# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
零成本降低大模型幻觉新方法,让DeepSeek准确率提升51%!
方法名为LingoEDU(简称EDU),即基本信息单元(Elementary Discourse Unit,EDU)技术。
LingoEDU在大模型正式生成之前装上的一个专门执行「预处理环节」的模型,这一环节主打精准切分,并且为每一个最小信息单元分配唯一的索引标记,给每一个生成内容打上标号——当需要引用某个信息时,可以精确地指向它的位置。
如此一来,让信息进入主模型进行思考生成前,先完成结构化预处理。
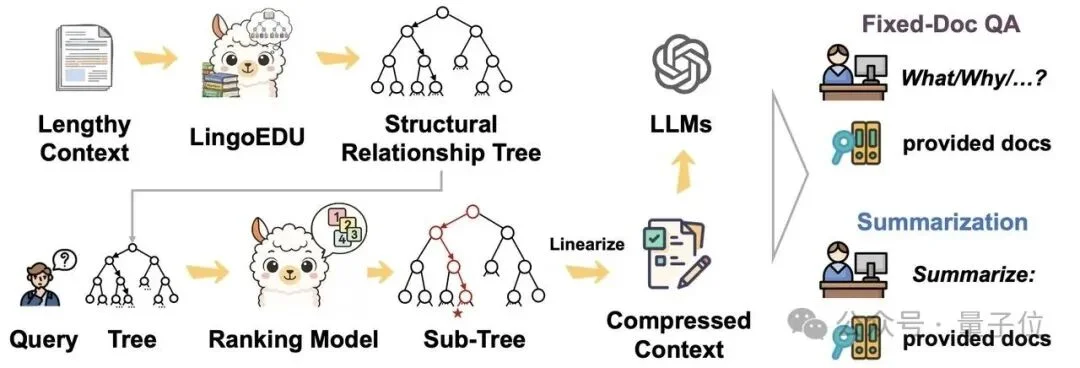
LingoEDU示意:将原文拆分成基本语义单元树后,能方便地在多文档问答、文档总结、DeepSearch等应用场景进行高效地上下文处理
这种「坐标系」让后续的所有操作都可以溯源,模型输出的任何内容都能精确对应到原文的具体位置,将「生成」关进「可追溯」的笼子里。
试想,如果生成的每句话、每个信息点都能精准地追溯到原文,都能check其正确与否,那么幻觉问题就可以在最大程度上被解决。
总结来说,其核心是对上下文进行结构化的精准切分,形成富含结构信息和语义信息的篇章结构树——每个节点都是一个完整的基本话语单元,节点之间通过清晰的层级关系连接。
LingoEDU具备如下优点:
1. 所形成的最小信息单元完整保留了原文的「语义信息」,同时保留了节点信息的完整性和节点之间信息的连贯性。
