# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

最近 AI 编程界最火的事情,就是怎么把各种 coding 模型卷到极致了。
有时候程序员狠起来,真的不怕 AI 抢了自己的饭碗。
一开始是 Claude Code 官方发布了 ralph loop 插件,可以让 cc 想停下来的时候自己检查下是否完成了任务,没完成就继续。cc 之父 Boris 就用这个,帮助自己一个月提交了 259 个 PR,添加了 40000 行代码,在 X 上狠狠装了一把。
紧接着 Cursor CEO 也不甘示弱啊,爆出他们用 GPT-5.2 让 Cursor 不吃不喝干了 1 个礼拜(真·资本家啊),写了 300 万行代码,从 0 到 1 卷出了一个浏览器,还自带一个自定义的 JS 虚拟机。
有朋友就问,你不是经常测试这些玩意儿么,好像 token 在你那儿都不是事儿。
有啥办法也让我的 Claude Code / Antigravtiy / Opencode 干一个礼拜活吗?
好在我这几天认真研究了 ralph loop 插件,以及 Amp 团队分享的 ralph agent 教程(X 上 180 万阅读啊)。
🏖️理论上,用 ralph loop 和 Amp 那个,都能做到类似效果。不止一个礼拜,一个月也能,只要钱包够深。
但前者要在插件基础上搞一堆配置,有点麻烦。
后者又要订阅个 Amp,手握 Cursor、Antigravity、cc 的我想想还是算了。
不过好在 Amp 那个 ralph 在 GitHub 开源了,有 4k star。
