# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当前,科学智能(AI for Science)被称之为人工智能的 “皇冠”,以 AlphaFold 为代表的 AI for Science(AI4S)技术在蛋白质折叠、气象预测等特定领域取得了里程碑式成就,但近期《Nature》发表的研究指出,过度依赖现有深度学习模型可能局限新知识的探索边界,甚至在某种程度上阻碍创新。
一项来自上海人工智能实验室(上海 AI Lab)的系统性评估①进一步揭示了当前前沿模型的短板。来自 10 个不同科学领域的 100 位科学家为模型构建了评测题目,结果显示:前沿模型在通用科学推理任务中得分可达 50 分(满分 100),但在各类专业推理任务(如专项文献检索、具体实验方案设计)中,得分骤降至 15-30 分。
“我们已身处 “通用人工智能”(AGI)前夕,但仍面临重要环节的缺失 —— 通专融合的智能。我们亟需推动科学智能从 1.0 向 2.0 迭代,即从 AI4S 迈向 AGI4S。” 日前,上海人工智能实验室主任、首席科学家周伯文在第四十届人工智能协会年会(AAAI 2026)发表特邀报告时提出,科学发现是 AI 的下一个前沿阵地 —— 它既是推理智能的终极试炼场,也是 “通专融合 AGI” 的验证舞台。若 AGI = 通专融合(Specialized Generalist),则可深度专业化通用模型(Specializable Generalist)是实现 AGI 的可行路径。
除了分享前沿观点,周伯文还详细介绍了上海 AI 实验室近年来开展的前沿探索与实践,包括驱动 “通专融合” 发展的技术架构 ——“智者”SAGE(Synergistic Architecture for Generalizable Experts),其包含基础、融合与进化三个层次,并可双向循环实现全栈进化;支撑 AGI4S 探索的两大基础设施“书生”科学多模态大模型 Intern-S1、“书生”科学发现平台 Intern-Discovery 及一系列相关阶段性进展。
演讲最后,周伯文向会场内外的观众发出行动召唤:架构已经就绪,但画卷仍存大片留白,期待与更多同行者共拓蓝图!
以下为报告全文,略有修订。

演进预判:从 ANI 到 AGI 的历史跨越
人工智能的发展历程并非线性堆叠,而是呈现出明显的阶段性跃迁。回顾 AI 发展的历史坐标,有助于我们厘清当前所处的位置及未来的方向。
早在 1996 年涉足 AI 研究之初,我便开始思考智能的本质。特别是在担任 IBM 人工智能基础研究院院长期间,首次提出了通往通用人工智能(AGI)的战略路线图,明确界定了 AI 发展的三个关键阶段:ANI(狭义人工智能)、ABI(广义人工智能)与 AGI,并给出了各自明确定义。
我当时的判断是 ANI 在 2016 年已趋于成熟,而通往 AGI 的必经之路并非直接跃迁,而是必须率先实现具备跨领域泛化能力的 ABI。我们认为这一跨越需要技术范式的根本性变革,最少包括三个方面:即从有监督学习转向自监督学习,从人类分割任务级联式系统转向端到端架构,从判别式工具进化为生成式助手。
