# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

AI 语音模型测试第三弹。
关于 AI 语音模型的测试,我们已经做过两期,两次覆盖了当时有些成绩(获得融资或者有市场声量)的模型。当时的结论是,虽然语音技术在持续进步,但是单纯靠模型本身的能力,离实际落地还有一段距离。
半年之后,语音赛道无论从融资上,还是从技术上,又都更进一步。
融资层面:
· 赛道头部的 ElevenLabs 继 1 月份融资 2.5 亿美元,估值突破 30 亿美元后,9月份,又推出 1 亿美元员工股权回购计划,此次回购的估值高达 66 亿美元,相比年初翻倍。
· 10月23日,Sesame 完成 2.5 亿美元的 B 轮融资。
· 12月初,欧洲创企 Gradium,刚刚完成 7000 万美元种子轮融资,打破了欧洲 AI 公司种子轮融资额的纪录。
技术层面,近一段时间推出的语音模型主要升级在于更精细的情绪控制、更自然的节奏与语调、更复杂的内容处理能力等等。而基于这些能力的升级,我们也看到了诸如 ListenHub 等应用端音频创企开始爆发,开发者们基于 TTS 的能力提升,正在向创作者工具、个人学习提效等场景发起探索。
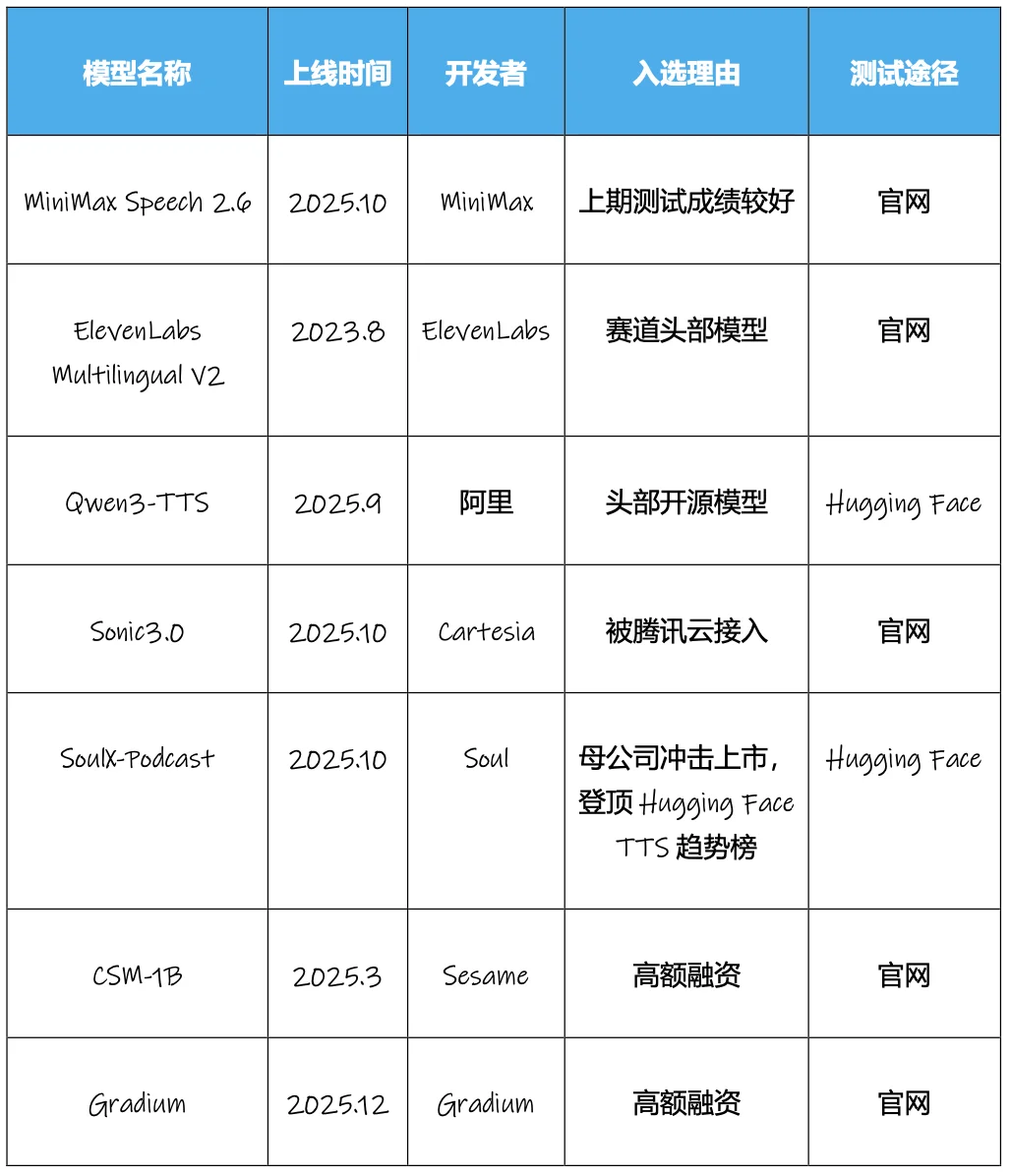
所以本次,我们筛选出了最新推出、或者最近有过融资的语音生成模型,进行了新一轮的测试。本次测试将更关注实际场景、与稍长文本场景的表现,而非单纯通过“模仿”的方式测试情感输出,而且,针对 ElevenLabs 等海外模型对中文适配不佳的问题,我们也设计了英文测试。
测试方法:
本次测试将设置 3 个场景,科技播客(1 分钟)、情绪独白(20 秒)、有声书旁白(1 分钟),分别对音频解说、有声书等 TTS 的主流应用场景,而英文测试则进行情绪独白和科技播客两个测试。
所有模型都按测试文本生成音频后,笔者会邀请 5 位评委,在每个场景中按 5 个评价维度进行评分,评委如果认为模型表现符合评价维度要求则打勾,每次打勾该模型得 4分,五位评委打分后,综合计算该模型总得分,满分为 100 分,不设及格分数(由于 SoulX 支持双人对话,所以在科技播客场景中 SoulX 模型设 20 分加分,单独列出,不加在总分内)。
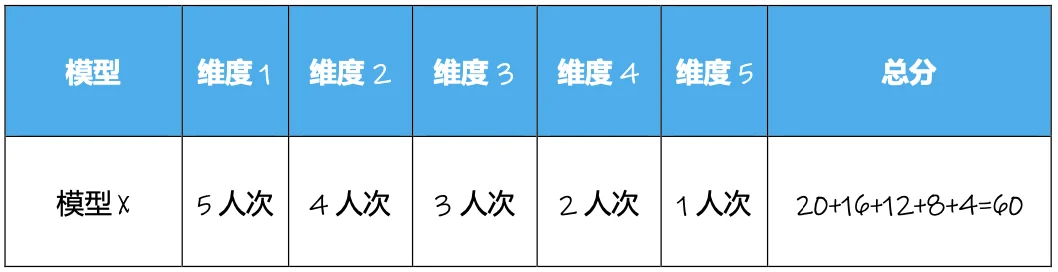
打分规则举例