它最基本的原理,就是下面这张图。通过模拟敏捷开发的方式,把大需求拆解为 user story,然后一个个测试验收,持续集成,直到把大需求全干完。全程就好像配备了产品经理、程序员、测试人员,以及一个小的项目管理系统。
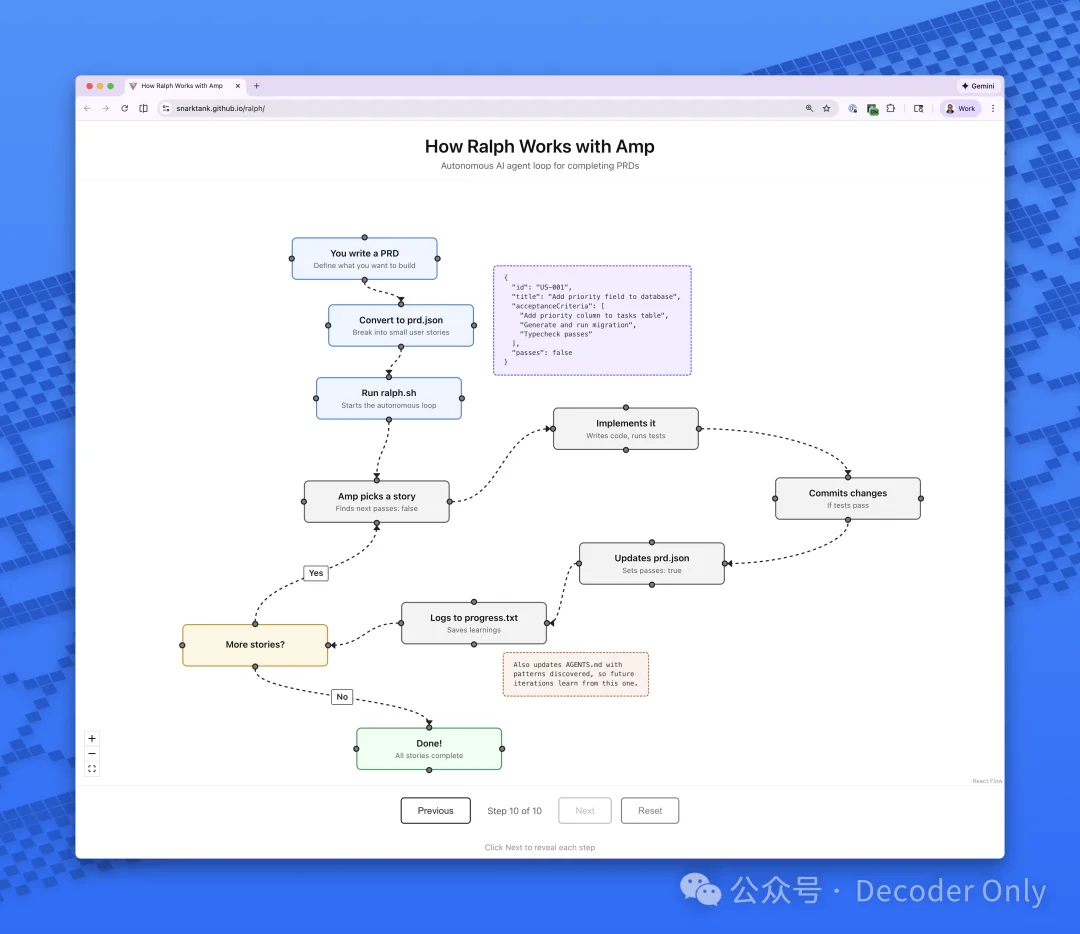
原理都搞清楚了,抄还不会嘛,毕竟我们还有 AI,这玩意儿它比我在行。
说干就干,以迁移到 CC 为例,下面是具体的步骤。
我们先把 amp 开源的那个项目克隆下来。
bash
git clone https://github.com/snarktank/ralph.git
看了下,它有点深度为 amp 定制了,不过有 Vibe coding,这个难不倒我们。
我们让 Opus 4.5 搞个迁移计划,让它也支持 cc。这一步我是在 Cursor 里跑的,先通过计划模式和它讨论,最终确认了完整的迁移计划,然后一把搞定了。
看了下改动点,重点是下面 3 个地方
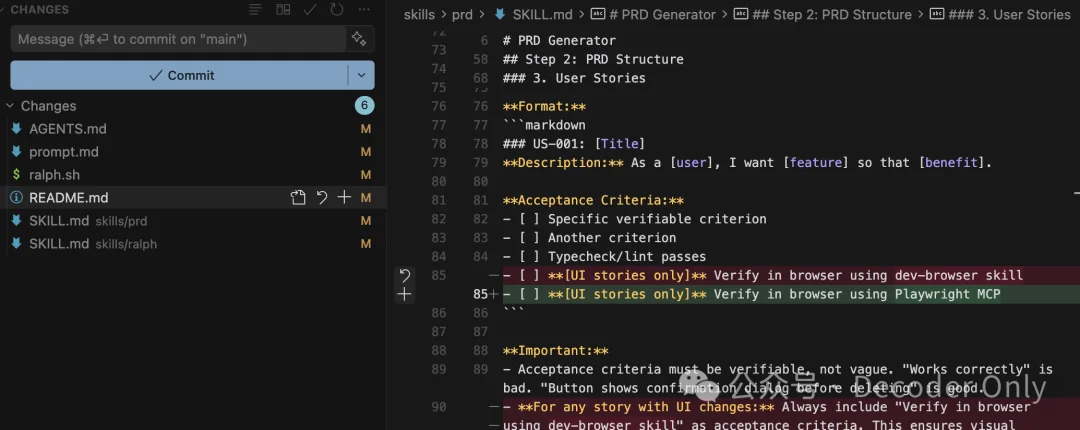
底层原理都是拉起一个 CLI,ralph 拿着鞭子催他干活。
所以,如果你想要迁移到 Codex、Opencode 等支持 CLI 的工具,方法是完全相同的。
和之前我们做的官方 ralph loop 的那个例子最大的不同,Amp 这个 ralph agent 自带了两个需求梳理和拆解的 skill。这样即使我们需求一开始没想特别细,那个 prd skill 也可以强迫我们跟它把需求讨论清楚,并拆解为 user story(用户故事)。
