# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2026年将至,ChatGPT发布三周年,但关于“AI瓶颈期”的焦虑正达到顶峰。
当全行业都在讨论如何通过量化、蒸馏来“省钱”时,新加坡国立大学校长青年教授、潞晨科技创始人尤洋却提出了一个更为本质的拷问:
如果给你300亿美元预算,今天我们真的能训出比GPT-4强出几个维度的模型吗?
在《智能增长的瓶颈》一文中,尤洋教授一针见血地指出:
当前智能增长的瓶颈,本质上是我们现有的技术范式,已经快要“消化”不动持续增长的算力了。
他提出了几个颠覆常规认知的硬核观点:
从电影制作到地震时间预测,我们离真正的AGI还有多远?……

这篇深度长文,或许能带你穿透“降本增效”的迷雾,直达算力与智能最底层的逻辑。
一起来看。
什么是智能?
尤洋没有照搬任何形式化或哲学化的“智能定义”。
相反,他采用了一种非常工程化、面向能力评估的处理方式,通过一组可验证、可实践的判断标准来刻画智能的边界:
这些例子背后,指向的是同一个核心能力:即对未来状态进行预测,并为预测结果承担实际后果的能力。

这一锋利的判断,不仅解释了为什么Next-Token Prediction能在过去几年成为事实上的“智能发动机”,也解释了为何许多“在封闭评测中表现出色”的系统,一旦进入真实世界就迅速暴露短板——
它们往往擅长组织与解释已有信息,却难以在不确定环境中对未来做出稳定、可执行的判断。
当然,需要强调的是,将智能高度凝聚为“预测”,更像是在给智能划定一个工程上可对齐算力投入的核心能力维度,而非穷尽智能的全部内涵。
这是一个足够清晰也足够有解释力的硬核视角。而规划、因果建模以及长期一致性等能力,是否能够完全被还原为预测问题,仍然是一个开放议题。
但当我们把智能简化为预测能力时,下一步的问题自然落到:算力是如何转化为这种能力的?
过去几年,行业对训练范式的讨论,常常被“方法论优越感”主导;但如果把目标限定为单位算力能换来多少智能,那么范式本身就不再神秘,而变成了一种算力使用策略。
不同于主流叙事,尤洋在文章中直接把预训练、微调、强化学习三者拉到统一层面,即三者本质上都是在计算梯度,更新参数。
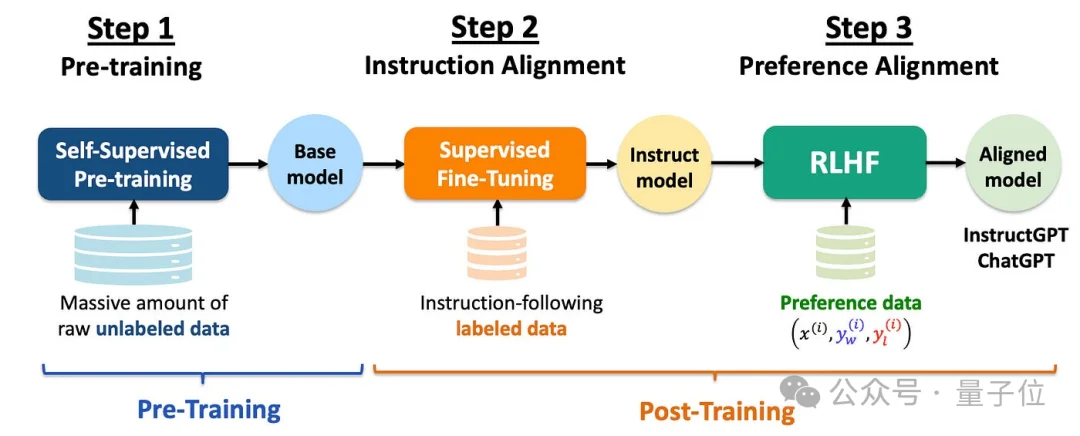
文章指出,当前模型的主要智能来源,依然是预训练阶段——不是因为它更“聪明”,而是因为它消耗了最多的能源与计算。
从智能增长角度看,这三者参数更新发生的频率与更新所消耗的算力规模确有不同,但是通过视角的转换,智能增长的讨论就从方法论之争,转向了一个更朴素,也更残酷的问题——
在算力持续投入的前提下,我们是否还能稳定地换取能力增长?
