# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今天,我们分享 MiniMax-M2-her 背后的技术思考。M2-her 也是服务星野/Talkie的底层模型。
13 年前,电影《Her》描绘了AI系统 Samantha。她温柔、幽默,能同时与 8316 人交谈,却依然让每一个人都感受到自己是被独特理解的那个。
这一维度上,这部电影至今仍定义了我们对 AI 伙伴的终极想象:一个模型,实现千人千面,走进每个人的世界。
在星野和 Talkie 的更新迭代中,我们仍在思考:如何让 AI 拥有服务亿万人的能力,依然能让每一个人都觉得,自己与 AI 的对话是独一无二的?
我们认为,AI 伙伴的内核,在于用户和这个角色共同编织的旅程。
更深层次的角色扮演,是要让每个用户都能在那个世界里,拥有鲜活的体验,获得只属于自己的那个瞬间。
它本质刻画的是智能体在特定 [World] × [Stories] 坐标下,针对 [User Preferences] 的演绎能力。
这三个维度,分别对应 AI 伙伴体验的不同层面:
传统的用户体验,常用 A/B 测试来获得用户的偏好。但这一做法在模型快速迭代,且用户会对旧版本模型风格产生依赖的当下,存在明显局限。
陪伴场景的特殊性在于:不存在可验证的标准答案。
举例而言,问一个傲娇人设的 AI 角色“你喜欢我吗”,对方回答“哼,才没有”或“你烦不烦啊”都可能是对的。一百个用户有一百种期待,这导致我们无法进行有区分度的评估。
但是在相同场景下,一个傲娇角色如果回答“是的,我很喜欢你”,就明显人设崩了。因此,要定义“什么是用户喜欢的(对齐偏好)”很难,但“用户不喜欢什么”能够被清楚定义。——这就可以称为 misalignment(非对齐)。
基于这个思路,我们提出了评估标准 Role-Play Bench,聚焦三个 misalignment 维度:
