# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大部分的高质量视频生成模型,都只能生成上限约15秒的视频。清晰度提高之后,生成的视频时长还会再一次缩短。
这就让尝试AI视频创意的创作者们非常苦恼了。要想实现创意,必须使用分段生成,结合首尾帧,不仅操作起来很麻烦,而且需要来回抽卡来保证画面的一致性。
那么,限制视频生成时长的瓶颈在哪里?
大家可能不知道的是,一段 60 秒、480p、24 帧/秒的视频,在模型内部会被拆解成 超过 50 万个「潜在 token」。
这些 token 就像一条极长的记忆胶带,模型想要保持剧情连贯、画面一致,就必须从头到尾保存上下文记忆。但代价是:算力直接爆炸,普通显卡根本扛不住。
这正是当前自回归视频生成模型的核心矛盾。一边是越长的上下文,画面越连贯;另一边是越长的上下文,计算成本越高。
于是,研究者们不得不做出妥协:要么用滑动窗口切掉大部分历史,换取可运行的算力;要么对视频进行激进压缩,牺牲清晰度和细节。
问题在于,这些压缩方法往往最先丢掉的,正是决定画面真实感与一致性的高频细节。
也正是在这一困境下,苏州大学校友,斯坦福大学博士,ControlNet 创作者张吕敏团队为此投入了研究,提出了一种新的解决思路,给出了专为长视频设计的记忆压缩系统,在压缩的同时尽可能保留精细视觉信息。

研究团队提出了一种神经网络结构,用于将长视频压缩为短上下文,并设计了一种显式的预训练目标,使模型能够在任意时间位置保留单帧中的高频细节信息。