六年多后 ChatGPT 的问世,第一次验证了人工智能系统在以上三方面的同时达成,实质上宣告了 ABI 阶段的到来。这一历史性突破验证了规模法则(Scaling Law)的有效性 —— 即通过扩大 Transformer 架构并将 “下一个词预测” 作为优化目标,人类首次实现了对世界知识的压缩。值得一提的是,我和团队早在 2016 年提出的关于 “多头自注意力” 机制的研究,作为 “与下游任务无关”(也就是 “预训练”)的自然语言长上下文压缩表征的首批成果之一,被开创性的 Transformer 论文引用与认可②,为这一预训练时代的压缩智能奠定了重要的理论基石。
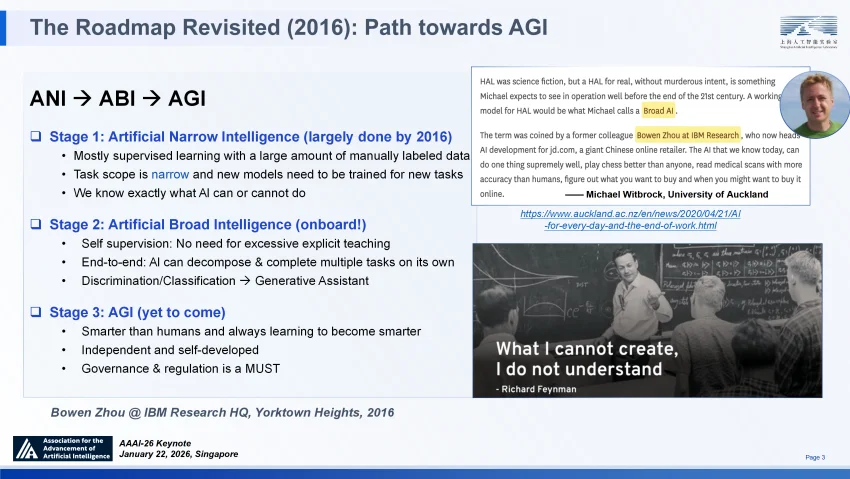
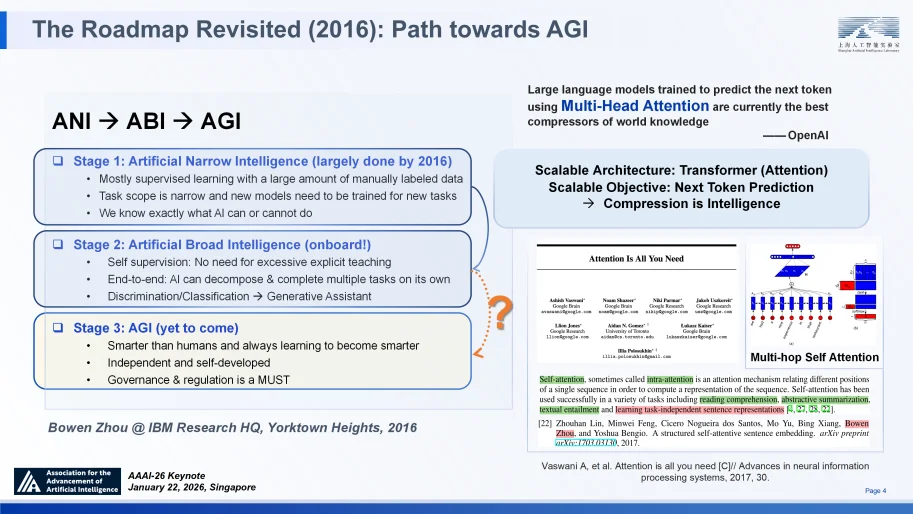
重访路线图(2016 年):通往 AGI 之路
战略路径:通专融合与科学发现的终极试炼
随着 Scaling Law 赋予了大语言模型广泛的泛化能力(ABI),在 2023 年初我们提出了一个关键的战略设问:通往 AGI 的下一步,仅仅是计算量的堆叠吗?对这些设问的思考促使我在 2023 年提出了 “通专融合” 路径。核心思想是如何动态实行融合人类认知思维的系统 1 和系统 2,以应对各种现实世界的任务。
重新定义 AGI 之路
过去 70 年 AI 的发展长期在 “专业性” 与 “通用性” 两个维度上分别进展。以 AlphaFold 为代表的早期系统是极致的 “专家”,在特定领域超越人类却缺乏迁移能力;而当前的大语言模型则是博闻广识的 “通才”,虽具广度但在处理复杂专业任务时往往难以企及专家深度和缺失关键细节。真正的 AGI 必须打破这种二元对立,构建一种能够动态融合 “系统 1”(直觉式快思考)与 “系统 2”(逻辑式慢思考)的智能架构 —— 即在保持通用认知基座的同时,能够在任意特定任务上通过持续学习与深度推理实现专家级的专精(阐述这一思路系统的立场论文已于 2024 年在 ArXiv 上发表)③。
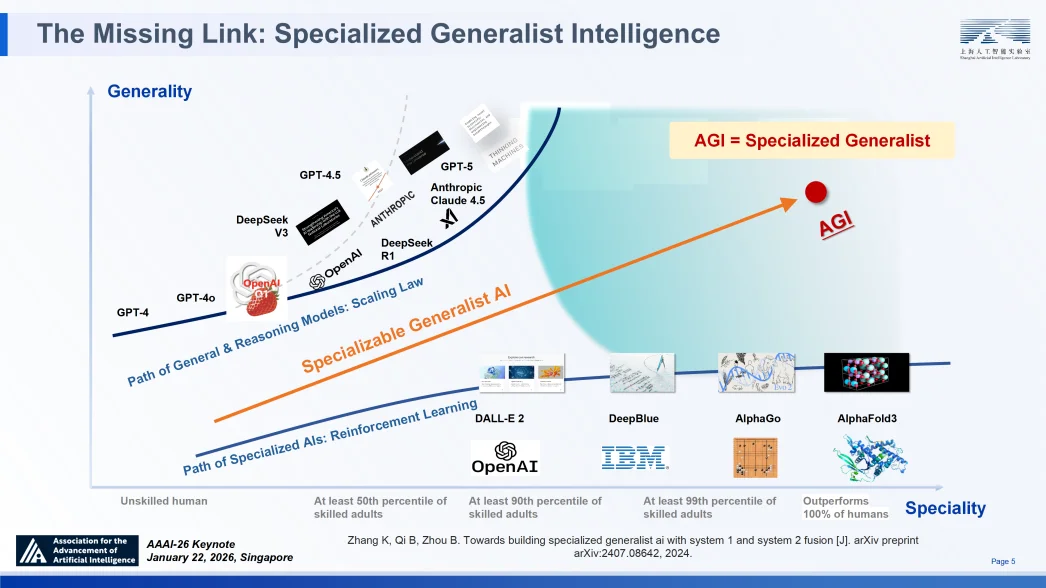
2024 年末 OpenAI o1 与 2025 年初 DeepSeek-R1 的出现,通过在大模型之上应用强化学习显著提升逻辑推理能力,有力地验证了关于 “通专融合” 路径预判的正确性。2025 年 10 月,约书亚・本吉奥教授等人提出了 AGI 的定义,将其分解为十种核心通用能力以及众多狭义的专业能力。若能全面达成这些能力,即意味着实现了 AGI。这一定义与我们 “通专融合是通往 AGI 的战略路径” 的观点高度吻合 —— 这表明该路径正日益成为整个学术社区的普遍共识。
科学发现:推理智能的终极前沿
下一个前沿领域是什么?我认为是科学发现(Scientific Discovery, SD)。在我看来,除了科学智能(AI for Science, AI4S)所承诺的治愈癌症等诸多益处之外,科学发现更是推理智能的终极考验,因此也是 AI 探索的绝对前沿。科学发现是已知与未知之间复杂的相互作用,涵盖了从假设生成、实验验证到理论总结的全过程。其对 AI 提出了三重极限挑战:
因此,科学发现不仅是 AI 的最佳应用场景,更是驱动 “通专融合” 迈向 AGI 的根本动力。
接下来,我想分享我们为应对这一挑战提出的技术架构 ——“智者”SAGE。
技术架构:递归循环的通用专家协同架构“智者”SAGE