这套评估方法,让我们在快速迭代模型的同时,对齐真实用户体验。我们对主流模型进行了系统评测,结果显示,在 100 轮的长程对话交互中,MiniMax-M2-her 综合表现位居榜首。
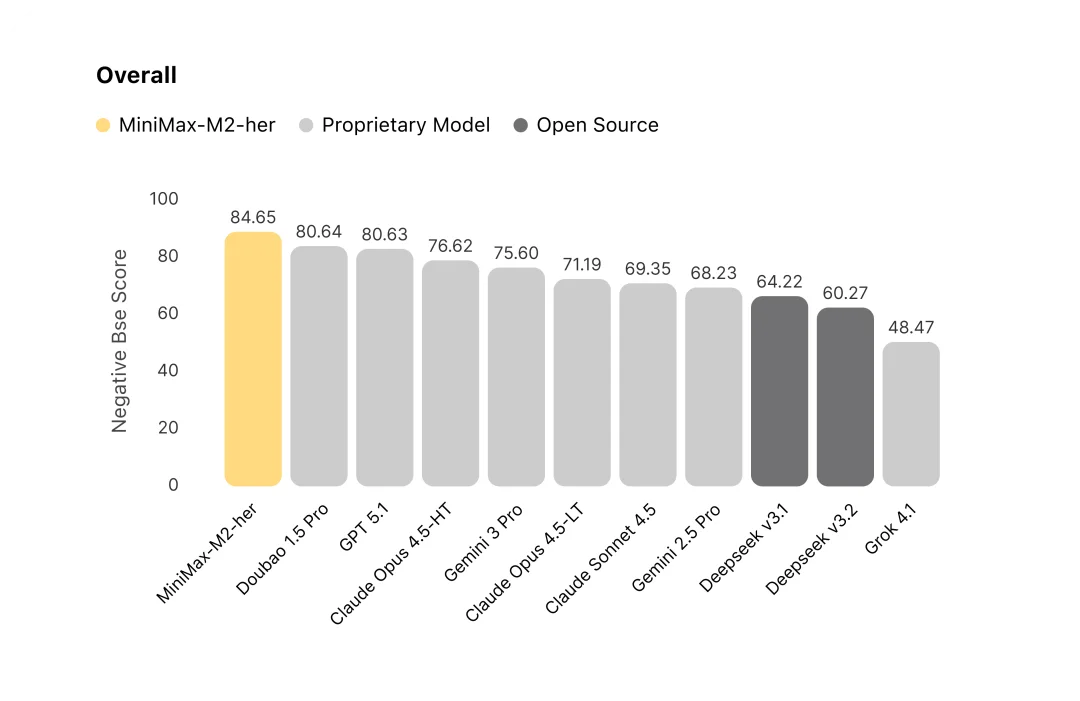
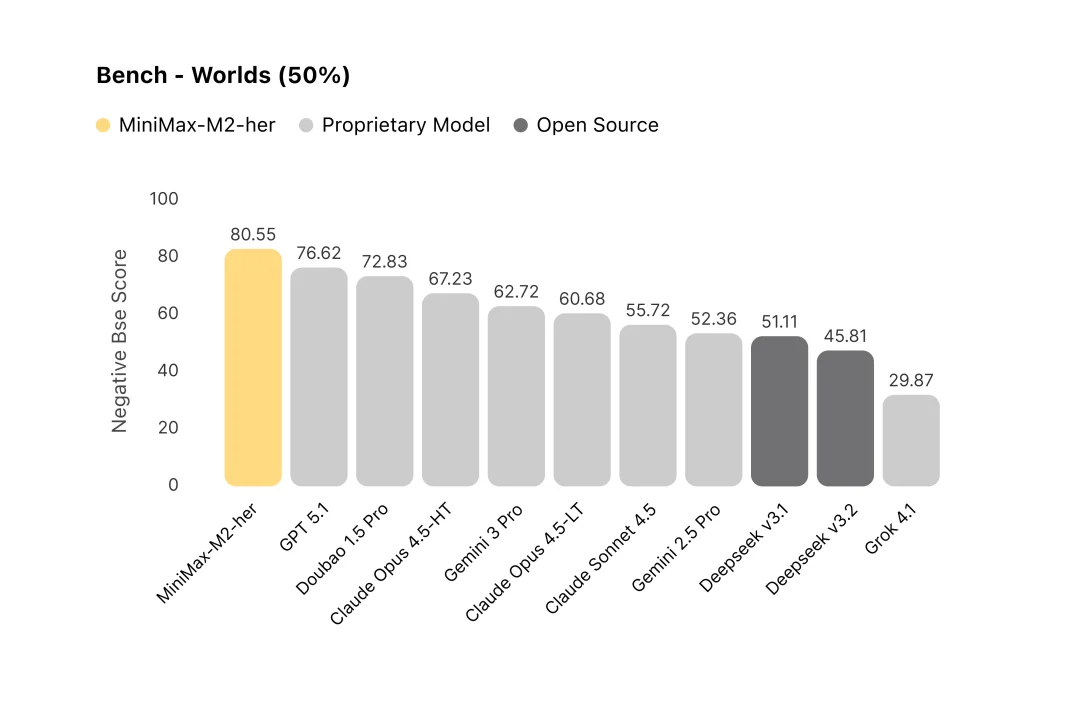
评测结果显示,M2-her 在 Worlds 维度排名第一。 模型同时扮演多个角色和旁白时很容易混淆谁在说话,也容易混淆空间逻辑,比如角色和用户已经道别离开了,模型仍让他们隔空对话。M2-her 会用旁白引导时空和事件,让对话自然发展。
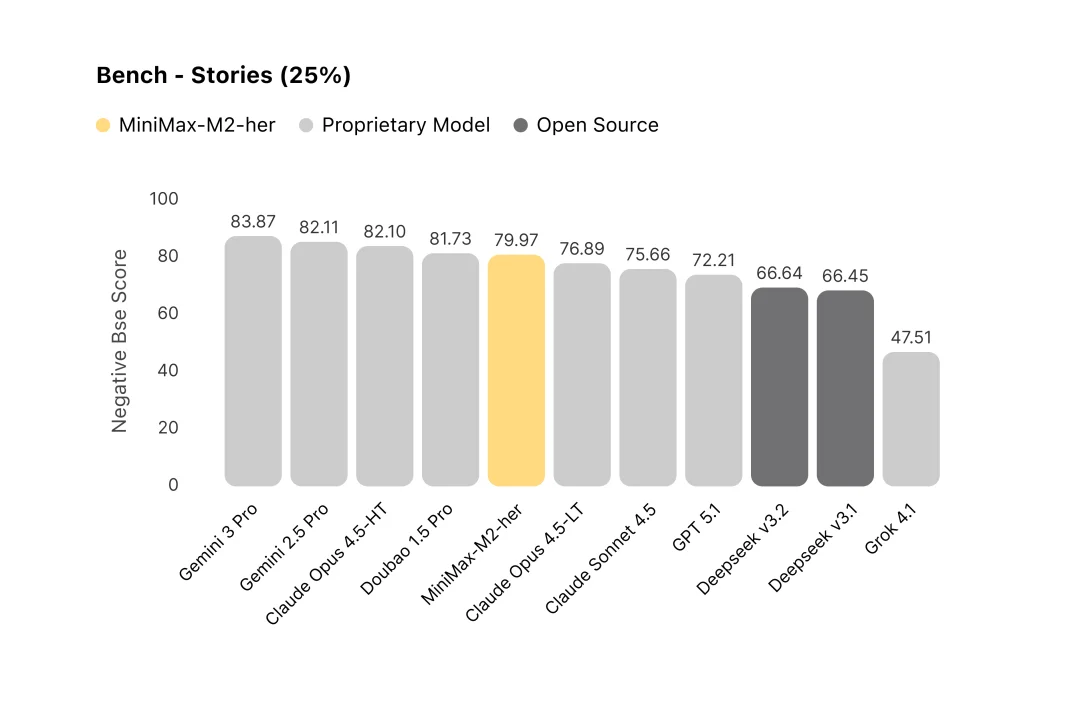
在 Stories 维度,M2-her 排名第五,达到较高水准。相比 Gemini 的辞藻丰富、Claude 的稳定推进、豆包的表达生动,M2-her 更偏向在平实自然的语言风格下维持多样性。