2. 使得上下文包含精准的「结构信息」,便于高效压缩,提升生成准确性。
实验结果显示,LingoEDU在切分准确性指标上显著超过所有基线模型,在成本和效率上也显著优于所有通用大模型的方法。
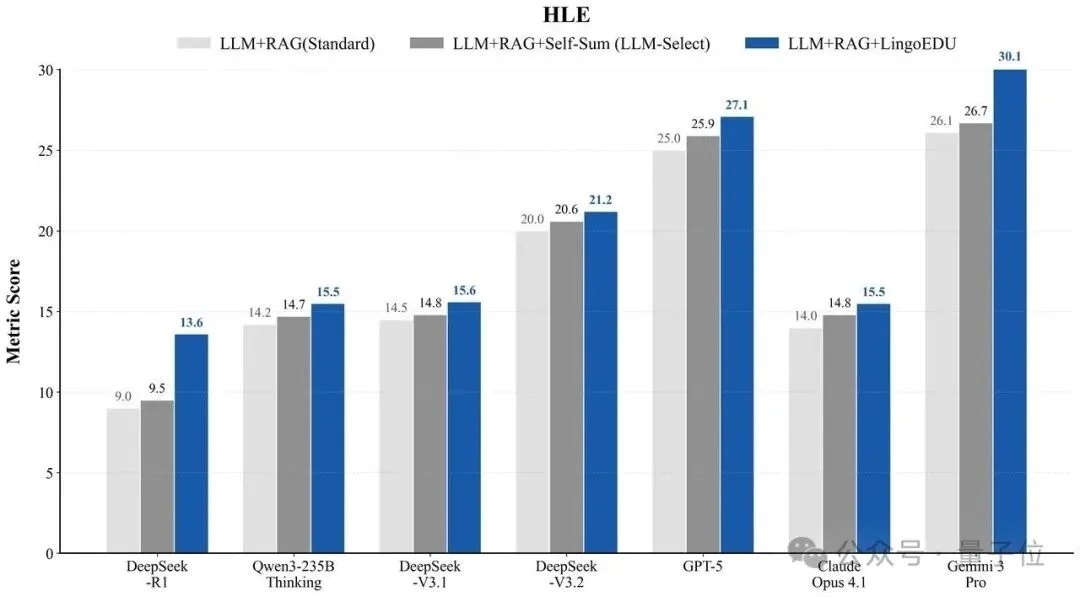
LingoEDU能够零成本适配所有大模型。在有着“AGI终极试炼”之称的HLE榜单上,DeepSeek-R1的准确率是9.0%,使用EDU之后准确率提升到13.6%,准确率相对提升51%。
这项研究由深言科技联合清华大学NLP实验室提出,以下是更多细节。

大模型产生幻觉的核心原因,从输出一侧来看,可以归结为其任务是基于概率的“合理的下一个词”的生成器;从输入一侧来看,则是由于输入的上下文过长,模型容易在海量信息中「迷路」,无法准确理解其中全部内容,从而产生不忠实于原文的输出。
前者是这种技术范式的固有特征,后者则可以在一定程度上被规范。
基于这一洞察,对后者问题的一个自然解决思路是:在把文档喂给模型之前,先做一些预处理,压缩去除冗余信息、保留必要信息,这样降低模型幻觉风险,同时降低模型处理成本和效率。
在过去的大模型训练过程中,任一基础模型都能实现对文档进行基本的结构化切分,但是其精准性却无法得到保证,这也是幻觉率居高不下的原因。
目前业界主要有两类上下文压缩方法,但都存在明显的缺陷:
这类方法直接对文本「动刀」,比如删除不重要的词或句子。
问题在于,这种操作往往基于单个词(Token)或粗糙的句子级别进行,容易把句子切得支离破碎。