为将 “通专融合” 战略转化为可落地的技术方案,上海 AI 实验室在 2024 年提出了“智者”SAGE 架构 —— 其并非若干模型的简单堆砌,而是一个旨在弥合广泛泛化与深度专精鸿沟的统一认知生态系统⑤。该架构由三个逻辑耦合的层次构成:
至关重要的是,SAGE 绝非静态的架构,而是一个递归运行的活体生态。它通过双向循环实现全栈进化:一方面,底层解耦的表征自下而上地支撑推理策略的生成;另一方面,顶层主动发现获得的高水平反馈自上而下回流,将探索中的 “未知” 转化为新的训练信号。这种闭环机制确保了 SAGE 不仅能实现模型参数的优化,更能推动认知策略本身的持续进化。
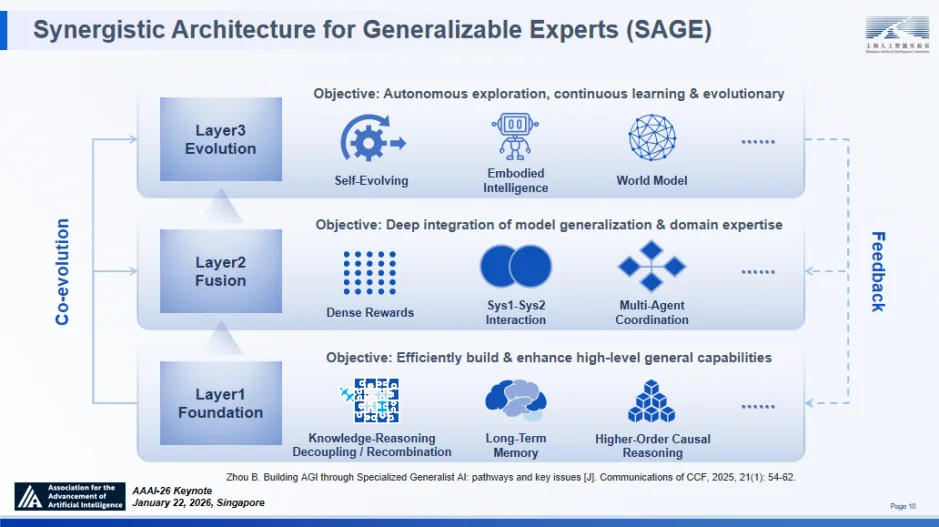
递归循环的通专融合技术架构“智者”(SAGE)
基础模型层:知识与推理的解构与动态耦合
SAGE 的底层致力于解决现有 LLM 将 “事实记忆” 与 “逻辑推理” 混淆的问题。以记忆解码器(Memory Decoder)⑥为例,它针对性地解决了现有大模型架构的两大顽疾:一是检索增强生成(RAG)在长文本语境推理中存在的显著延迟与高昂工程成本;二是领域自适应全参数微调所带来的算力消耗及灾难性遗忘风险。
作为一种预训练、即插即用的独立组件,记忆解码器创新性地采用与基础模型并行运行并融合输出分布的机制。它首次用紧凑的参数化模型替代了传统非参数检索器,在无需修改基础模型参数、无在线检索开销的前提下,实现了高效的知识注入。实验数据显示,其推理开销仅为基础模型的 1.28 倍,显著低于现有主流方案。这一设计成功填补了 “高密度知识供给” 与 “推理引擎解耦” 之间的技术鸿沟,在 SAGE 框架中实现了推理能力与长期记忆的 “解耦但可集成的推理与知识”,同时强化了 “长期记忆” 能力。
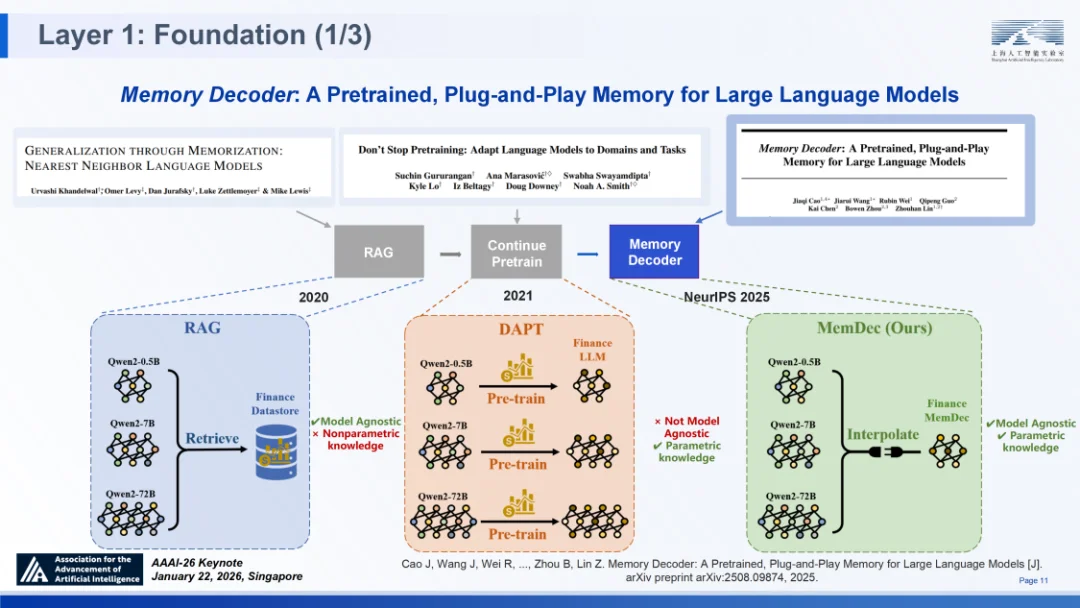
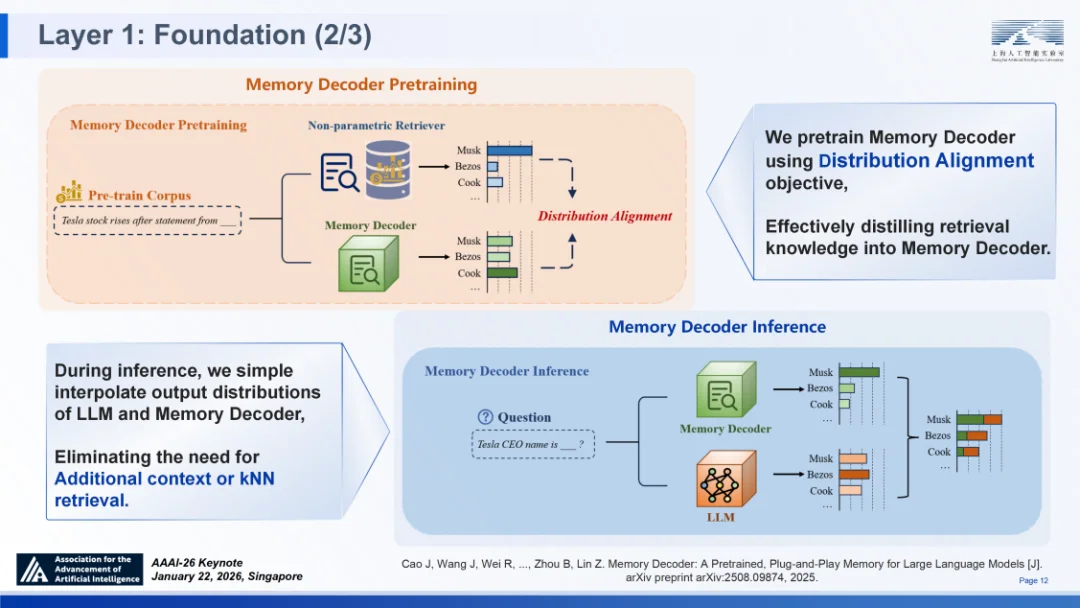
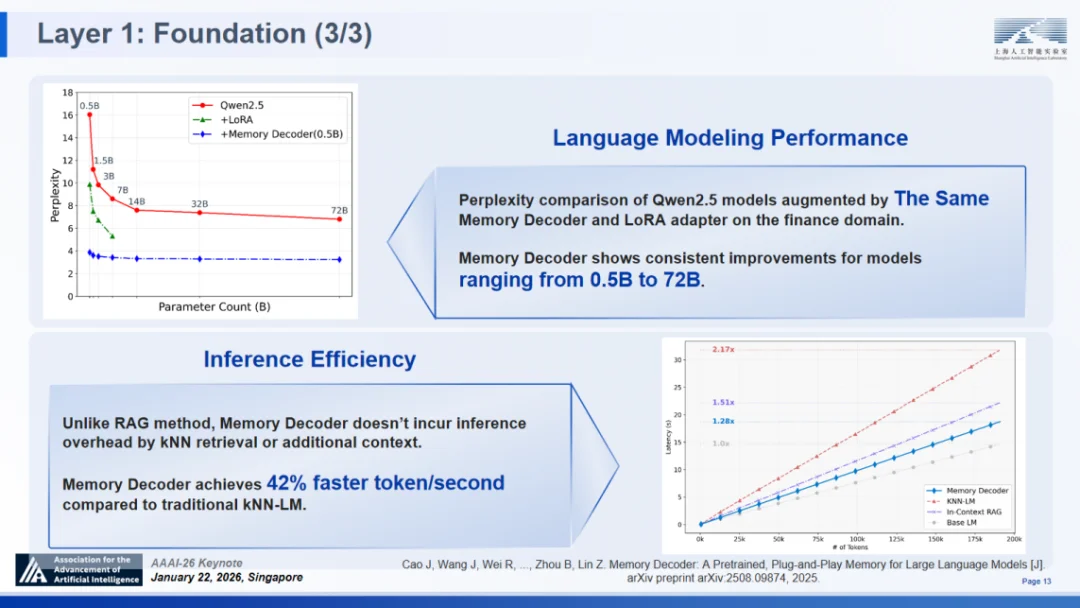
记忆解码器:面向大语言模型的预训练、即插即用记忆体
强化学习:连接基础层与进化层的纽带
强化学习(RL)是连接 SAGE 基础层与融合层、进化层的纽带,也是实现 “通专融合” 的核心动力之一。回顾其演进历程,RL 经历了从早期封闭环境下的博弈(如 AlphaGo),演进至通过 RLHF 实现人类偏好对齐,目前正处于以 o1 和 DeepSeek-R1 为代表的可验证推理(RLVR)阶段,并终将迈向面向物理世界与科学发现的开放式体验学习新纪元。

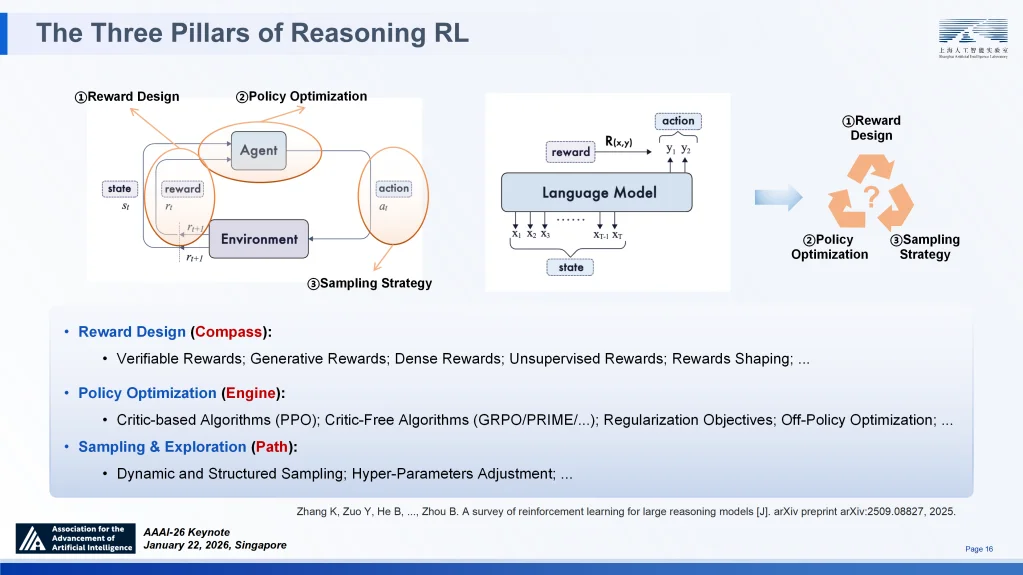
适用于可通专融合的强化学习及其三大支柱
在微观机制上,RL 被归纳为三大支柱:奖励设计作为 “指南针”,通过稀疏或密集信号界定模型专精的目标;策略优化作为 “引擎”,涵盖从 PPO 到 GRPO 的算法迭代,驱动模型高效更新;采样与探索则决定了模型在庞大搜索空间中的导航路径⑦。
鉴于不同任务对 RL 配置的需求各异,构建系统的核心技术挑战在于统一:我们如何将多样性的最佳的奖励机制、策略优化与采样探索整合为一个协调一致的系统,从而打造出真正的 “可深度专业化通用模型”?
