# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今天,我又要来得罪人了。
甚至可以说,这篇文章发出来,可能会直接断了很多人的财路。
起因是我前几天分享的两篇关于n8n工作流的文章,彻底爆了:
这10个n8n工作流,直接干死了90%的Tiktok视频生产,一键直出100条
这几天应该有超过500人加我微信。。但因为我还在外面出差,导致很多消息回复很慢
加我的很多同学都想学n8n,还有一部分让我帮忙定制的
但我把送上门的钱,全推了。
为什么? 往小了说,复杂的企业级交付太重,个人工作室预算又太低,这生意没法做。 往大了说,由人类手工搭建工作流的时代,已经结束了。
我知道这句话会得罪一堆做n8n培训和代搭建的人。
但事实就是如此残酷:AI技术的本质就是平权,它存在的意义就是把那些昂贵的、原本属于少数人的技术壁垒,夷为平地。
之前我就发过两篇文章预警:
n8n已死!我用Kimi跑通了Claude Skills,直接替代工作流
当时很多人不信,觉得我在博眼球。
今天,我不仅要帮大家省下这笔定制费,我还要一次性把底牌亮出来:
跑一个专门用于生成n8n工作流的Claude Skills。
首先第一步就是解决AI选型的问题。工具无需质疑Claude Code依然最强。
但AI大模型怎么选?
昨天群里就有人吐槽说国外大模型的账号被封了,但又没解决方案,很焦虑
其实,现在国产AI真的牛逼,有一说一,虽然不能说超过海外御三家,但是日常应对90%的工程项目其实都没有问题了,例如智谱今天发布的GLM-4.7。
为什么我敢这么说?因为我从 GLM-4.5 时代就开始用了,还写过几篇文章,属于是一路看着它一步步变强的。 刚好我自己之前就订购了智谱的 GLM Coding Plan,今天正好直接用旧的套餐,来测测这个新发布的 GLM-4.7 到底几斤几两。
我第一时间去看了硬指标,只看我们做 Claude Skills 最需要的核心能力:Coding(编码) 和 Reasoning(推理)。
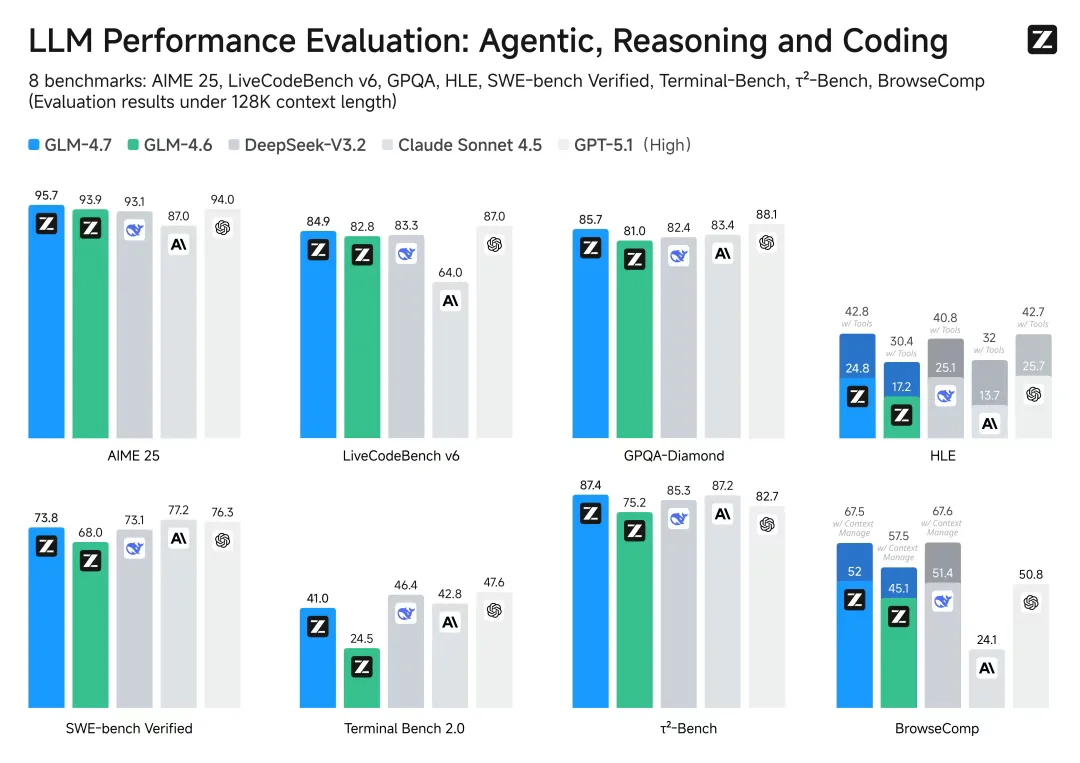
就只看2点用得上的:
所以,结论很简单:
如果你的目标是搞定工作流,GLM-4.7 是目前性价比最高、最稳的解法。
但实战如何?我们就拿它来跑今天的需求,看它到底怎么个事。

首先,目前GLM-4.7的型号是glm-4.7-coding-preview
可以参考这段代码设置好Claude code:
mkdir -p ~/.claude && cat > ~/.claude/settings.json <<EOF
