# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
何恺明,再次出手精简架构。
新方法Pixel Mean Flow(pMF),突破传统扩散模型/流模型限制。
两大传统组件多步采样和潜空间都被砍了,现在只需一步,直接在像素空间生成图像。

在ImageNet 256×256分辨率上,pMF达到了2.22 FID;512×512分辨率上则是2.48 FID。这是目前单步、无潜空间扩散模型在该基准上取得的最佳成绩之一。

现代扩散模型生成图像,一直离不开多步采样和潜空间编码。
多步采样意味着生成一张图需要跑几十甚至上百次神经网络,潜空间则需要先把图像压缩到一个低维空间再进行操作。两者的共同目的是把一个极度复杂的生成问题拆解成若干个相对简单的子问题。
近年来,研究社区分别在这两个方向上取得了进展:
一致性模型(Consistency Models)和何恺明团队2025年提出的MeanFlow在少步、单步采样上持续突破。

何恺明团队2026年1月提出的JiT(Just image Transformers)则证明了在原始像素空间做扩散模型的可行性。
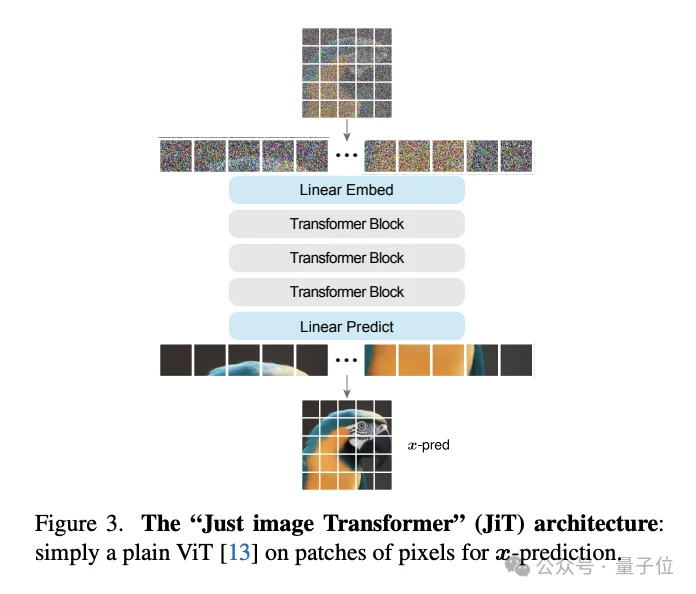
但把这两条路合到一起,难度陡增。
少步模型要求单个网络能够处理不同起点和终点的轨迹;像素空间模型则需要在没有预训练tokenizer的情况下完成压缩和抽象。
两边的挑战叠加在一起,对架构设计提出了更高的要求。
pMF的思路可以概括为:网络直接输出像素级别的去噪图像,但训练时用速度场来计算损失。
具体来说,pMF定义了一个新的场x,它是从平均速度场u通过简单变换得到的。
x场的关键特性是看起来像干净的图像。
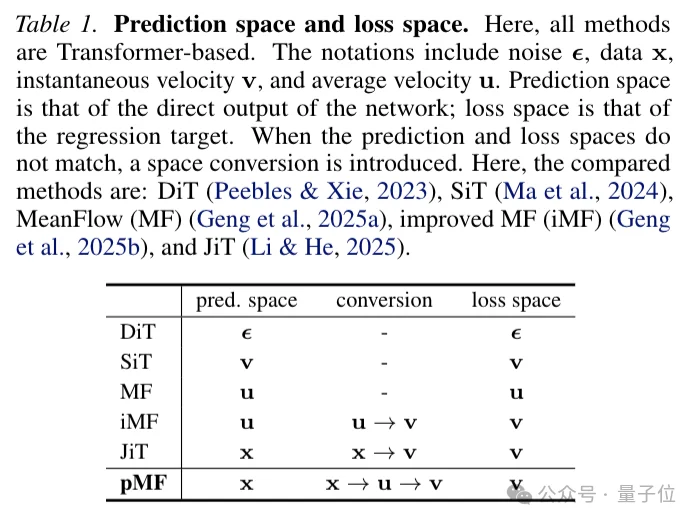
论文通过追踪ODE轨迹进行可视化发现,平均速度场u对应的是噪声图像,而变换后的x场则对应近乎干净或略微模糊的图像。

