# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
作为大模型从业者或研究员的你,是否也曾为一个模型的 “长文本能力” 而兴奋,却在实际应用中发现它并没有想象中那么智能?
你大概率也遇到过以下困境之一:
虚假的繁荣: 模型在 “大海捞针” (Needle-in-a-Haystack) 测试中轻松取得高分,营造了一种长文本能力已经解决的 “虚假繁荣”。但一旦任务从简单的信息定位,升级为需要串联分散证据、整合全局信息的多跳推理 (multi-hop reasoning) 时,模型的表现便会急转直下,难以构建起完整的逻辑链条,暴露出其在深度理解上的真实短板。
训练的噩梦: 长文本、多任务的训练数据就像一个成分复杂的 “大杂烩”,其多源、多域的特性,让标准的 RL 算法严重 “水土不服”。你精心设计的奖励函数(Reward Function)很可能因为数据分布的剧烈变化而产生偏差,导致模型性能不升反降。最终,监控图上那剧烈震荡的奖励和熵(Entropy)曲线,无情地宣告着训练过程的 “翻车” 与崩溃。
窗口的天花板: 即使上下文窗口被扩展到 256K,1M 甚至更长,它也终究是一个有限的 “物理内存”。然而,现实世界的知识流 —— 分析整个代码仓库、研读一份完整的年度财报、或是精读一部专业巨著 —— 其信息量轻易就能突破这个上限。这使得模型在处理这些 “超框”(Out-of-Window)任务时,不得不依赖分块处理等妥协方案,最终导致关键全局信息的丢失和端到端推理能力的降级。
如果这些场景让你倍感熟悉,那么问题很可能不在于你不够努力,而在于业界缺少一套完整、端到端的长文本推理后训练 “配方”(Post-training Recipe)。
针对这一系列挑战,通义文档智能团队正式推出 QwenLong-L1.5—— 一个基于 Qwen3-30B-A3B 打造的长文本推理专家。我们的核心贡献,正是提供了这套缺失的 “配方”,它系统性地统一了:
这套组合拳,旨在一次性解决从 “学不好” 到 “用不了” 的全链路难题。

要让模型真正掌握长文本推理,零敲碎打的优化是远远不够的。我们提出了一套系统性的 “组合拳”,包含三大核心法宝,从根本上重塑模型的学习与思考方式。
模型的 “食粮” 决定了它的 “智商”。如果只给模型投喂简单的 “大海捞针” 式任务,就如同只让学生做单选题,却期望他能写出长篇论述文。