注:本次测试音频在各模型官网或者 Hugging Face 等平台生成,可调节的参数或情绪标签较少,可能无法达到实际应用时的输出水平,但在录制测试音频时已尽量将模型的输出效果调节到最好,且由于本次评分为人类主观评分,难免出现偏颇,所以本次评分仅针对测试音频,结果仅供参考。
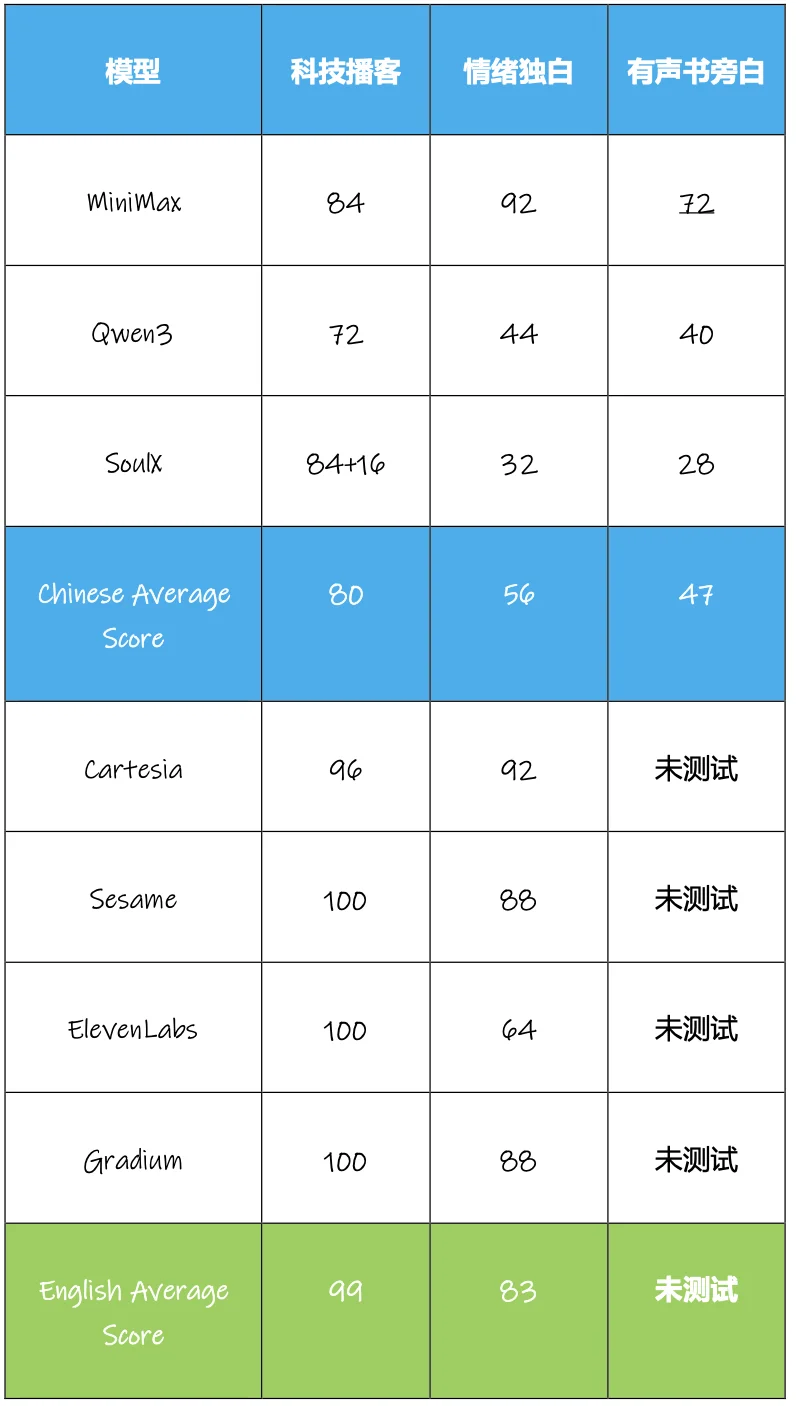
从中文的测试结果看,MiniMax 在 3 个场景中都取得了最高分,且基本断崖领先其他模型。
注 1:在测试中,由于 ElevenLabs 和 Cartesia 对中文的支持不佳,中文测试中的分数显著低于中国厂商模型,例如 ElevenLabs 在有声书旁白测试中仅得到 16 分,所以我们就不放入表格,以免影响整体参考,后续另作英文测试。
注 2:MiniMax 的官网可调节语速、音调等参数,而 SoulX 和 Qwen3 在 Hugging Face 进行测试,则无法调节参数。测试途径缺少调节选项,也可能部分影响测试效果,读者可在“无法调节”范围内,进行两两对比。
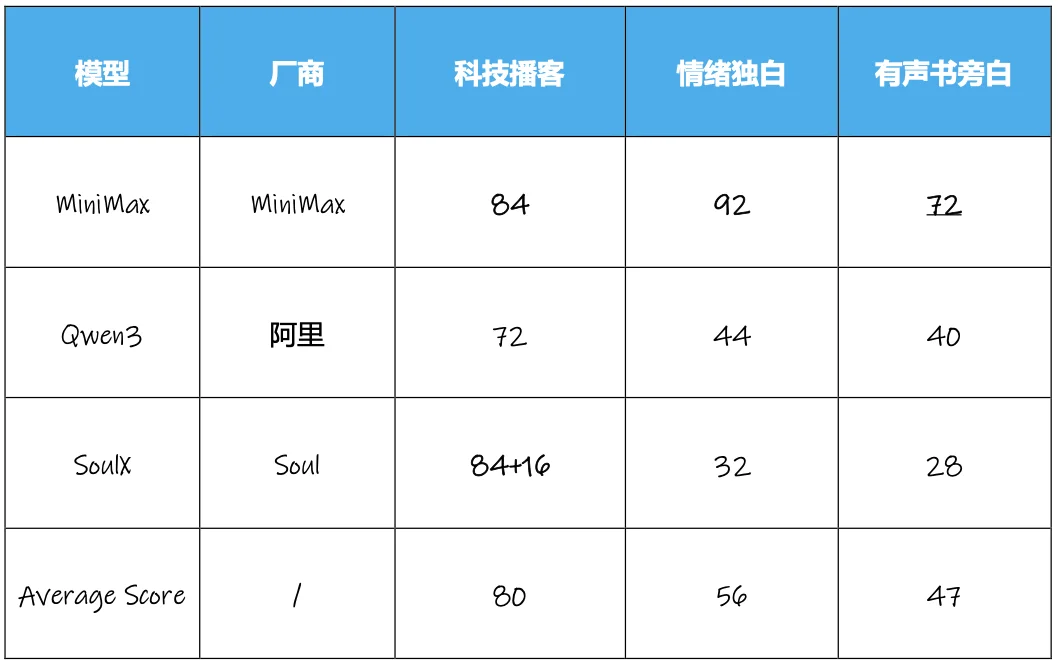