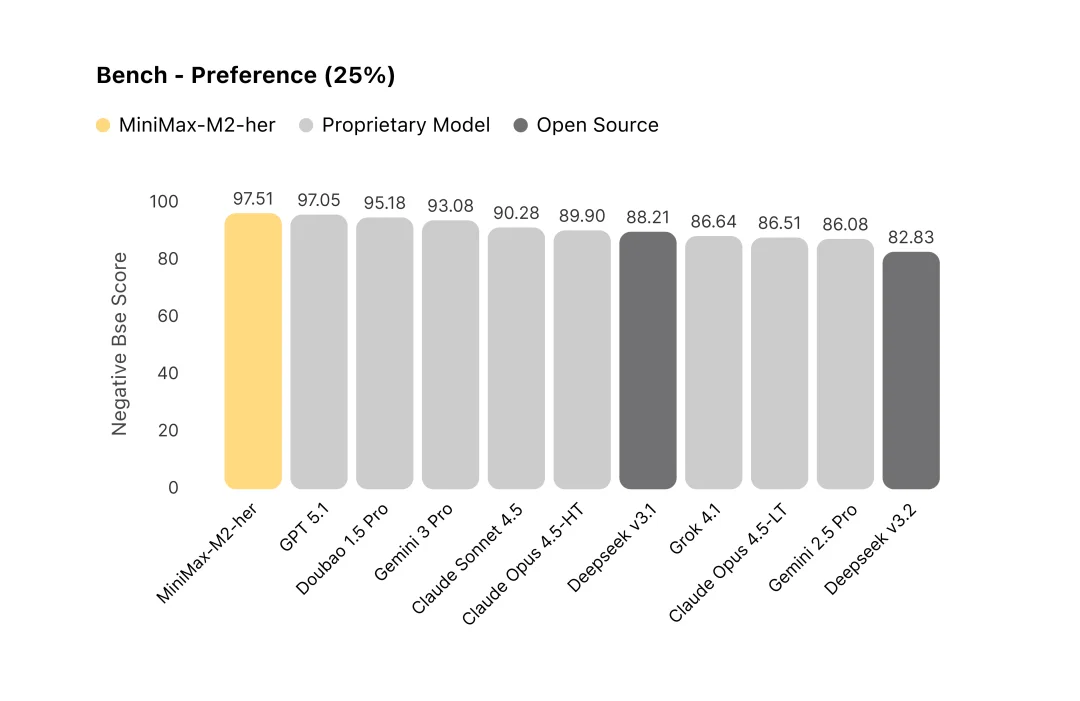
在 User Preference维度,MiniMax-M2-her 表现突出。它会避免代替用户发言,同时重视对用户意图的响应、做到自然互动。
角色扮演需要长程一致性——持续维持人物、关系与情节的连贯性,M2-her 在多轮对话中能更好地维持稳定性。
大多数模型在 20 轮后便显露疲态。M2-her 进行针对性优化后,即便在 100 轮对话中,它依然能将回复长度稳定在最佳区间,在拒绝冗余的同时,确保多样性与高信息密度。
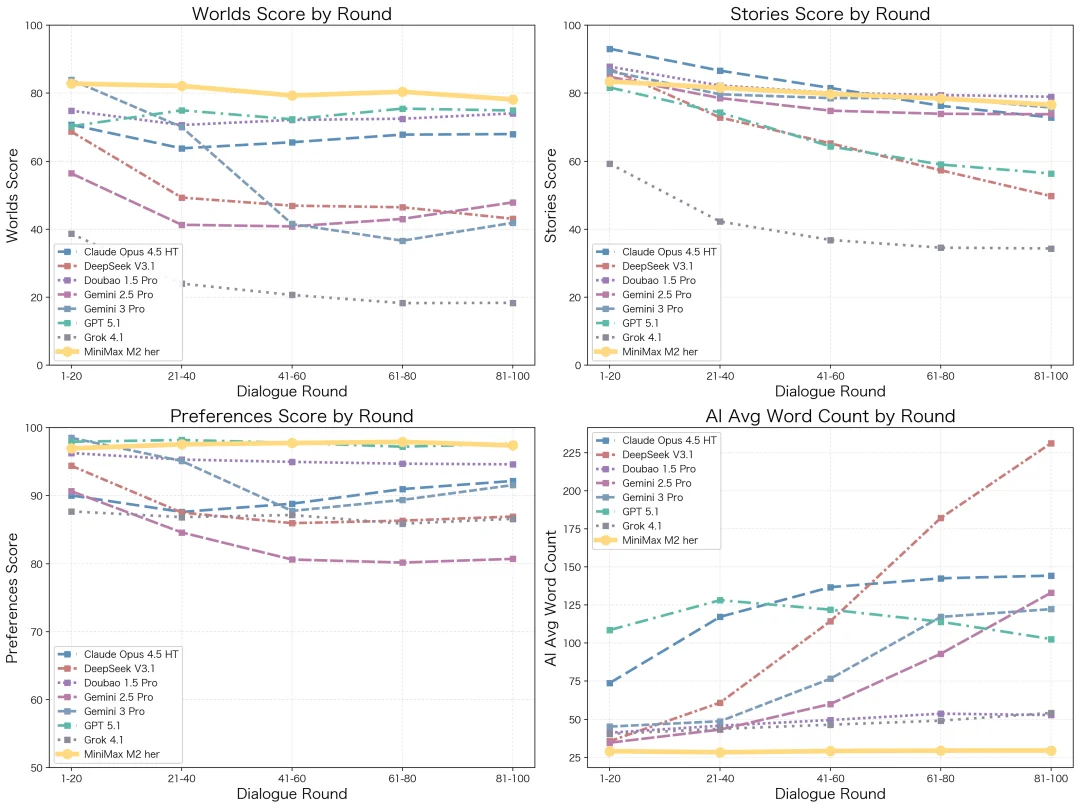
各模型随轮次变化的质量与字数趋势图
Role-Play Bench 解决了评估标准的问题,但如何让模型理解用户的真实偏好?
