# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
DeepSeek开源DeepSeek-OCR2,引入了全新的DeepEncoder V2视觉编码器。该架构打破了传统模型按固定顺序(从左上到右下)扫描图像的限制,转而模仿人类视觉的「因果流(Causal Flow)」逻辑。
DeepSeek又双叒叕更新了!
这次是DeepSeek-OCR模型的重磅升级:DeepSeek-OCR2。

还记得上一代DeepSeek-OCR吗?那个用视觉方式压缩一切的模型。
这一次,DeepSeek更进一步,对视觉编码器下手了,提出了一种全新的DeepEncoder V2架构,实现了视觉编码从「固定扫描」向「语义推理」的范式转变!
DeepSeek-OCR2不仅能像人类一样按逻辑顺序阅读复杂文档,还在多项基准测试中刷新了SOTA。
当然,按照DeepSeek的惯例,Paper、Code、Model全开源!
项目地址:
https://github.com/deepseek-ai/DeepSeek-OCR-2
模型下载:
https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
论文地址:
https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
DeepSeek-OCR2的核心创新在于通过DeepEncoder V2,赋予了模型因果推理能力(Causal Reasoning)。
这就像是给机器装上了「人类的阅读逻辑」,让AI不再只是死板地从左上到右下扫描图像,而是能根据内容语义灵活调整阅读顺序。
DeepSeek在论文中指出,传统的视觉语言模型(VLM)通常采用光栅扫描(Raster-Scan)顺序处理图像,即固定地从左到右、从上到下。
这种方式强行将2D图像拍扁成1D序列,忽略了图像内部的语义结构。
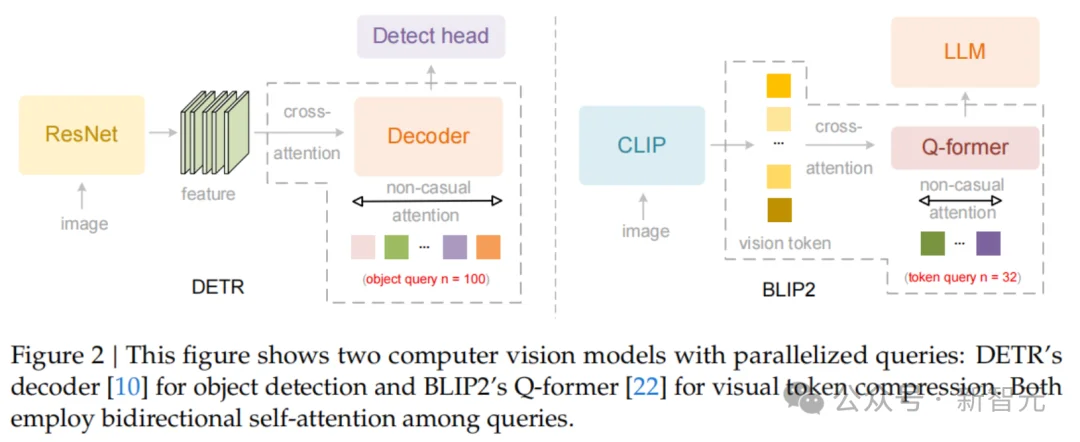
这显然与人类的视觉习惯背道而驰。
人类在看图或阅读文档时,目光是随着逻辑流动的:先看标题,再看正文,遇到表格会按列或按行扫视,遇到分栏会自动跳跃。
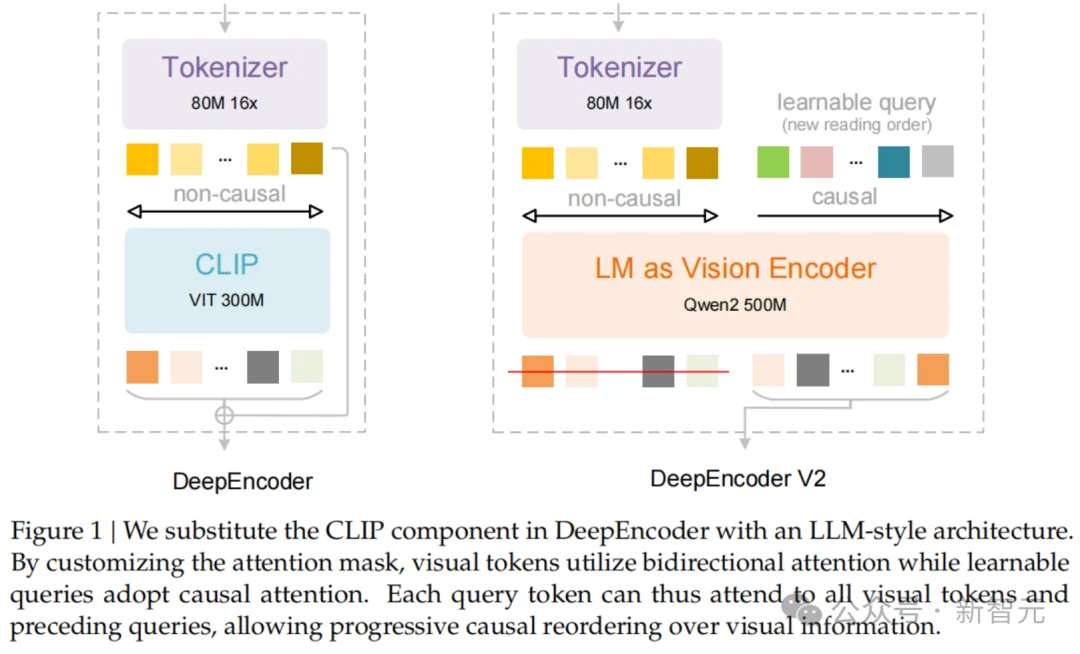
为了解决这个问题,DeepSeek-OCR2引入了DeepEncoder V2。
它最大的特点是用一个轻量级的大语言模型(Qwen2-0.5B)替换了原本的CLIP编码器,并设计了一种独特的「因果流查询」(Causal Flow Query)机制。
DeepEncoder V2架构详解
DeepEncoder V2主要由两部分组成:
1. 视觉分词器(Vision Tokenizer)
沿用了SAM-base(80M参数)加卷积层的设计,将图像转换为视觉Token。
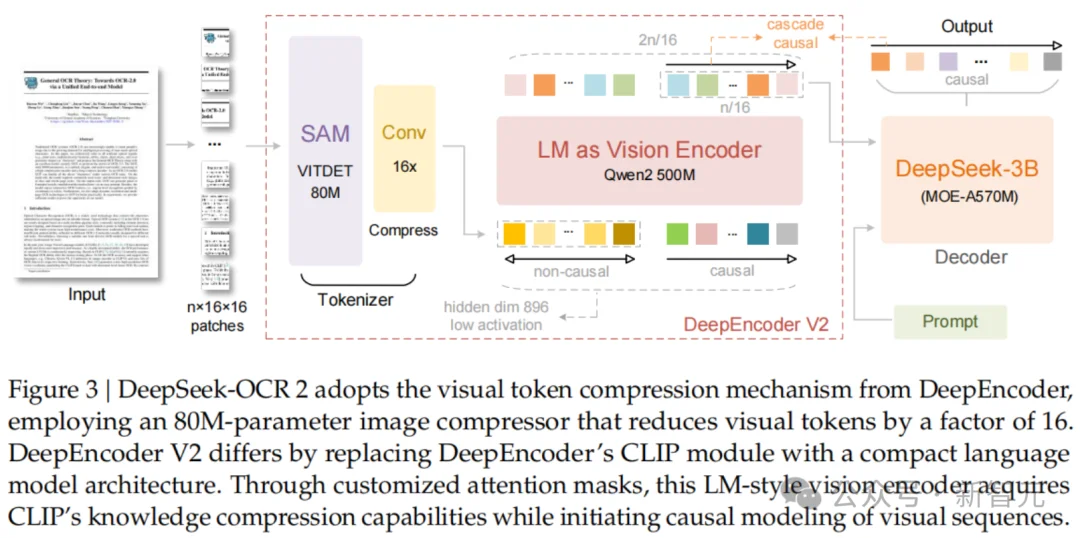
2. 作为视觉编码器的LLM
这里DeepSeek使用了一个Qwen2-0.5B模型。
它不仅处理视觉Token,还引入了一组可学习的「查询Token」(Query Tokens)。

关键的创新点在于注意力掩码(Attention Mask)的设计:
