# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
诺奖得主Hassabis曾说过,未来十年,AI将会治愈所有疾病!
多模态大模型Scaling还在继续,每一次迭代,意味着我们离这一愿景又近了一步。
然而,现实却给我们泼了一盆冷水。
KFF最新一项调查显示,美国每6名成年人中,就有1人每月使用ChatGPT获取健康建议。
然而,结果令人震惊,仅有1/3的人信任AI给出的建议,大多数人还是持有怀疑的态度。

为什么人们一边热情拥抱AI,一边又心存疑虑?
根本原因在于:通用大模型,并不是为医疗而生的。
它们整体能力很强,但在高度专业的医疗场景中,却往往幻觉频出、缺乏严谨的临床验证。
这也正是医疗领域,需要专家级大模型的原因。
它不需要成为简单的「万能答案机」,而要做一名真正的「临床工作者」,才能赢得医患的信任。
在国内医疗AI赛道上,有一家企业,正在尝试打破这道信任壁垒——
云知声用了13年时间。
最近,在权威医疗评测MedBench4.0中,云知声斩获大语言模型、多模态模型和智能体评测「三冠王」。
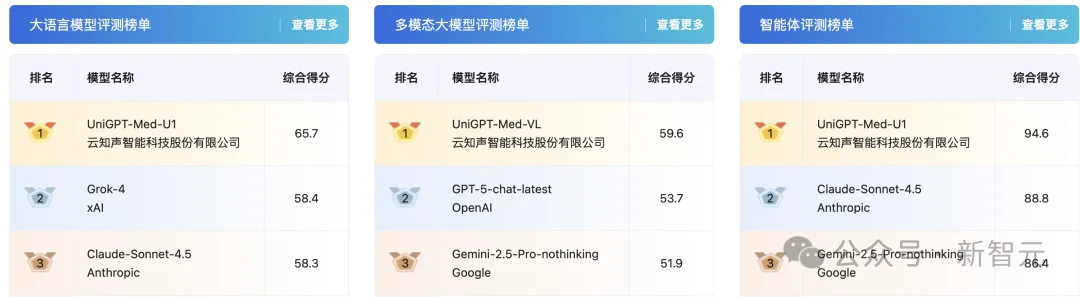
此次「三冠王」,是对山海大模型核心升级的肯定。
这不仅重新定义了医疗AI的天花板,也标志着AI真正走向严肃临床!
医疗AI,走到哪一步了?
Hassabis的预言并非空穴来风,放眼全球,AI在医疗领域正以惊人的速度展开。
