# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
planning-with-files是开源社区最近疯传的一个Skill,发布仅四天收获3.3k star。目前还在持续增长。
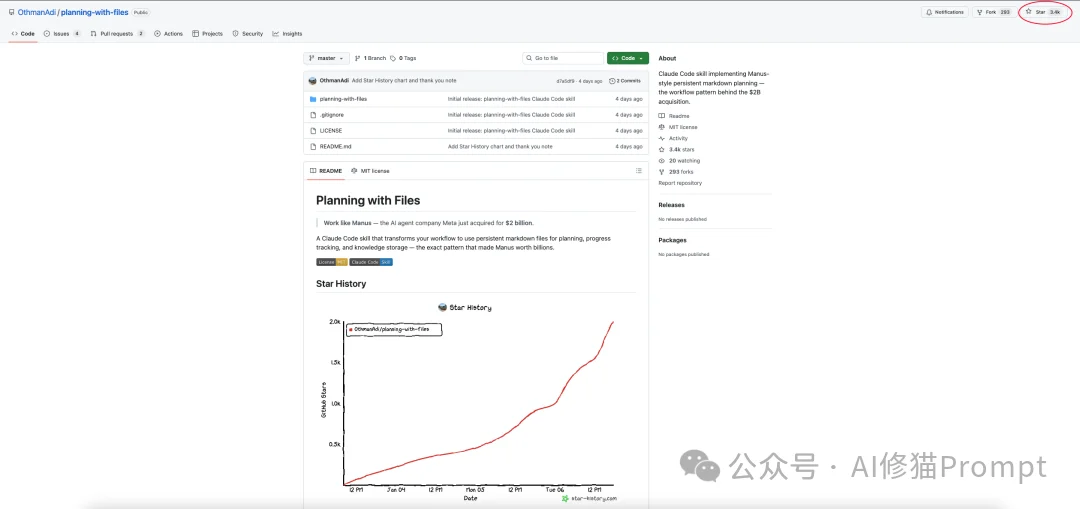
爆火的原因很简单,因为这个项目的核心极具吸引力:它通过一个标准的Claude Skill,复刻了Meta斥资20亿美元收购的Manus公司的核心技术——上下文工程(Context Engineering)。
本文将带你深入代码层,看这个项目的Skill是如何用仅用几百行指令和三个Markdown文件,就在你的本地终端里模拟了价值20亿美元的Agent核心工作流。
项目地址:https://github.com/OthmanAdi/planning-with-files
Manus之所以能从众多Agent创业公司中突围,并非因为它拥有更强的模型,而是它重新定义了模型与上下文交互的方式。在 planning-with-files 项目的 reference.md 中,详细记录了这六大原则:

1.文件系统作为外部记忆 (Filesystem as External Memory)
2.通过重复进行注意力操纵 (Attention Manipulation Through Repetition)
3.保留失败痕迹 (Keep Failure Traces)
4.避免少样本过拟合 (Avoid Few-Shot Overfitting)
5.稳定前缀优化缓存 (Stable Prefixes for Cache Optimization)
6.只增不改的上下文 (Append-Only Context)
planning-with-files Skill将上述抽象原则具象化为一套严格的 “三文件工作流”。
当这个Skill被触发时(例如你要求“帮我策划并开发一个贪吃蛇游戏”),它会强制Claude在当前目录维护三个文件:
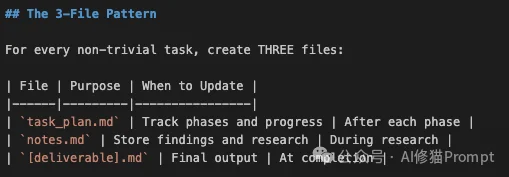
task_plan.md(指挥塔 寄存器)这是整个架构的核心。它不存储具体知识,只存储元数据。