如果你了解敏捷开发,肯定秒懂;
没接触过也没关系,可以把它理解为一个个小的需求点,而且可以独立验收上线的那种就行。
回顾上次的项目,我觉得那个需求,一开始确实也没梳理特别细,后面让 ralph loop 插件执行 make it better 就完全让它放飞了,结果做了一堆屎上雕花的功能。
言归正传,我们把改造后适配的脚本,都复制到项目目录。
接下来这步很重要,我们让 Claude Code 用 prd skill 来帮我们创建需求。
这次需求没变,还是做一个可以把飞书文档快速调得更好看的微信公众号排版工具。
Plain Text
加载 prd skill,帮我创建一个 PRD,具体要做的是一个公众号排版工具,可以快速粘贴飞书文档的内容,并把它的各种格式,直接映射到模板里,非常现代、好看
可以看到,它开始拆解需求,和我对话,要求我回答问题。
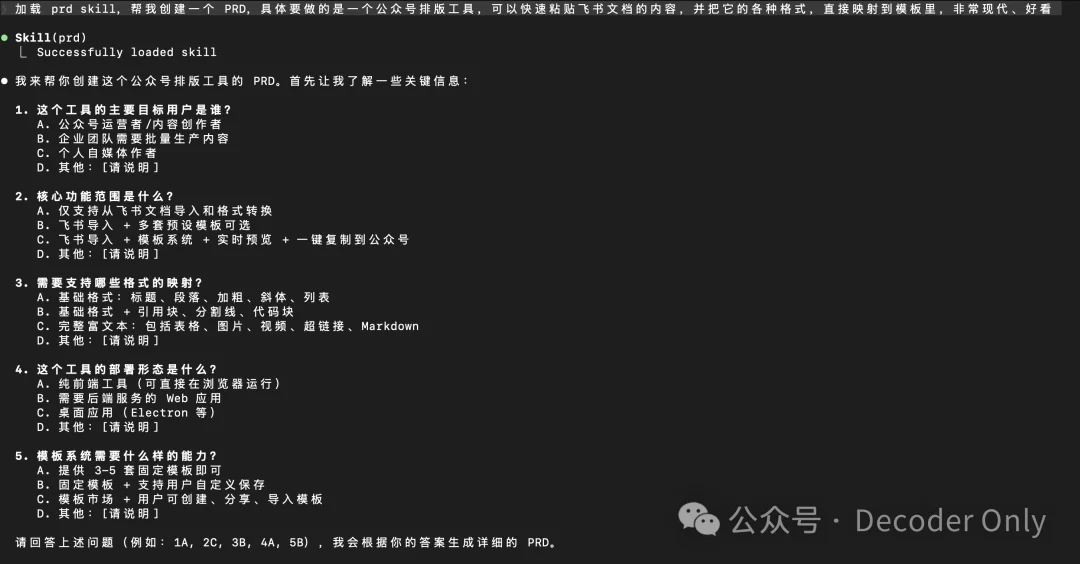
回答后,它开始创建 PRD
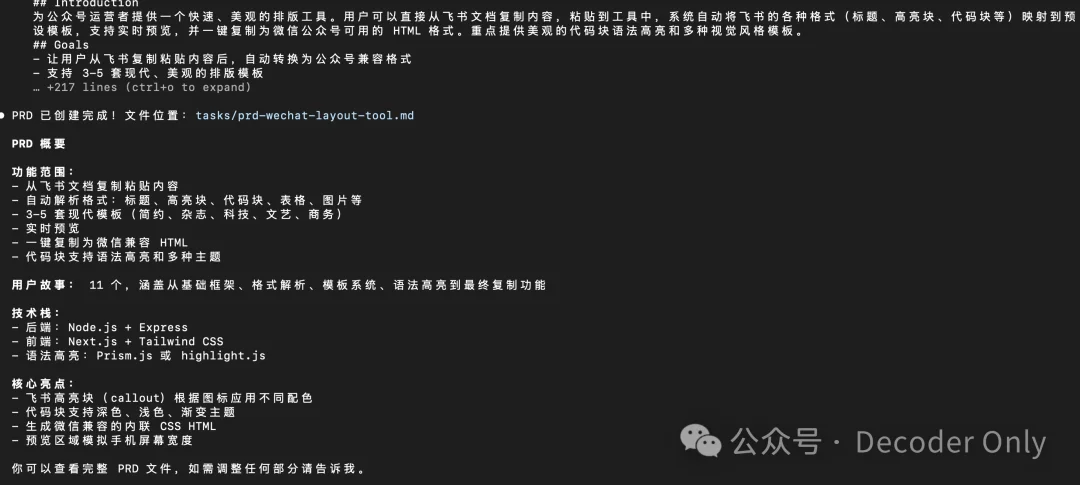
看了下写的 PRD,我发现 Amp 他们开源的这个 skill 还是做得不够极致,至少用在我这个例子里,有些需求细节还是写得不够清楚。
咋办呢。。。
😎要不让 Claude Code 扮演需求评审时的反派角色,专门给产品经理找茬吧。
于是我给了它这么一个指令,要求它再次和我评审讨论每一个需求点。
Plain Text
找一下那个 prd skill,然后我们讨论下 prd-wechat-layout-tool.md 还有哪些细节要补充.