比如,原文是「因为天气恶劣,航班被迫延误」,压缩后可能变成「天气恶劣,航班延误」——虽然保留了关键词,但因果关系变得模糊。
对模型来说,这就像阅读一篇被打了马赛克的文章,很难准确理解原意。
另一类方法是把文本压缩成向量表示(即“Gist Tokens”),相当于把整段话「浓缩」成一个黑盒表示。
这种方法效率很高,但问题在于:模型完全看不到原文是什么,只能依赖这个抽象的向量。
这就像让你只看一张照片的缩略图来描述细节——很容易产生误解和臆测。
归根结底,我们需要一种「两全其美」的方法:既保留文本的可读形式、避免黑盒带来的幻觉,又能维持语义的完整性、避免碎片化导致的连贯性丧失。
这就需要找到一种合适的切分方式,能把文档拆解成满足以上两个需求的信息块,作为文档处理、大模型正式生成的基础。
团队提出全新框架LingoEDU,核心是提升文档处理的可溯源性和生成质量。该方法包含两个核心部分:以忠实度为导向的输入/输出设计,以及一套严格的自我修正数据合成流程。
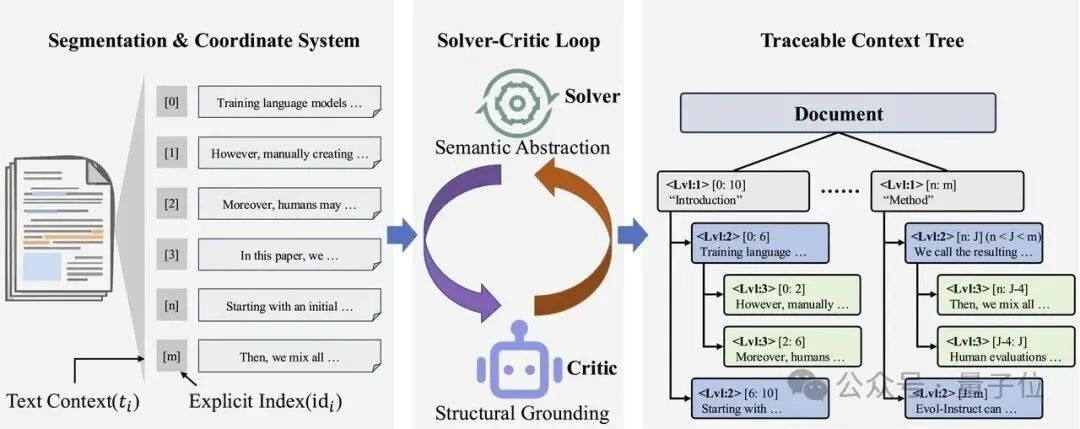
△ LingoEDU方法示意图
忠实度意味着可溯源性。团队通过将生成过程完全锚定在预定义的每一个EDU上,来实现这一目标。
1.EDU表示策略:前置唯一索引标记,为模型创建参考坐标系
2. 增强型结构生成:让模型「引用」而非「创作」
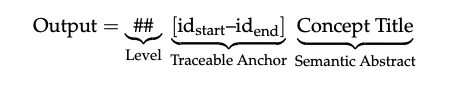
3. 受限解码:从物理上阻止幻觉
为了进一步确保忠实度,项目在推理阶段施加了严格的词法约束。当模型生成范围标记中的数字时,可选的词表被严格限制为当前输入中实际存在的索引。