而横向对比三个场景,各语音模型在科技播客场景的表现最好,平均得分为 80,高于情绪独白场景的 56 分,而表现最差的则是兼有“长文本”与“情绪传达”的有声书旁白场景,平均得分仅 47 分,也就是说,短时间的正确情绪表达已经较上次有所进步,但要长时间(1 分钟)都有不错的表现,还是不太行。
详细测试过程与评分情况如下:
本测试主要对应社媒上知识性音视频解说场景,主要考验模型在强知识、多术语场景下的表现。
本测试的 5 个评价维度分别为:真人感强;语言清晰、中英文混合处理自然;术语正确;停顿、重音自然;全程节奏稳定、听感顺滑;加分项(仅 SoulX):双人对话衔接自然、无抢话。
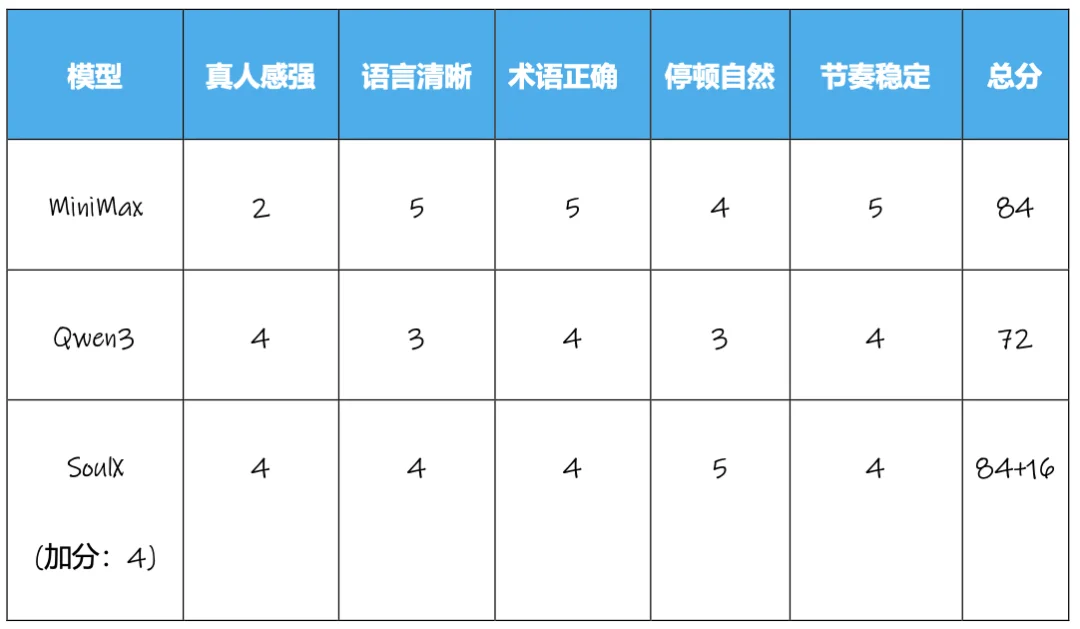
在相对较为基础的科技播客场景,所有模型的表现都不错,平均分达到了 80 分。从单个模型的表现看,MiniMax、SoulX 两款模型都取得了 84 分的高分,而且 SoulX 还因多人对话效果取得了 16 分的加分,Soul 在推出 SoulX-Podcast 时曾明确表示,该模型针对多轮多人对话场景做了针对性的优化,所以在播客场景中,SoulX 的表现较好。