有网友表示,「自己在每次看医生之前,都会进行一次AI会诊和评估。没有AI的医疗是失职的」。
可以看出,AI正逐渐成为个人医疗健康的重要参照物。
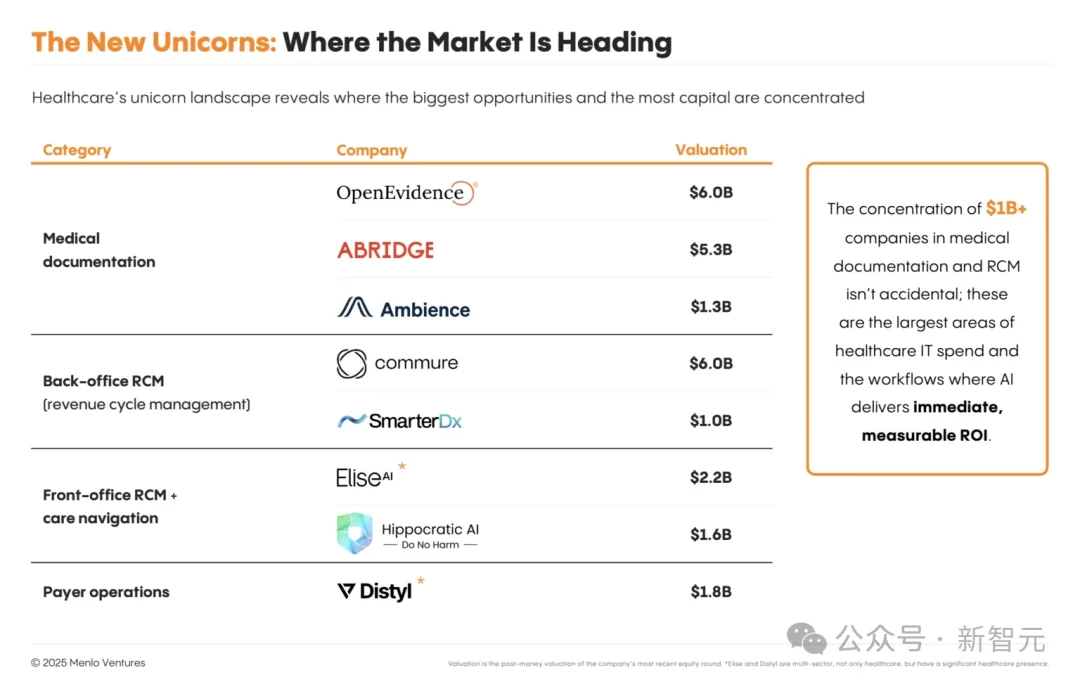
根据Menlo Ventures研究,今年有22%的医疗机构部署了特定领域的AI工具,这一数字是2024年的7倍。
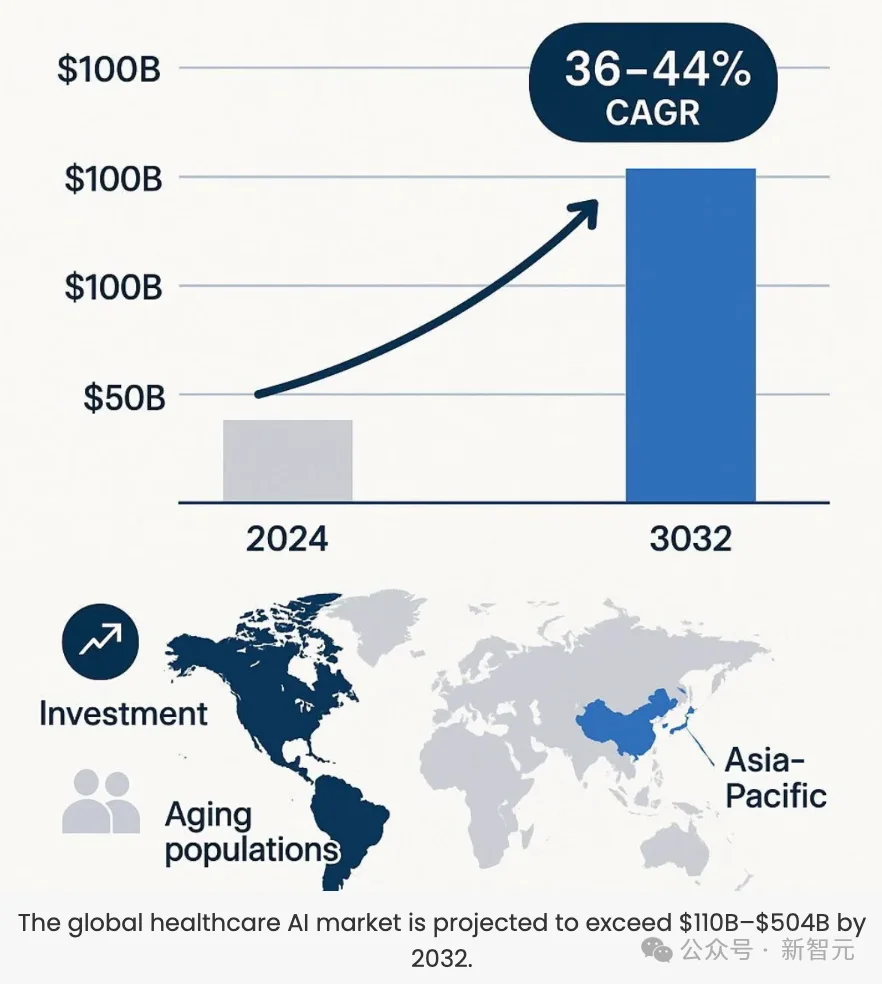
另有数据显示,预计到2032年,全球医疗AI市场规模将超过1100亿美元-5040亿美元。
在这一赛道上,不仅有谷歌、微软、OpenAI等科技大厂长期深耕,还有一些垂类的初创公司纷纷展开布局。
5月,谷歌DeepMind曾开源了强大的医疗模型MedGemma,在多模态医学文本和图像理解上表现优异。
同一时间,微软MAI-DxO诊断工具,可以协调多个AI医生的诊断,准确率号称达医生的4倍。
还有OpenAI在8月专为生命科学和蛋白质工程,定制了一款GPT‑4b micro。
此外,还有一些新晋的实力玩家,包括OpenEvidence、Commure等,集中在了医疗文书、后台/前台RCM等领域。
在临床实践阶段,AI已开始辅助医生处理日常问诊任务、实时检测患者健康、并通过预测分析预防疾病进展等。
然而,现实与理想之间仍横亘着重重痛点。
从技术层面来看,医疗场景存在诊疗路径的多元性,同一病历可能存在多种合理的路径,医生的经验、科室差异都会影响判断。
而KFF调查揭示的「信任危机」并非孤例。