这就像给模型戴上了一副”有色眼镜”——它只能”看到”真实存在的选项,从物理上阻止了编造不存在引用的可能性。
这一部分工作的核心作用是生产高质量的拆分数据用于模型训练。为了解决高质量、对齐的结构化数据稀缺的问题,项目引入了一个自动化流水线,其核心思想是在“角色”和“任务颗粒度”两个维度上进行分解。
1. 利用生成对抗的思想提升数据质量
2.双层任务分解(Bi-Level Task Decomposition)
核心作用:区分「结构信息」和「语义信息」,提升模型切分的准确性
为了验证LingoEDU的切分效果,团队构建了248篇文章(包含web和pdf文件)组成的语义切分评测数据集,在这个数据集上,对比了本项目所采用的切分方法和各种基线方法的效果,主要指标是树编辑距离(TED,Tree Edit Distance)和文章级别准确率(DLA,Document Level Accuracy),同时针对成本和效率进行了对比。
实验结果显示,本项目的方法在切分准确性指标TED和DLA上显著超过所有基线模型,在成本和效率上也显著优于所有通用大模型的方法。
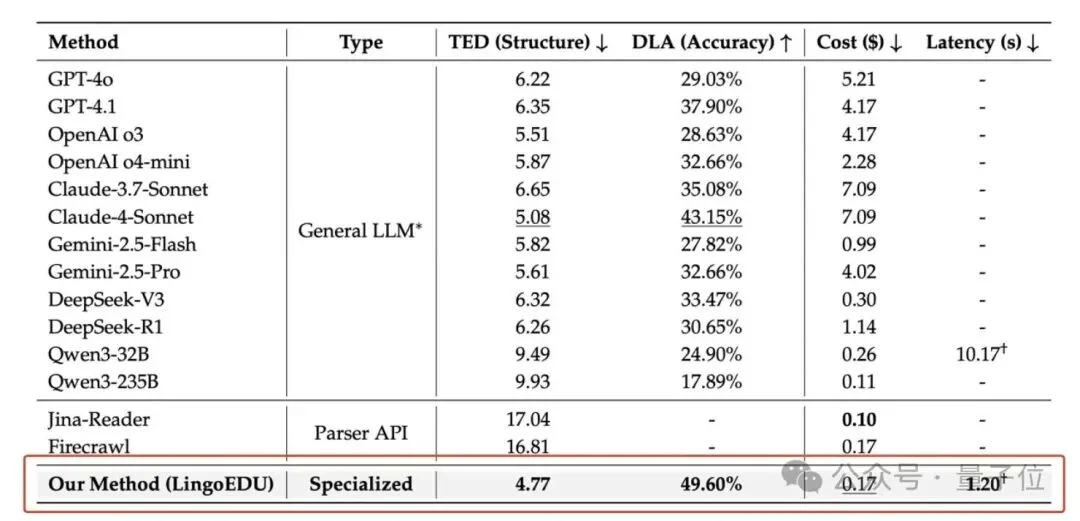
相对线形的文本,精细化切分后的语义单元树能提供更加丰富的结构化信息和更加细粒度的信息管理和压缩,提升模型生成的准确性;同时由于信息表达的方式相对原始文本没有发生变化,可以方便地应用在各种下游任务上。