这背后的假设是流形假设(manifold hypothesis):自然图像实际上位于一个低维流形上,让网络直接预测这个低维流形上的量,比预测高维噪声空间中的量要容易得多。
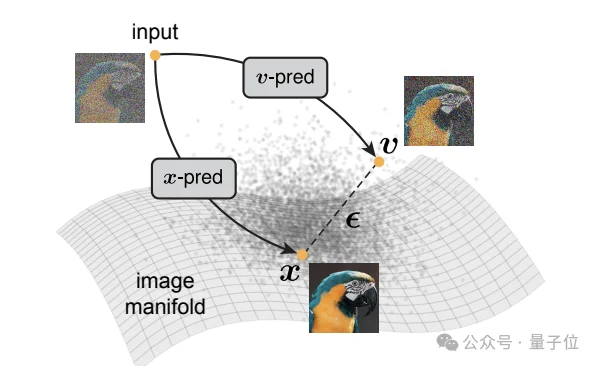
团队用一个2D玩具模型验证了这一点。
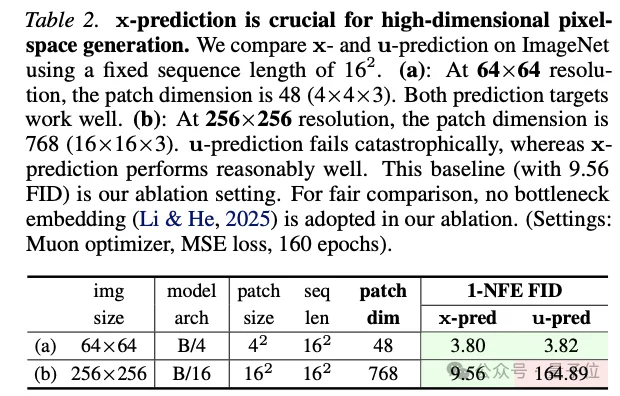
当把2D数据投影到512维观察空间时,传统的u-prediction直接崩溃,而x-prediction仍然能够正常工作。
在真实的ImageNet实验中也是如此:256×256分辨率下,patch维度达到768(16×16×3),u-prediction的FID直接飙到164.89,而 x-prediction则保持在个位数。
pMF还有一个独特优势:
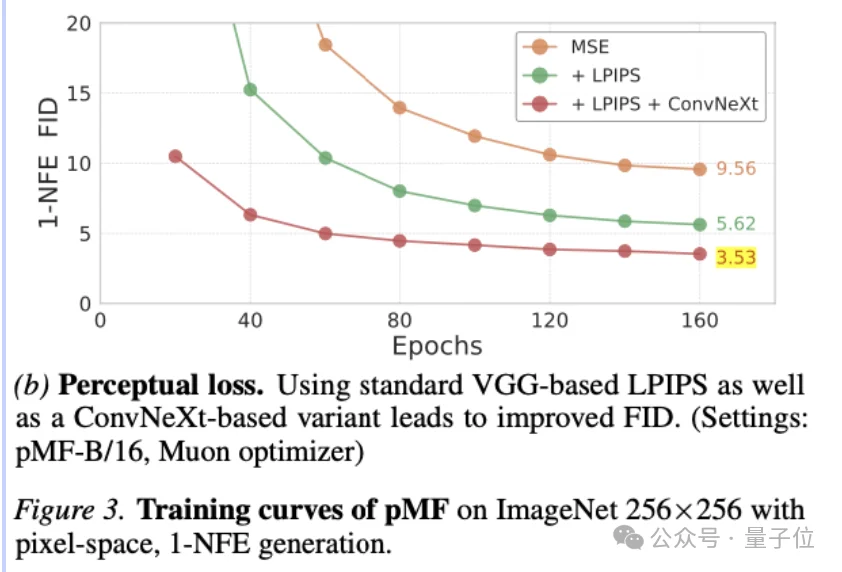
因为网络直接输出像素图像,可以自然地使用感知损失(perceptual loss)。
这本是潜空间方法在训练VAE时才能用的技巧,pMF把它带到了生成器本身的训练中。实
实验显示,加入感知损失后,FID从9.56直接降到3.53,提升了约6个点。
在ImageNet 256×256上,pMF-H/16模型以2.22 FID的成绩,超越了此前唯一的同类方法EPG(8.82 FID)。与GAN方法相比,pMF达到了相近的FID,但计算量大幅下降——StyleGAN-XL每次前向传播需要1574 Gflops,是pMF-H/16的5.8倍。
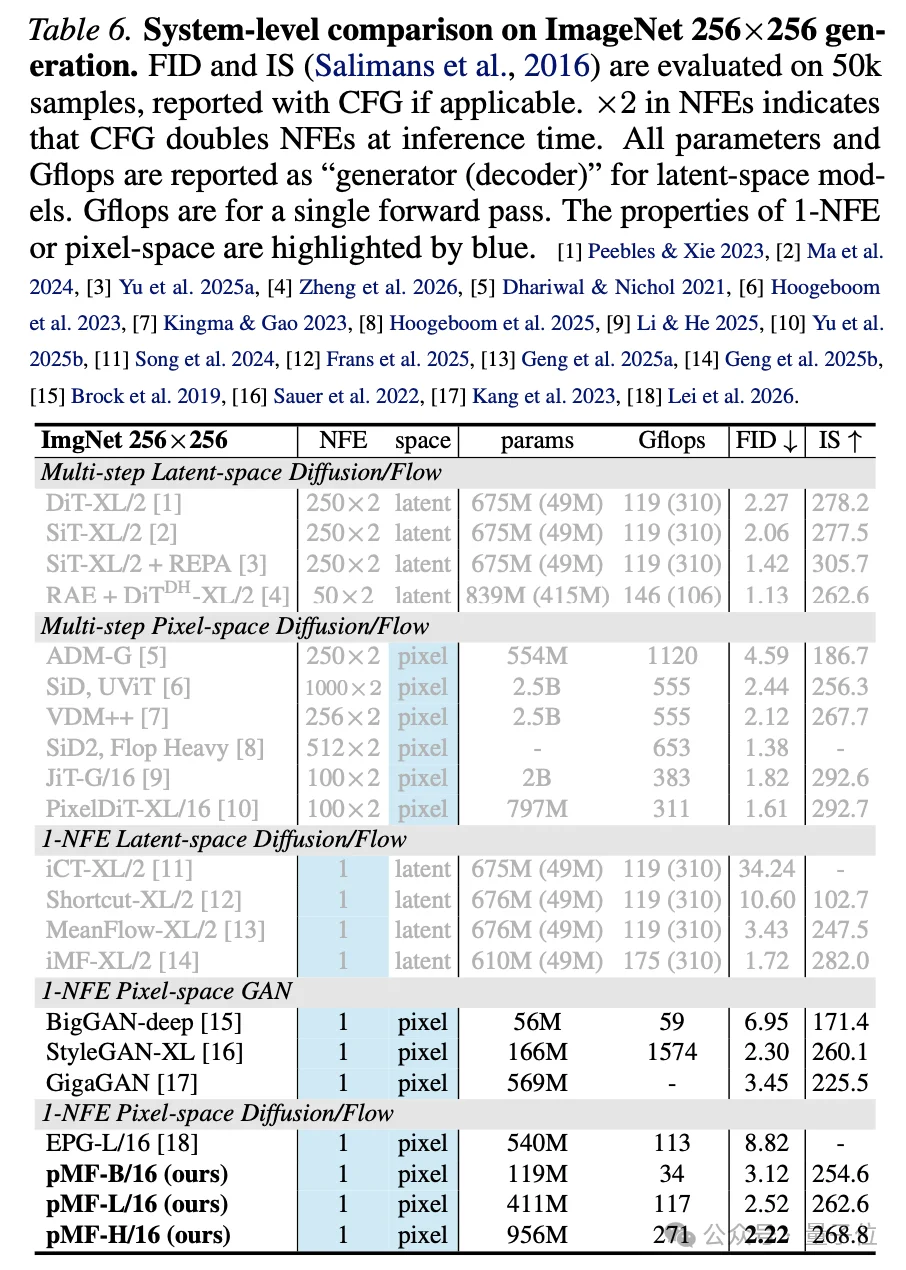
在512×512分辨率上,pMF采用了32×32的大patch尺寸,保持与256×256相近的计算开销,达到了2.48 FID。