融合协同层:强化学习驱动的深度推理进化
在 SAGE 架构中,融合协同层承载着协调 “直觉快思考” 与 “逻辑慢思考” 的核心职能,而强化学习(RL)则是实现这一动态协同的关键桥梁。为了构建一个真正的 “可深度专业化通用模型”,必须克服传统 RL 在复杂推理任务中面临的三大核心挑战:高昂的监督成本、训练过程中的熵坍缩以及单一路径的模式崩溃。为此,我们在该层引入了三项具有范式意义的算法创新,旨在构建密集的奖励机制、维持持续的探索能力以及激发推理路径的多样性。
隐式奖励强化学习算法(PRIME):突破高密度监督的成本悖论
高度专家化的模型与人类专家在学习机制上具有相似性:专家化模型在训练过程中需要更密集的反馈信息。对于 “通专融合” 大模型而言,要解决科学发现中的长链条推理问题,仅依赖最终结果的稀疏奖励往往捉襟见肘,模型急需密集的逐步监督信号。然而,传统的解决方案依赖于过程奖励模型(PRM),这要求对海量推理步骤进行人工细粒度标注,其成本之高昂,使得规模化扩展几乎成为不可能。
针对这一 “高密度监督需求” 与 “高昂标注成本” 之间的矛盾,我们提出了 PRIME 算法⑧ ,旨在从理论层面推导并获取 “免费” 的过程奖励。其核心洞察在于,利用策略模型与参考模型之间的统计差异。通过将模型训练目标设定为基于两者对数似然比的结果奖励模型,我们从数学方面证明,该模型能够隐式地习得 Q 函数。这意味着,智能体在无需显式训练庞大的 PRM 模型的情况下,即可在推理的每一个步骤中,通过计算动作在当前状态下的优劣,直接推导出密集的、逐步的奖励信号。
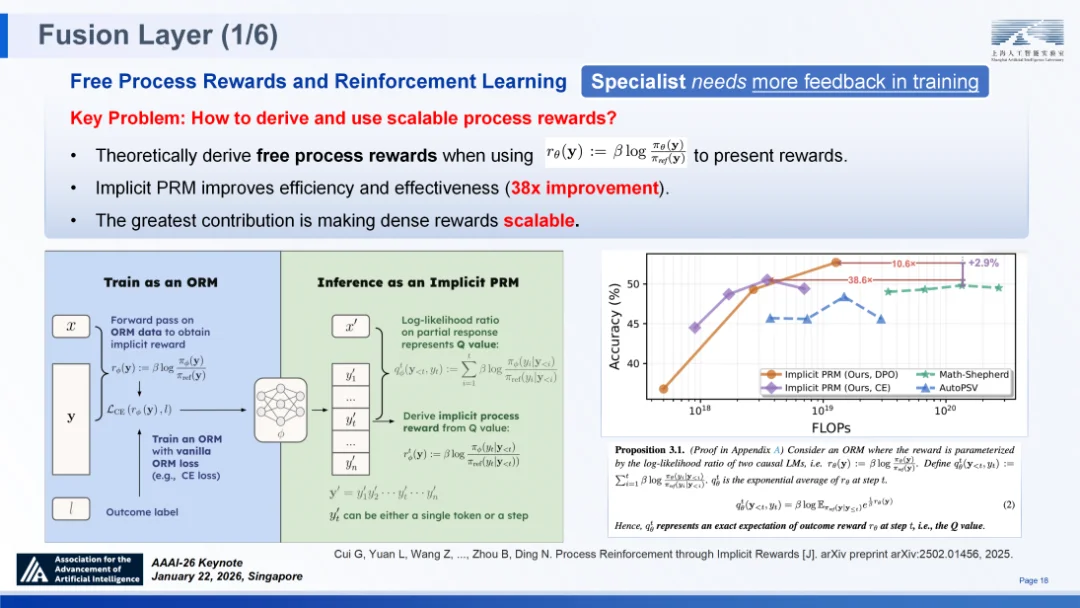
隐式奖励强化学习算法(PRIME)
这一创新带来了多维度的显著优势:
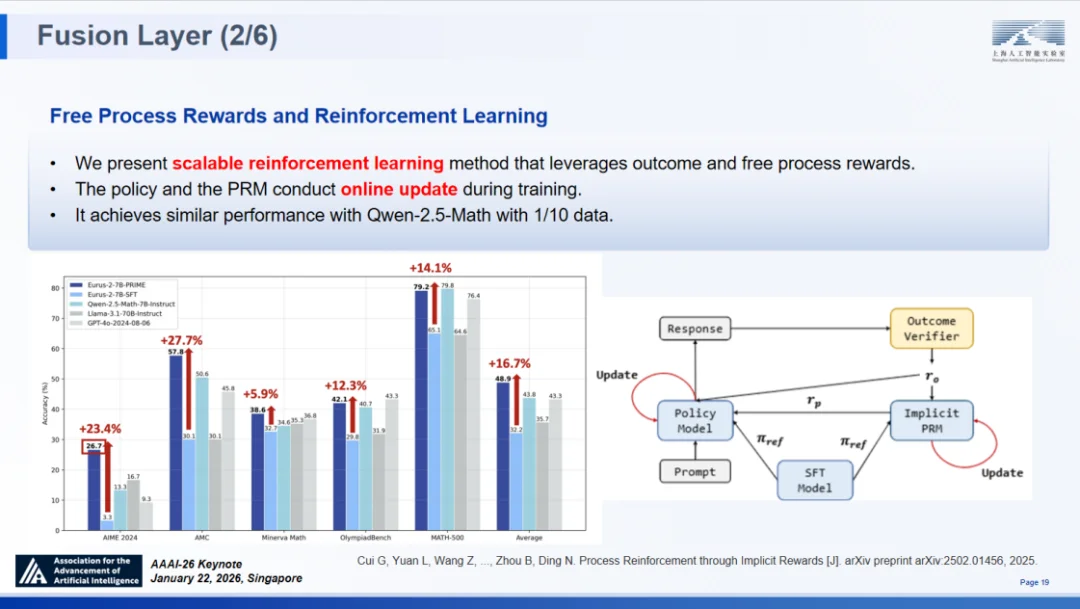
基准测试结果有力地验证了 PRIME 的有效性:在 AIME 2024 数据集上,模型准确率提升了 23.4%;在 AMC 数据集上提升了 27.7%;在 MATH-500 等权威测试中也取得了显著增长。这一系列数据充分证明,通过隐式机制构建的稠密奖励,能够有效驱动模型突破复杂推理的瓶颈。
强化学习的熵机制:避免 “过度自信” 导致探索止步
专家化模型的训练不仅需要反馈,更需要持续不断的学习。在深入研究用于推理的强化学习时,我们揭示了一个阻碍模型进化的根本性障碍 —— 熵坍缩。通俗地讲,这等同于解决如何让通用模型在专家化的过程中,始终保持探索与好奇心,让模型和顶级人类专家一样在专业问题的挑战上避免过早过分自信,而是 “stay hungry, stay foolish”(求知若饥,虚心若愚)。
在训练过程中,随着模型性能的初步提升,策略熵往往会急剧下降。这种下降意味着模型对其输出的置信度快速提高,导致其过早地收敛于局部最优解,从而丧失了探索更优推理路径的可能性。实验数据显示,熵的消耗主要集中在训练的前数百步,此后模型的性能提升便迅速进入边际效益递减阶段。这种现象极似人类认知中的 “过度自信”,即因自满而停止了对问题细微差异的主动探索 —— 而这种主动探索,恰恰是通用模型进化为能捕捉深层规律的 “专精模型” 的关键所在。
为了解决这一问题,我们深入探究了熵与奖励之间的权衡机制,并发现了一个关键的定量关系:验证性能(R)与熵(H)呈现显著的对数线性相关⑨。这一简洁而深刻的结论为训练方案的优化指明了方向:构建可扩展推理 RL 框架的难点,不在于单纯堆砌训练时长,而在于对熵消耗的精细化管理,确保模型在训练全周期内保留足够的不确定性,以驱动持续的探索。