为了教会模型真正的 “思考”,我们打造了一条新颖的数据合成流水线。其核心思想是 “先拆解,后组合”,专造需要 “多跳溯源 (multi-hop grounding) 和全局推理” 的难题。这就像用乐高积木拼城堡:我们先把一本巨著拆解成一个个知识 “积木”(原子事实),再根据复杂的 “图纸”(如知识图谱、多文档表格),把这些分布在不同章节的积木拼成一个宏伟的 “城堡”(复杂问题)。
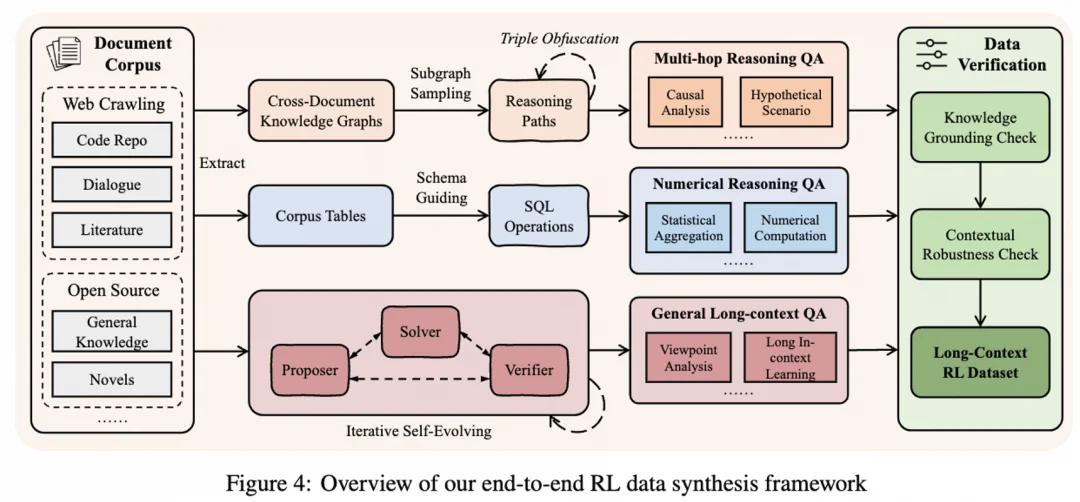
这条流水线由三大 “出题引擎” 驱动,能程序化地生成无穷无尽的高质量挑战:
强化学习(RL)是提升模型推理能力的关键,但在长文本、多任务场景下,标准的 RL 方法会面临两大严峻挑战,极易导致训练崩溃。
第一个挑战源于数据分布的异构性。我们的长文本训练数据来自代码、学术文献、财报等多个领域,任务类型也涵盖了问答、计算、分析等。这种复杂性导致在训练的每个批次(mini-batch)内,数据分布都会发生剧烈偏移(distributional drift)。
这种偏移会严重干扰奖励信号(reward)的稳定性,并对优势函数(advantage function)的估计引入巨大噪声,使得梯度更新方向变得极不可靠。为解决此问题,我们采取了双重策略:
任务均衡采样(Task-balanced Sampling): 在构建每个训练批次时,强制从不同的任务类型(如多跳推理、数值计算、对话记忆等)中均匀抽取样本,从源头上保证了批次内数据分布的相对均衡。
任务专属优势估计(Task-specific Advantage Estimation): 在计算优势函数时,我们不再对整个批次的奖励进行标准化,而是在每个任务类型内部独立进行。这能有效隔离不同任务间迥异的奖励分布(如 0/1 的稀疏奖励与 0-1 的密集奖励),从而为每个任务提供更准确、更稳定的优势信号。
第二个挑战是长文本推理中的信用分配难题(Credit Assignment Problem)。在生成式任务中,一个最终错误的答案(negative response)往往包含了大量完全正确的中间推理步骤。传统的 RL 算法通过一个单一的负向奖励来惩罚整个序列,这种 “一刀切” 的做法会错误地惩罚那些正确的、具有探索价值的步骤,不仅压制了模型的探索能力,甚至可能导致 “熵坍塌”(entropy collapse)和训练早停。