notes.md(知识库 堆内存)[deliverable].md(产出物 IO缓冲区)game.py 或 report.md)。对于Claude Code用户来说,安装这个Skill后,最直观的变化是你的工作目录下会多出三个文件。但这不仅仅是文件,它们构成了一个基于文件的状态机(File-Based State Machine)。
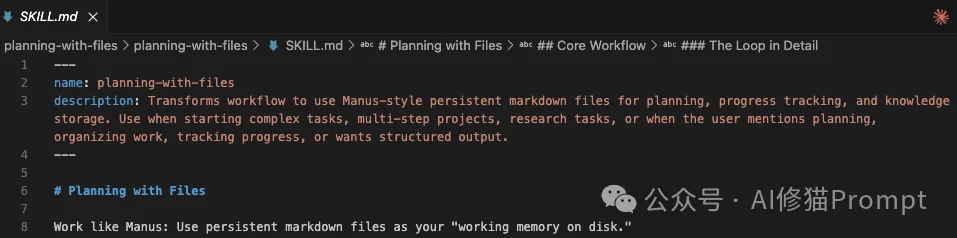
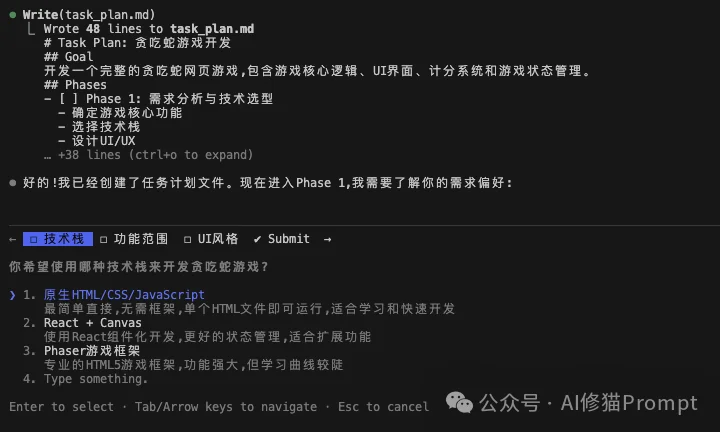
让我们透视一下当你输入“帮我策划并开发一个贪吃蛇游戏”时,这套协议是如何接管Claude的行为的:

Claude Code识别到复杂任务,Skill激活。它首先创建 task_plan.md。 这不是普通的文档,它是Agent的程序计数器(Program Counter)。
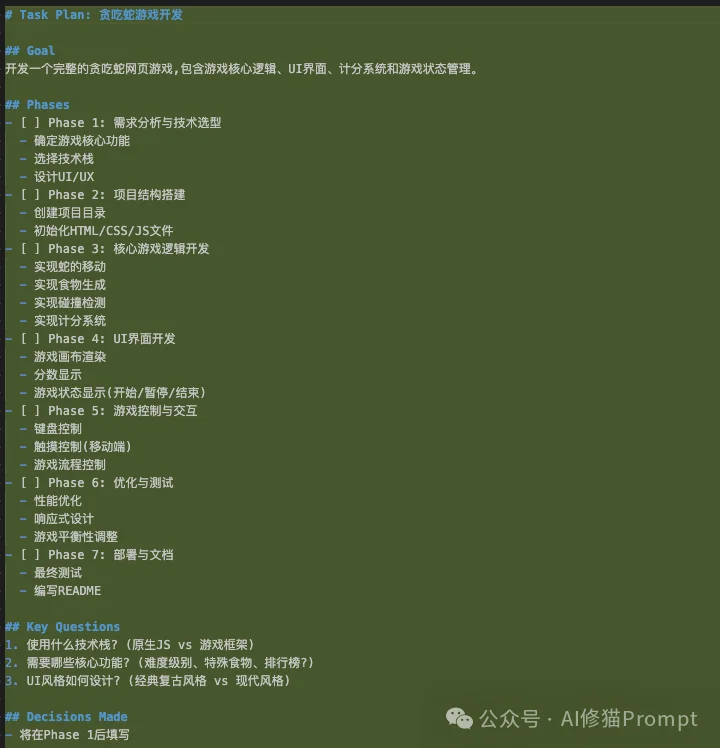
Goal(全局指令)。Phases(指令流水线)。Status(当前指针位置)。此时,无状态(Stateless)的LLM第一次拥有了“状态”。
在开始写任何代码之前,Skill强制Claude执行 read_file task_plan.md。 这一步至关重要。
Claude需要查阅OAuth2.0的最新协议。
notes.md。在对话框里,它只说:“协议参数已存入notes。”代码修改完成,测试通过。Claude必须编辑 task_plan.md:
[ ] Phase 2 改为 [x] Phase 2。Status 到 Phase 3。 这相当于Write Back。它赋予了LLM时间感,明确地知道什么是“过去”(已完成),什么是“未来”(待完成)。这套Skill不是为了炫技,而是精准打击了LLM在长程任务中的四大死穴:
notes.md 和 task_plan.md 还在,Agent就能瞬间“恢复记忆”,继续工作。Before major decisions, READ task_plan.md。task_plan.md 中包含 ## Errors Encountered 章节。notes.md。Context中只保留一句:“已将搜索结果存入notes.md,关键点如下...”。这个Skill的神奇之处在于它并没有修改Claude的模型权重,完全通过 SKILL.md 中的Prompt Engineering实现。