我们提出了一种精准化、局部化且轻量化的熵控制方案:针对这类标记开展选择性调控(如采用 Clip-Cov、KL-Cov 等方法),能够达成局部、轻量的熵控制效果,既保障模型探索性不受损,又不会干扰正常优化流程。该方法实现了对熵的局部控制,既保障了模型的探索性不受损,又避免了对正常优化流程的干扰。应用该策略后,模型在保持高探索能力的同时,显著提升了下游任务的准确率。这一方法已被实验室的“书生”科学多模态大模型 Intern-S1 等多个头部机构采纳应用,其相关成果更由斯坦福 Yejin Choi 教授在 2025 年神经信息处理系统大会(NeurIPS)上进行了重点阐述。
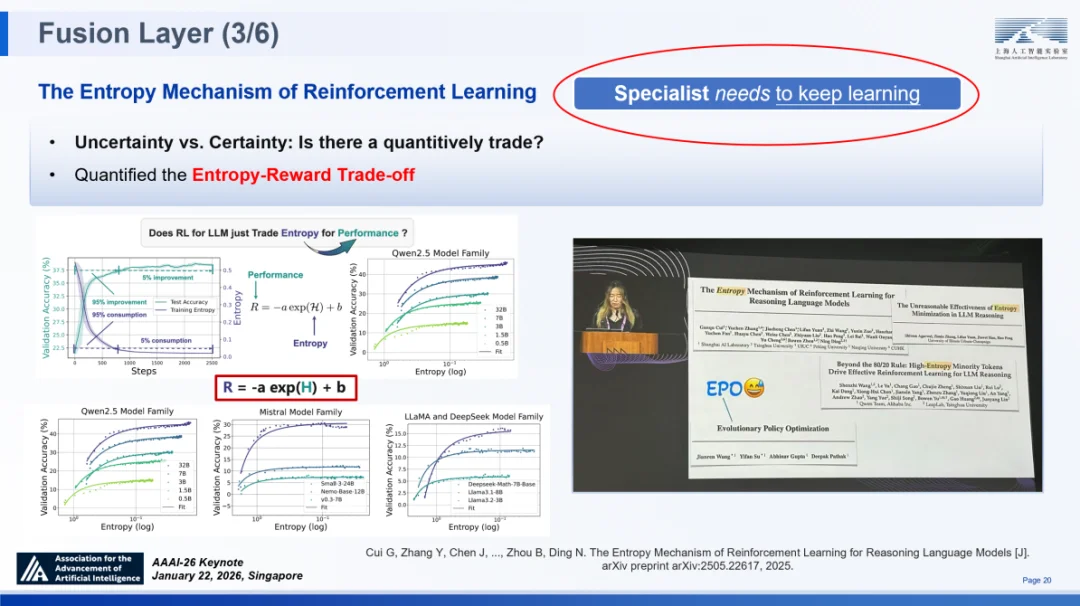

强化学习的熵机制
匹配大语言模型推理的奖励分布(FlowRL):实现专家化模型能力多元化
真正的专家不仅能解决问题,更能能为同一个问题提供多种解决方案,专家化模型亦是如此。然而,现有的标准强化学习方法(如 PPO、GRPO)普遍以 “奖励最大化” 为单一目标。这种导向在复杂推理任务中极易导致模式崩溃,即模型倾向于反复收敛至单一的、已知的成功路径,而忽略了其他潜在的更优解或多样化解法。
传统 RL 方法生成的分布与目标分布之间的 KL 散度高达 8.68,表现为极端的尖峰,意味着模型探索空间的极度狭窄。为了赋予模型真正的专家级思维多样性,我们在融合层引入了 FlowRL⑩,这是一项借鉴生成流网络(GFlowNets)思想的创新工作,标志着强化学习优化逻辑的范式转变。
FlowRL 的核心在于将学习目标从 “奖励最大化” 重构为 “分布匹配”。模型不再仅仅追逐单一的高分答案,而是致力于学习所有有效推理路径的概率分布。
案例显示,在处理同一道数学推理题时,GRPO 模型陷入了思维死循环,推理过程重复且最终未能求解;而 FlowRL 模型则成功探索了多样化的推理路径,最终得出了正确答案 721。
整体实验结果进一步证实了 FlowRL 的优越性:


匹配大语言模型推理的奖励分布(FlowRL)
探索进化层:从被动拟合到主动认知探索
SAGE 架构的顶层探索进化层承载着通往 AGI 最关键的愿景 —— 打造一个具备自演化能力的 “可深度专业化通用模型”。这一层的核心挑战在于,如何让通用模型不仅在单一任务上实现深度专精,更能在大规模任务集乃至复杂的物理世界中,通过持续的交互与反馈实现自我迭代。为了应对这一挑战,我们从信号(Signal)、规模(Scale)与落地(Ground)三个关键维度出发,构建了一套完整的进化机制。
信号维度:测试时强化学习(TTRL)与自我进化
在推理测试阶段,模型面临的最大困境在于训练数据与测试数据之间的分布偏移。一旦失去真实标签的引导,传统模型便停止了学习步伐。然而,真正的 “专家”—— 如同人类物种一样 —— 应当具备在任何未知境况下持续学习适应的能力。
针对这一痛点,我们提出了测试时强化学习(Test-Time Reinforcement Learning, TTRL)框架⑪ ,其核心洞察建立在一个简洁的假设之上:共识即意味着正确性(Consensus implies correctness)。
具体而言,TTRL 在推理过程中对多个候选解决方案进行采样,并将多数投票的结果作为 “代理奖励”,进而利用测试数据流直接对模型参数进行在线更新。这一方法在技术实现上具备极致的轻量化特性,仅需不到 20 行代码,即可将任何推理轨迹转化为有效的训练信号,实现了模型在无监督环境下的 “自我举证” 与 “自我增强”。

测试时强化学习与自我进化(TTRL)
实测数据验证了 TTRL 的惊人潜力:
TTRL 的成功证明了智能体具备自主螺旋式上升的成长潜力,为 SAGE 架构中的自我进化提供了一条简洁高效的路径。
规模维度:InternBootcamp 与任务扩展定律
在解决了 “怎么学” 的信号问题后,必须回答 “在哪学” 的规模问题。通专融合模型不仅需要在单一任务上通过 “慢思考” 实现专精,更需要在成百上千个任务上同时实现能力适配。此外,我们还希望探索一个更深刻的问题:当测试任务的数量与多样性同步扩增时,是否存在专门针对在测试环境下、针对任务数量的 Scaling Law?
