# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大家好,我是被智谱卷到的袋鼠帝。
昨天智谱刚把GLM-4.7放出来,群里就有老哥找我写文章了..
智谱也太卷了🥹,于是,我又被迫加班了
从平安夜奋战到了圣诞节,终于在今天把这篇文章发出来了,不容易啊
正好我一直以来想做一个产品,我这次用Codex + GLM-4.7 + Claude Code,从0到1做了一个一键生成海外营销数字人短视频的平台(MVP项目)

我觉得作为半天内搓出来的项目已经相当nice👍,具体的开发经验稍后分享。
在这之前,我先跟大家说说GLM-4.7这次更新了些什么
这次升级的点,其实很集中,基本就落在四个关键词上:前端、全栈、Agent、写作。
1.前端更漂亮了:GLM-4.7这次前端审美大幅提升了,生成的前端将会更好看;
2.编程能力提升:提升多语言编程能力(全栈开发能力),开发复杂项目更得心应手;
3.Agent能力更强了:工具调用能力提升,在τ²-Bench交互式工具调用评测中得到87.4分,成为开源SOTA,超过了Claude Sonnet 4.5。提升了数学和推理能力,在HLE(人类最后的考试)基准测试获得42.8%,较GLM-4.6提升41%,超过了GPT-5.1
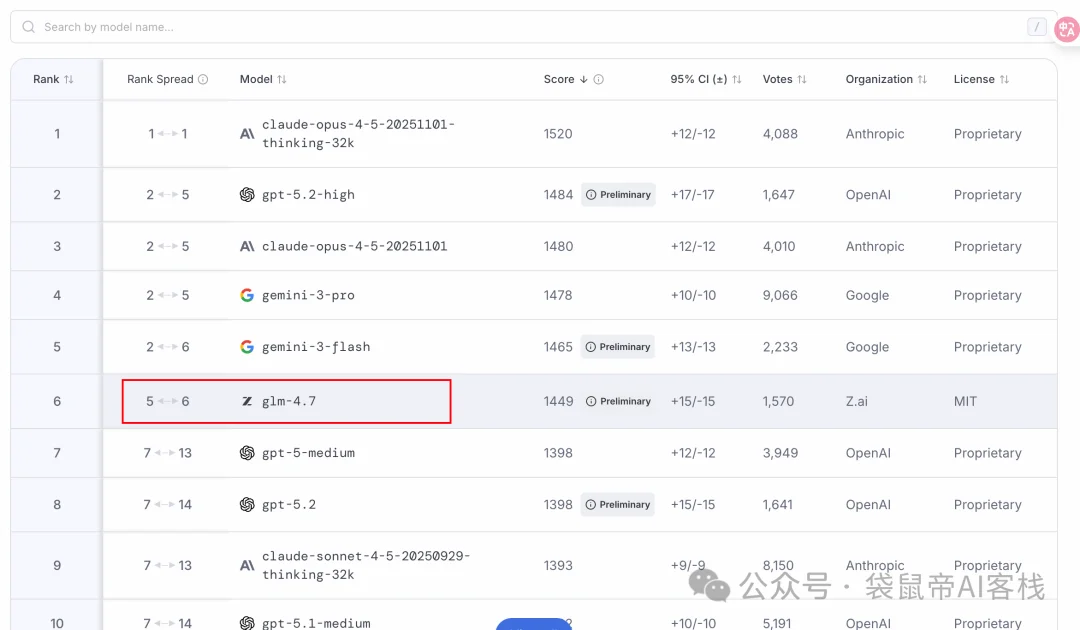
4.Code榜杀疯了:在Lmarena的全世界Code盲测排行榜上排名第6,超越了GPT-5.2。
5.情商也更高了,写作和角色扮演方面也有加强。
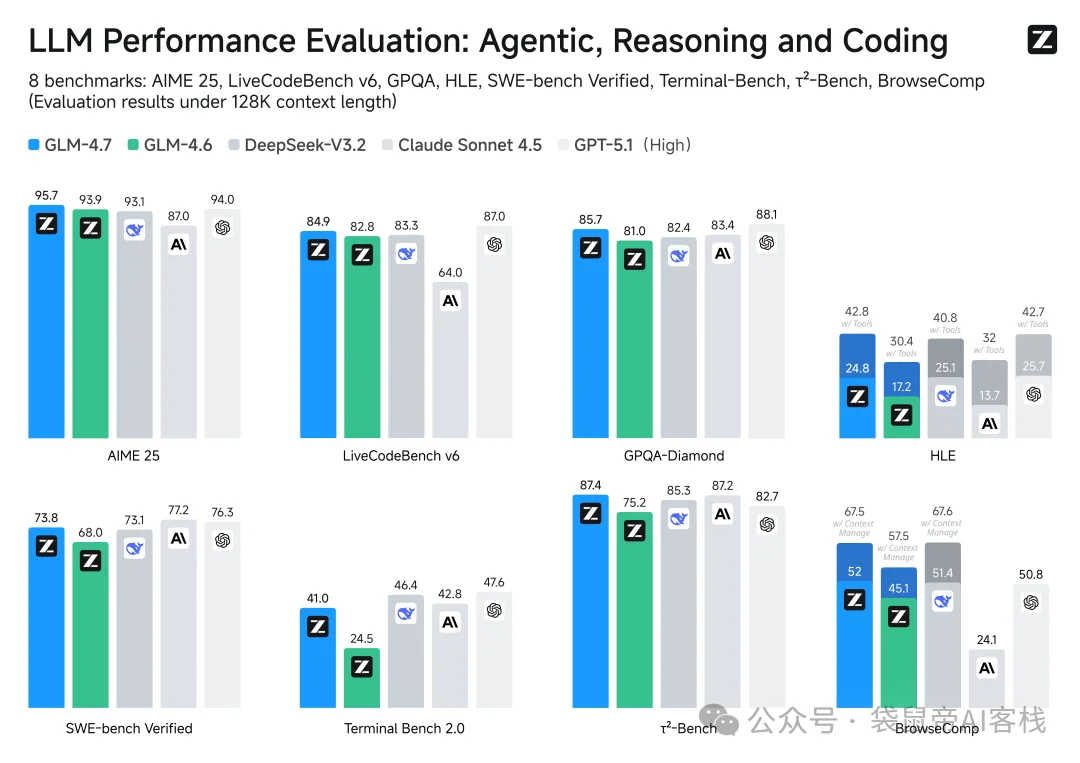
其实这些跑分我都看麻了,现在我主要看Lmarena的排行,因为这里是全世界所有人盲测投票出来的结果。