相对于比较基础,只要求内容与听感正确的 AI 播客场景,更重“情绪传达”的有声书场景的难度会高一些。而测试 2 则对应有声书场景中的“内心 OS 或人物自白”部分,这些内容往往体现角色情绪和状态,通常包含较为强烈的情绪。本次测试将采用 20 秒左右的短文本,加上较强烈的悲伤情绪,考验模型的“情绪传达”能力。
本场景的五个评价维度为:情绪清晰(悲伤)、情绪传达自然不夸张、停顿自然、无语调/读音等明显影响听感的瑕疵、情绪前后稳定。
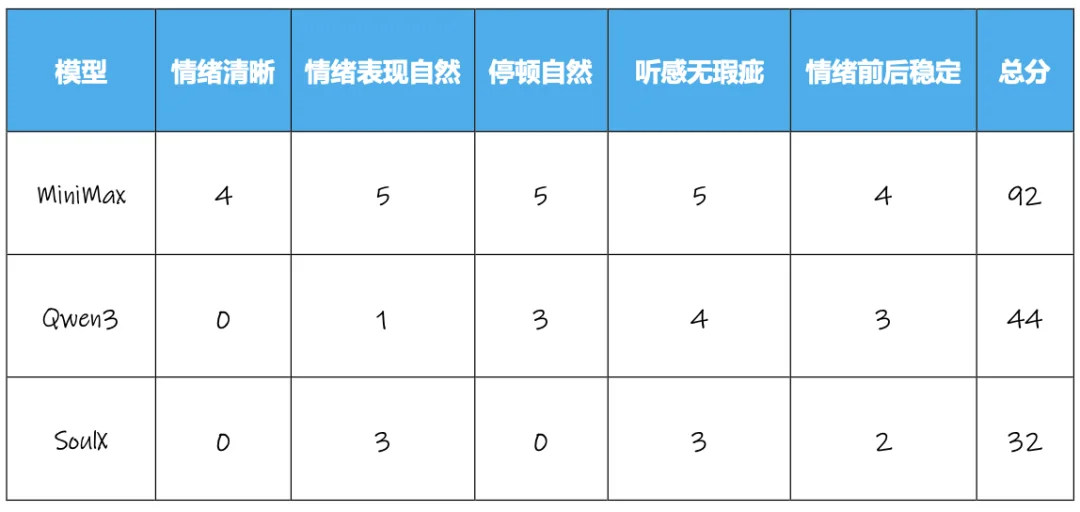
从体现情绪传达的两个维度看来看,除了 MiniMax 做的较好外,其他模型无一例外都出现了情绪体现不足的问题,对绝大多数中文模型来说,悲伤、愤怒等情绪的传达,虽有所进步,但仍存在问题,但其中 MiniMax 的表现仍比较好,得分达到 92 分。

有声书场景中,出现频率更高的内容是“描述性旁白”,但在很多有声书中,旁白也会包含一定情绪,以符合内容基调。所以,第三项测试是时长 1 分钟左右,带一些悲伤情绪的描述性旁白,以测试模型能否长时间、正确传达情绪。
本场景的 5 个评价维度为:是否符合有声书场景、情绪传达正确(平静、略悲伤)、断句/停顿自然、无语调/读音等明显影响听感的瑕疵、情绪有叙事层次。
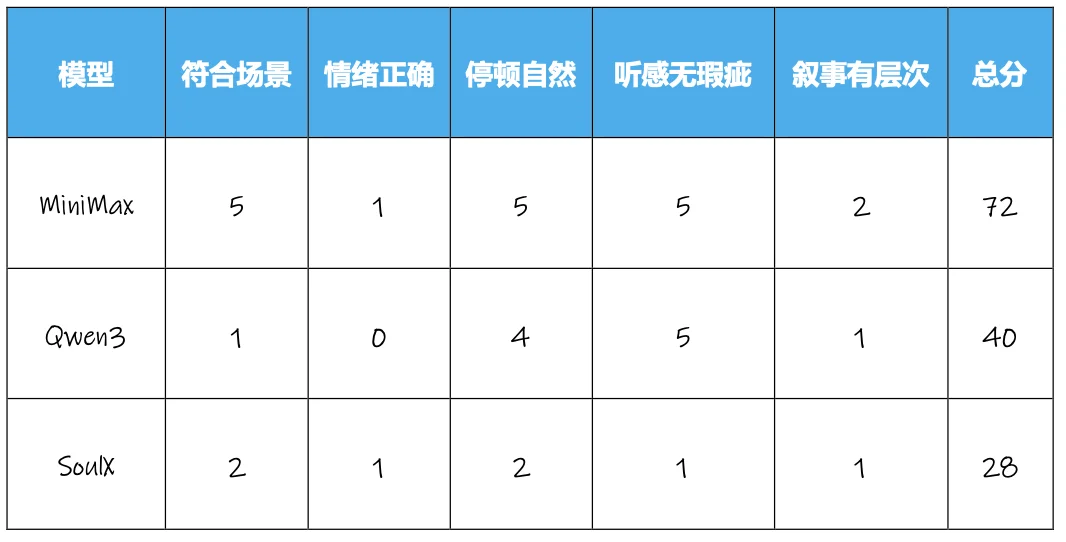
