# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近在研究 RAG 系统优化的时候,发现了一个有意思的格式叫 TOON。
全称是 Token-Oriented Object Notation,翻译过来就是面向 Token 的对象表示法。
说实话,第一次看到这个名字我就被吸引了。因为搞 AI 应用的人都知道,Token 费用是真的贵。
但深入研究之后,我发现这事没那么简单。
省 Token 是真的,但代价也是真的。
今天就来聊聊这个权衡。
先说说为什么会有 TOON 这东西
用大模型做开发的朋友应该都有感受,JSON 真的太费 Token 了。
每个字段名都要用双引号包起来,每个对象都要花括号,每个数组都要方括号。
更要命的是,如果你有一个 1000 行的用户列表,"username" 这个字段名要重复 1000 次。
有研究估算,在 RAG 场景下,这种结构性字符占据了输入 Token 的 40% 到 60%。
这就是所谓的「语法税」。
你付的钱里,有一半是在给花括号和引号买单。

Token费用账单:花括号、引号、重复字段名占据40-60%的开销
TOON 的解决思路其实很暴力
既然花括号费钱,那就不要花括号。
既然引号费钱,那就不要引号。
既然字段名重复,那就只写一次。
来看个对比。
JSON 是这样的:
{"users": [{"id": 1, "name": "Alice"}, {"id": 2, "name": "Bob"}]}
TOON 是这样的:
users[2]{id,name}:1,Alice2,Bob
字段名只在头部声明一次,后面的数据行只有值,用逗号分隔。
这种表格化的写法,把 Token 消耗压到了极限。

JSON繁琐的花括号引号 vs TOON简洁的表格形式,Token节省一目了然
实测效果确实惊艳
在扁平对象列表场景下,TOON 能省 45% 左右的 Token。
在深层嵌套且字段名较长的情况下,甚至能省到 70%。
如果你的 RAG 系统每天处理几百万条检索结果,这个节省是实打实的钱。
但问题来了
省 Token 会不会让模型变笨?
这是我最关心的问题,也是很多开发者担心的。
答案是:看场景。
简单检索任务,TOON 表现还不错
官方给的数据显示,在简单的信息提取任务里,TOON 的准确率甚至比 JSON 还高一点。
比如「找出 ID 为 5 的用户的名字」这种任务。
解释是 JSON 那些花括号和引号其实是「噪音」,TOON 去掉噪音之后,模型反而能更专注于数据本身。
这个说法有一定道理。
但复杂推理任务,TOON 就拉胯了
第三方独立测试给出了另一个数字:47.5%。
在涉及跨行比较、聚合计算、逻辑推理的测试中,TOON 的准确率只有 47.5%,落后于 JSON 的 52.3%。
更惨的是,在处理深层嵌套数据时,TOON 准确率跌到了 43.1%,垫底。
而同样的测试里,Markdown 表格拿到了 60.7%,YAML 拿到了 62.1%。
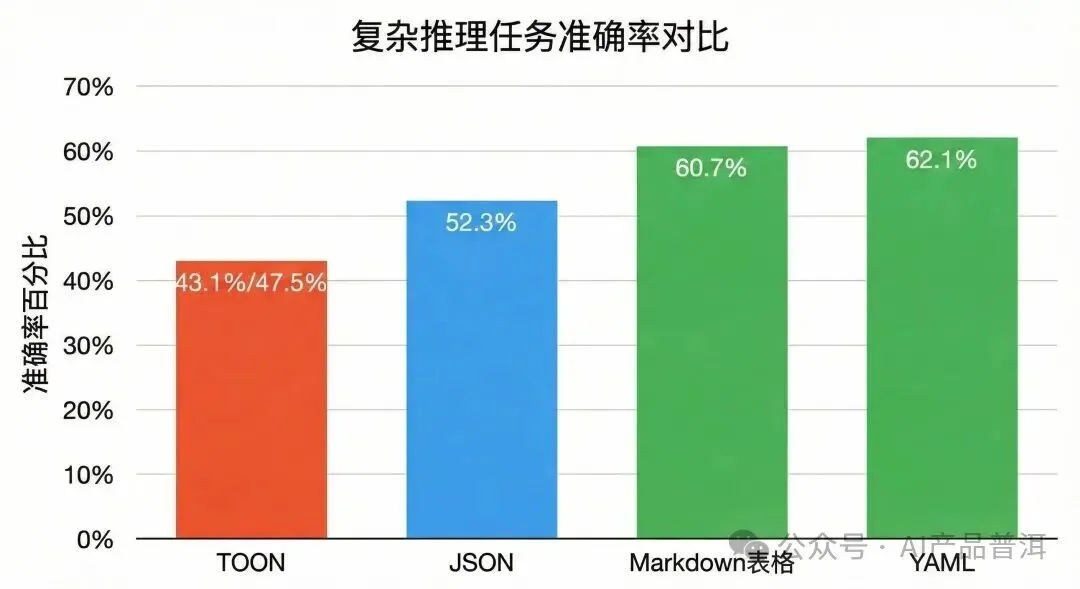
复杂推理任务准确率:TOON垫底,YAML和Markdown表现更好
为什么会这样?
