# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
太香了太香了,妥妥完爆ChatGPT和Nano Banana!
刚刚,ViT核心作者、Meta超级智能团队成员Lucas Beyer连发三条帖子,怒赞通义千问不久前发布的开源模型Qwen—Image—Layered。
在他看来,这才是图像生成的正确打开方式~
他还顺便自补了一句:这个模型方向自己其实也想做来着,只是太忙,一直没来得及动手……(笑)
实话实说,Qwen—Image—Layered模型确实不一般,因为它可以让我们真正实现ps级别的拆图自由。
也就是说现在图片元素也支持精细化修改了:

连网友们看了模型效果后都不禁感叹:咋有种开源PhotoShop的感觉,amazing啊~

所以,这套让Lucas Beyer反复点赞的模型到底强在哪儿,咱一起来看!
如果说Nano Banana技能点在生图,那Qwen—Image—Layered模型则厉害在:《拆图》。
相信大家都有过类似的经历,我们平时用大模型生图时总会碰的到一个抓狂问题,那就是图片生成so easy,细节修改so抓狂!!!
AI生出来的图片里,经常会有一些小细节不太到位,但我们又没法只改局部,只能整张丢回模型重新生成,结果往往还不如上一版…

Qwen—Image—Layered模型的核心能力,就是专治「一图定生死」这事儿的。
它能将一张普通图片分解成多个包含透明度信息的RGBA分离图层,实现真正意义上的图片素材的可编辑性。
光说概念有点抽象,咱直接看例子~
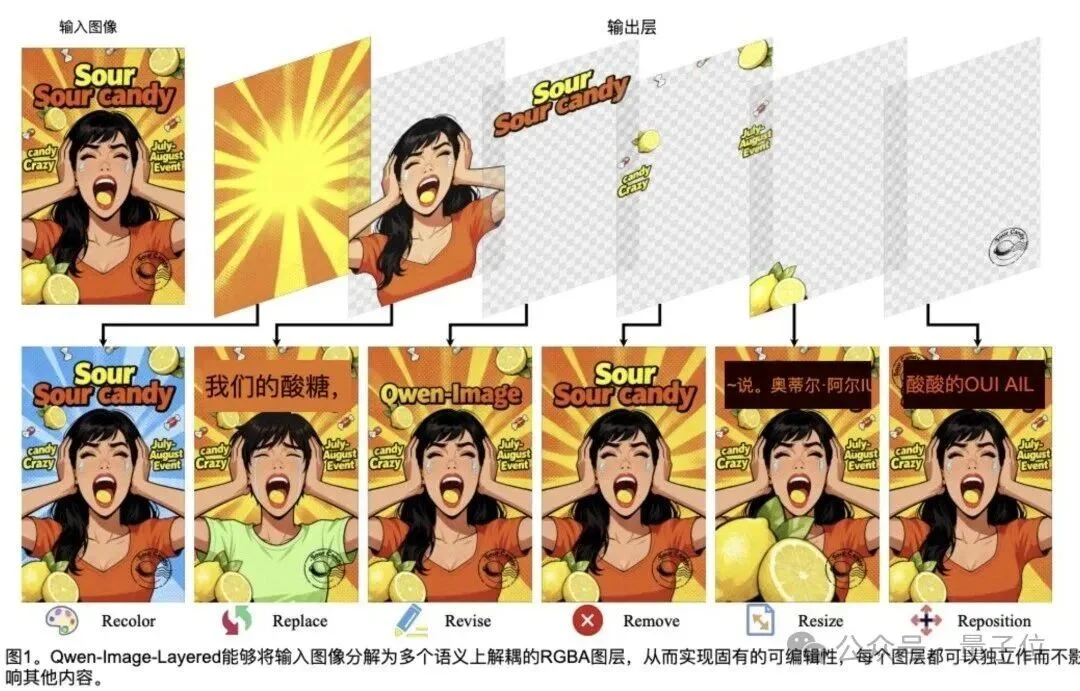