从具体的打分情况来看,在停顿与听感无瑕疵两个较为基础的评价维度上,各模型的表现相对较好,说明各模型在基础听感上已经合格,但是在“情绪正确”、“叙事层次”这两维度上,包括 MiniMax 在内的所有产品都得分较低。由于测试文本偏描述性,情感并不强烈,导致大多数模型的输出都比较“平淡”,没有体现出悲伤情绪。

由于 Sesame、Gradium 不支持中文,且参与中文测试 ElevenLabs、Cartesia 因适配性问题表现不佳,所以我们将这 4 款模型单拿出来进行英文场景的测试,由于篇幅问题,英文测试只进行情绪独白和科技播客两个场景的测试。
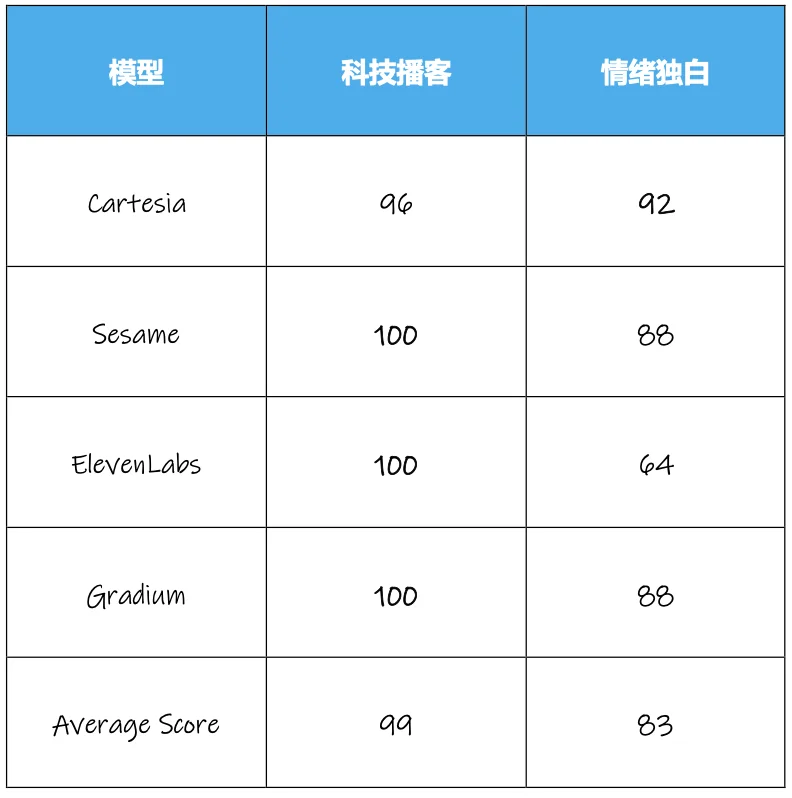
科技播客场景中,4 款模型中有 3 款都取得了满分,平均分达到了 99 分,主观听感上可以达到真人水平。而情绪独白场景,4 款模型的平均分也达到了 88,仅有 ElevenLabs 的得分在 80 以下,整体表现也强于中文场景的几个模型。
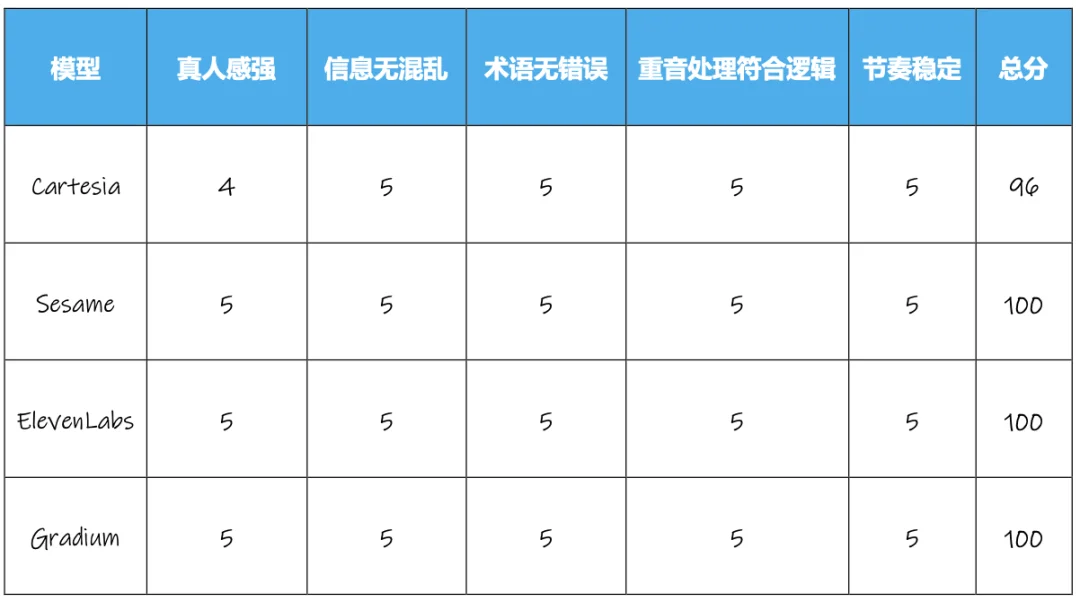
英文播客场景测试结果
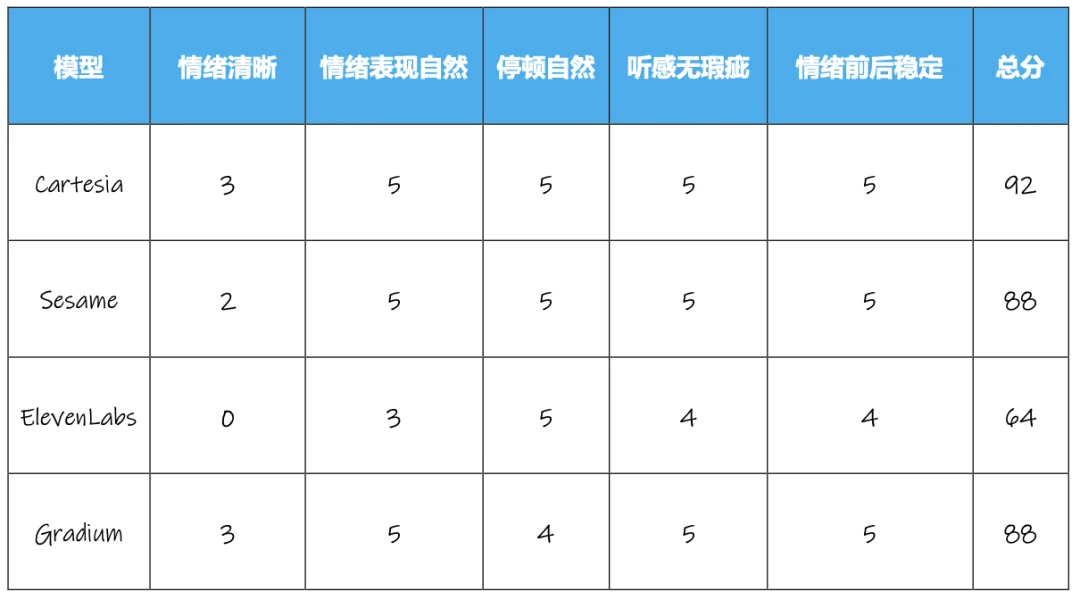