为此,我们研发了大规模、标准化、可扩展的交互验证环境 ——InternBootcamp ⑫。
作为首个覆盖 8 大任务类别、超 1000 种多样化环境的平台,InternBootcamp 支持在指定环境中开展大规模强化学习训练。其独特的 “任务与验证函数自动生成” 能力,使得用户能够便捷地将电路设计等专业领域任务转化为可验证环境,通过仿真手段完成结果核验。
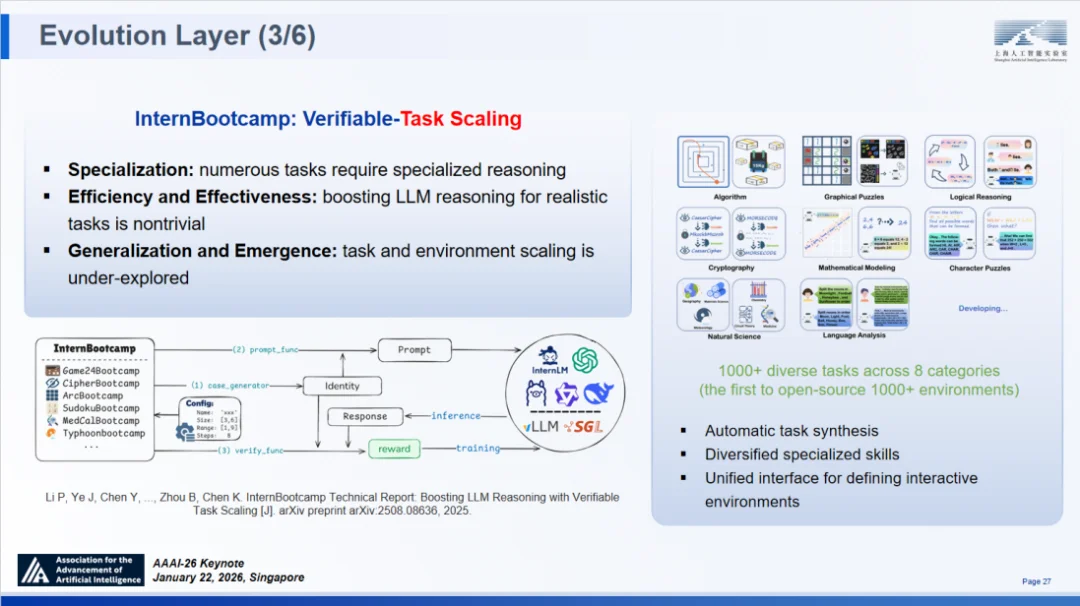
InternBootcamp 覆盖 8 大任务类别、超 1000 种多样化任务环境
基于 InternBootcamp 的实验揭示了两个重要现象:
落地维度:SimpleVLA-RL 与具身智能演进
进化的终局,是回归物理世界。当前具身智能面临的核心瓶颈是数据匮乏:机器人演示数据获取成本极高,且单纯扩大监督微调(SFT)规模面临边际效益递减。我们认为,强化学习(RL)凭借其突破演示数据局限的探索能力,结合简单的二元奖励(成功 / 失败),足以成为解决这一问题的钥匙。
基于此,我们提出了极端数据稀缺情况下的在线强化学习框架 ——SimpleVLA-RL ⑬。该框架基于视觉 - 语言 - 动作(VLA)模型,结合 GRPO 优化目标,并通过并行多环境渲染技术支持交互式轨迹采样。
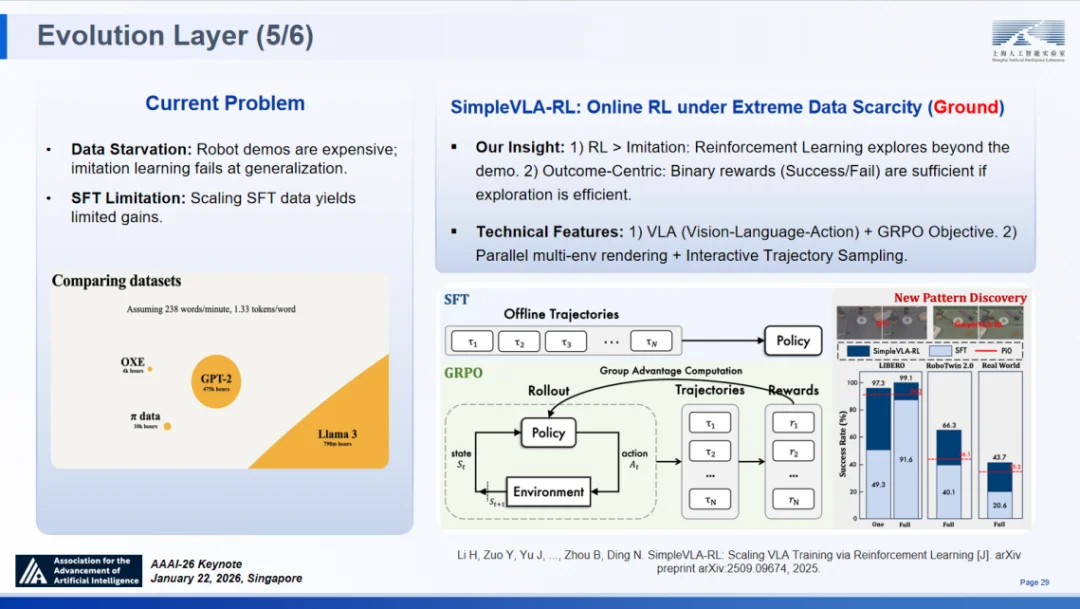
极端数据稀缺情况下的在线强化学习框架 SimpleVLA-RL
实验结果颠覆了对数据效率的传统认知:
得益于 SimpleVLA-RL,我们仅用极少的数据与计算资源,便取得了可与 Physical Intelligence 团队 π*0.6 模型比肩的性能表现。这一成果标志着 SAGE 架构彻底打通了负责推理决策的 “大脑” 与负责执行动作的 “躯体”,真正实现了智能体在物理世界中的 “具身化” 演进。
经过近两年的扎实探索,SAGE 架构已跨越理论构想阶段,完成了全栈验证。在基础层,MemoryDecoder 实现了记忆与计算的结构性解耦;在融合层,PRIME 与 FlowRL 攻克了监督稀缺与推理单一性的难题;在进化层,TTRL、InternBootcamp 与 SimpleVLA-RL 构建了从测试时强化到 “具身化” 演进的闭环。
范式革命:从 AI4S 到 AGI4S
尽管以 AlphaFold 为代表的 AI for Science(AI4S)技术在蛋白质折叠、气象预测等特定领域取得了里程碑式成就,但近期《Nature》发表的研究指出,过度依赖现有深度学习模型可能局限新知识的探索边界,甚至在某种程度上阻碍创新。这印证了我们的核心观点:擅长处理数据充足、定义明确任务的传统深度学习,若仅作为工具存在,难以应对科学发现中 “未知的未知”。
系统性的评估进一步揭示了当前前沿模型的短板。我们联合来自 10 个不同科学领域的 100 位科学家设计了评估体系,结果显示:前沿模型在通用科学推理任务中得分可达 50 分(满分 100),但在各类专业推理任务(如专项文献检索、具体实验方案设计)中,得分骤降至 15-30 分。
这种明显的 “木桶效应” 表明,科学发现全周期的效能正受制于专业推理能力的最薄弱环节。因此,整合通用推理与专业能力,进而推动科学智能从 AI4S 向 AGI4S 迭代成为必然选择。
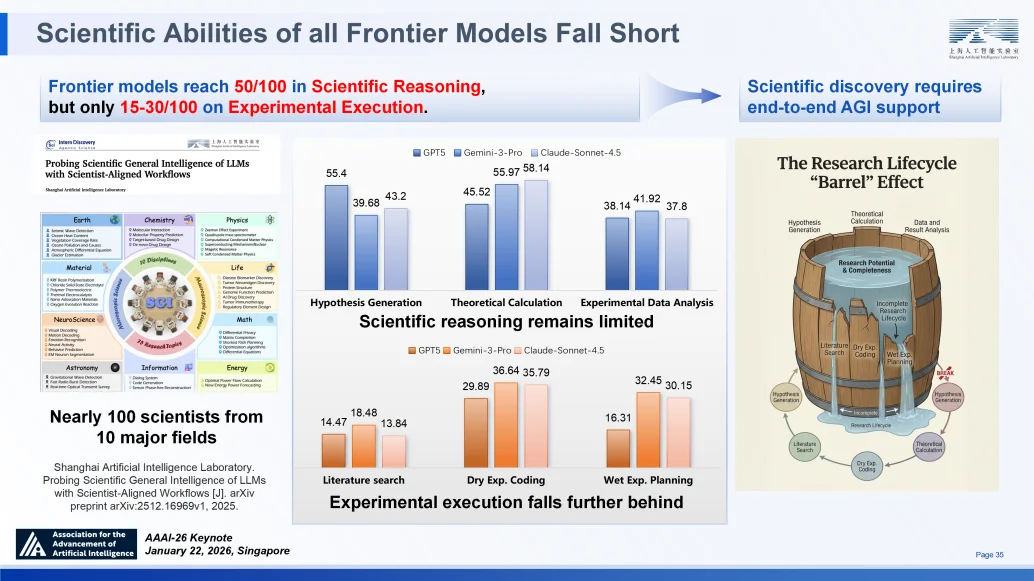
研究表明,当前所有前沿模型的科学能力均显不足
从 AI4S 迈向 AGI4S,这一升级旨在推动研究者、研究工具与研究对象的协同演进。通过 AGI 促进三者相互作用、协同演进、螺旋式上升,将创造出真正 “革命的工具”,推动科研范式变革⑭。
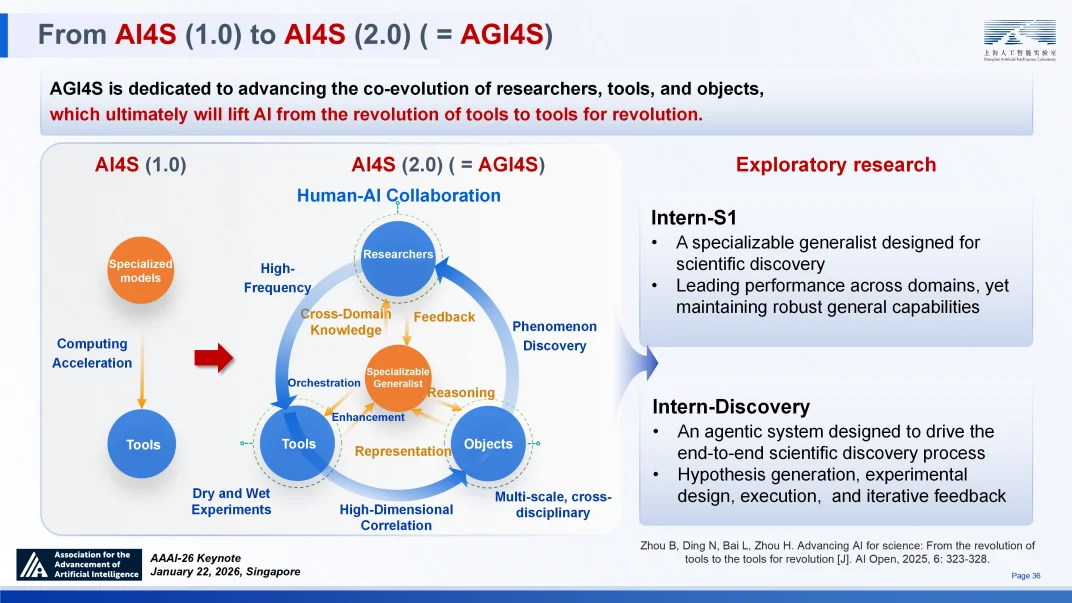
从 AI4S 1.0 到 AI4S 2.0(AGI4S)
Intern-S1:面向科学的可深度专业化通用模型
为打破上述瓶颈,我们研发了 “书生” 科学多模态大模型(Intern-S1)⑮。作为 SAGE 架构在科学领域的集中体现,Intern-S1 旨在构建一个既具备强大通用能力,又能理解复杂科学数据的 “可深度专业化通才”。其在三个层面进行了深度创新:
测评结果显示,Intern-S1 在通用能力上对齐 SOTA 开源模型,而在涵盖化学、生物、材料等 9 大领域的科学性能上,全面超越了包括 GPT-5 和 Grok-4 在内的顶尖闭源模型。
Intern-Discovery:全流程科学智能体系统