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "在此处填入您的智谱API_KEY",
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7-coding-preview",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.7-coding-preview",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.7-coding-preview"
}
}
EOF
这是我MacBook的配置
配置完成后,当你再次进入 Claude Code,你会看到底层的驱动引擎已经换成了 glm-4.7-coding-preview。

很多人用 AI 生成工作流失败,是因为让 AI “凭空想象”。 n8n 的节点参数非常复杂,凭空生成的 JSON 往往连导入都会报错。
我的思路完全不同:我不让 AI 创造,我让它“抄作业”。 也就是:Context Learning(上下文学习)。
(这个逻辑在之前文章讲过,建议先看一下)
也就是说要让AI先到网上根据我的需求找已经存在的类似工作流。
之前我是手动用ChatGPT找完再处理的,到底能不能用Claude code纯自动跑完我是没底的。
所以要先试下,参考提示词:
请你调用 playwright mcp到https://n8n.io/workflows/ 下载10个用veo3.1生成视频的工作流json到本地文件夹,流程是打开网站后会有一个搜索框,输入相关的关键词后,下面会出现result的部分,选择合适的,点进去会进入工作流的介绍页面,判断合适后,左边会有`use for free`按钮,点击后会有弹窗,点`copy template to clipboard[json]`,此时工作流代码就已经在剪贴版了。
接下来,就在本地新建一个json文件把代码粘贴进去即可。注意工作流文件的命名要跟网页上的一致。如果有看到关于use cookies的弹窗,就关掉。
卧槽,牛逼!看来这个逻辑是对的,如图左边已经自动新建好了veo_workflows文件夹并且已经有了9个n8n工作流json文件了。
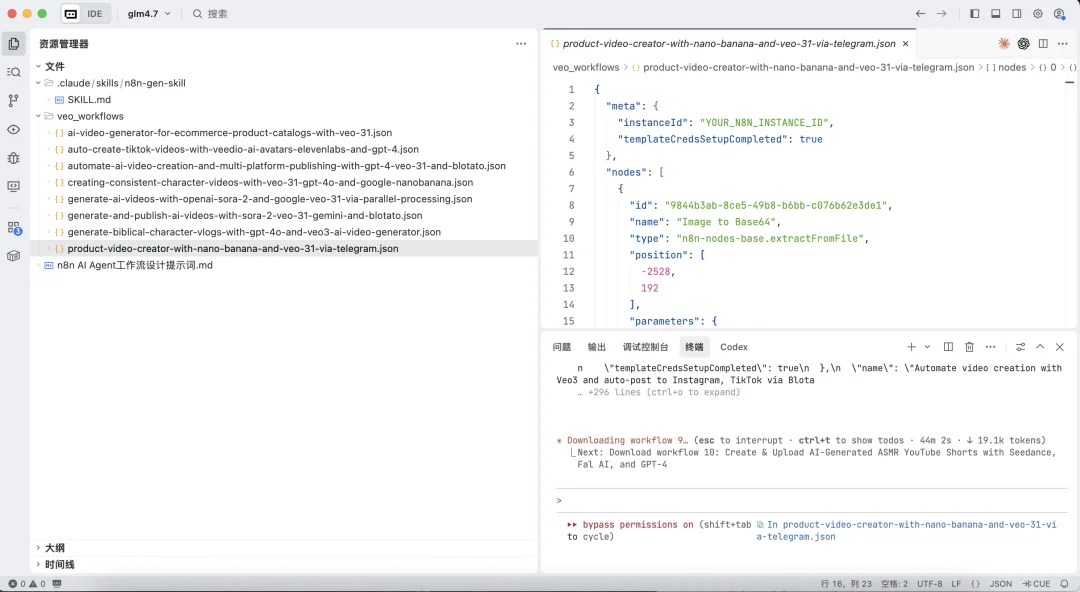
这个过程看出来GLM-4.7 在工具调用(Tool Use)上的表现非常稳。它精准地识别了网页元素,完成了点击、弹窗处理、复制 JSON 的全套动作。
当然,用playwright的效率还是比较慢的,完全就可以用AI写一段python或者js的爬虫代码来抓