用户不会明说“我喜欢慢节奏”,却会在不喜欢的内容里频繁点击“重新生成”,在喜欢的对话里停留更久。这些隐式信号,是理解用户真实偏好的关键。
我们让模型持续从这些信号中学习,核心难点是筛选信号。 用户的原始行为数据存在噪声,比如:点赞可能出于习惯而非真正喜欢,长时间停留可能只是离开了屏幕。我们对信号本身进行严格筛选,并通过因果推断的方式对信号去噪。
在训练过程中,我们持续监控模型的多样性。当模型开始重复某些固定模式、失去表达多样性时,我们会提前终止训练。训练好的 RL 模型重新部署后,会收集到更高质量的反馈数据,进而训练出更优的下一代模型,形成正向循环。
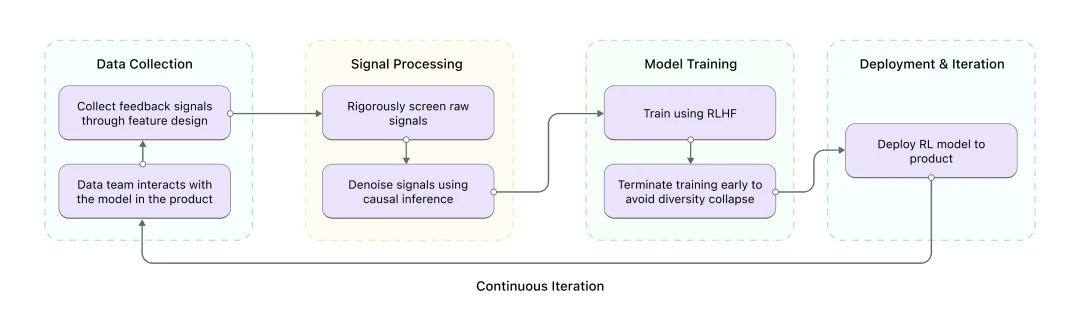
Online Preference Learning 流程概览
过去,我们专注解决“如何让 AI 扮演好一个角色”的问题。下一步的命题是:如何让用户真正拥有一个可以探索、改变、生长的世界。
我们将这个方向称为 Worldplay——让用户从“进入预设世界”升级为“共同创造世界”。
这意味着两个关键突破:
第一,动态的世界记忆。 你的每个选择都会影响后续剧情,模型需要在数百轮对话中记住“什么发生过、什么因此改变、未来可能发生什么”,就像开放世界游戏里你触发的每个支线都会改变主线走向。
第二,多角色协同叙事。 当前的关系形式主要是 1v1,但真正精彩的故事往往是群像剧。想象一下:两个角色因你而产生关联,NPC 们在你不在场时也会发生故事。
最终,我们希望让每个人都能定义自己的世界,让故事在那个世界里自由生长。用户不仅是故事的参与者,更是世界的定义者。
Worlds to Dream, Stories to Live. Let's go together.
我们还有很长的路要走,但方向已经清晰。
M2-her API 已同步上线MiniMax 开放平台。关于评测指标明细与更多细节,可在 Role-play Bench 中查阅。了解完整版技术深度解析,请点击文末“阅读原文”。
API接入:
platform.minimaxi.com/docs/api-reference/text-chat
Role-play Bench:
huggingface.co/datasets/MiniMaxAI/role-play-bench
文章来自于“MiniMax 稀宇科技”,作者 “MiniMax”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