由于医疗高度专业性,错误往往不会呈现「显性」,因此医疗AI最大的风险在于「答得看起来很对」。
但实际上,幻觉问题是最致命的。
从数据层来看,高质量医疗数据极其稀缺,因为数据分散在不同医院、系统,且标准不统一,含有大量噪声。
甚至,大量数据是「切片式」的,完整诊疗链路数据极少。
再加上,数据标注成本极高,一般由专业医生参与,很难像自动驾驶那样形成「自增强飞轮」。
在临床层面,最大困境在于,AI很难融入医生真实的工作流当中。
很多医疗AI产品失败的原因在于,把医生当成了「搜索用户」,而非「任务执行者」。
真正的临床医疗是「流程型工作」,AI不仅要擅长其中的某一步,还要理解前后的约束关系。
面对这些困境,我们不禁要问:一个平衡实用性、专业性、安全性的医疗AI存在吗?
答案,或许就在云知声「山海·知医大模型5.0」的身上。
它的诞生,标志着AI从单一的「智能工具」,转变为可靠的「临床协作者」。
山海·知医5.0登场
「临床协助者」时代开启
这么说吧,这一次「山海·知医大模型5.0」是云知声医疗AI的集大成之作,围绕临床需求展开了系统性重塑。
它采用了「医学文本+多模态」双引擎架构,在多项关键能力上实现全面提升。
一、全栈能力融合
过去医疗AI产品,往往以「模块化能力堆叠」为主——NLP负责病历结构化、影像模型辅助阅片......
这些能力虽各自有效,但缺乏统一语义空间与任务协同机制,在真实场景中,难以形成闭环。
要知道在临床中,诊疗是一条高度连续、动态演化的决策链条(非必要环节,依具体病况而定):
主诉→病史→检查→影像→诊断→路径选择→随访调整