在官方案例中,一张完整图片输入之后,模型会自动把画面拆成6个包含不同元素的图层,背景是背景,人物是人物,装饰是装饰,互不干扰。
看到这儿大家是不是突然感觉,这个非常适合用在海报制作等细节较多的图片上??(雀实
但是Qwen—Image—Layered模型能做的还不止只是分离图层这么简单,我们还可以对图层进行二次编辑修改。
比如最基础的:改背景,不动主体。
只替换背景图层的颜色,一张橙色背景的海报,瞬间就能换成蓝色版本:

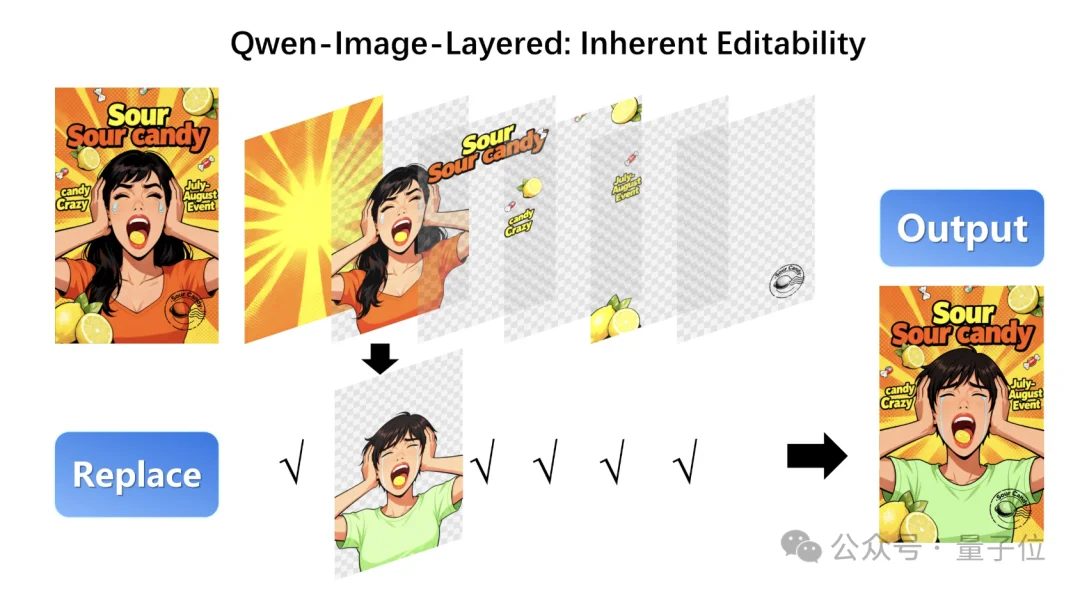
再比如,直接换主体。
保持构图不变,把原图里的长发女孩,换成短发女孩,几乎看不出拼接修改痕迹:
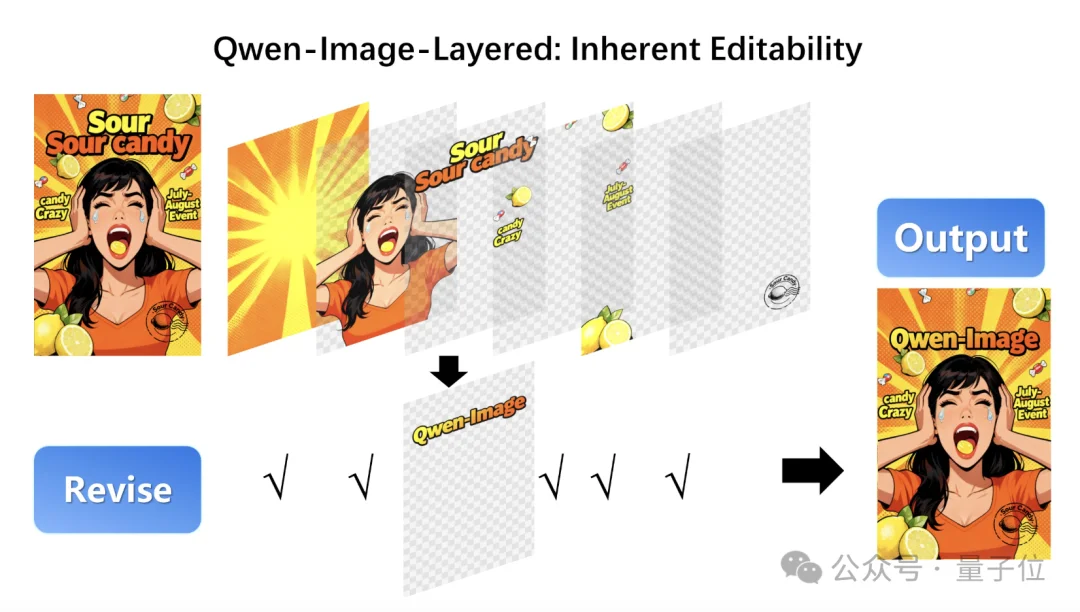
再来看下面这个——文字编辑。
我们可以只修改图片中的局部文字,哪怕第一次生成的文字有幻觉问题也不怕了:
除了基本的替换编辑功能外,Qwen—Image—Layered模型还支持调整元素的大小、删除不想要的元素等等。
例如像这样,我们可以删除掉画面中不想要的元素对象,只保留自己想留的画面元素:
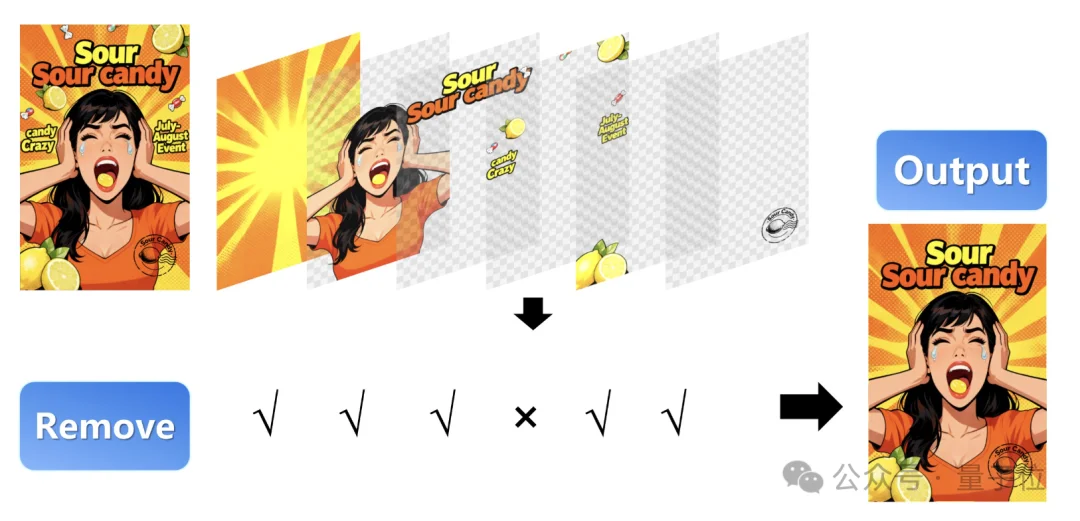
又或者在不拉伸、不失真的前提下,轻松调整元素的大小比例,其实有点像PS里的自由缩放功能:
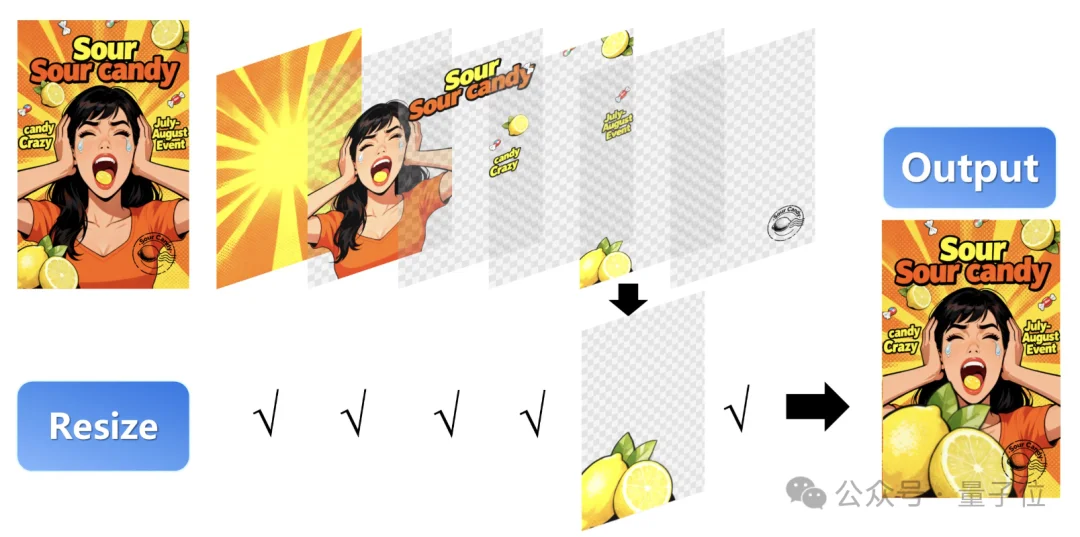
值得注意的是,Qwen—Image—Layered模型分层不限于固定的图层数量,支持可变层分解,例如我们可以根据需要将图像分解为3层或8层:
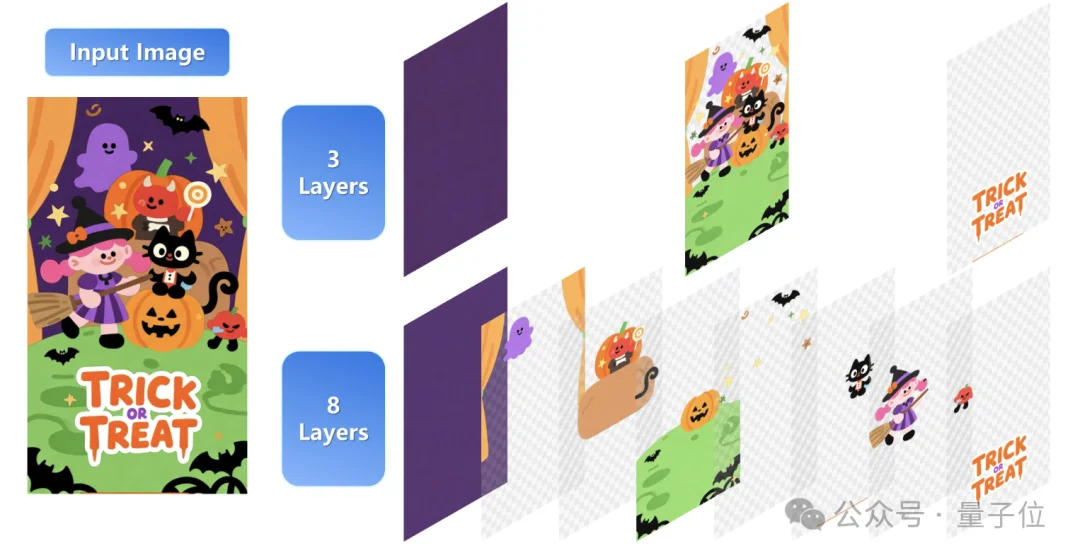
这个能力非常适合我们在不同的编辑需求场景下使用,可以根据我们想局部编辑的元素数量多或少而定。