英文情绪独白场景测试结果

英文科技播客

英文情绪独白
最后,我们将所有结果汇总,得到一些观察如下:
1、科技博客测试的难度相对较低,更考验模型正确输出内容的能力。总体来看,中英文模型都表现较好,但是从平均分来看,英文模型达到 99,显著高于中文模型的 80 分。
2、情绪独白场景中,英文测试的均分也显著高于中文,且差距较大,这其中有模型层面的差距,也存在一些客观原因。中英文差别最大的就是“声调”这个点,在中文中,一个字拥有 4 个声调,甚至粤语是“九声六调”,且声调的不同会直接影响语义,而大模型不仅要准确输出声调,保证语义正确,还要通过语气、变调、节奏等体现出韵律与情感,模拟真人语音。而英文则不存在这个问题,大模型仅需掌握自然的重音、停顿、节奏,相对要简单很多。
3、英文测试中,Sesame、Gradium 等较新的模型效果,在情绪传达方面,得分超过了我们认知中的赛道头部 ElevenvLabs。能拿下高额融资,测试下来确实具有不俗实力。
三期音频测试做下来,从最开始的“短文本、模仿秀”、到这一期面向有声书、语音解说等真实场景的测试。测试难度的升级,不仅是语音模型能力的提升,也反映了 TTS 的应用场景也逐渐清晰。
语音输出的落地有三条主线,一是规模化生产内容(有声书、播客、视频解说等)、二是陪伴等对用户情绪有针对性回应的交互,三是更强调实时性的语音交互(AI Agent、智能客服)。而基于这三大落地场景,目前语音模型升级的焦点在长文本能力、高信息密度的稳定性、多轮对话、多语言适配、低延迟实时输出等基础能力;另外一条主线,则是与情感相关的拟真度、人格一致性、情绪饱和度等。有点像理性与感性 2 条演进路线。
而综合测试和我们的观察,在规模化生产内容方面,当前的模型能力已经足够,比如在 AI 语音应用层产品 ListenHub 中,语音模型能力加上工程优化后,其输出“播客/语音解说”等内容,已基本与真人无异。但情感方面仍是语音模型的短板,要想让语音模型正确理解上下文与情感环境,并能长时间、输出正确情绪,仍需复杂的工程优化。
虽然 AI 语音已经取得了长足进步,但根据 ListenHub 创始人橘子的说法“语音还没有到‘ChatGPT 时刻’”,技术层面仍处于快速发展的阶段,未来我们仍将持续推出选题,关注 AI 语音的技术提升与落地应用场景。
文章来自于“白鲸出海”,作者 “张凯然”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
