# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
视频 - 音频联合生成的研究近期在开源与闭源社区都备受关注,其中,如何生成音视频对齐的内容是研究的重点。
近日,来自香港大学和字节跳动的研究团队提出了一种简单有效的框架 ——JoVA,它支持视频和音频的 Token 在一个 Transformer 的注意力模块中直接进行跨模态交互。为了解决人物说话时的 “口型 - 语音同步” 问题,JoVA 引入了一个基于面部关键点检测的嘴部区域特定损失 (Mouth-area specific loss)。
实验表明,JoVA 只采用了约 190 万条训练数据,便在口型同步准确率、语音质量和整体生成保真度上,达到了先进水平。


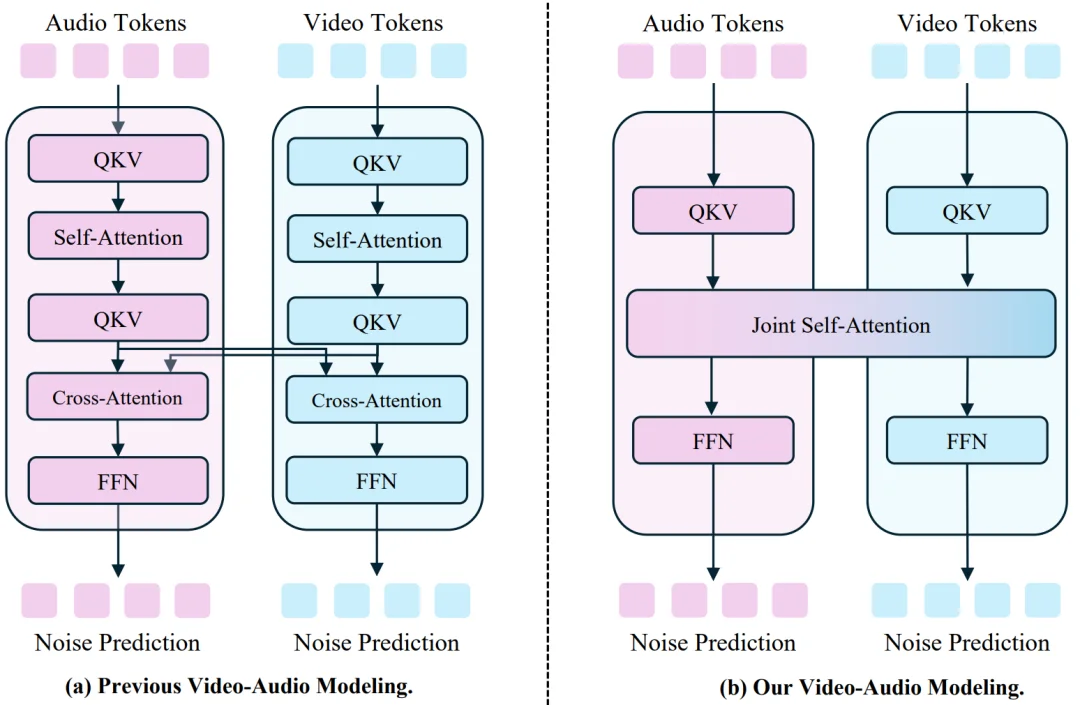
目前的开源解决方案通常分为两大类别:一类是 “级联式”,即先生成视频再配音,或者先生成语音再驱动视频生成,这种方式在一定程度上会导致音频和画面的割裂;另一类是 “端到端的联合生成”,试图同时输出视频和音频。
如下图 a, 现有的端到端方法(如 OVi 和 Universe 等),为了实现双模态对齐,需要在自注意力层 (self-attention) 之外,额外设计融合模块或跨注意力层 (Cross-attention)。这不仅破坏了 Transformer 架构的简洁性,还可能阻碍进一步的数据和模态扩展。
相比之下,JoVA 采用了更加简洁的设计(如图 b),直接使用联合自注意力层 (joint self-attention) 进行两种模态特征的融合与对齐。它同时承担了单模态内的建模以及跨模态的融合任务,无需引入任何新的模块。