当然,如果只是想改文字,差不多两三层就够了,如果修改需求比较多比较复杂,多拆几层反而更好操作~
除了刚才说的这些,模型还支持在已分解的图层基础上做进一步分解,进而实现无限分解,听上去很像无限套娃…
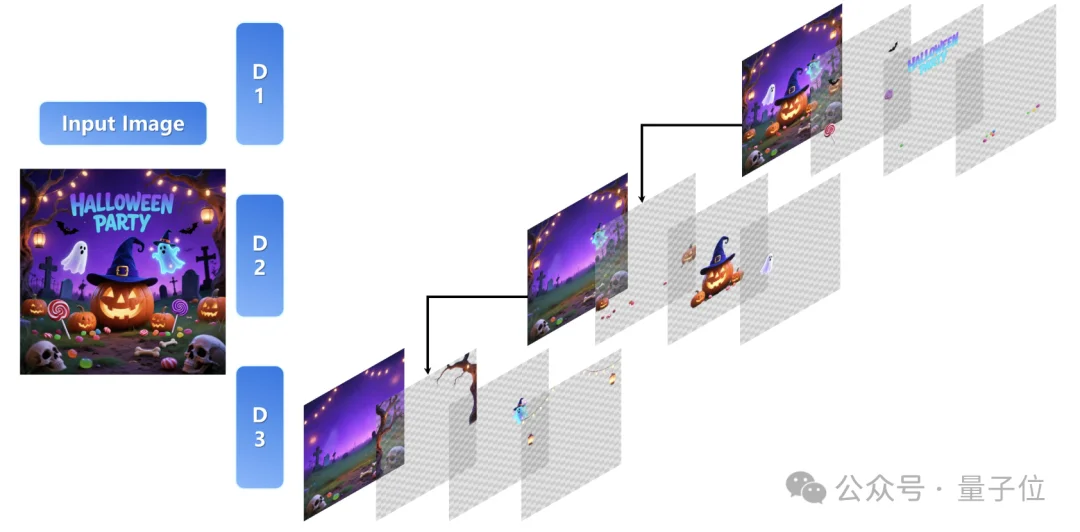
像下面这位网友,用Qwen—Image—Layered把人物元素进行一次性分层处理,最后甚至可以一路拆到只剩下一个线稿层:

再来看这位网友,原本人物和背景完全糊在一起的一张图,被模型直接拆成了主体和背景两个独立元素:
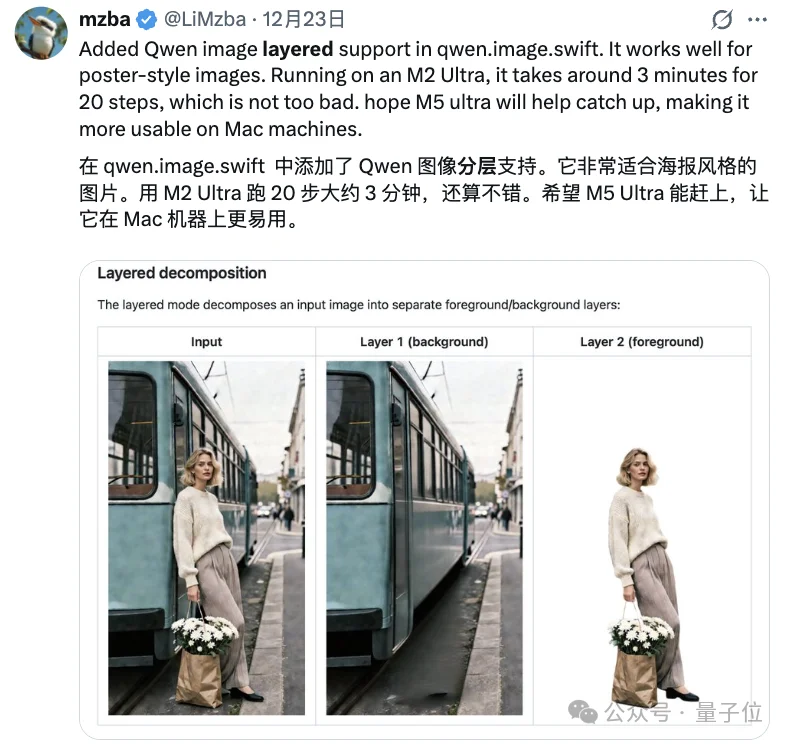
简单说就是:只要画面里不止一个元素,它就能拆、还能一直拆……
有朋友看到这儿该问了,小小模型背后能有这PS一般的能力,用的是啥神奇魔法?