我发现目前的需求描述和 acceptance criteria 还是太粗糙.
我希望和你 1. 先做整体的讨论 2. 每个需求我们要一个个 review, 你也要帮我提出批判性的意见,一个个 review 修改确认通过
果然,找出了一系列问题,主动写需求不擅长,找问题还是在行的嘛

这样,每个需求,它都举出了问题,并给出了建议。

看到它想得比我还极致,这下放心多了。
于是,我开始一个个和它讨论、评审、细化。。。
好家伙,这个过程,产品界面在我脑海里,好像开始越来越清晰。
但过程确实磨人,尤其是少了点之前 Vibe Coding 的那种所说即所得的爽感。
难道这就是所谓的延迟满足感吗。。。
就这样,过去了 3 小时 🤣🤣🤣,我们终于有了一版人类与 AI 舌战群儒 PK 后的 PRD。
打开这个 PRD 看下,好家伙,足足写了 916 多行,这些细节都是前面 3 个小时一个个打磨出来的。
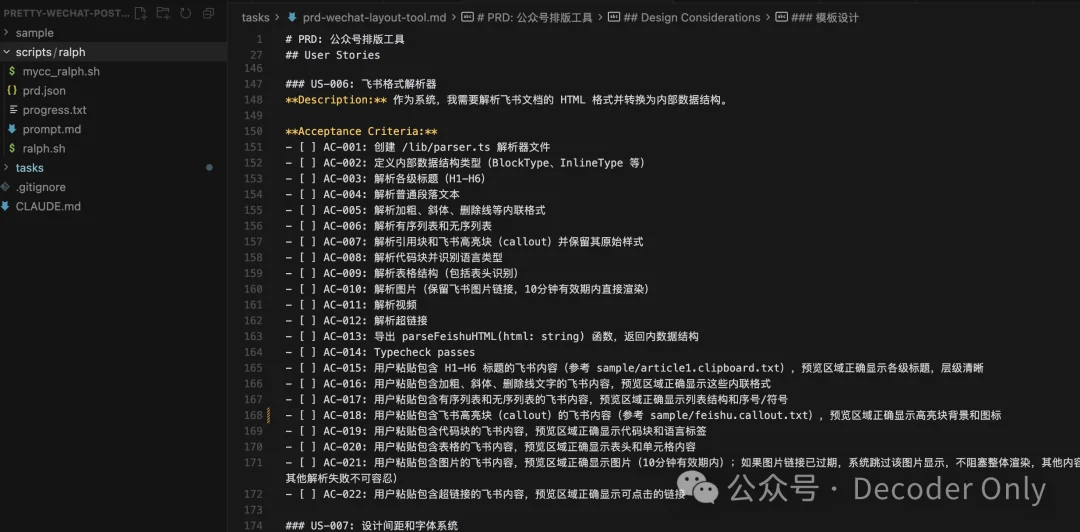
另外,总共还拆成了 17 个 user story,每个都有清晰的验收标准。
到了这里,我感觉已经被 AI 压榨干了,得开始反向压榨才行了。
这里我们就要引入 Amp 它的第二个 skill —— ralph skill 了。
名字嘛,起得不那么好,还不如叫 breakdown 或 userstory skill。
⚡这个 skill 的核心逻辑,有点像雇佣了一个产品经理,把 user story 都拆解好,然后录入到项目管理系统里。接下来研发就可以认领系统里的每个需求点,一个个来做了。
这个 prompt 我们直接抄一下 ralph 示例里的就行。
Plain Text
请参考 ralph skill,把 @tasks/prd-wechat-layout-tool.md 转换为 /scripts/ralph 目录下的 prd.json,注意要保留原始 PRD 我们讨论的所有细节,并且保留中文的描述,不可以遗漏任何一条内容.