这要从大模型的工作原理说起。
局部性原理
JSON 有个好处:键和值挨得很近。
当模型读到 "admin" 这个值的时候,前一个 Token 就是 "role"。
模型只需要看看邻居就知道这个值是什么意思。
但 TOON 不一样。
当模型读到第 50 行的 admin 时,定义它含义的表头 {role} 可能在几百个 Token 之前。
模型要维持一个很长的注意力连接,才能正确理解这个值。
在超长列表的末端,模型容易出现「列错位」的幻觉,把第三列的值当成第四列。
📌 想第一时间获取这类技术解读?关注公众号「AI产品普洱」设为星标 ⭐,新文章不错过。进群交流?回复"交流群",我拉你。
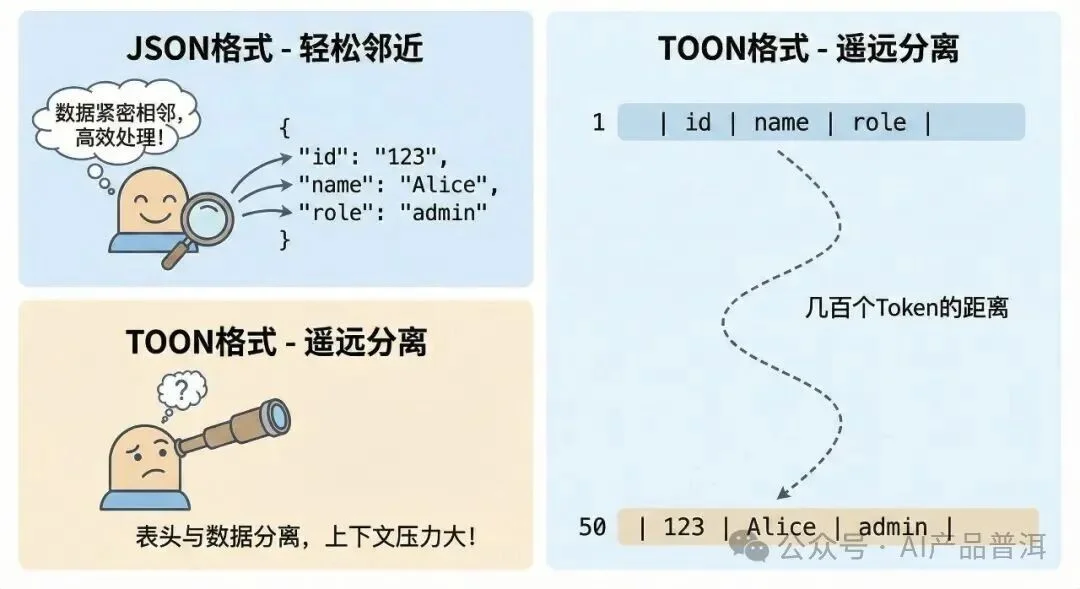
JSON键值紧邻易理解,TOON表头与数据相距甚远导致模型困惑
训练数据偏差
现有的大模型是在海量 JSON 数据上训练的。
它们对 JSON 有「肌肉记忆」,处理起来又快又准。
但 TOON 是 2025 年左右才出现的新格式,在模型的预训练语料里几乎不存在。
模型面对 TOON 的时候,是在处理「分布外数据」。
虽然大模型有很强的泛化能力,但面对陌生语法,出错的概率必然更高。
冗余的价值
JSON 那些重复的字段名虽然浪费 Token,但它一直在「提醒」模型:这是 id,这是 name,这是 role。
TOON 去掉了这种提醒,模型只能靠自己的记忆来追踪结构。
对简单任务来说,这没问题。
但对复杂推理来说,这种冗余的缺失可能就是推理断链的关键因素。
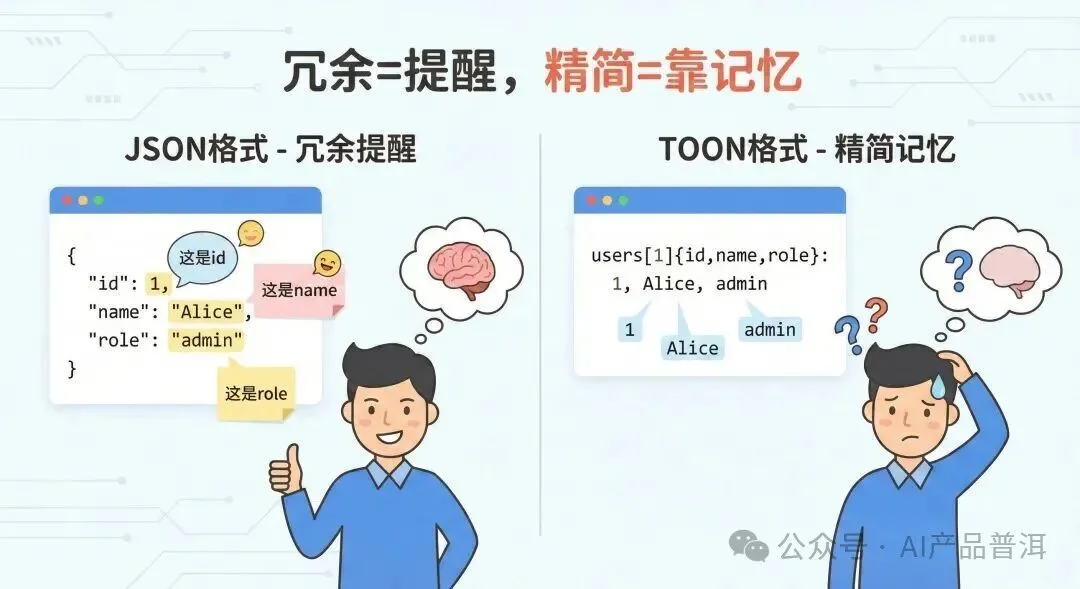
JSON每个值都有标签提醒,TOON则需要模型靠记忆追踪结构
TOON 还有几个具体的坑
列漂移
如果某一行的某个字段为空或缺失,模型可能把后续字段错误地前移。

空字段导致后续数据错误前移,模型把城市当成了年龄
结构性遗忘