如果说 Intern-S1 是科学大脑,那么 Intern-Discovery 则是具备行动力的科学智能体。该平台构建了一个将 Intern-S1 与海量数据、2000 + 专业工具及湿实验室验证环境深度融合的智能体系统,实现了从假设生成到实验验证的闭环。
Intern-Discovery 的核心逻辑在于建立 “智能体生成” 与 “智能体验证” 的双向循环:前者主动洞察现象、提出假设并设计实验;后者通过仿真与物理实验验证假设,并将反馈回传以修正认知。
为支撑这一复杂流程,系统引入了两大关键支柱:
案例实证:重塑科学发现流程
Intern-Discovery 已在气候科学与生物医学领域展现出 “革命性工具” 的潜力。
在气候科学领域,面对降水预测中极端复杂的非线性交互,Intern-Discovery 自主调用 30 余种工具,分析了 20 年的多模态数据。它写了 4000 多行专业代码,成功发现了被人类专家忽略的水汽与动力项关联,并推导出一个简洁的新型显式非线性方程。该方程不仅形式优雅简洁,且显著提升了模拟精度,有效修正了长期存在的系统性偏差,证明了智能体在理论构建层面的创造力⑰。
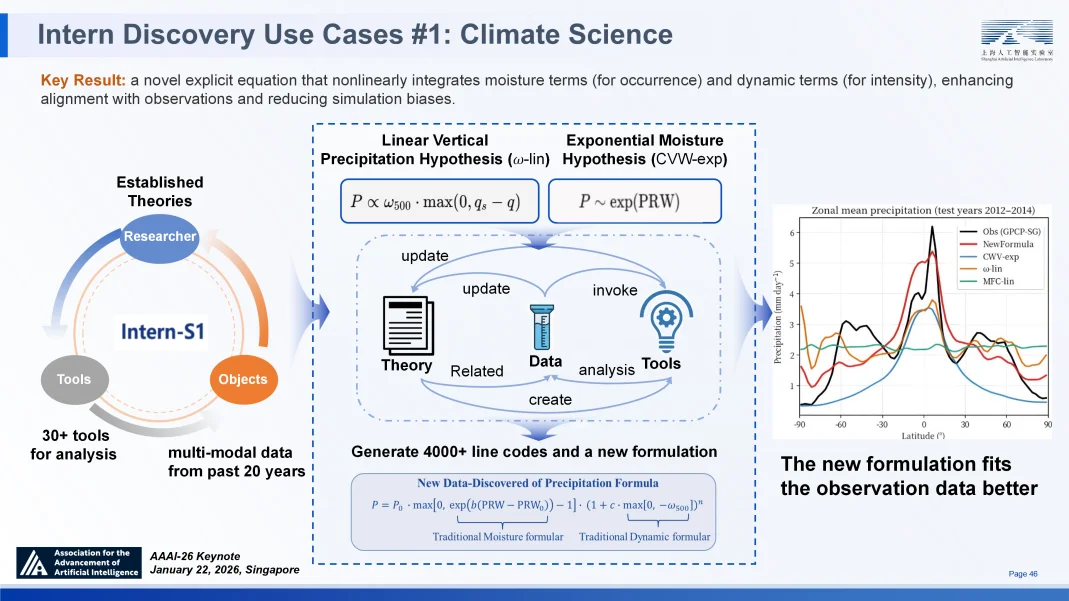
Intern-Discovery 在气候科学的应用案例
在生物医学领域,虚拟疾病生物学家 “元生” 通过模仿人类科学家的思维模板,整合遗传学、蛋白质组学及临床文献等多源数据。即便在数据稀疏条件下,它仍成功发现并验证了具有高临床潜力的隐藏靶点,展示了从数据到机制、从假说到验证的全流程智能化能力。
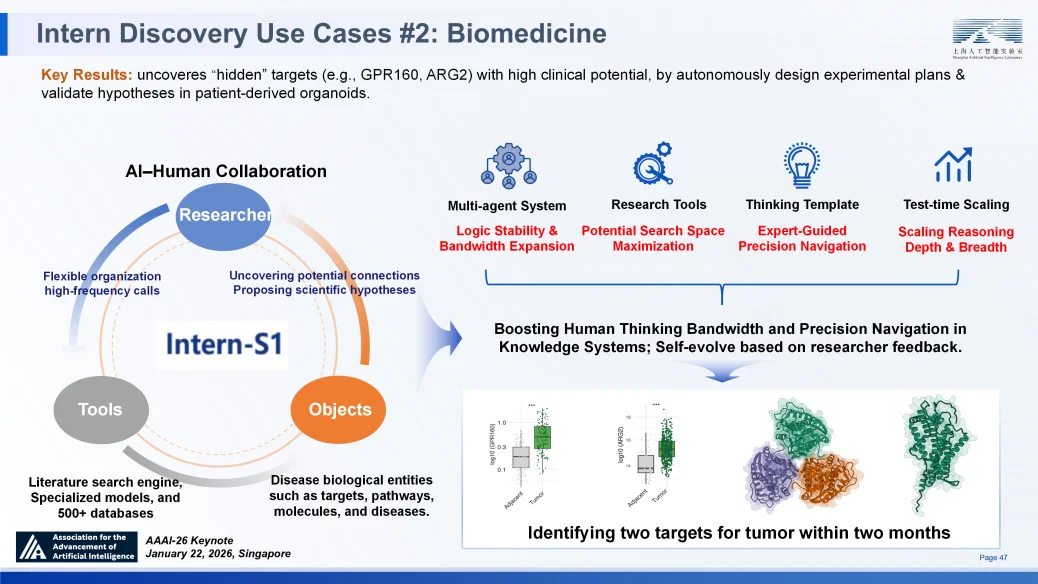
Intern-Discovery 在生物医学的应用案例
从 Intern-S1 的底层推理突破到 Intern-Discovery 的系统级应用,我们正逐步构建起一套覆盖科学发现全周期的 AGI4S 基础设施。这不仅是工具的革新,更是科研范式的重塑 —— 让人工智能真正成为推动科学边界拓展的合作伙伴。
行动召唤:共拓新世界蓝图
综上所述,我们正处在实现 AGI 的前夕,若 AGI = 通专融合(Specialized Generalist),则可深度专业化的通用模型(Specializable Generalist)是实现 AGI 的可行路径,而“智者”SAGE 的三层技术框架正是驱动后者发展的核心架构。
下一个前沿阵地是科学发现 —— 它既是推理智能的终极试炼场,也是 “通专融合” 的验证舞台,大规模推理将赋能科学发现,科学发现亦将反哺推理能力的进化。
Intern-S1 与 Intern-Discovery 是迈向该方向的首步实践,但这一切仅仅是初始的雏形。如果将“智者”SAGE 架构比作一张新世界的地图,我们目前已建立了很好的初步验证与很多尖兵前哨站,但这张地图上仍存在广阔的 “空白区域”。
架构已经就绪,但画卷仍存在大片留白。如果这些初步进展激起了你的兴趣,我邀请你深入阅读我们的论文与代码 —— 它们都是开源的。但更重要的是,我邀请志同道合者与我们一同填补这些空白,共同构建完整的蓝图。
谢谢!

本次报告核心要点总结
参考文献
① Shanghai Artificial Intelligence Laboratory. Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows [J]. arXiv preprint arXiv:2512.16969v1, 2025.
② Vaswani A, et al. Attention is all you need [C]// Advances in neural information processing systems, 2017, 30.
③ Zhang K, Qi B, Zhou B. Towards building specialized generalist ai with system 1 and system 2 fusion [J]. arXiv preprint arXiv:2407.08642, 2024.
④ Qi B, Zhang K, Tian K, ..., Zhou B. Large language models as biomedical hypothesis generators: a comprehensive evaluation [C]. COLM, 2024.