执行完毕,我们看下。
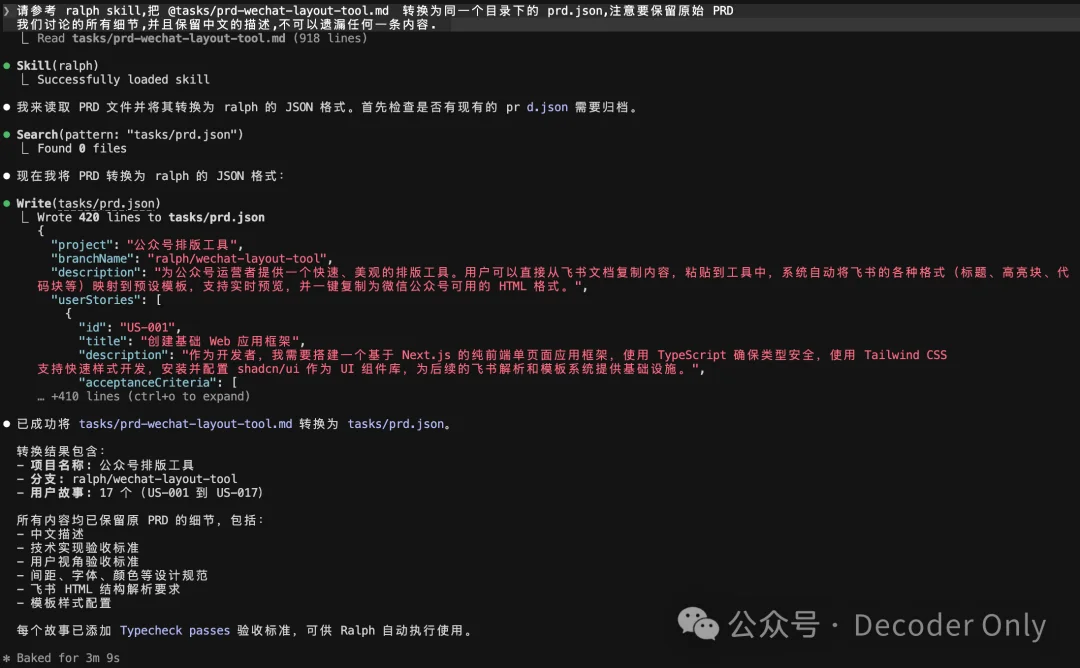
嗯,都转成 prd.json 了,内容大差不差,核心是里面有各个需求的状态,相当于一个简易的 Jira。
🤑这一步开始会比较费 token 了,如果你主要想体验整个流程,建议在🌋买个新的 coding plan,首月促销好像是 8.9 元吧,支持 GLM、Kimi 等多种模型,量大管饱,够你进行各种暴力测试了。
比如我这里就用了里面的 GLM 模型来跑。
如果你更在乎质量,个人还是推荐海外那几个 SOTA。
好的,切换到脚本所在目录,开始执行
bash
cd scripts/ralph./ralph.sh
不过一开始运行,我就发现一个问题,不知道是不是脚本没迁移好,Claude Code 的输出没有实时同步出来,即使我让它输出到一个文件里,也不行,🤦。。。
研究了下,是 claude -p 这个指令不支持流式输出,算了,先忍一下,看看能不能出活先。。。
看了下左边的目录,一直在新增文件,有动态变化,package.json 等都出来了,看来还是有在悄咪咪干活的。