基线模型可以将一段20 秒的视频压缩为约 5k 长度的上下文表示,同时支持从中随机检索单帧,并在感知质量上保持良好的外观保真度。
这种预训练模型可以直接微调为自回归视频模型的记忆编码器(memory encoder),从而以较低的上下文成本实现长历史记忆建模,并且仅带来相对较小的保真度损失。

该视频是使用完整历史上下文(不切割任何历史帧)逐秒自回归生成的。20 多秒的历史被压缩为 ∼ 5k 上下文长度,并由 RTX 4070 12GB 处理。
具体而言,研究团队采用两阶段策略:
首先,预训练一个专用的记忆压缩模型,其目标是在任意时间位置上尽可能保留高保真帧级细节信息。
该预训练目标通过对从压缩历史中随机采样的帧最小化其特征距离来实现,从而确保模型在整个序列范围内都能稳健地编码细节信息。
在网络结构设计上,提出了一种轻量级双路径架构:模型同时处理低分辨率视频流和高分辨率残差信息流,并通过将高分辨率特征直接注入 Diffusion Transformer 的内部通道,绕过传统 VAE 所带来的信息瓶颈,从而进一步提升细节保真度。
预训练记忆压缩模型
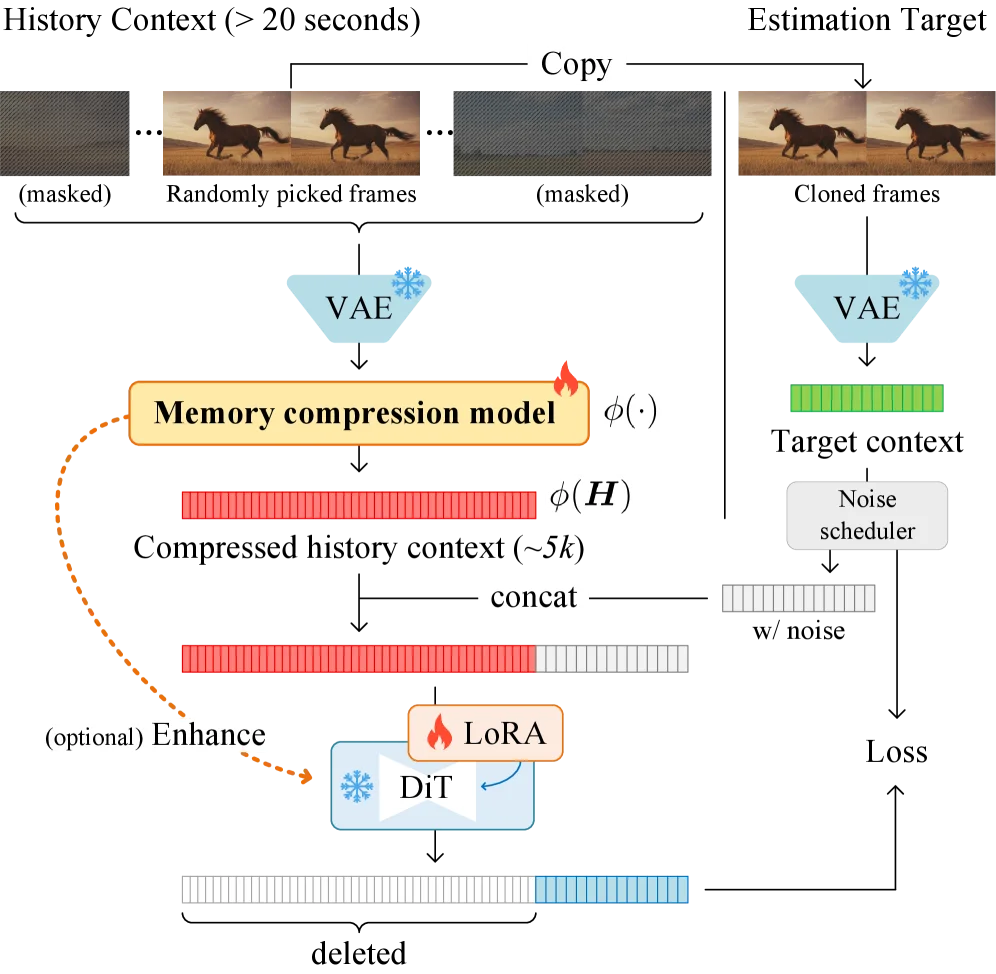
记忆压缩模型的预训练。记忆压缩模型需要将长视频(例如 20 秒)压缩成短上下文(例如长度为 5k)。预训练的目标是在任意历史时间位置检索具有高频细节的帧。
该方法的核心创新在于其预训练目标设计。
研究团队观察到,衡量视频压缩机制保留上下文细节能力的一个合适的指标是其任意时间位置高质量帧检索的能力。对于高压缩率,完美检索变得不切实际,因此目标变为最大化任意帧的检索质量。