在处理极长的数据流时,模型可能「忘记」头部的字段定义。
读到第 200 行的时候,模型可能已经不记得第 3 列是价格还是数量了。
生成格式错误
让模型输出 TOON 格式是个噩梦。
模型很难提前计算数组长度,经常生成无效语法。
必须在 Prompt 里教模型认识 TOON
因为模型对 TOON 陌生,你要在 System Prompt 里加一段说明:
「以下数据采用 TOON 格式。该格式使用缩进表示嵌套,使用 key[N]{columns} 表示表格化数组。请依据表头定义解析数据。」
这种简单的「上下文教学」能显著提升准确率。
建立场景白名单
适合用 TOON 的场景:RAG 检索结果、长历史记录摘要、大数据量日志分类。
这些场景的共同特点是:数据量大、结构一致、只读、逻辑简单。
不适合用 TOON 的场景:复杂数学推理、深层嵌套配置生成、高精度金融数据处理。
这些场景还是老老实实用 JSON 或 Markdown。
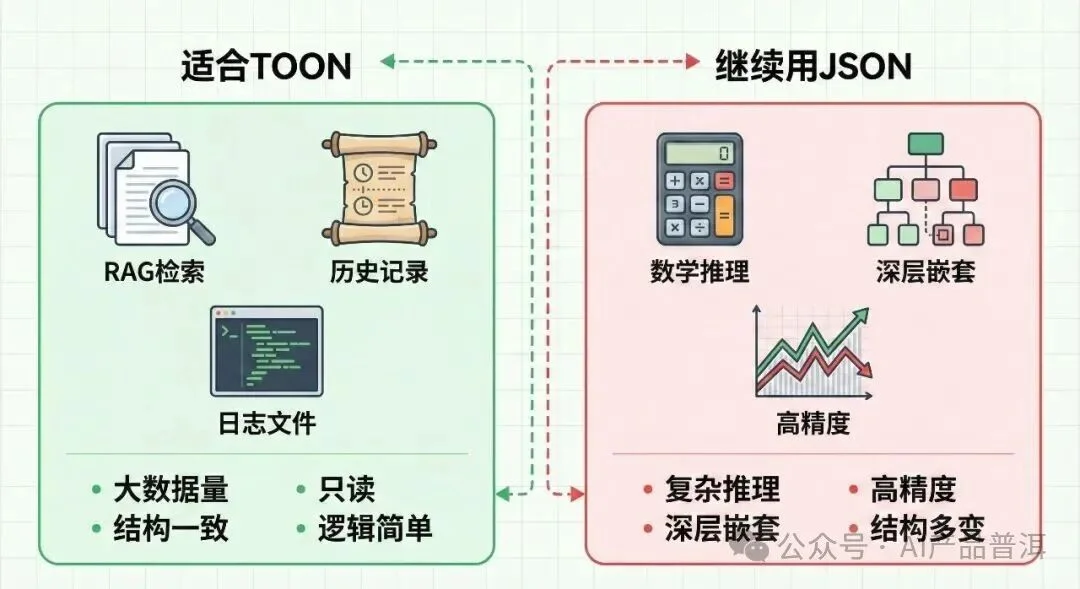
左边绿色区域适合TOON的场景,右边红色区域应继续使用JSON
总结一下
TOON 不是银弹,也不是废品。
它是一种需要特定工程策略来驾驭的高级工具。
Token 节省是真的,30% 到 60% 的节省在高频场景下能省不少钱。
理解能力下降的风险也是真的,尤其是复杂推理和长距离依赖的任务。
场景决定优劣:浅层、大量、一致的数据用 TOON,深层、复杂、生成的任务用 JSON。
如果你正在做 RAG 系统优化,可以在检索列表这个环节试试 TOON。
但核心的推理逻辑,还是让 JSON 和 Markdown 来扛吧。
评论区聊聊你的看法,你会在项目里尝试 TOON 吗?
我是 AI 产品普洱,咱们下期见。
文章来自于微信公众号 “AI产品普洱”,作者 “AI产品普洱”


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