GLM-4.7作为开源模型,在编程方面能干到世界第6也是挺意外的
再回到我比较关心的事儿。
这些升级,能不能在一个真实产品里兑现呢。
所以我这次不想搞Case了,也不搞什么花活
我用Codex + GLM-4.7 + Claude Code,尝试在一天之内,做完一个海外营销数字人短视频生成平台的MVP。
现在回头看,这个想法本身,其实比结果更有意思。
我先简单说下这个MVP项目是干啥的。
逻辑比较清晰,大概率能赚米:
一段口播(音频)+数字人结合产品(图片)+视频Prompt(文字)=数字人营销短视频
文案由GLM-4.7生成,通过TTS(可以用开源的index-tts)转成语音
图片可以由香蕉 Pro生成,也可以自己上传
视频Prompt也可以由GLM-4.7生成
最后的数字人由开源的infiniteTalk模型生成
流程大致如下:

这不是随便搞的,而是一个真实存在需求的产品形态。
因为我最近一直在研究AI数字人视频的开源方案,现在数字人开源方案逐渐成熟,并且效果已经很不错了,但是真正卡住大家的,不是模型效果,而是把这些能力整合成一个完整产品的工程。
这个平台,把制作数字人短视频SOP化了,而且的本很低,意味着可以把AI数字人的价格打下来。
而正好,GLM又升级了,好像除了用GLM-4.7,没有别的更好的选择了,毕竟这是目前接入Claude Code性价比最高的模型
对了,用量大可以选择包月,更划算,文末有折扣二维码
这次开发的平台难度有点高,我刻意把节奏放慢了一点,没有一上来就写代码。
现在AI做任何事情,上下文才是关键
所以第一步,我们需要花大量的时间在写需求上。
页面长啥样?用户咋流转?哪里同步哪里异步?用谁的API?数据库存啥?