⑤ Zhou B. Building AGI through Specialized Generalist AI: pathways and key issues [J]. Communications of CCF, 2025, 21 (1): 54-62.
⑥ Cao J, Wang J, Wei R, ..., Zhou B, Lin Z. Memory Decoder: A Pretrained, Plug-and-Play Memory for Large Language Models [J]. arXiv preprint arXiv:2508.09874, 2025.
⑦ Zhang K, Zuo Y, He B, ..., Zhou B. A survey of reinforcement learning for large reasoning models [J]. arXiv preprint arXiv:2509.08827, 2025.
⑧ Cui G, Yuan L, Wang Z, ..., Zhou B, Ding N. Process Reinforcement through Implicit Rewards [J]. arXiv preprint arXiv:2502.01456, 2025.
⑨ Cui G, Zhang Y, Chen J, ..., Zhou B, Ding N. The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models [J]. arXiv preprint arXiv:2505.22617, 2025.
⑩ Zhu X, Cheng D, Zhang D, ..., Zhou B, Mei H, Lin Z. FlowRL: Matching reward distributions for LLM reasoning [J]. arXiv preprint arXiv:2509.15207, 2025.
⑪ Zuo Y, Zhang K, Sheng L, ..., Ding N, Zhou B. TTRL: Test-Time Reinforcement Learning [C]// NeurIPS, 2025.
⑫ Li P, Ye J, Chen Y, ..., Zhou B, Chen K. InternBootcamp Technical Report: Boosting LLM Reasoning with Verifiable Task Scaling [J]. arXiv preprint arXiv:2508.08636, 2025.
⑬ Li H, Zuo Y, Yu J, ..., Zhou B, Ding N. SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning [J]. arXiv preprint arXiv:2509.09674, 2025.
⑭ Zhou B, Ding N, Bai L, Zhou H. Advancing AI for science: From the revolution of tools to the tools for revolution [J]. AI Open, 2025, 6: 323-328.
⑮ Shanghai AI Laboratory. INTERN-S1: A SCIENTIFICMULTIMODAL FOUNDATION MODEL [J]. arXiv preprint arXiv:2508.15763, 2025.
⑯ Jiang Y, Lou W, Wang L, ..., Zhou B. SCP: Accelerating Discovery with a Global Web of Autonomous Scientific Agents [J]. arXiv preprint arXiv:2512.24189, 2025.
⑰ Guo Z, Wang J, Ling F, ..., Zhou B, Bai L. A Self-Evolving AI Agent System for Climate Science [J]. arXiv preprint arXiv:2507.17311v3, 2025.
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