在训练过程中,模型从历史序列中随机选择一组帧索引 Ω,并对其余所有帧进行噪声掩蔽处理;模型必须仅依赖压缩后的表示来重建这些被选中的帧。
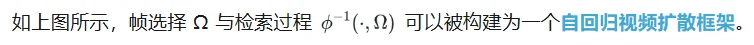

随后,研究团队将所选的干净帧复制作为扩散模型的目标,使扩散系统能够在任意时间位置重建目标帧。该过程可表示为:
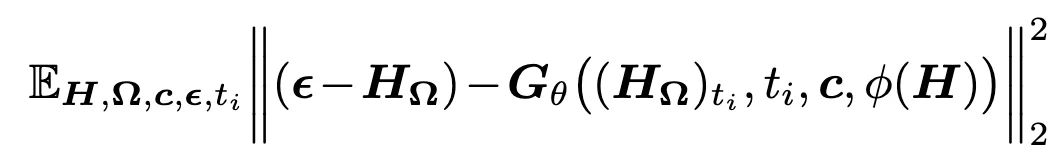
这种随机化选择机制有效防止模型通过仅编码易于访问的帧(例如首帧或末帧)来「投机取巧」,从而迫使模型学习一种能够在整个时间序列范围内持续保留细节信息的表示方式。
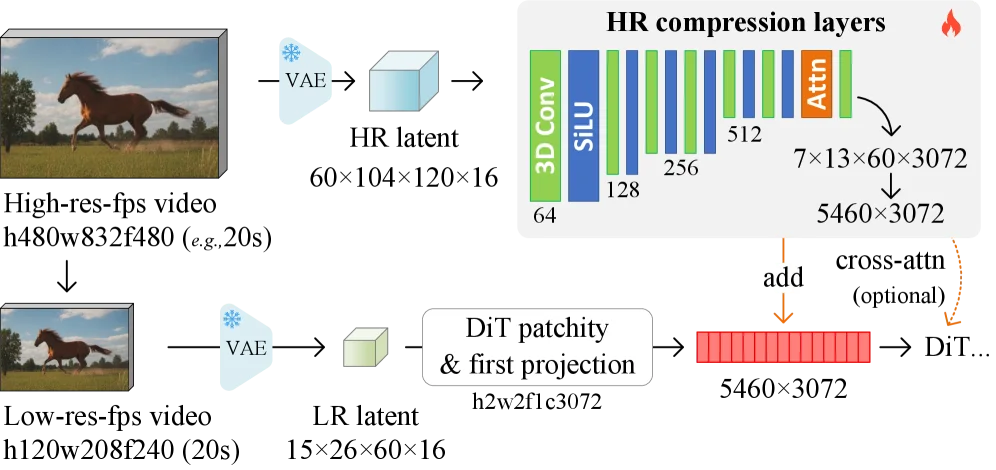
内存压缩模型的架构。使用 3D 卷积、SiLU 和注意力机制来构建一个轻量级的神经网络结构,作为基准压缩模型。
视频扩散模型的微调
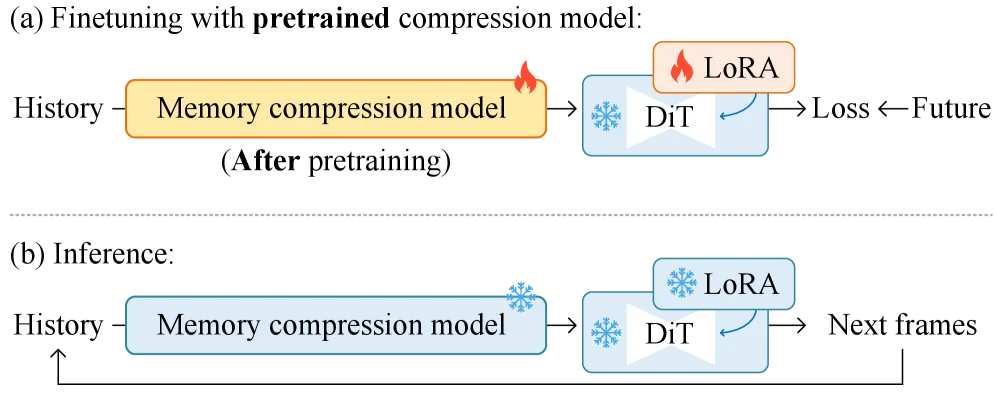
微调自回归视频模型。展示了最终自回归视频模型的微调和推理过程。记忆压缩模型的预训练在微调之前完成。

由此得到的视频生成模型具备超长历史窗口(例如超过 20 秒)、极短的历史上下文长度(例如约 5k),并且对帧检索质量进行了显式优化。
该扩散过程亦可按照公式表示为:
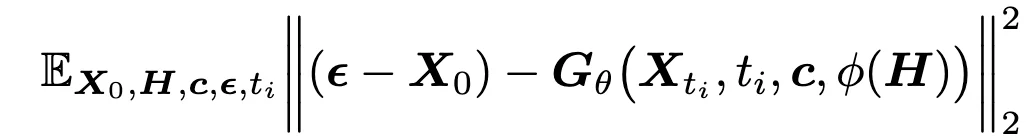
在实验中,研究团队使用 8 × H100 GPU 集群进行预训练,并使用 1 × H100s 或 A100s 进行 LoRAs 微调。所有实验均在 HunyuanVideo和 Wan 系列的基础模型上进行。
数据集由来自多个网站的约 500 万互联网视频组成。其中约一半是竖屏短视频,其余为普通横屏视频。数据经过质量清洗,然后使用 Gemini-2.5-flash VLM 对高质量部分进行字幕标注,剩余部分使用本地 VLM(如 QwenVL)进行处理。测试集包括由 Gemini-2.5-pro 编写的 1000 个故事板提示和 4096 个未在训练数据集中出现过的视频。