这个阶段的初期,其实非常反AI,全是人脑在工作。
但如果你跳过这一步,后面就会发现,靠模型写得越快,返工越狠,离你的预期越来越远。
第二步,我把自己梳理的需求初稿交给了接入了GLM-4.7的Codex。
codex梳理需求很好用,GLM-4.7接入Codex的方法,放到最后了
不是让它写代码,是让它帮我评审需求,挑毛病,找出待确认的地方,然后不断跟它对话,对齐需求,这几轮来回,非常重要。
因为它逼着你把脑子里那些模糊的想法,变成可以落地的更详细的需求。
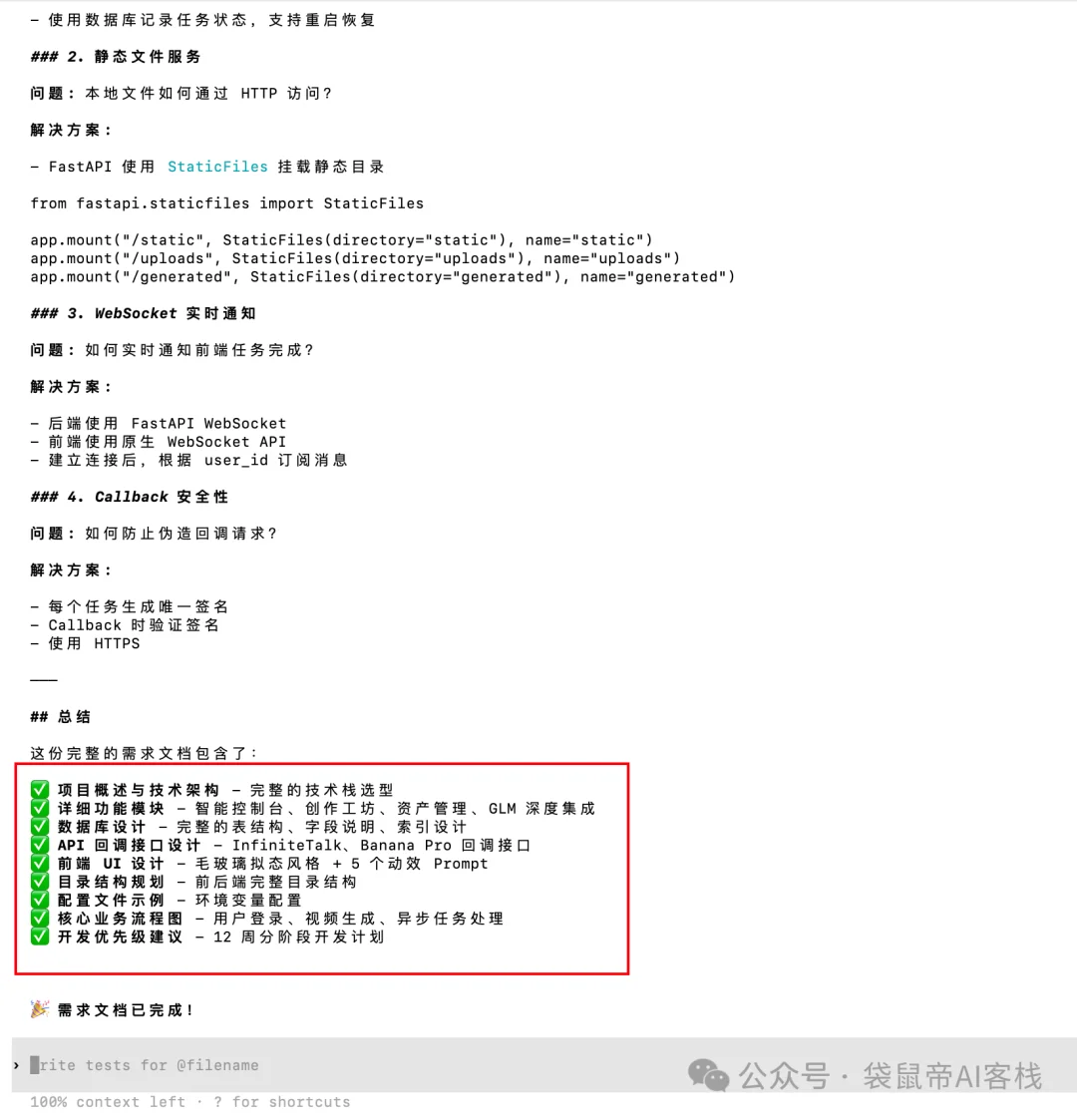
最后,GLM-4.7给我输出了一份一千三百多行的超详细的需求文档。
从技术架构、选型到接口定义,从数据库表结构到前端UI布局等9大块(见上图),几乎把后面所有容易出问题的地方都提前铺平了。
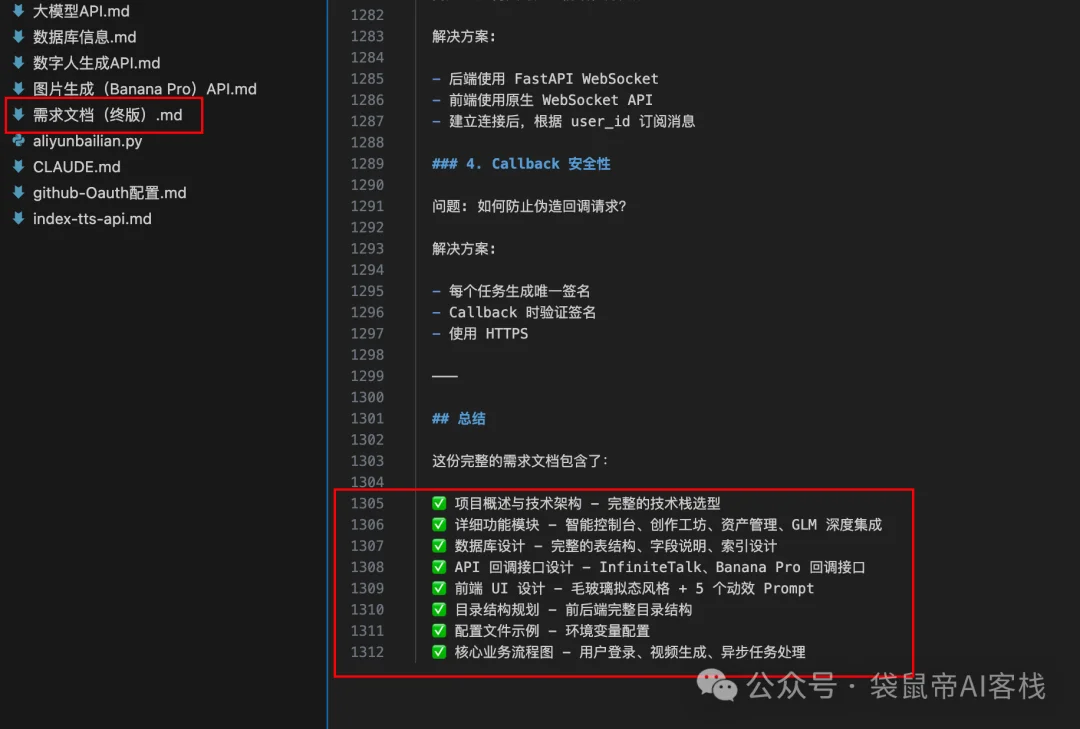
第三步:梳理需要用到的第三方API(请求、响应示例、apikey等)、数据库信息(地址、端口、用户名、密码、数据库名称)

第四步:直到这一步,我才让GLM-4.7+Claude Code进场。
还是不要一上来就写代码,先执行/init,让Claude Code熟悉目录下的所有文件,包括需求文档
然后开Plan Mode(计划模式)制定一个开发计划。

确认没问题之后,才开始一段一段往下写。

开发完成之后,可以让GLM-4.7帮忙快速启动前后端(过程中需要下载相关依赖,它都完成得很好)
不过这个任务还是太复杂了点,不仅有复杂的业务逻辑,还集成了大量AI能力
GLM-4.7一次性跑完之后是有一些Bug的。
但我觉得现阶段应该不会有模型能一次完成得很好,而且没有bug。
这里我有一个非常明显的体感变化:
以前我用大模型写复杂项目,最怕啥?最害怕的不是写不出来,而是改Bug。
让它修一个报错,它可能顺手把旁边已经稳定的功能一起改了....