例如可以观察一下网页,地址是https://n8n.io/workflows/?q=加上搜索词veo3.1+tiktok
应该不难,大家自己试下。
素材有了,接下来就是最关键的一步:Prompt Engineering(提示词工程)。
我设计了一个n8n AI Agent 工作流设计专家指令:
👍太长了,关注公众号「饼干哥哥AGI」
后台回复n8n skill获取完整版
# n8n AI Agent 工作流设计专家指令
你是一位精通 n8n 自动化与 AI Agent 架构的首席解决方案架构师。你的任务是根据用户输入的业务需求,结合本地参考的工作流模版,构建一个**工业级、模块化、可直接导入**的 n8n 工作流 JSON 文件。
## 1. 输入处理与上下文学习
### 1.1 深度分析参考系 (Context Loading)
你拥有访问 `n8n_references/` 目录下 10 个已下载工作流 JSON 文件的权限。在开始设计前,你必须:
1.**遍历阅读**:逐个分析这些 JSON 文件的结构。
2.**提取模式**:识别文件中优秀的逻辑结构,特别是:
...
### 1.2 用户需求解析
分析用户输入的自然语言需求,拆解为:
***输入源 (Inputs)**: 用户从哪里提供数据 (Form, Google Sheet, Webhook?)
***处理核 (Core Logic)**: 需要经过哪些 AI 处理 (LLM Analysis, Image Gen, RAG?)
***输出端 (Outputs)**: 结果发送到哪里 (Email, Slack, Database?)
---
## 2. 架构设计原则 (Design Philosophy)
### 2.1 AI Agent 核心化
除非用户需求极度简单(如纯数据搬运),否则**必须使用 `AI Agent` 节点**作为核心大脑,而不是简单的线性 Chain。
...
### 2.2 逻辑复用 (Logic Reuse)
**不要凭空创造节点配置。**
...
### 2.3 模块化与可视化 (Modularity)
生成的工作流必须清晰易读,严禁生成“意大利面条式”的混乱连线。
***使用 Sticky Notes 分区**:必须利用 n8n 的 Sticky Note 功能,将工作流划分为不同区域(Color-coded),例如:
...
### 步骤 4:生成 JSON
* 输出必须是**纯净的 JSON 格式**,符合 n8n Workflow Schema。
* 确保 `nodes` 数组和 `connections` 对象完整对应。
* 确保所有引用的节点 ID 是唯一的。
它有多牛逼?
