# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在空间智能(Spatial Intelligence)飞速发展的今天,全景视角因其 360° 的环绕覆盖能力,成为了机器人导航、自动驾驶及虚拟现实的核心基石。然而,全景深度估计长期面临 “数据荒” 与 “模型泛化差” 的瓶颈。
近日,来自 Insta360 研究团队、加州大学圣地亚哥分校 (UCSD)、武汉大学以及加州大学默塞德分校的研究者共同推出了 Depth Any Panoramas (DAP)。这是首个在大规模多样化数据集上训练的全景度量深度(Metric Depth)基础模型,不仅统一了室内外场景,更通过 200 万量级的数据引擎与创新的几何一致性设计,刷新了多项 benchmark 纪录,在多种 open-world 场景下保持优异的效果。

模型对由 Gemini 或 DiT-360 等合成的全景图同样展现出了极佳的预测效果,生成的深度图边缘锐利、逻辑自洽,是空间 AIGC 链路中理想的几何基石。 除了静态图像,DAP 在处理全景视频流时同样展现出了极佳的预测效果,具备优秀的帧间一致性与稳定性 。


在深度学习时代,数据的规模决定了模型的上限。然而,获取带高精度深度标注的全景数据成本极高,导致学术界长期依赖于几万张规模的小型数据集,如 Stanford2D3D 或 Matterport3D。
为了打破这一僵局,DAP 团队构建了一个规模空前的全景数据引擎,将数据量直接推向了 200 万(2M)级别,除了现有的 Structured3D:
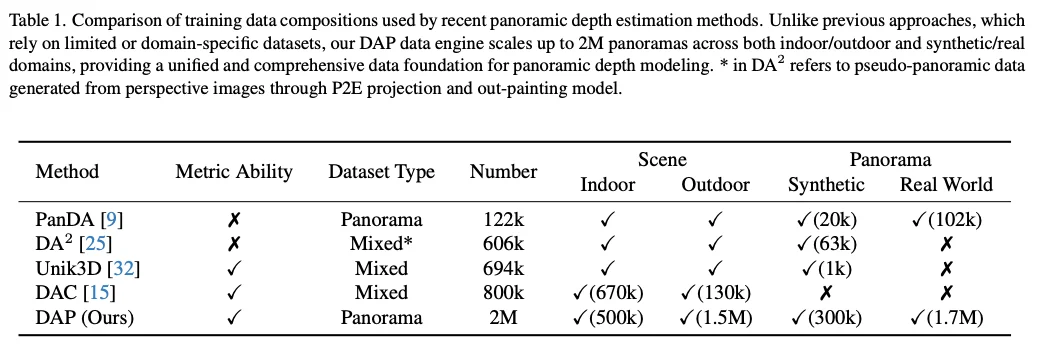
面对 1.9M 没有任何标签的原始全景图,如何挖掘它们的价值?
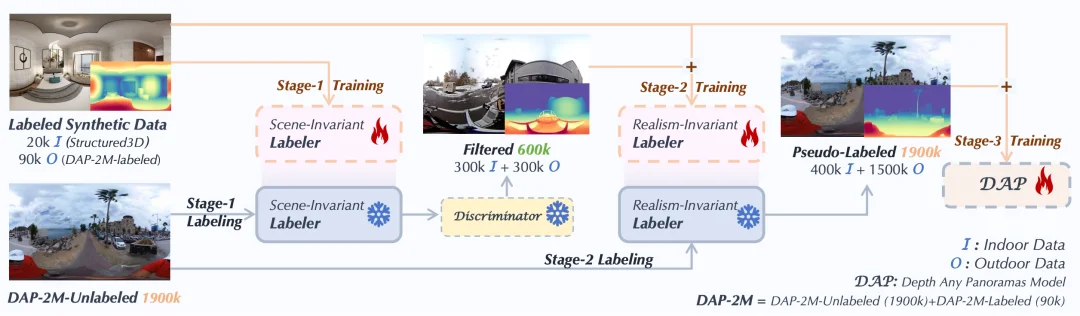
DAP 巧妙地设计了一个三阶段伪标签精炼管线,像漏斗一样层层筛选,最终淬炼出高质量的监督信号:
1. Stage 1:场景不变标注器。先用小规模但精准的合成数据(Structured3D + DAP-2M-Labeled)练出一个基本功扎实的标注器,确立物理意义上的深度基准。
2. Stage 2:写实性不变标注器。引入专门的深度质量判别器(Discriminator),从 1.9M 预测结果中筛选出最靠谱的 600K 样本(300K 室内 + 300K 户外),再次训练标注器,消除合成数据与真实场景之间的纹理鸿沟。
3. Stage 3:全量 DAP 训练。在汇集了精炼伪标签和原始强监督标签的 2M 数据集上,正式炼成 DAP 基础模型。
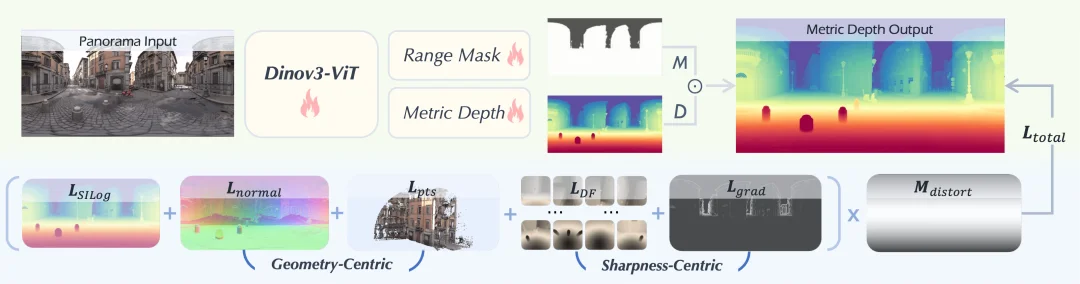
除了海量数据,DAP 在模型架构上也进行了设计:
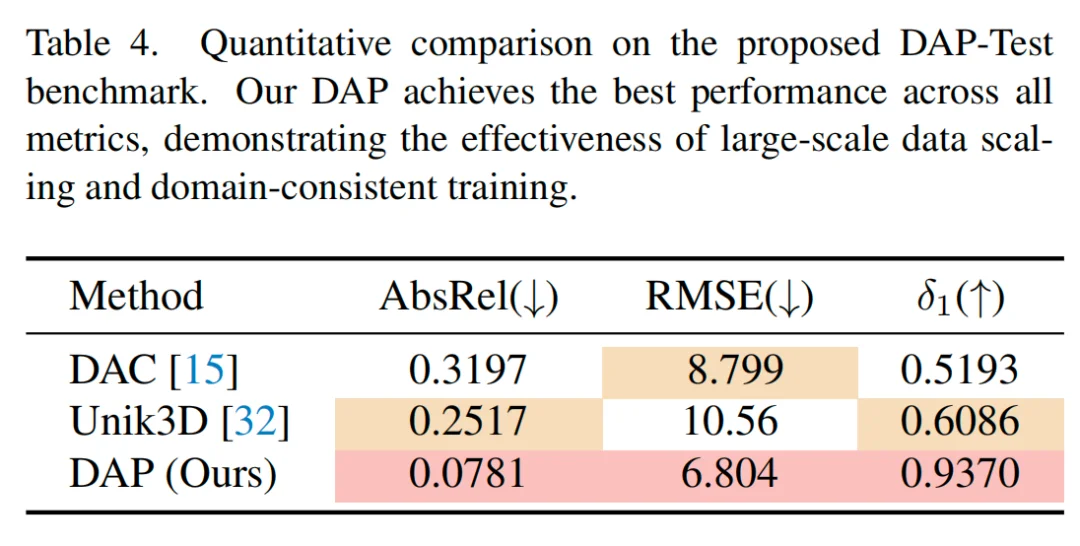
在多项严苛的零样本(Zero-shot)测试中,DAP 展现了优异的效果:
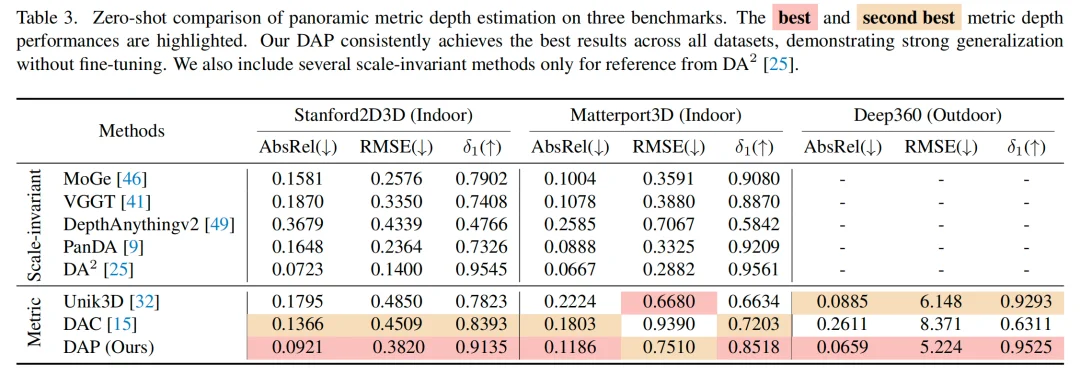
图示对比:图中的实测对比中可以看到,对比 baseline 出现的远景模糊和天空深度误判,DAP 无论是复杂的家具纹理还是远处的山脉轮廓,都清晰可见。

DAP 的出现,标志着全景深度估计正式进入了 open-world 时代。
它不仅能为自动驾驶、机器人避障提供更广阔的 “全知视角”,也为 3D 场景重建、VR/AR 内容创作提供了极低成本的深度获取手段。正如论文总结所言,DAP 通过大规模数据扩展和统一的三阶段管线,成功构建了一个能跨越室内外、统一米制深度的全景视觉基座。
目前,DAP 的项目页面已经正式上线,相关的代码与模型也已开源。
“数据是在全景领域实现 AGI 感知的关键。” DAP 不仅为机器人全向避障提供了更精准的 “眼睛”,也为 VR/AR 场景的大规模 3D 重建和场景生成奠定了坚实的技术底座。如果你对全景视觉、空间计算或深度估计感兴趣,DAP 绝对是不容错过的年度之作!

文章来自于“机器之心”,作者 “机器之心”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