不藏着掖着,Qwen—Image—Layered的核心技术,本质上是一套端到端的「扩散模型」。
它并不是用来生成图片的那种扩散模型,而是专门为「拆图片」这件事设计的——
模型直接输入一张完整的RGB照片,通过扩散过程,一步步预测出多个带透明度信息的RGBA图层。
这里有一个绕不开的前提是:
我们平时看到的图片其实只有RGB三个通道,但真正的图层编辑,离不开Alpha(透明度)通道。
为此,Qwen—Image—Layered专门设计了一套四通道的RGBA-VAE,把RGB输入和RGBA输出,统一压缩到同一个隐藏空间中:
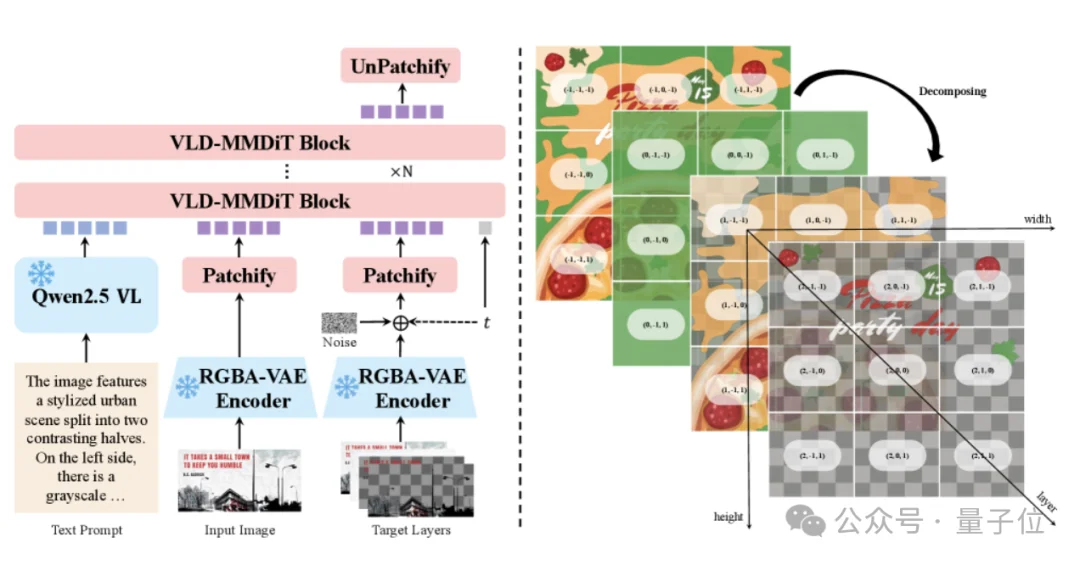
具体来说,当输入是一张普通RGB图片时,模型会自动把Alpha通道补成1(完全不透明),在初始化阶段还会聪明地复用预训练参数,避免在透明度建模时出错。
这样一来,模型从一开始就「懂透明」,不同图层也就不会被混在一起。
而且在结构上模型也不是死板拆层,它的核心Transformer—VLD-MMDiT会根据图片复杂度,自动决定需要拆成多少层。
为了避免前一层把后一层盖住的问题,模型还加了一套Layer3D RoPE(三维位置编码),简单说就是给不同图层打上明确的层级标签,让模型在空间和顺序上都分得清楚~

还不止如此,在隐藏空间里中,模型能够被逐步「引导」去学会:哪些像素该属于哪一层、哪些区域需要保留透明度、哪些内容应该被分离开来。
这样一来哪怕图层再多对模型来说也都是小case了~
并且在训练策略上模型也不是从零教的,而是基于Qwen-Image预训练生成模型逐步升级:
第一阶段让模型学会文本生成单RGBA图层,第二阶段让模型学会扩展到多图层合成,第三阶段让模型真正学会从图片反向拆解多图层。
每阶段几百K步训练,加上重建损失和感知损失,确保语义分离干净、不冗余。

这样一来好处很直接,以前方法(如LayerD)要递归抠前景再补背景,容易积累错误,或者用分割+修复,遮挡区补不好。
Qwen—Image—Layered模型直接实现端到端生成完整RGBA层,避免这些问题,尤其擅长复杂遮挡、半透明和文字。
相较于Nano Banana的“一次抽图定生死”,Qwen—Image—Layered的拆图能力能让Lucas Beyer这么喜欢,也就不奇怪了…
目前模型已经开源,感兴趣的朋友可以试试~
github开源地址:https://github.com/QwenLM/Qwen-Image-Layered
文章来自于“量子位”,作者 “梦瑶”。