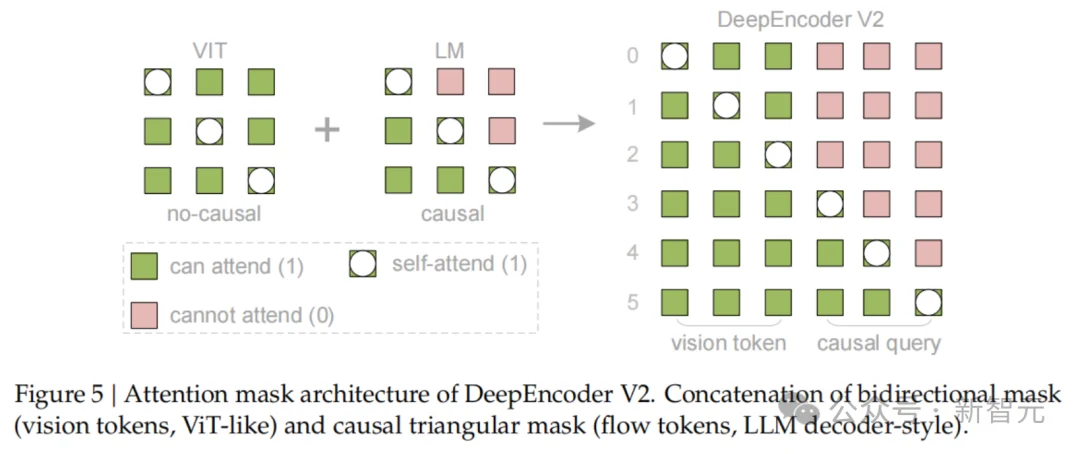
视觉Token之间采用双向注意力(Bidirectional Attention),保持全局感知能力,类似于ViT。
而查询Token则采用因果注意力(Causal Attention),每一个查询Token只能看到它之前的Token。
通过这种设计,DeepEncoder V2实现了两级级联的因果推理:
编码器通过可学习的查询对视觉Token进行语义重排,随后的LLM解码器则在这个有序序列上进行自回归推理。
这意味着,DeepSeek-OCR2在编码阶段就已经把图像里的信息「理顺」了,而不是一股脑地扔给解码器。
实验数据显示,DeepSeek-OCR2在保持极高压缩率的同时,性能显著提升。
在OmniDocBench v1.5基准测试中,DeepSeek-OCR2在使用最少视觉Token(仅256-1120个)的情况下,综合得分高达91.09%,相比前代提升了3.73%。
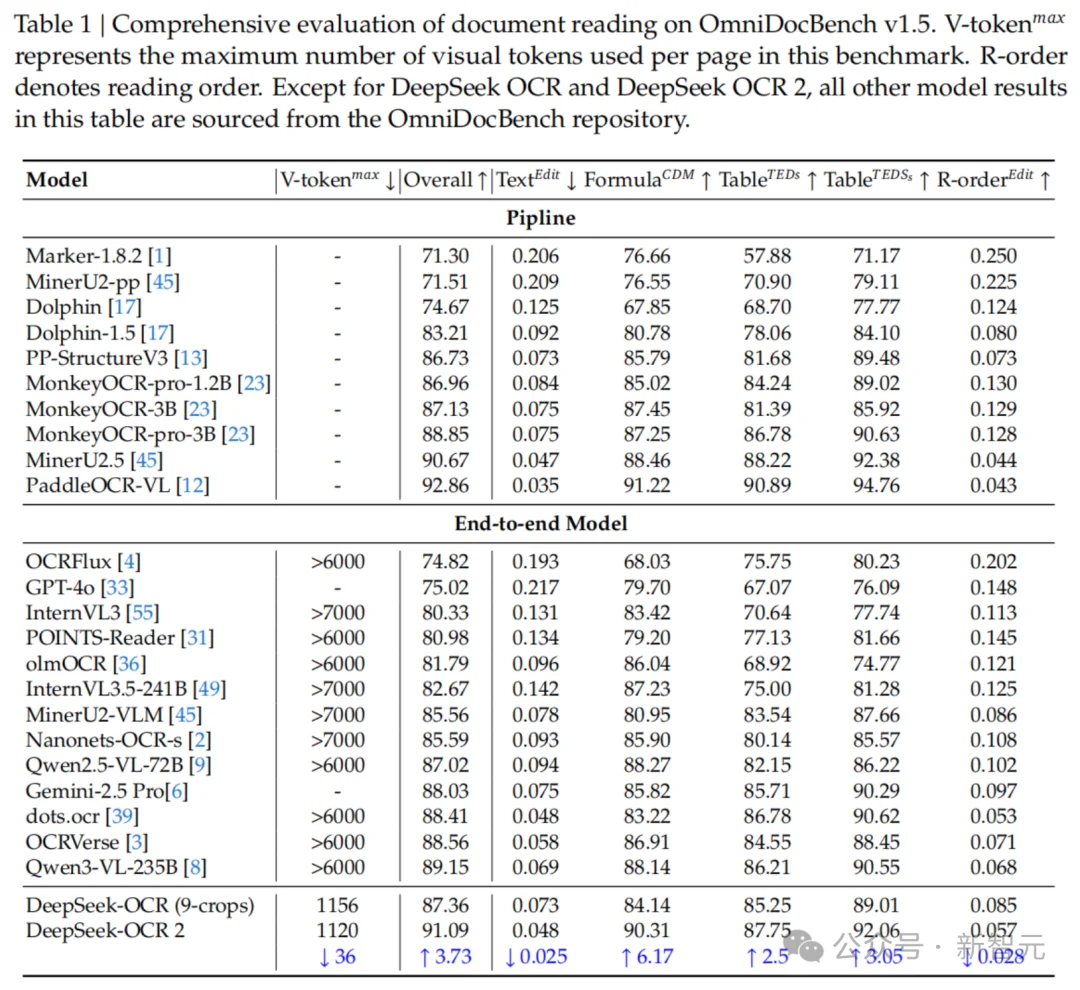
特别值得一提的是,在阅读顺序(R-order)的编辑距离(Edit Distance)指标上,DeepSeek-OCR2从前代的0.085显著降低到了0.057。
这直接证明了新模型在处理复杂版面时,逻辑性更强,更懂「阅读顺序」。
在和Gemini-3 Pro等闭源强模型的对比中,DeepSeek-OCR2也丝毫不落下风。
在均使用约1120个视觉Token的情况下,DeepSeek-OCR2的文档解析编辑距离(0.100)优于Gemini-3 Pro(0.115)。