然后bug就越改越多,甚至还会为了完成任务造假,最后整个项目可能都改废了。。
这种感觉就像你让他修厨房的水龙头,他修好了,但回头把你卫生间的水管给踩爆了。这种按下葫芦浮起瓢的感觉,真的让非常抓狂!

以前用一些规则和或者直接在Input Prompt里面约束会稍微好一点点
这次GLM-4.7牛逼的地方在于,它知道边界在哪。
能判断清楚这个问题属于哪个模块,影响边界在哪里,只在必要的位置做修复。
这会让你真正敢放手把项目持续交给它推进,而不是每一步都担惊受怕,动不动就要回滚。
每找到一个问题,它都能立马解决,整个项目非常确定的在朝着越来越好的方向发展,这一点就足以封神了
GLM-4.7的审美和前端能力也有明显的提升,特别是在一些小细节上
你看这边框的流光

这个卡片的聚光灯效果,也非常棒

整个过程需求、各种API信息整理大概3个小时
编码和调试花了4个多小时,这里面包含了,前端的UI设计,功能逻辑,后台的接口、功能,还有跟数据库,以及第三方API的交互等等。
最后,一个功能完整、界面效果也不错的出海营销数字人短视频生成平台(MVP项目),就这样跑通了。
还有一个点,更现实。
Claude Code,本身就非常消耗token,如果用国外的模型,我可能会下意识压缩提示词,减少上下文。
不是不想给信息,是钱包着不住...但开了GLM Coding Plan包季的我变得非常豪横,疯狂给Claude Code灌信息,因为试错成本很低。
我不再担心每一次修改的成本,关注的重心完全回到了结果本身。
当然,现阶段GLM-4.7在特别长的任务里,偶尔还是会忘记早期的一些设定,需要你提醒。
一次性生成的复杂项目,也然需要人工Review和微调。
但技术本身正在被GLM系列的开源模型快速平权。
特别是从GLM-4.5开始,我就觉得智谱在大模型方面越来越对味了。
我还记得7月底的厦门之行,我们一众博主在一起讨论,都发自内心的被GLM-4.5的编程能力所惊艳。
直到国庆前几天,GLM-4.6又出来了,再次屠榜。时隔2个多月,又到4.7,编程和Agent能力都在不断升级,感觉这速度也忒快了,下半年开始就跟开了挂一样。
盲猜GLM-4.8或者GLM-5将在春节前夕发布。
希望下一代的GLM模型能原生集成多模态,在上下文长度方面再次突破,那将是一个在编程和Agent无敌的存在了。
所以,其实现在代码越来越不是事儿了,谁能找到需求、痛点,用最低成本,最快的速度把流程跑通,谁就是赢家。
我发现周围开始靠Vibe Coding赚到钱的人,大多不懂代码。
我也一直都觉得,AI时代,程序员好像反而是最难靠coding赚钱的人。
但是最近我思考了很多,我还是想打造自己的产品,我希望曾经引以为傲的技术能力,在AI时代更能放大它的价值。
接入Claude Code:
把下面的配置写到Claude Code的setting.json配置文件中
{
"env": {
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",