故事板上的定性结果。通过从故事板中流式传输提示来展示结果。故事板是一组提示,其中每个提示涵盖一定数量的帧。故事板可以由外部语言模型编写。
在定性评估方面,如图所示,研究者证明了模型能够处理多种多样的提示和故事板,同时在角色、场景、物体和情节线方面保持一致性。
在定量评估方面,研究者们从 VBench、VBench2等平台引入了多个视频评估指标,并进行了一些修改。
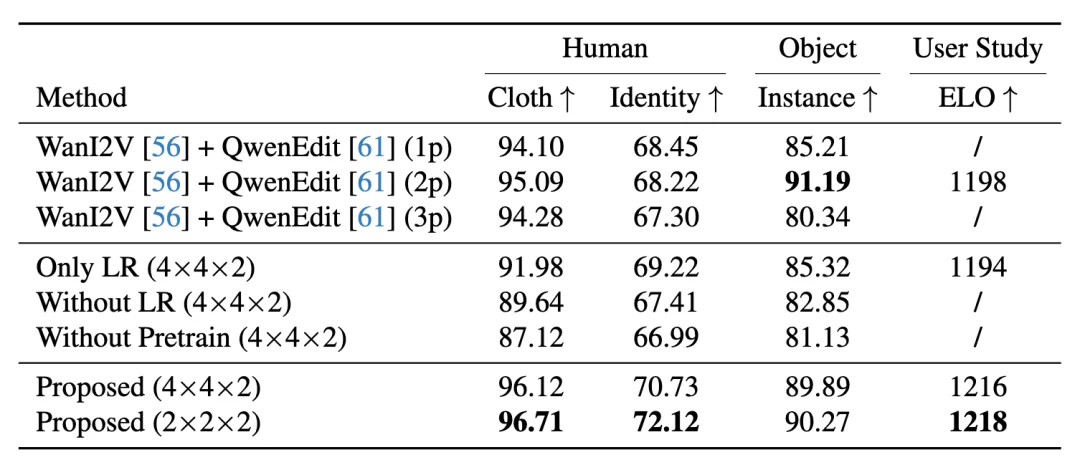
视频内容一致性的定量评测结果。其中,Qwen 中的 「1p」 表示仅使用 1 张图像 作为图像模型输入。由于部分方法存在严重伪影,因此未将其纳入人工 ELO 评分统计。
如表所示,本文提出的方法在多个一致性指标上表现出合理的分数。Wan+Qwen 组合在实例分数上似乎具有领先分数,这可能是由于图像模型不会显著改变或移动对象,从而避免了 VLM 问答检测到的伪影。本文的方法在对象一致性方面表现出有竞争力的分数。此外,用户研究和 ELO 分数验证了本文提出的架构,证实它在压缩和质量之间实现了有效的权衡。
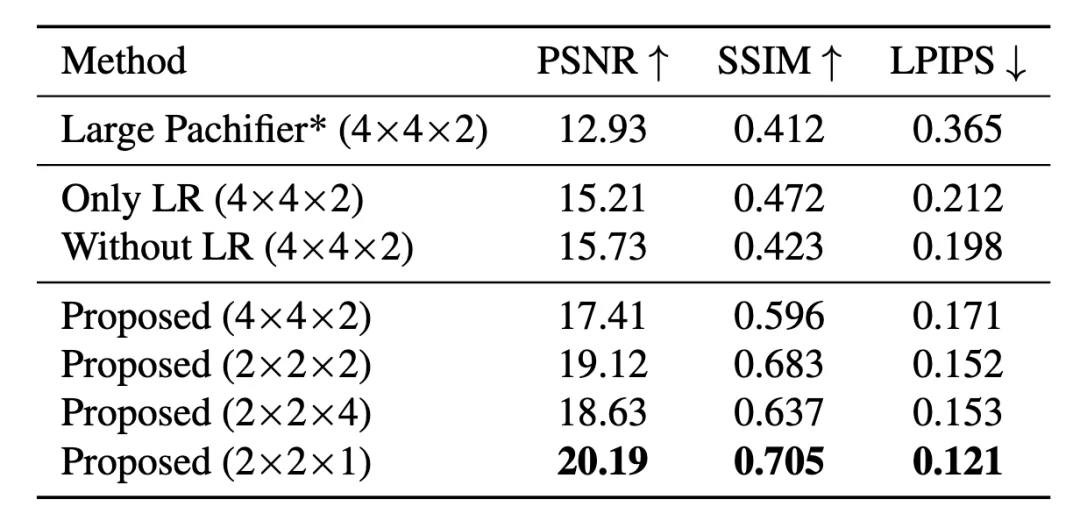
压缩结构的定量结果。展示了使用不同消融压缩架构的数值测试。
评测结果如表所示。结果表明,本文方法在 PSNR、SSIM 等指标上取得了相对更优的性能。此外,即便在 4×4×2 的较高压缩率条件下,该方法仍然能够有效保持原始图像结构。

压缩重建的视觉比较。展示了使用不同可能的神经网络结构和各种压缩设置进行预训练后的重建结果。

记忆压缩模型预训练的影响。展示了使用或未使用记忆压缩模型预训练的结果。输入是相同的 20 秒历史视频,在输出帧中可视化中间帧。
除此以外,研究团队还在论文中讨论了不同神经网络架构设计之间的权衡取舍。
更多信息,请参阅原论文。
文章来自于“机器之心”,作者 “冷猫”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