JoVA 采用 Waver 作为基础模型。为了实现音频生成,JoVA 首先通过复制预训练视频主干网络 (Backbone) 的参数来初始化音频扩散模型。在特征提取方面,采用了 MMAudio VAE 将原始音频转换为声谱图潜在表示 (Latent Representation)。
音频分支的训练沿用了与视频分支相同的流匹配 (Flow Matching) 目标函数。在预训练阶段,视频和音频模态是独立训练的;而在后续阶段,两者被统一整合进同一个架构中进行并行处理。此外,对于视频生成,模型支持参考图像 (Reference Image) 作为条件输入。该图像经由视频 VAE 编码后,在通道维度上与噪声视频潜特征进行拼接。
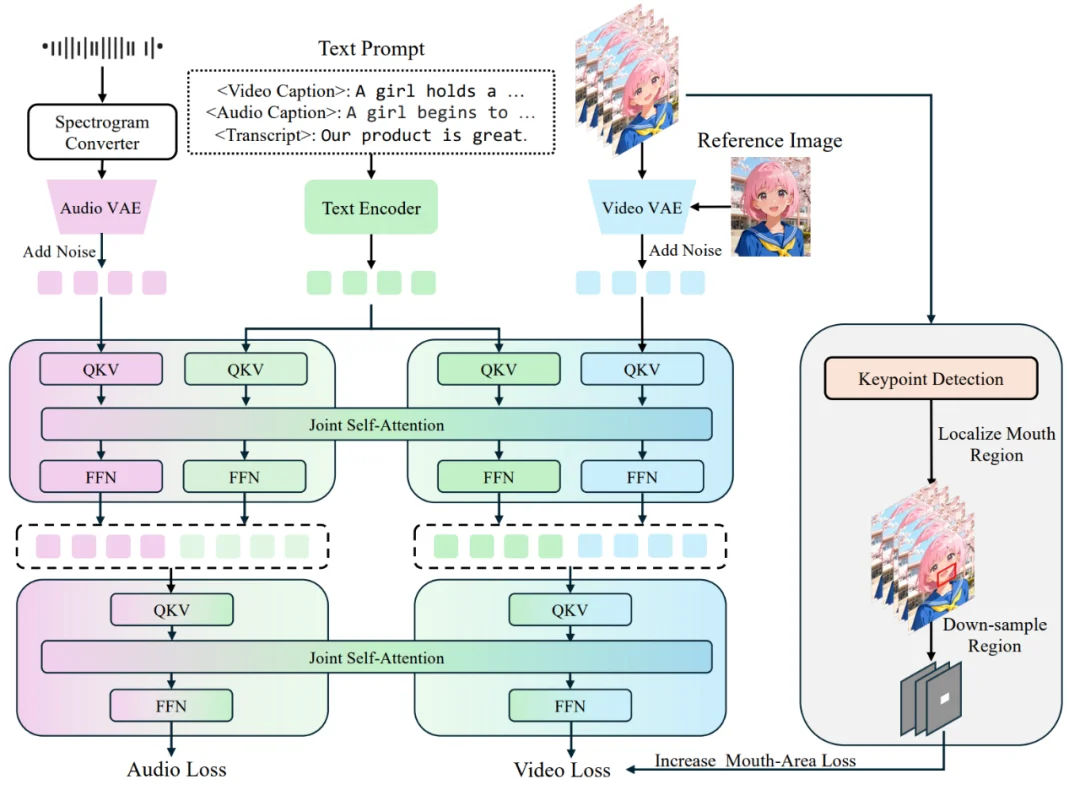
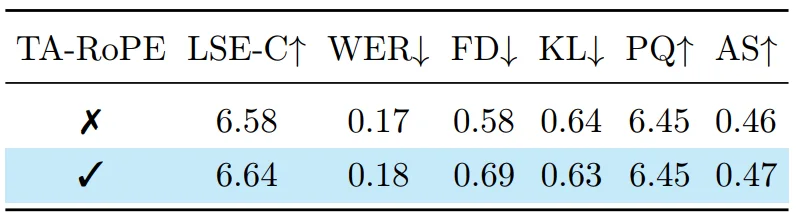
为了实现模态间的融合,JoVA 在 Transformer 块内部采用联合自注意力机制(Joint Self-Attention)。具体而言,视频 Token、音频 Token 以及对应的文本 Token 被拼接在一起,输入到共享的自注意力层中进行处理。这种设计允许不同模态的 Token 在每一层都进行直接的信息交换,既保留了各自的预训练知识,又实现了特征融合。为了确保视频与音频在时间维度上的精确同步,模型采用了源自 MMAudio 的时间对齐旋转位置编码(Temporal-aligned RoPE),在时间维度上同步了两种模态的位置编码。