在有着中文网页检索天花板难度之称的测试集BrowseComp-ZH上,将各大模型的LLM API+RAG Research叠加EDU技术后,准确率全部提升,其中DeepSeek V3.1提升的幅度近一倍,达到18.7%。
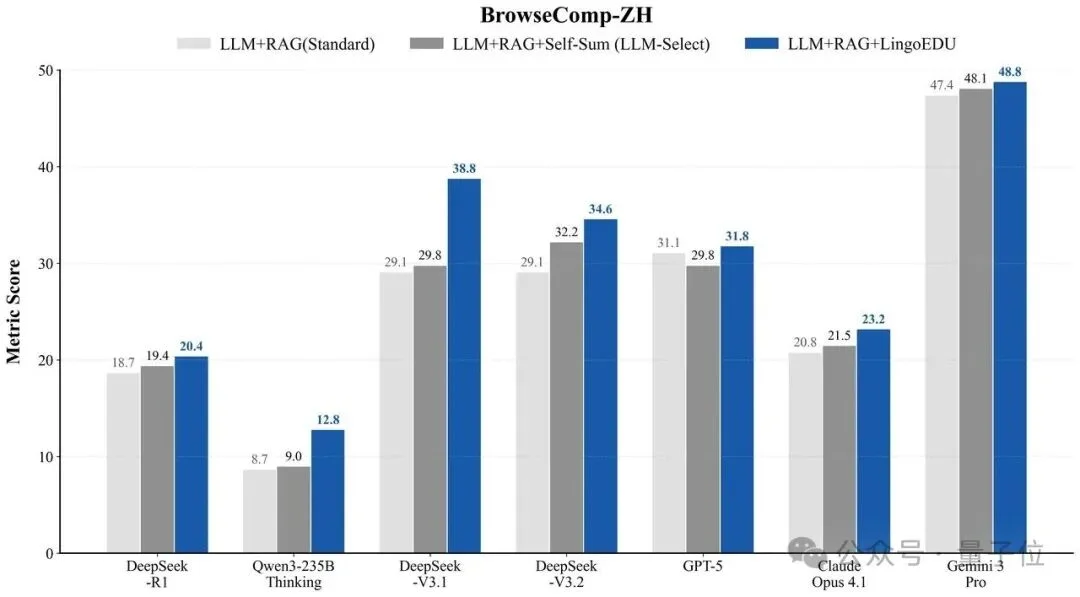
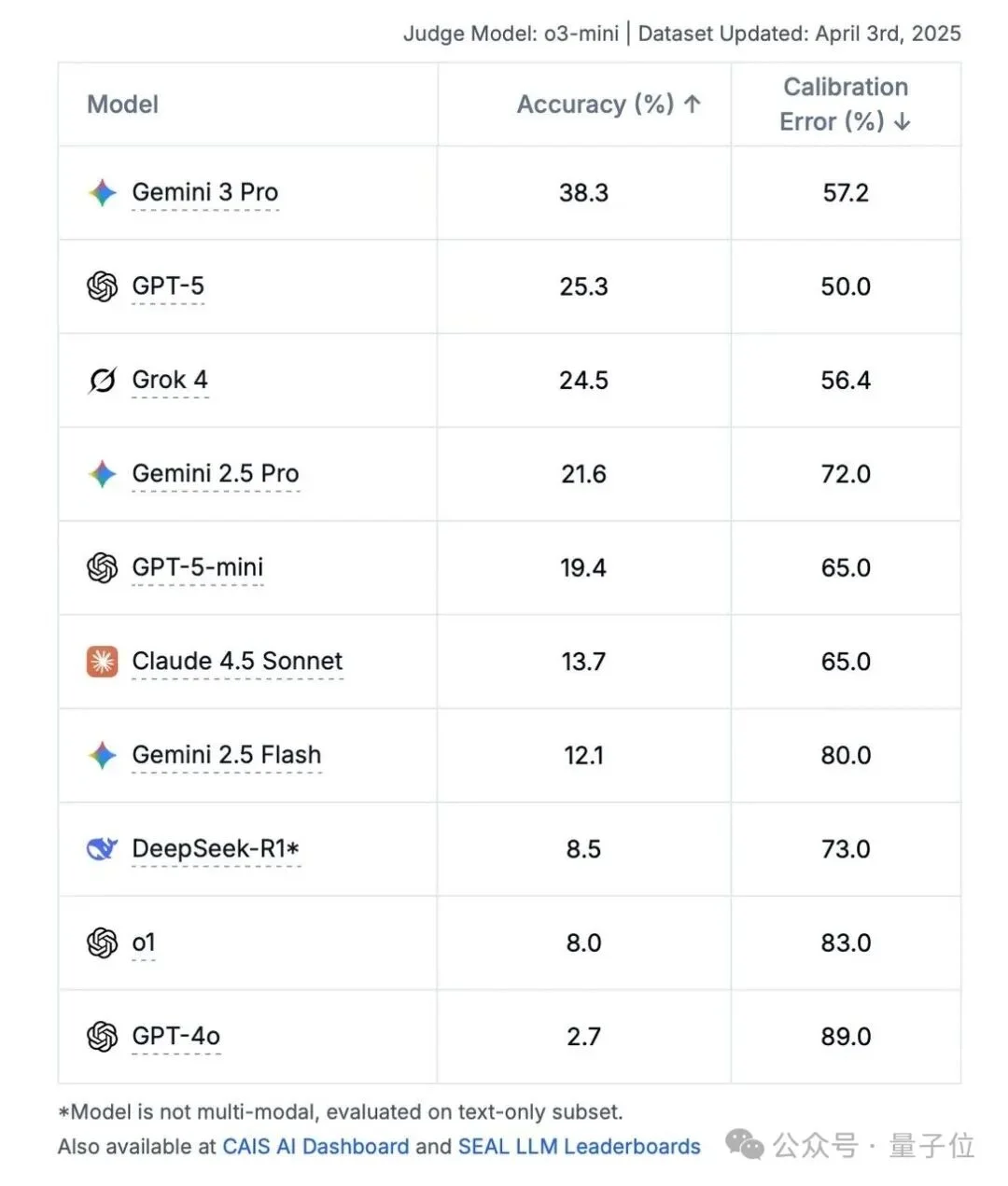
在有着“AGI终极试炼”之称的HLE(Humanity’s Last Exam,人类最后的考试)测评集上,官方数据对行业头部大模型准确率的测评结果如下:
适配EDU技术之后,各模型的准确率表现有明显提升,DeepSeek R1的提升幅度较大,从9.0%提升到13.6%,准确率相对提升51%。
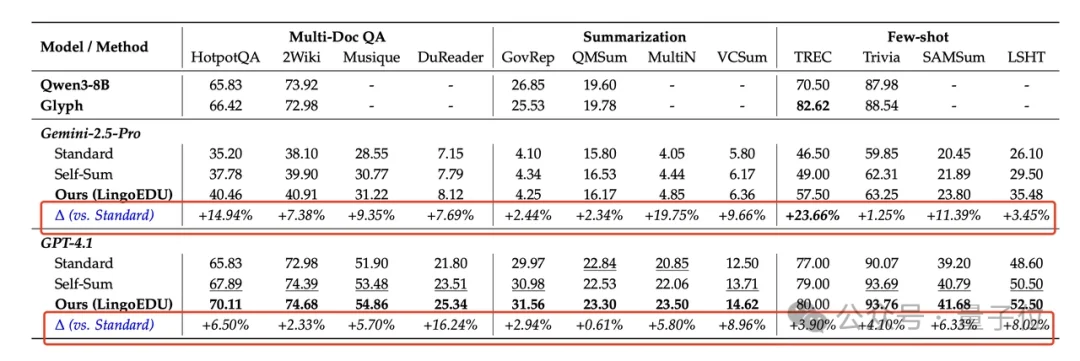
同时,团队也在LongBench(包括Multi-Doc QA、Summarization和Few-shot任务)上进行了对比实验,以Gemini-2.5-Pro和GPT-4.1为代表模型,验证LingoEDU的效果,实验结果显示LingoEDU能够提升模型在LongBench所有摘要总结、多文档问答等子任务的效果。
论文链接:
https://arxiv.org/pdf/2512.14244
Github开源链接:
https://github.com/DeepLangAI/LingoEDU
文章来自于“量子位”,作者 “LingoEDU团队”。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