山海·知医大模型5.0恰恰为门诊、住院等复杂诊疗场景提供「一站式」智能支持,打破了传统医疗AI功能单一的局限。
它实现了文本深度处理、智能体任务协同、影像多模态感知等全栈能力的融合。
这也就意味着,山海·知医大模型5.0可以处理知识问答、临床路径规划、影像报告解析等多元任务。
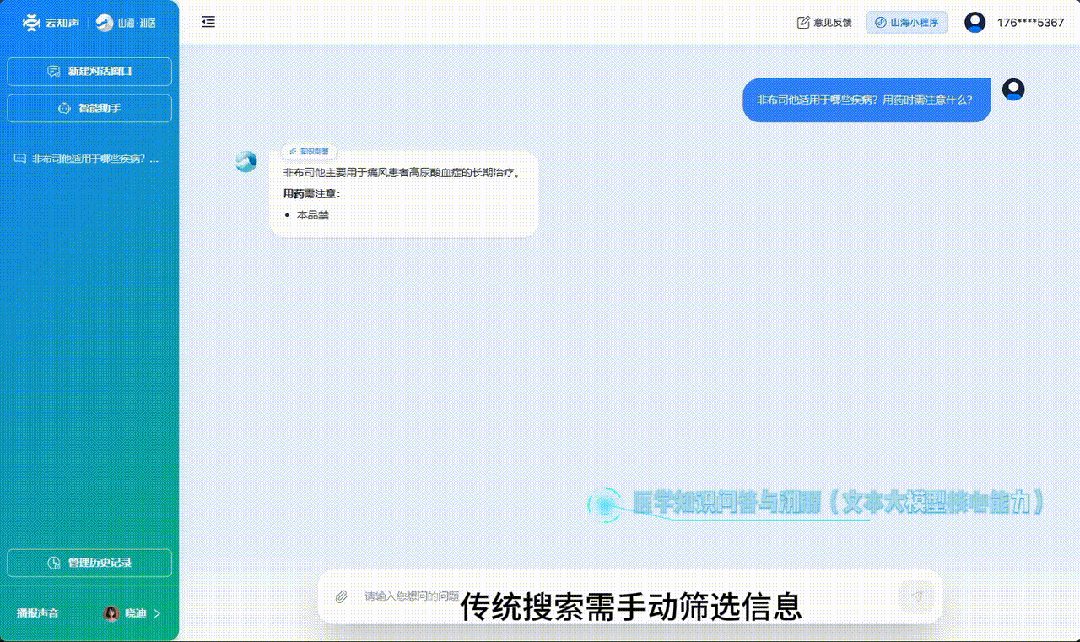
假设一位医生需要查询「非布司他」适应症和用药禁忌,山海文本大模型直接给出回复,还可以溯源更具可信度。
在真实诊断中,医生需要结合多维度信息,比如一位胸痛患者,需同时分析影像报告和病史。
此时,山海·知医在看懂影像同时,还能关联文本信息,实现「影像+临床」双验证。
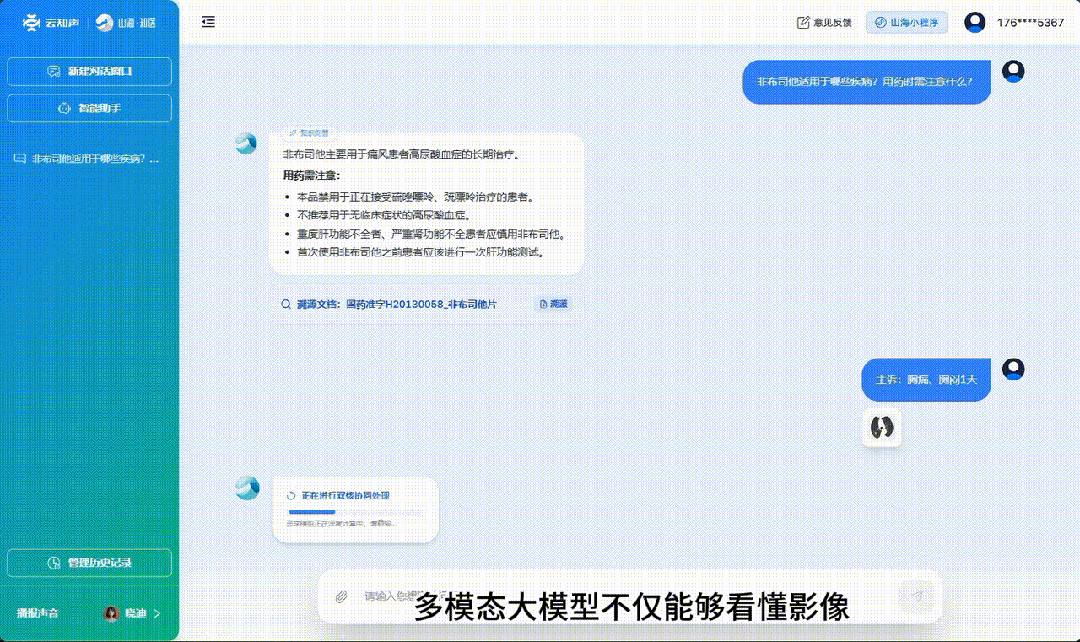
此外,它调动「双核模型」规划临床路径。

二、高阶推理进化与智能体进化
临床诊断的难点在于,它需要在不完整信息下,不断提出假设、验证假设、修正假设。
山海·知医大模型5.0此次升级的核心突破,在于模型「思维的进化」。
它深度融合了模拟临床诊断的复杂推理链,让自身具备了一种更接近医生思维的推理工作流。
同时,它还具备了原生的任务规划与工具调用能力,在理解需求后,拆解任务并决定每一步需要什么工具、数据。
下面demo中,拿到模拟的病例后,山海·知医没有简单罗列病因,而是对每种病因进行证据加权、鉴别排除,最终给出循证决策路径。

在生成全流程任务处理清单时,它还会自主调用工具、跨系统协调资源......