为了解决人像生成中的唇形同步问题,JoVA 引入了一种针对嘴部区域的增强监督策略。该过程包含三个步骤:
1. 区域定位:首先在原始视频帧上进行面部关键点检测,计算出覆盖嘴部区域的像素级边界框。
2. 潜空间映射:将像素空间的边界框映射到 VAE 的潜空间。这包括空间上的缩放(除以空间下采样因子 s)和时间上的滑动窗口聚合(根据时间下采样因子 t 合并窗口内的边界框),以精确定位潜特征中的嘴部区域。
3. 加权损失:在训练目标函数中引入了专门的嘴部损失项。该损失仅对视频潜特征中的嘴部掩码区域计算流匹配损失,并通过权重系数进行调节。最终的总损失函数由视频损失、音频损失和嘴部区域损失共同构成,从而在不增加推理阶段架构复杂度的前提下,强制模型学习细粒度的唇形 - 语音对齐。
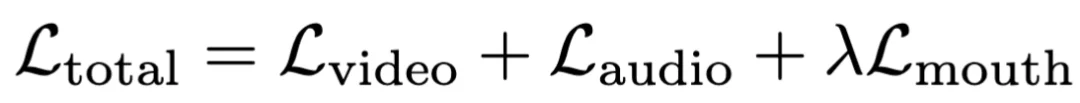
如下图,我们可以发现,这种映射方式可以很好地在潜空间定位到嘴部区域:

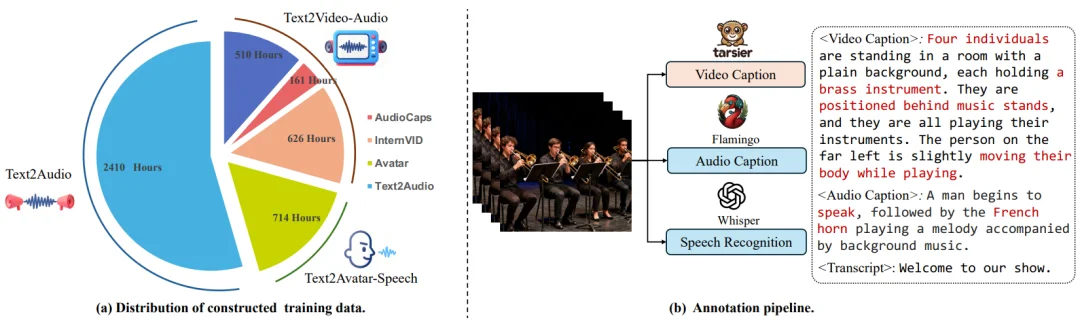
作者构建了包含三个部分的训练数据集:Text2Audio(环境音)、Text2Video-Audio(自然场景视听对)以及 Text2Avatar-Speech(数字人 / 说话人视频),总共约 1.9M 的训练样本。数据标注采用了一套自动化流水线:使用 Tarsier2 生成视频描述,Audio-flamingo3 生成音频描述,并利用 Whisper 进行自动语音识别(ASR)以获取语音文本。
