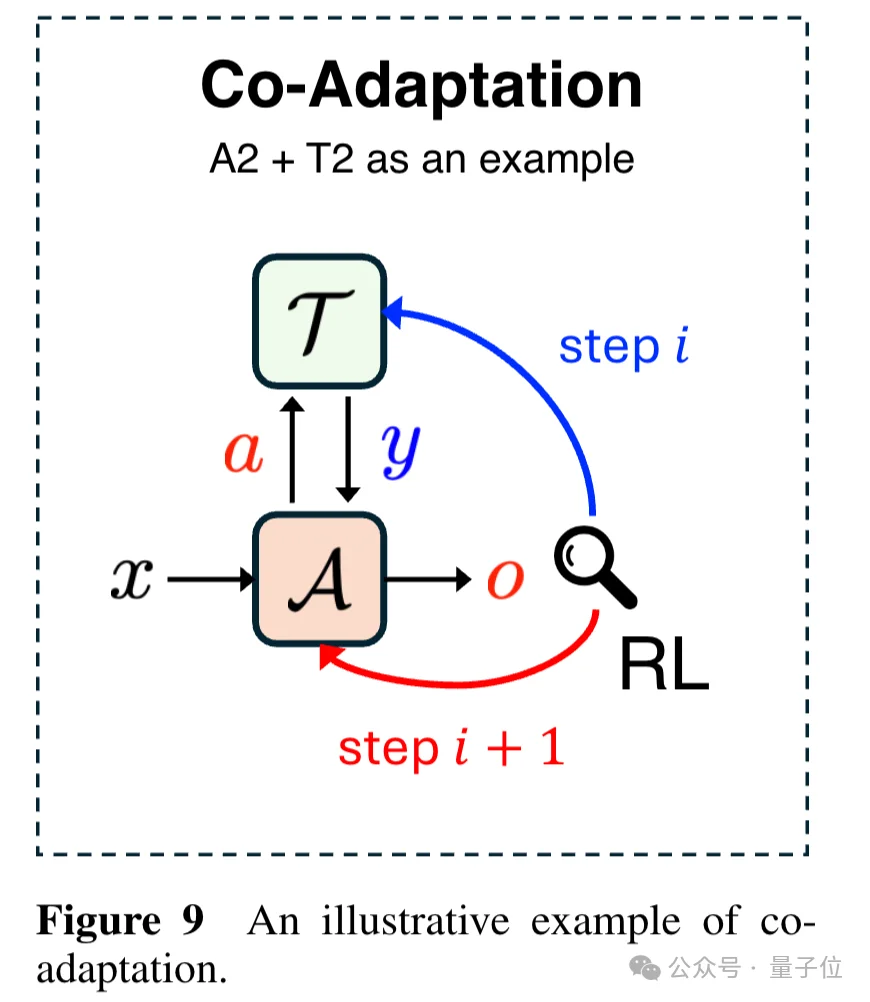
协同适应(Co-Adaptation)是最具挑战性的课题。目前几乎所有方法都是“冻一个、调一个”,但未来理想的系统应该让Agent和工具在同一个学习循环中相互优化。这带来了复杂的信用分配问题:任务失败了,到底该怪Agent还是工具?