可以看到,AI正从被动应答的「医学认知大脑」,升级为能主动理解需求、拆解步骤并高效执行的「自主医疗行动者」,完美适配从门诊到住院的全流程复杂任务流。
三、多模态深度赋能临床
影像和文本,从来不是两条独立的信息链。
山海·知医大模型5.0升级后,兼具「看懂影像」和「读懂文本」的双重能力。
它不仅能精准识别X光、CT、MRI等影像中病灶,还能将影像特征映射到医学语义空间中。
也就是说,它可以实现影像特征与临床描述的跨模态语义对齐及联合推理。

这就好比为医生配备了「图文协同」智能助手,大幅提升诊断的精准性与效率。
四、医疗垂域专业能力领先
在医疗领域,模型能力的上限固然重要,但能否长期、规模化进入真实临床流程,取决于下限是否足够可靠。
这次升级,5.0版本围绕了「权威性、真实性、可验证性」这一核心命题展开,构成医疗垂域竞争力的底层支柱。
在医学知识上,它精准覆盖了疾病、症状、药物、治疗方案等全领域医学知识,可实现高效检索与专业回复。
同时,借助增量训练,Graph-RAG知识注入、任务级Agentic-RL训练等,大幅减少了幻觉事实性错误。
此外,在医学信息抽取能力上的强化,5.0版本能对复杂病历、病程记录、医嘱文本实现高精度实体识别与关系抽取。

总而言之,山海·知医大模型5.0在「四大核心」能力上实现了阶跃式进化,构建了目前业内最全面的医疗AI支持框架,完美匹配临床实际需求。
那么,它背后究竟采用了什么黑科技,让我们一一拆解。
核心技术揭秘
从底层数据体系到强化学习策略,山海·知医大模型5.0是一个从真实临床任务中「长出来」的医疗大模型体系。
从架构上来说,山海·知医大模型5.0「双核引擎」的背后——
医学文本大模型是核心底座,多模态能力再通过视觉编码器对齐后内嵌其中。
与上一代模型相比,5.0版本首个根本性的变化,发生在「数据体系」。
在训练过程中,它采用了「结构化图谱-半结构化文档-过程化轨迹」三层数据结构:
底层是「医学知识原生结构」,这部分数据核心是医学知识图谱,包含了疾病—症状—检查—用药之间的结构化关系,以及不同医学时间尺度下的演化逻辑。
中层是「权威医学文本」,比如包括临床指南、医学文献、教材与专业书籍等。
上层是「真实临床任务」数据,即医生与系统交互产生的数据,以及真实业务流程中沉淀的「工作流样本」,覆盖了从门诊、住院到出院的完整就医路径。
此外,5.0版本核心能力提升的另一关键,在于「任务型强化学习」算法的改进。
如上所述,医疗中正确答案往往不存在唯一形式,那么如何让AI判定对/错?
山海·知医的做法在于,将医生真实的操作行为作为「奖励信号」,比如对模型的输出、补充、否定/纠正。
这些行为被设计成「任务级奖励函数」,直接用于强化学习的训练。
顺便提一句,强化学习并非单点优化,而是直接嵌入到业务流程,与具体任务绑定,让模型学会在什么阶段,应该做什么事。
内化智能体
在当前主流方案中,Agent往往以外挂形式存在,但会带来稳定性差、调用不确定、工程复杂的问题。
山海·知医选用了另一条路:
把工具调用与规划能力,直接训进模型内部。
在训练阶段,模型就已经见过真实业务的工具使用流程,学会了在特定情境下调用特定工具。
本质上,这是把「流程记忆」内化到模型参数当中。
此外,在慢病管理、连续就诊场景中,模型并不会什么都记下来,而采用了「选择性记忆机制」。
团队会通过上下文工程与权重设计,对过期、低价值的信息进行降权,将与当前任务更相关的信息纳入长期记忆中。
凭借扎实的技术积累,云知声再获喜讯:国家人工智能应用中试基地(医疗)‧浙江测试了30多款AI模型,山海·知医大模型5.0脱颖而出,入选《MedAIBench测评榜(优秀国产医疗大模型)》。
值得一提的是,在未来规划中,山海·知医大模型还将:
逐步融合语音模态、扩展至医学科研领域(诸如文献分析、科研辅助),甚至去探索更底层的生物医学建模能力。
这释放出一个清晰的信号:
医疗大模型的核心竞争力,不只在于参数规模,而在于是否真正可以嵌入临床任务本身。
毋庸置疑,技术如果只停留在论文与榜单上,医疗行业不会买账。
临床信任来自「用起来省事、风险确实降低、可管可控」。
截至2025年6月,云知声智慧医疗解决方案已部署400家医院,700余家进入测试阶段。
特别地,已覆盖全国近40%百强三甲医院,如北京协和医院、北京友谊医院等。
根据弗若斯特沙利文的数据,按2024年收入计算,云知声在中国医疗服务及治疗AI市场中排名第四,并在电子病历这一关键细分市场中稳居行业前三。

比如,在北京友谊医院顺义院区应用中,报道提到云知声的门诊病历生成系统的单份病历采纳率接近90%。
既能在权威评测里拿到三冠王,又能在病历、质控、医保这些「硬骨头」场景里跑起来,这是一种更稀缺的能力:
专业不是写在宣传页上,而是磨在流程里。
从协和医院出发,云知声AI落地医疗
今年,AGI的共识已经形成。真正的分歧只剩一个:谁先落地?
成立于2012年,「港股AGI第一股」云知声从创立之初只专注一件事:把AI,塞进真实世界。
而他们在医疗领域的布局,远早于大模型的浪潮。
一年多后,在行业对「AI+医疗」普遍持怀疑态度时,云知声便做出了一个明确的决定:进医疗。
2016年,云知声的语音识别系统,在北京协和医院落地,主打「效率工具」。
医生开口说话,系统实时转写。一份病历,从原来的3个小时,缩短到1小时以内。
AI,第一次把时间还给了医生。但云知声并不满足于此。
他们不想只做「更快」的工具,便开始尝试更难的事。于是,他们基于「知识图谱+BERT语言模型」的能力去做病历质控。

BERT语言模型由谷歌在2018年发明,是当时最先进的语言模型
病历看起来只是几页文字,但在医疗体系里,它是一切判断的起点。
用药对不对,流程合不合规,风险能不能追责, 全靠病历。

过去,仅靠人工抽检,覆盖率只有约2%-5%。而云知声的做法是:100%全量用AI检查,可以实现全病历覆盖,大幅提高病历质控的效率。
如今,大模型出现后,云知声把AI直接嵌进了医生的工作流。
现在,医生一次问诊结束后,AI可以自动生成病历。医生只需看一眼,点个确认,直接引用率约90%。
换句话说:10份病历里,9份不用改一个字。
更关键的是,这90%不是出现在普通医院,其中不乏协和医院这样的百强三甲。
如果基层医院也用上同样的工具,AI真正的普惠,才刚刚开始。
而这些,还只是云知声智慧医疗的冰山一角。
医院,是国内AI落地医疗的主战场,但医疗机构不只是三甲医院。
在临床知识图谱、大语言模型、智能语音识别等基础技术支撑下,云知声正在探索一条更适合中国国情的、可规模化的AI医疗服务落地路径。
在国家层面,「AI+医疗」的落地节奏,已经被明确写进时间表。
2027年:基层诊疗智能辅助广泛应用
2030年:智能辅助基本实现全覆盖

AI医疗,已不再是探索题,而是时间表里的必答题。
云知声已做好两手准备:一方面继续保持技术和产品的快速迭代,另一方面积极进取、持续探索新的商业模式。
据黄伟博士介绍,云知声已经走通从医院到保险公司的商业模式。无论是医保,还是商业保险方面,云知声的增长非常快速。
从医院,到区域平台,再到医保和商业保险。
云知声,正在把AI医疗从「项目交付」,变成「系统供给」。
而他们更大的愿景是,持续提升AI大模型的医学能力,为人类健康做出更多贡献。
文章来自于微信公众号 “新智元”,作者 “新智元”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MONAI是一个专注于医疗影像分析的深度学习框架,它可以让医院高效、准确地从医疗影像数据中提取有价值的信息,以辅助医生进行诊断和治疗。
项目地址:https://github.com/Project-MONAI/MONAI?tab=readme-ov-file
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