这部分可以补充阅读之前的文章,但这次会更简单。
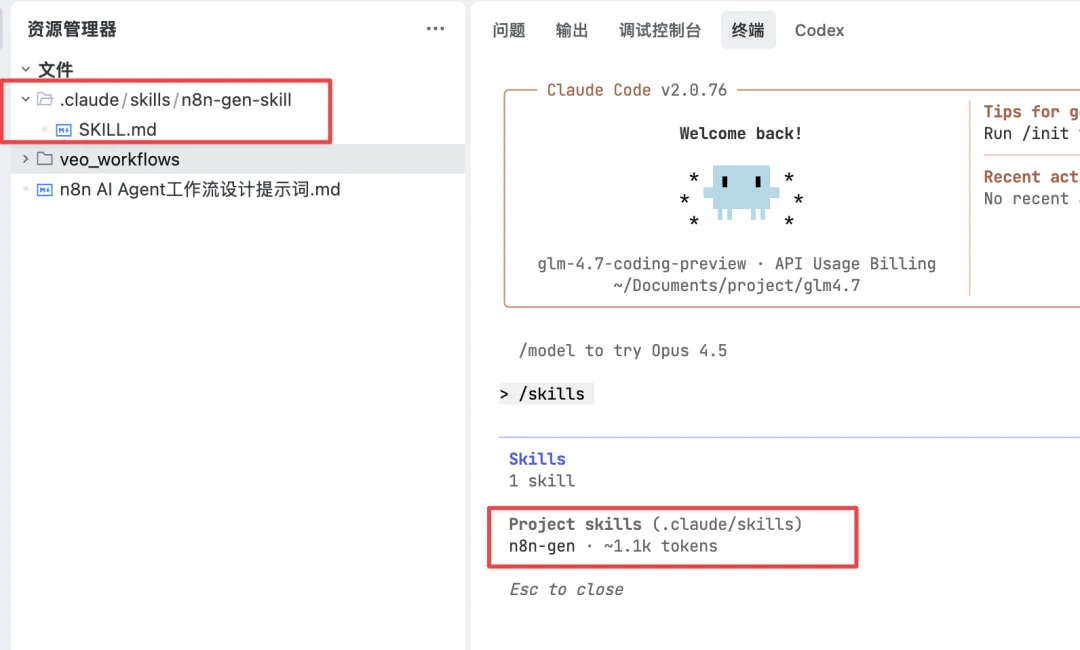
在项目文件夹下生成文件夹.claude/skills
Claude Code会自动读取里面的skill文件夹,例如n8n-gen-skill
再到里面,新建一个关键的SKILL.md
👍太长了,关注公众号「饼干哥哥AGI」
后台回复n8n skill获取完整版
处理好后,我们输入/skills,就会看到如图已经读取好了
接下来就测试一下:
帮我做一个用veo3.1生成tiktok带货视频的n8n工作流,要求每天定时晚上11点跑工作流,先读取我的谷歌表格,把状态为未完成的记录提取出来,里面是我放到的产品图、拍摄风格,需要你循环逐个图片作为参考图,连同拍摄风格传给veo3.1来生成视频,把生成好的视频,下载后上传到谷歌云盘,最后把视频地址同步回谷歌表格,同时这行标记状态为已完成。
老规矩,看到下图中n8n-gen-skill前面有绿灯,才证明是正在使用skill

处理完成。n8n_output 文件夹里多了两份文件。
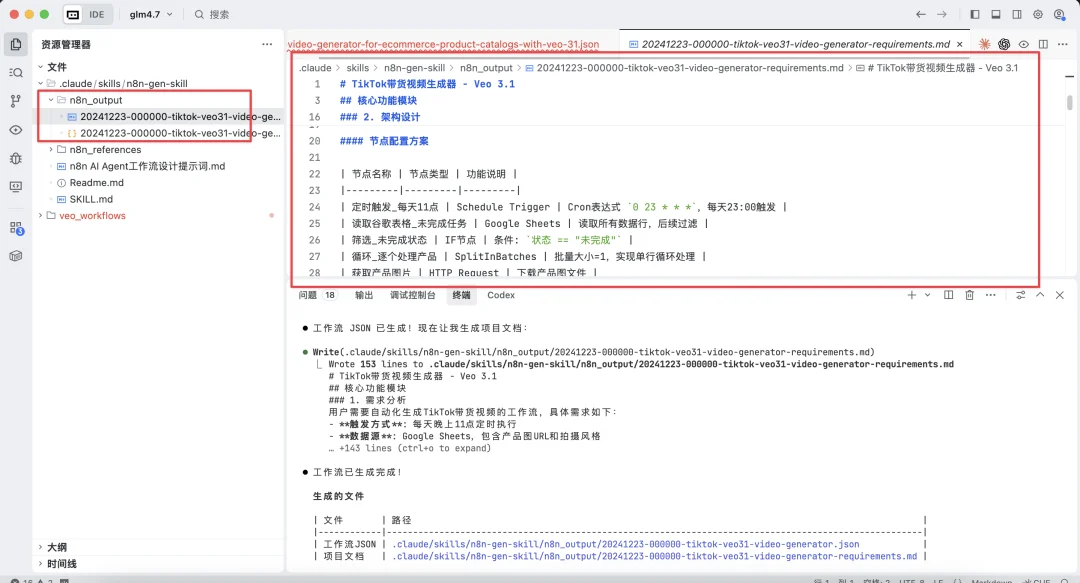
第一份:需求说明文档(Markdown)
这简直是乙方的救星! 里面详细记录了架构设计、节点配置方案,甚至连 Google Sheets 的表头结构都定义好了。你直接把这个丢给客户,专业度瞬间拉满。
直接解决了很多人拿到工作流后不知道怎么配置的问题。