我们打开 progress.txt 进度文件看下,没想到挺快的,已经干到第 2 个 story 了
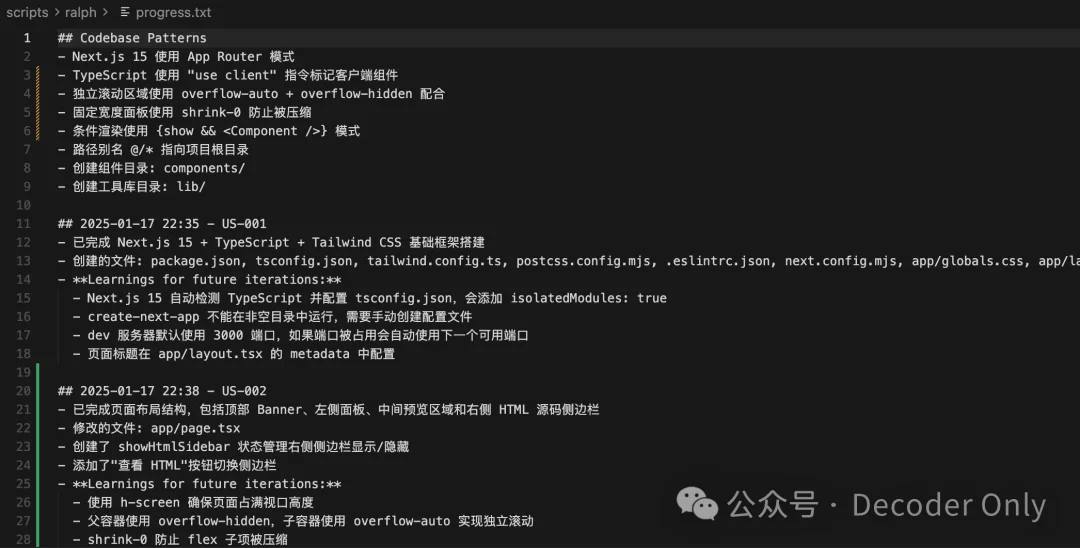
就这样过了 15 分钟。。。
不过这么干等着,看不到实时进度,我也开始有点烦躁了,万一挂了咋办呢。。。
于是我决定,一边让它继续干活,一边寻找解法。
我又开了一个 cc,开始和它讨论怎么把那个 ralph.sh 迭代为可以查看到实时输出。
经过九九八十一次失败的尝试后,最终找到一个方法 —— 使用 stream-json 参数,并且实时解析,再把我们最关心的进度信息展示出来。
更新完脚本,重新运行看看,这时候前面的脚本已经做完第 5 个 story 了,所以这里自动从第 6 个开始了。
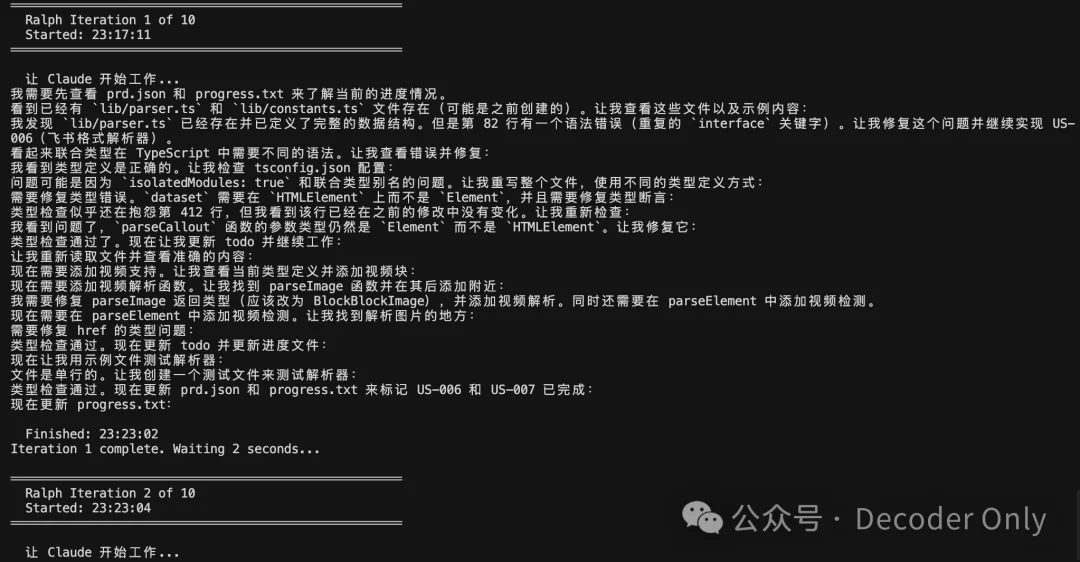
做完 2 个 story,可能 Claude 老毛病犯了开始磨洋工,刚好我们的 ralph 监工来了,自动开始第二轮。
🥳 太棒了,说明 ralph 是正常运转的。

不过我仔细看了下输出的内容,发现一个问题,它都没给涉及 UI 功能的 story 跑 Playwright 自动化测试!