"ANTHROPIC_AUTH_TOKEN": "<GLM_API_KEY>",
"API_TIMEOUT_MS": "3000000",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": 1,
"ANTHROPIC_MODEL": "glm-4.7",
"ANTHROPIC_SMALL_FAST_MODEL": "glm-4.7",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.7",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.7"
}
}
接入Codex:
第一步:把下面这些配置写到codex的config.toml
[model_providers.glm]
name = "GLM Chat Completions API"
base_url = "https://open.bigmodel.cn/api/paas/v4"
env_key = "GLM_API_KEY"
wire_api = "chat"
requires_openai_auth = false
request_max_retries = 4
stream_max_retries = 10
stream_idle_timeout_ms = 300000
[profiles.glm]
model = "glm-4.7"
model_provider = "glm"
第二步,设置环境变量。
在你的终端里,执行以下命令,注意:把GLM_API_KEY替换成你自己的APIKey。
export GLM_API_KEY="你的GLM_API_KEY"
如果是Windows可以在PowerShell里面执行:
$env:GLM_API_KEY = "<GLM_API_KEY>"
第三步,使用codex --profile glm命令,指定模型来启动,这样Codex就会默认使用我们配置好的GLM-4.7模型了。
我是之前300直接包季了,在时间内不用考虑token消耗,就算开发项目疯狂用,也没有限流过, 挺爽的。
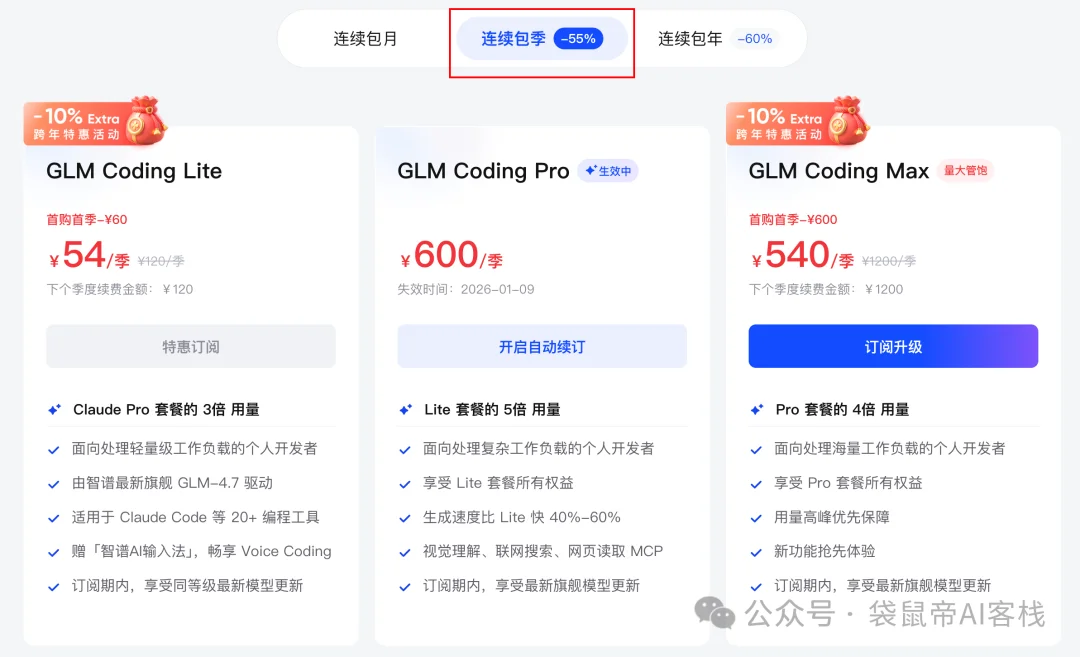
我还给大家争取到了专属优惠,扫描下面二维码,可以领取Coding Plan所有套餐的8折优惠券。

最后的最后,如果你也在观望AI编程,不妨给自己设一个具体目标,哪怕只是一个很小的产品,先把东西做出来。
很多答案,只有在真正跑通的那一刻,才会变得清楚。
你会愿意把核心产品的第一版,交给AI一起完成吗?欢迎评论区交流~
我是袋鼠帝,持续分享AI实践干货,我们下期见
文章来自于“袋鼠帝AI客栈”,作者 “袋鼠帝AI客栈”。



【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