为了回答这个问题,这篇文章回溯了过去十年大模型快速进化的原因。尤洋指出,这一轮智能跃迁的成立,依赖于三件事情同时发生:
因此,Transformer的成功,并不仅仅是算法层面的胜利,更源于模型架构与硬件体系高度匹配的系统性结果。
在这三者共同作用下,算力增长、模型规模扩大与能力提升之间形成了一条相对稳定的正反馈链路。
需要注意的是,这一范式的有效性,也在一定程度上受益于语言任务本身的结构特性:语言高度符号化、序列化,且评测体系与训练目标高度一致。
这使得算力增长、模型规模扩大与能力提升之间,在这一阶段形成了一条相对稳定的正反馈链路。
也正是在这一历史条件下,从GPT-1、GPT-2到GPT-3,再到ChatGPT,智能水平得以沿着同一范式持续抬升。
这也自然引出了后文的核心问题:
当算力继续增长时,我们是否还拥有同样可扩展的范式?
尤洋在文中提出了一个非常具体、也非常可操作的标准来判断智能的瓶颈:
当一次训练的FLOPS从10^n变成10^{n+3}时,我们是否还能稳定地获得显著更强的模型?
如果答案开始变得不确定,那么问题就不在于“算力是否继续增长”,而在于:
这也是文章里反复强调FLOPS的原因:
Token数、参数量、推理速度,往往会混合效率与商业因素;而FLOPS才是最底层、也最难被包装或美化的算力尺度。
在这个意义上,所谓“瓶颈”,并不是红利消失,而是算力增长与智能增长之间的映射关系开始松动。
更值得一提的是,尤洋在文章中刻意把讨论从“效率优化”里拎出来,换了一个更接近一线大厂决策的场景:
假设今天Google拍给你一张“300亿美元预算”的支票,给你半年DDL——在这种极限训练目标下,你还会优先选择Mamba这类“吞吐量更高”的架构吗?
未必。因为吞吐量解决的是“同等智能更便宜”,不自动等价于“同等成本更聪明”。
真正的难点变成:我们到底有没有一种扩展性更强的架构或Loss函数,能把新增算力更稳定地“吃进去”,并把它转换成可兑现的能力增量?
那么如何能在单位时间内吃下更多算力,并真正将它转化为智能呢?
在正式回答算力转化智能的问题之前,尤洋还对硬件与基础设施层面进行了深入的探讨。
他根据自身多年的从业经验得出,计算开销/通信开销的比值,必须维持或提升,这样才能在继续堆叠GPU的情况下,线性地换来更多智能。
因此,未来AI基础设施的核心目标,应该关注并行计算体系在软硬件层面的整体扩展性,而不仅仅是单点芯片性能。
在这一基础上,尤洋最后提出了多个探索方向,比如更高精度、高阶优化器,更可扩展的架构或者Loss函数,更多epoch与更深度的超参数探索。
这些探索方向,都在试图回答同一个命题——如何让模型在“吃掉”万亿级投入的同时,吐出等比例增强的智能?
对于智能的进一步增长而言,真正重要的,是在极端算力条件下持续变强的能力——这也意味着,预训练所能承载的智能增长空间,可能还远未走到尽头。
回到最初讨论的问题,算力到底还能不能继续转化为智能?
尤洋并未给出断言,但逻辑已经清晰:
只要我们还能找到更高效组织计算的方式,智能的上限就远未到来。
原文传送门(或点击“阅读原文”):
https://zhuanlan.zhihu.com/p/1989100535295538013
文章来自于“量子位”,作者 “允中”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