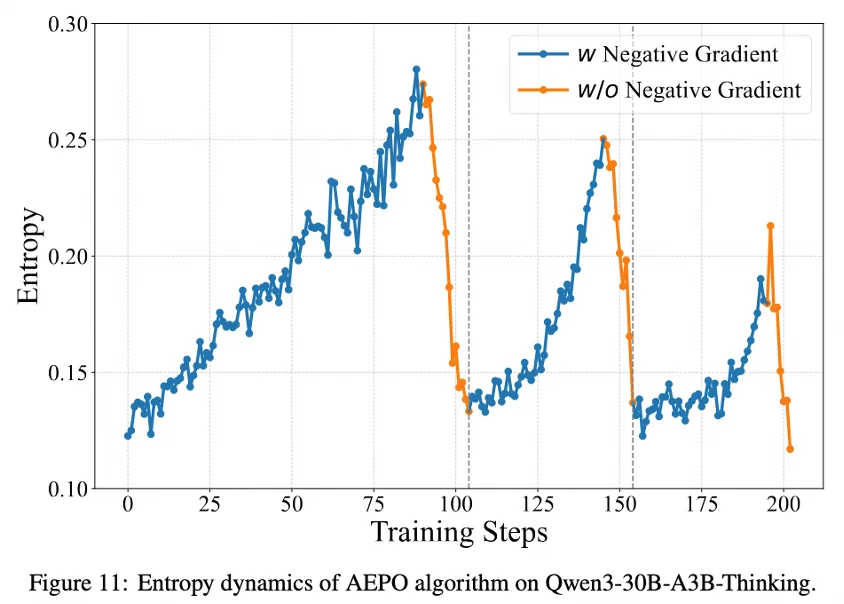
为此,我们提出了自适应熵控制策略优化(Adaptive Entropy-Controlled Policy Optimization, AEPO)算法。AEPO 的核心是一种基于模型自身不确定性(以策略熵衡量)的动态梯度屏蔽机制:
当模型在高不确定性(高熵)状态下生成了错误答案时,AEPO 会主动屏蔽(mask)其负向梯度。这保护了模型的探索性行为,避免因惩罚不成熟的尝试而丧失学习潜力。
反之,当模型在高置信度(低熵)状态下依然犯错时,负向梯度会被正常施加,以坚决纠正这些高置信度的错误。
通过这种动态的、智能的梯度控制,AEPO 将模型策略的熵稳定在一个健康的区间,完美平衡了探索与利用,从根本上解决了长文本 RL 中的不稳定性问题。
256K 的上下文窗口,本质上是一种有限的 “短期记忆”。当面对浩如烟海的真实世界知识流时,我们需要的不是一个更大的窗口,而是一个全新的工作模式。
为此,我们为模型设计了一套记忆管理框架 (Memory Management Framework),这相当于给了它一个可无限扩展的 “智能笔记本”。在阅读超长文档时,模型不再试图将所有内容硬塞进 “短期记忆”,而是学会了边读边记要点(迭代式记忆更新),形成结构化的记忆,并在需要时高效检索和利用这些 “笔记”。
但这并非一个孤立的工具。通过巧妙的多阶段融合 RL 训练 (multi-stage fusion RL training),我们将这种 “笔记能力” 与模型与生俱来的 “过目不忘”(窗口内推理)能力无缝地融合在了一起。最终得到的,是一个统一的模型 —— 一个既能 “深思” 又能 “博览” 的全能选手,真正突破了物理窗口的束缚。
性能全面飞跃,30B moe 模型实现媲美顶级旗舰的效果!
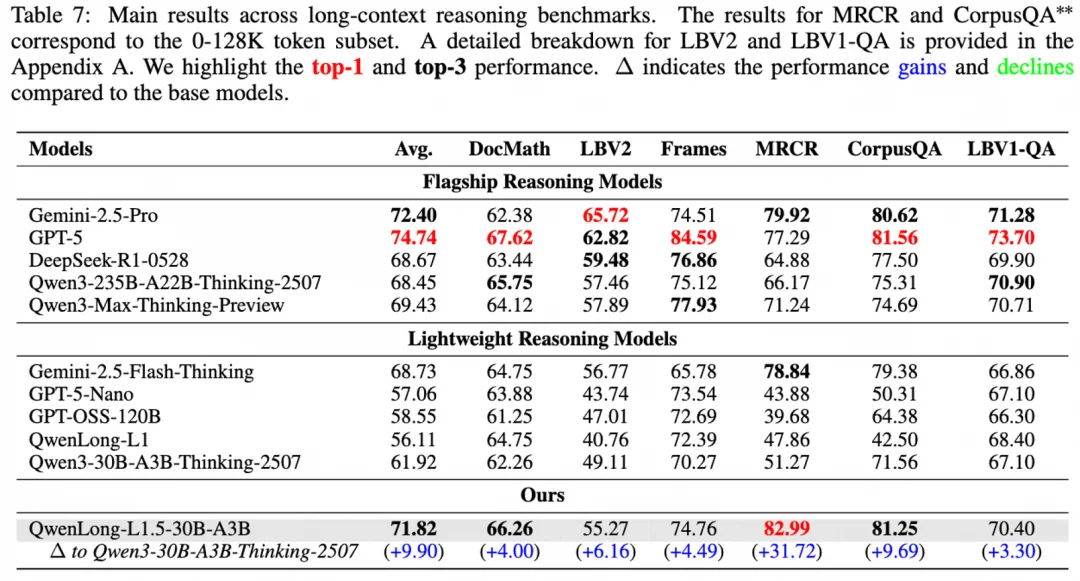
QwenLong-L1.5 在多个权威长文本推理基准上取得了令人瞩目的成绩,其表现可以总结为:
这并非巧合,而是精准地验证了我们 “高质量精神食粮”(可编程数据合成)的有效性 —— 我们专门为模型打造了什么样的难题,它就在解决这些难题上获得了最强的能力!
训练 “专才” 是否会牺牲 “通才” 能力?这是大模型微调中常见的 “跷跷板” 难题。
我们的答案是:不仅不会,反而会相互促进!