即使我们在 prompt.md 里约定了,但还是没听话。
这就有点蛋疼了,于是我悄咪咪改了最后一个 story,加上了一条必须用 Playwright MCP 测试所有功能的验收标准。
看来后面得给每个 story 也都带上才行。
开始了,也看到它自动截图了,不错不错
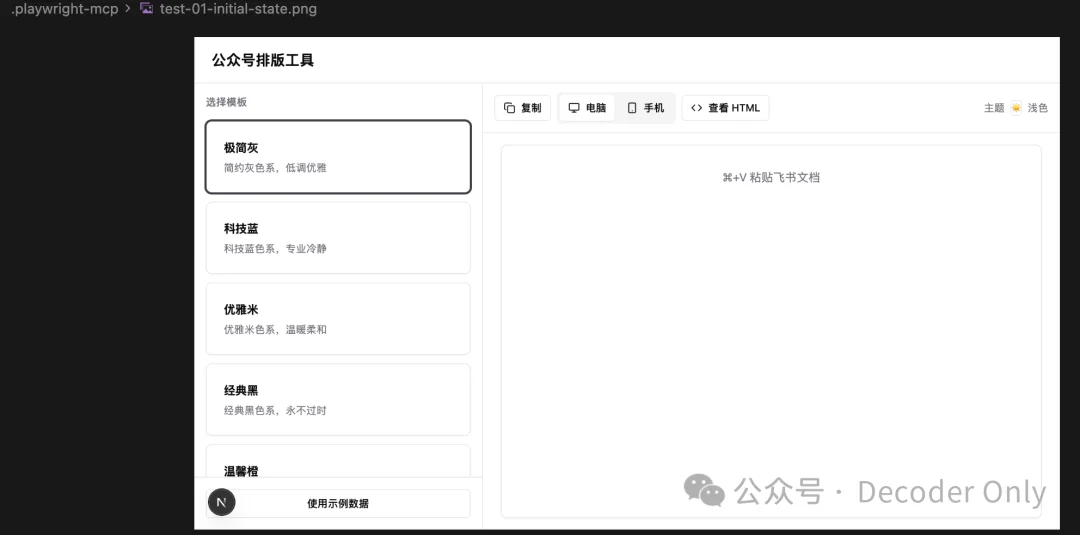
跑了十来分钟,终于说测完了

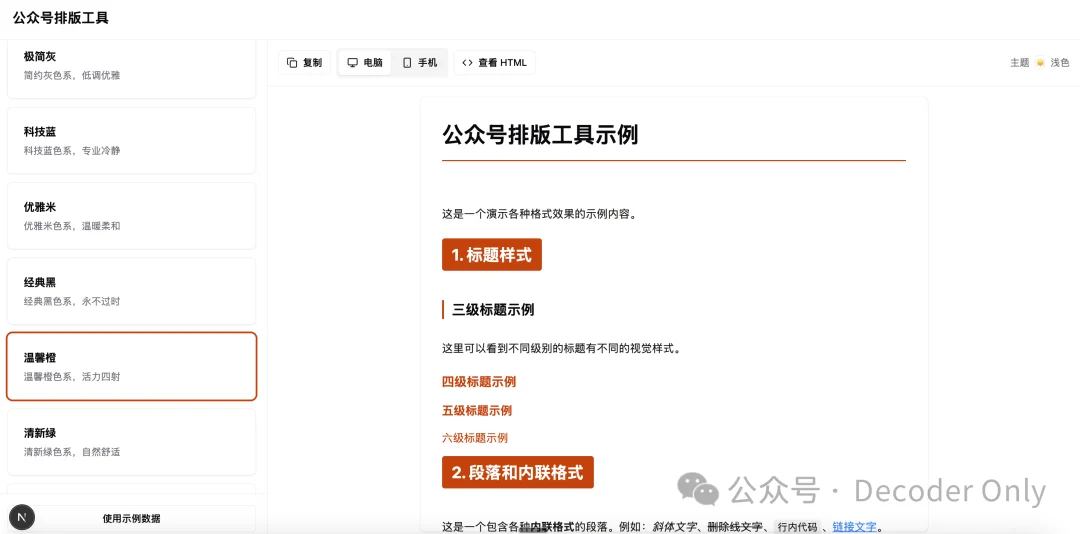
我们自己打开试试看,还不错,有模有样了
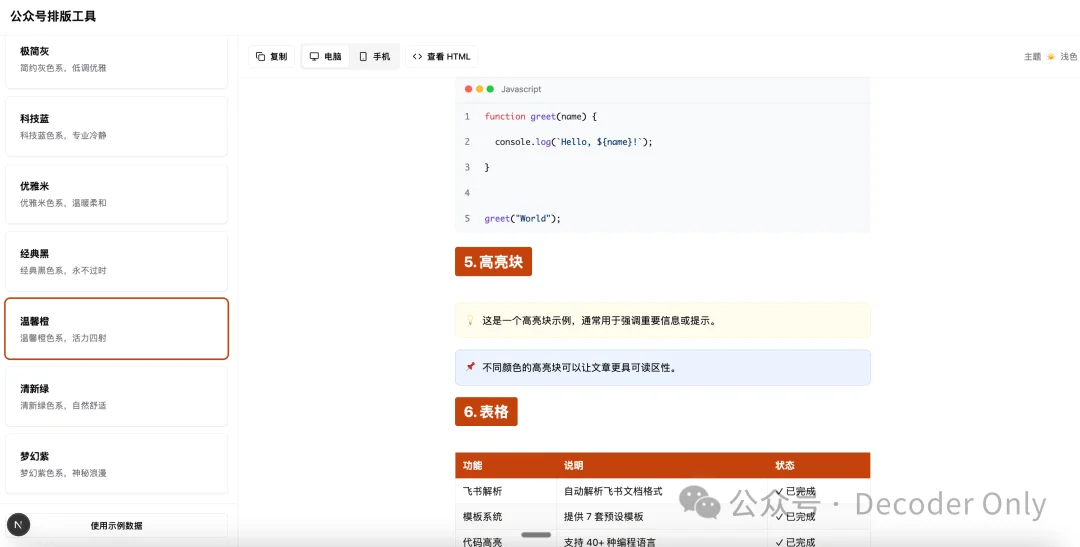
代码块、高亮块、表格也都整出来了
我们粘贴个内容到微信看看,嗯,也不错

再试一下粘贴一个飞书文章,也都正常了。

一些感想
跑完这个 ralph agent 的全过程,我得出了一个结论:
😆如果前期需求拆得足够多、足够细,要想让 cc 不间断地跑一个礼拜,不是不可能。
但这里,有个很大的问题或假设,需求一开始就想得非常清楚了,并且有人不愿其烦地把它拆解好、写好、定义好测试验收标准。
这对于弱前端交互、重后端逻辑的产品来说,或许会更适合一些。
但对于重前端交互的场景,有极其多的细节,是在一手体验测试中发现、迭代、解决、优化的。
即使有 Playwright 帮我们截图分析,它也只能发现一些明显的问题,至少在有更强的流式视频模型出来之前,这一步目前还是非常依赖人的一手体验和反馈的。