第二份:n8n 工作流 JSON
我把生成的 JSON 文件直接导入 n8n。
太牛逼了!!我发誓我没有修改任何一个节点,这样的工作流,还不是傻瓜线形的,甚至连循环判断都是正确了,真的能省很多事。
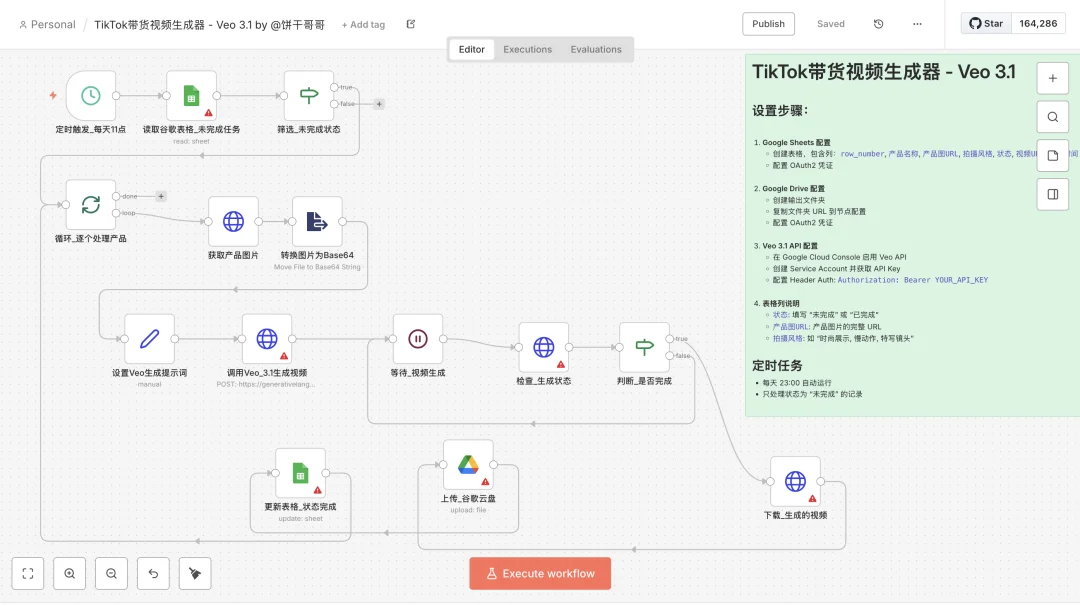
这就是 GLM-4.7 + Context Learning 的威力。 它不是在“生成”,它是在“理解”了业务逻辑之后,像一个高级架构师一样在“构建”。
看到这里,你明白我开头为什么敢“断人财路”了吗?
以前你的护城河,是背下了几百个节点的参数,是熬夜试错的经验。 但就在刚刚,GLM-4.7 用几分钟的“思考”,把这些壁垒瞬间夷为平地。
说实话,这次 GLM-4.7 真的给了我一种久违的惊艳感。
不仅仅是它现在开源第一, 而是因为那些纸面的参数,在业务落地中变成了实实在在的提效——当我把生成的 JSON 导入 n8n,发现连循环逻辑、API 鉴权都严丝合缝,不需要我手动改一个标点符号。
这证明了它的思考模式 绝不是噱头。 它不再是一个只会补全代码的工具,而是一个真正拥有逻辑推理能力、能读懂你业务上下文的架构师。
以前,你的上限是你双手的速度;
搭配时下最强AI,你的上限仅取决于你的想象力。
文章来自于“饼干哥哥AGI”,作者 “饼干哥哥AGI”。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