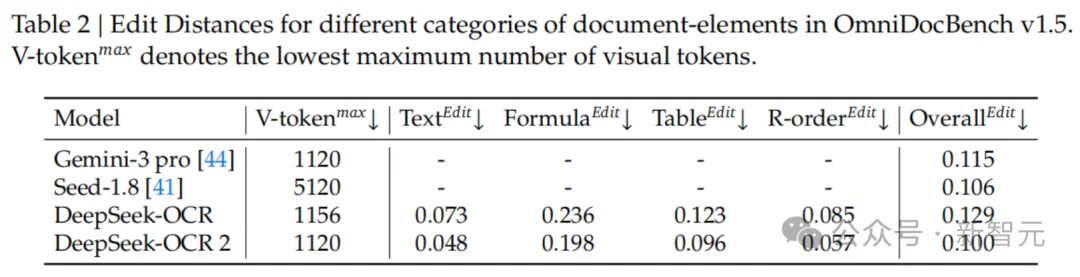
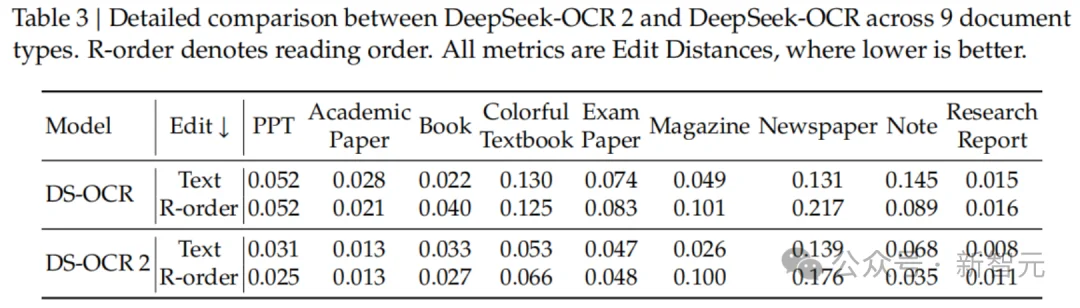
不仅是刷榜,DeepSeek-OCR2在实际生产环境中也非常能打。
DeepSeek披露,在处理在线用户日志图像时,OCR结果的重复率从6.25%降到了4.17%;在PDF数据生产场景中,重复率从3.69%降到了2.88%。

这意味着模型生成的文本更加干净、准确,对于作为LLM训练数据的清洗流水线来说,价值巨大。
DeepSeek在论文最后提到,DeepSeek-OCR2通过DeepEncoder V2验证了「LLM作为视觉编码器」的可行性。
这不仅是一个OCR模型的升级,更是迈向原生多模态(Native Multimodality)的重要一步。
未来,同一个编码器只要配备不同的模态查询嵌入(Query Embeddings),就能处理文本、图片、音频等多种模态的数据,真正实现万物皆可Token,万物皆可因果推理。
DeepSeek表示,虽然目前光学文本识别(OCR)是LLM时代最实用的视觉任务之一,但这只是视觉理解宏大图景的一小部分。
DeepSeek将继续探索,向着更通用的多模态智能进发。
参考资料:
https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
文章来自于“新智元”,作者 “定慧 好困”。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