💡所以,一句话结论,不要想着有这个东西,就能帮你真的节约大量的时间。需求细节的定义,永远是最重要,也最花时间的。
而 Vibe Coding 最大的乐趣,在于 vibe 本身,在于你亲自动手,不断和 AI 互动,把产品一步步打磨出来的那个过程。
这个过程,除了解决具体的技术问题,更多是在帮你一起把需求细节定义清楚 —— 一边做、一边定义。
通过与你的早期产品进行紧密互动,在互动中,你会非常自然地想清楚,什么样的交互体验是最好的,什么样的逻辑是更合理的。而这些细节,可能不需要都文档化写成一个个的 story 或大部头的 PRD,代码理应就是你的 PRD。
所谓的 spec mode,看似提高了效率, 有可能只是过去时代分工的产物。
接下来,我可能不会再用这种方式,写 3 小时需求,再苛求他一夜实现。
不过我可能还是会继续用 ralph 来帮我做一些确定性高、重复性高的工作,比如自动跑测试。
好的,这次的 ralph agent 体验分享,就到这儿。
感谢你读到最后,如果觉得有所启发,也帮忙点一波关注点赞分享~
如果你用 ralph 有什么新玩法,也欢迎评论交流
文章来自于“Decoder Only”,作者 “湾仔码农”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