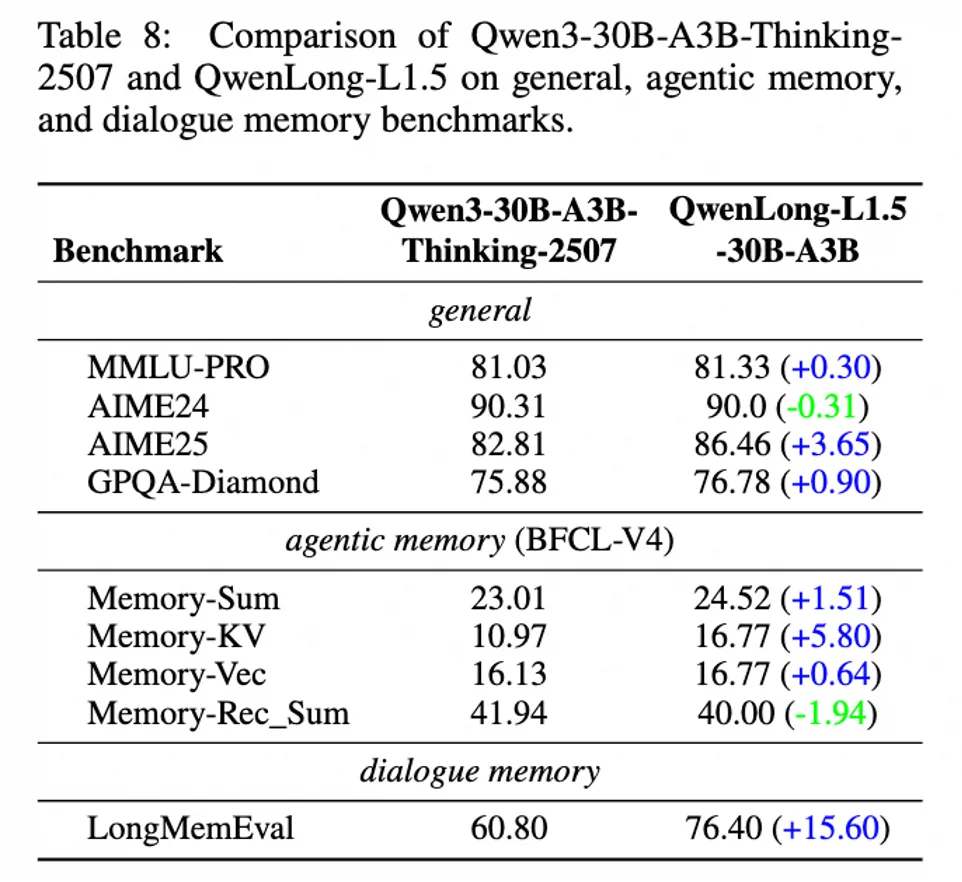
实验结果显示,经过长文本强化训练后,QwenLong-L1.5 不仅没有出现 “偏科” 或 “遗忘”,反而在一系列通用能力上也获得了显著提升:
这有力地证明了,提升长程信息整合能力,是一种基础性的 “认知升级”,其收益会辐射到模型的各项核心能力之中。
当任务长度远超物理上下文窗口时,模型真正的扩展能力才得以体现。
借助我们的 “外置大脑”(记忆管理框架),QwenLong-L1.5 在处理百万、甚至四百万级别的超长任务时,展现出了卓越的性能。

结果显示,QwenLong-L1.5 在这些极限挑战中,性能远超同类智能体方法,充分验证了我们框架强大的可扩展性。这表明,我们不仅提升了模型在窗口内的能力,更赋予了它突破物理窗口限制、处理无限信息流的巨大潜力。
总结:我们提出的 QwenLong-L1.5 及其背后的 “数据合成 + RL 优化 + 记忆管理” 三位一体的后训练框架,为解决大模型长文本推理难题提供了一条经过验证的、可复现的路径。
开源呼吁:我们相信开放与共享的力量。相关技术细节已在论文中公布,代码也在 https://github.com/Tongyi-Zhiwen/Qwen-Doc 开源。欢迎大家下载使用、交流探讨,共同推动长文本技术的发展!
文章来自于“机器之心”,作者 “机器之心”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