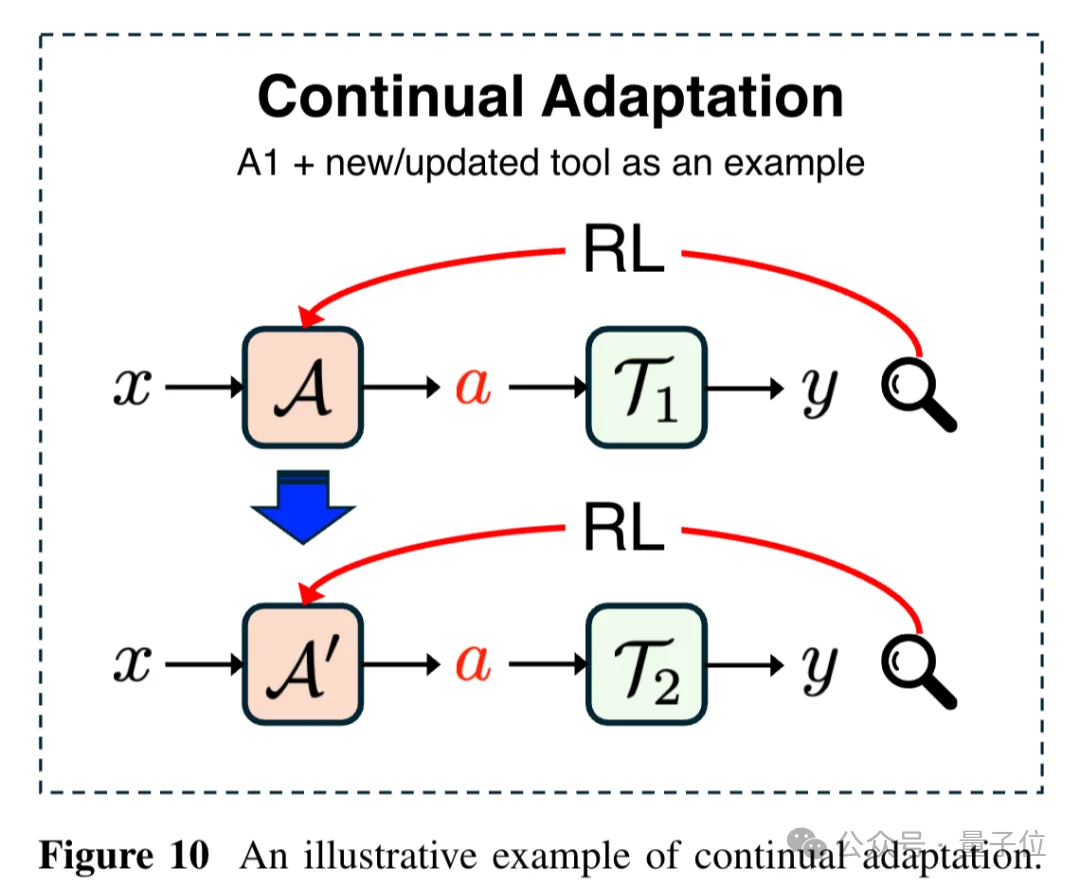
持续适应(Continual Adaptation)针对的是真实世界的非平稳性。任务分布会随时间变化,工具会更新,用户需求会演进。如何让Agent持续学习新技能而不遗忘旧能力,是部署层面的核心难题。
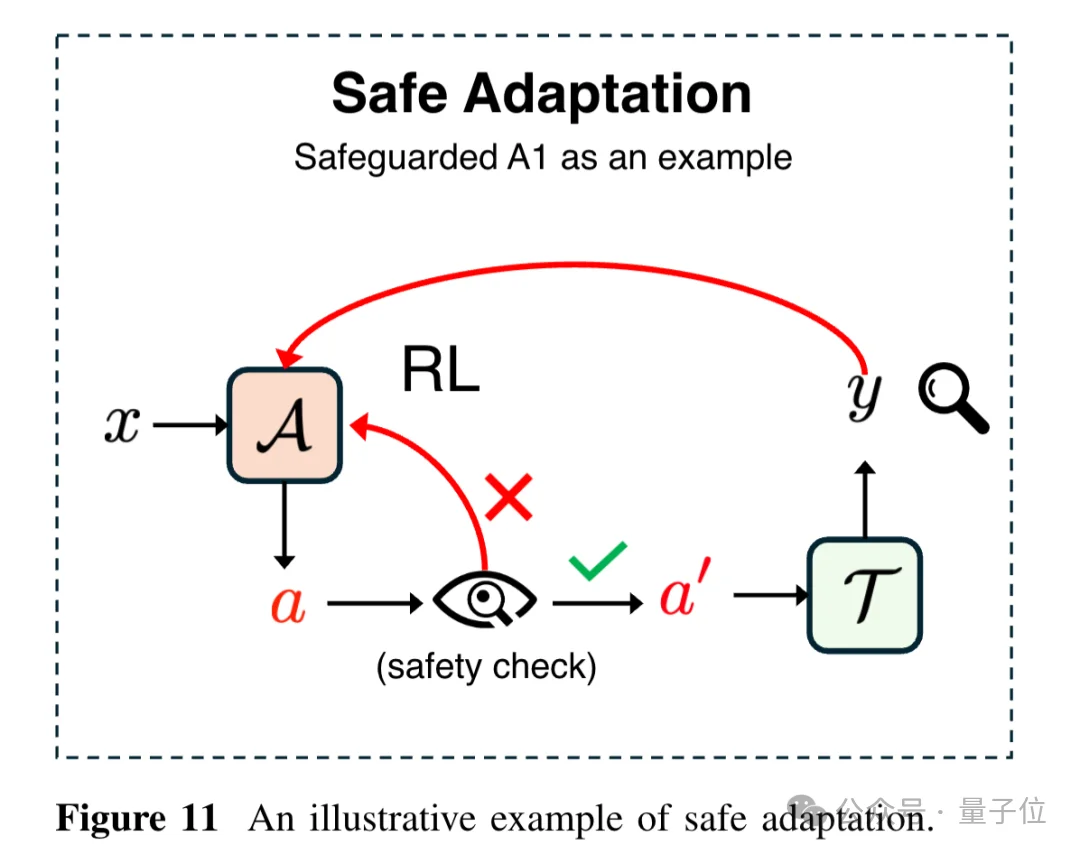
安全适应(Safe Adaptation)揭示了一个令人担忧的现象:大模型在强化学习优化推理能力的过程中,会逐渐侵蚀掉监督微调阶段建立的安全护栏。模型学会了用复杂的“思维链”给自己的违规行为编造理由,反而更容易被越狱攻击。
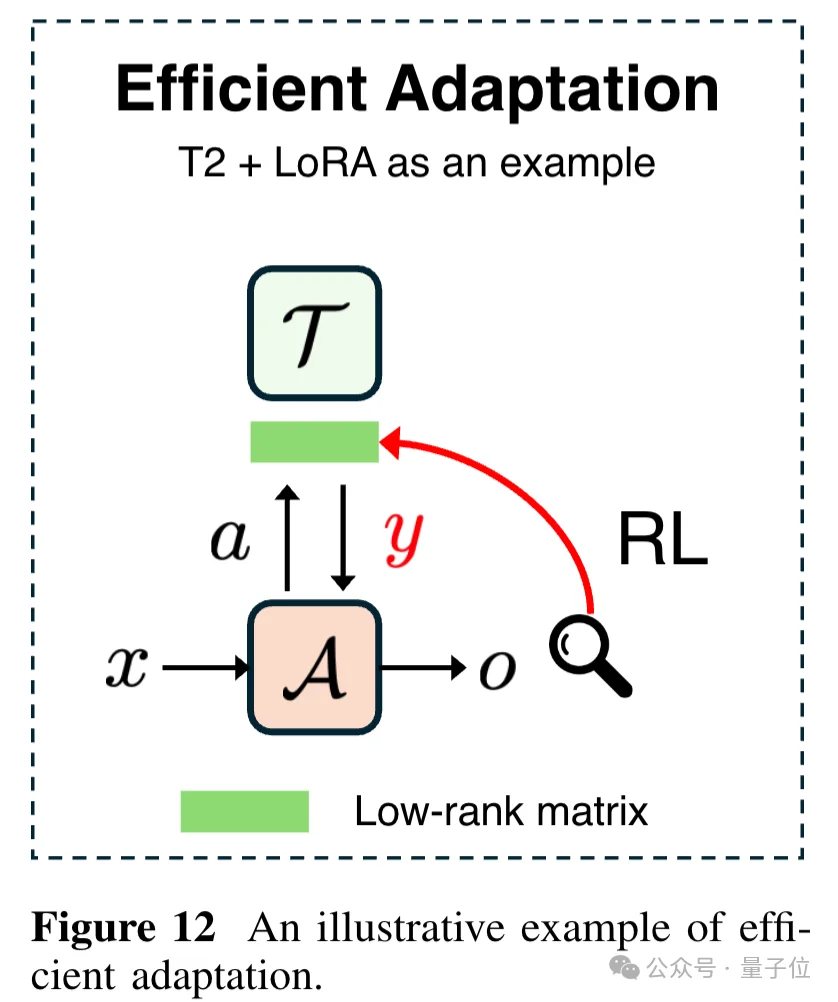
高效适应(Efficient Adaptation)关注的是资源受限场景。论文介绍了LoRA在强化学习中的应用、FlashRL的量化加速技术,以及端侧设备的个性化适应方案。
这篇综述的GitHub仓库已经开放,持续收录相关论文和资源。对于正在搭建Agent系统的开发者来说,这份51页的“适应性指南”或许能避开一些坑。
论文地址:
https://arxiv.org/abs/2512.16301
Github:
https://github.com/pat-jj/Awesome-Adaptation-of-Agentic-AI
文章来自于“量子位”,作者 “梦晨”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