在实施细节上,采用两阶段训练策略:先进行语音单模态独立训练(80K 步),再进行联合视听训练(50K 步),并在推理时使用了分类器无关引导(Classifier-Free Guidance)以提升生成质量。
在 UniAvatar-Bench(作者精选的 100 个样本)和 Verse-Bench(600 个多样化样本)两个基准上进行了评估。对比对象包括两类:一是使用真实音频驱动的视频生成模型(如 Wan-S2V, Fantasy-Talking),二是联合视听生成模型(如 Universe-1, OVI)。
UniAvatar-Bench 表现:JoVA 在整体性能上表现最佳。
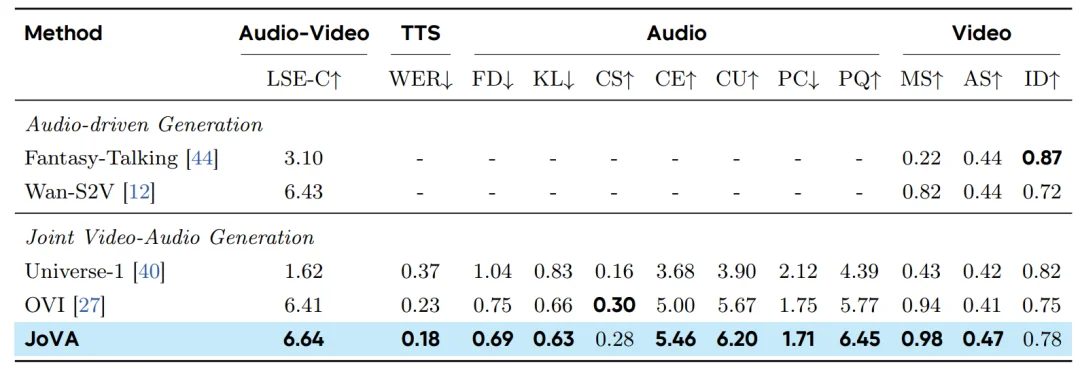
Verse-Bench 表现:JoVA 展现了在多样化场景下的鲁棒性。
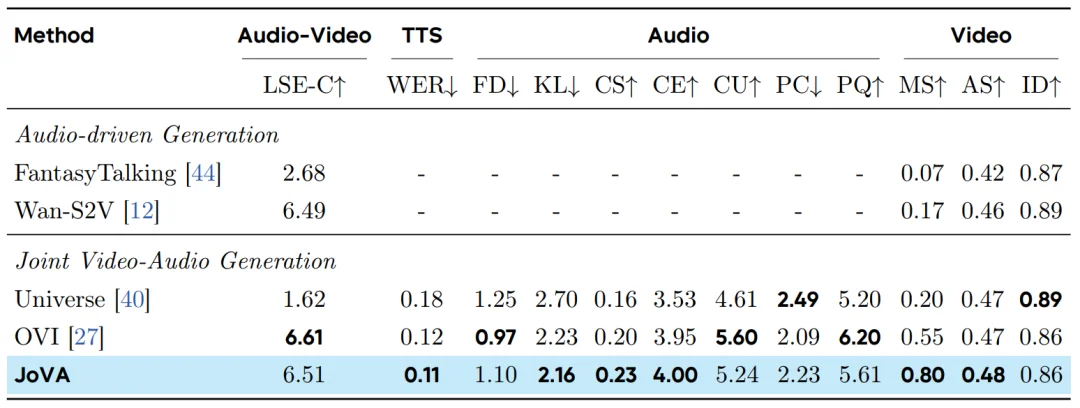
模型扩展性与效率分析
研究进一步对比了基于 Waver-1.6B(总参数量 3.2B)和 Waver-12B(总参数量 24B)主干网络的 JoVA 模型性能:

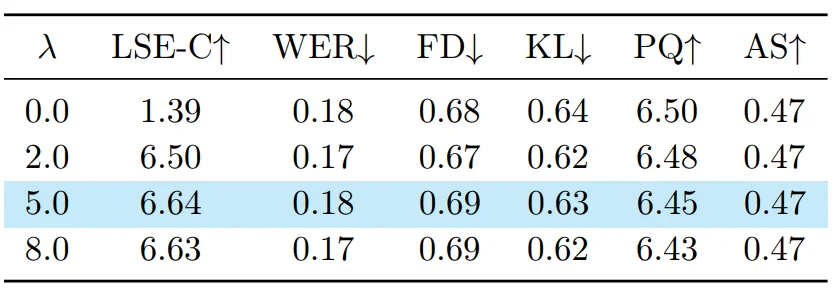
为了验证各模块的有效性,作者进行了多项消融实验:
嘴部感知损失(Mouth-Aware Loss)的影响:
时间对齐 RoPE 的影响:
联合自注意力 vs. 交叉注意力:

文章来自于“机器之心”,作者 “黄小虎”。


【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