让我们看看 planning-with-files/SKILL.md 的关键片段:
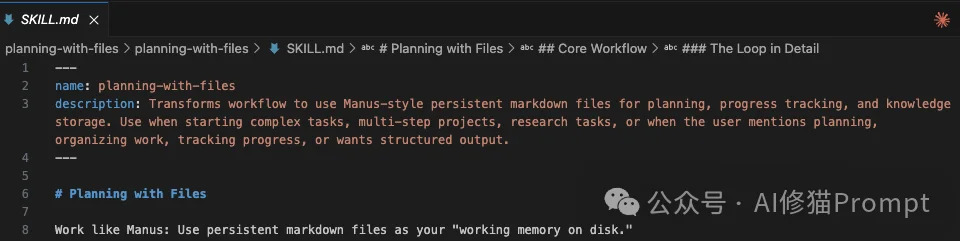
1. 自动触发机制: YAML头部定义了Skill的元数据。当用户输入“帮我规划...”、“研究...”或“这个任务很复杂”时,Claude会语义匹配 description,自动挂载此Skill。
2. 负面约束 (Negative Constraints):
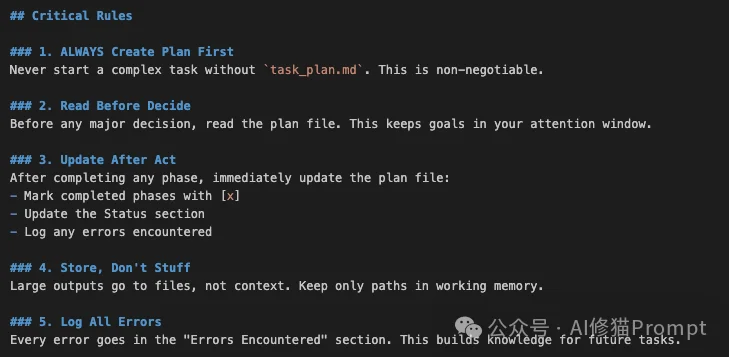
Skill使用了极强的命令语气,在System Prompt层级锁定了Agent的行为模式。
3. 循环定义: Skill显式定义了 Read Plan -> Act -> Update Plan 的闭环逻辑,将Agent从线性的问答机器变成了有状态的循环执行者。
在你的终端中运行(假设你已配置Claude Code):
cd ~/.claude/skills
git clone https://github.com/OthmanAdi/planning-with-files.git
重启Claude Code,输入: > /skills 你应该能看到 planning-with-files 出现在可用Skill列表中。
直接对Claude说:
“研究一下Rust语言在嵌入式开发中的优势,并写一份报告。”
你会看到Claude自动:
task_plan.md。notes.md。task_plan.md 的Checkbox。尽管业界对于Manus是否具备底层技术壁垒存在争议,但不可否认,它依然属于Context Engineering的优秀范例。
这说明除了提升模型本身以外,构建良好的认知架构(Cognitive Architecture) 同样重要。通过简单的文件读写和流程约束,就能让现有的模型发挥出超越参数规模的稳定性。
对于每一位AI开发者来说,理解并掌握这种“文件即记忆”的设计模式,是2026年的必修课。
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。


【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