另外,潜空间方法还有一笔经常被忽略的开销:VAE解码器。
标准SD-VAE解码器在256分辨率下需要310 Gflops,512分辨率下需要1230 Gflops,这个开销已经超过了pMF整个生成器的计算量。
论文还进行了大量消融实验:
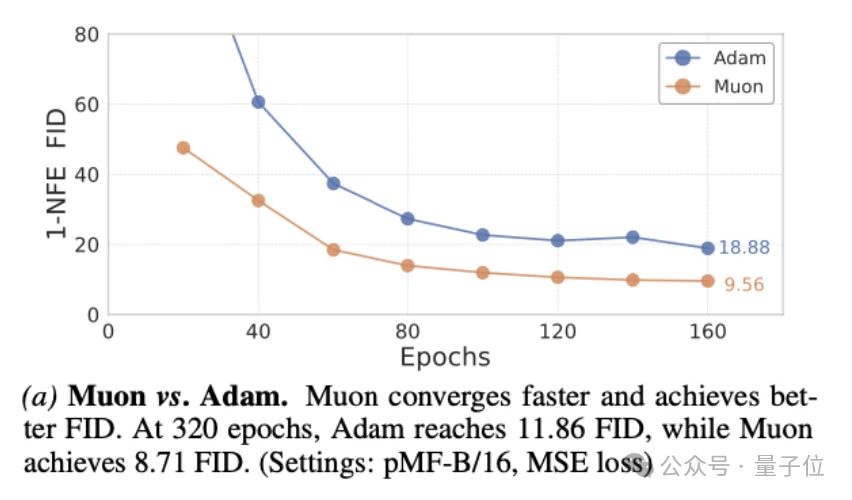
优化器方面,Muon比Adam收敛更快且效果更好;
时间采样方面,MeanFlow的全平面采样策略不可或缺,只在r=t或r=0单线上采样都会导致失败;
预条件器(pre-conditioner)方面,传统的EDM和sCM风格设计在这个高维场景下不如直接的 x-prediction有效。

一个图像生成模型,本质上就是从噪声到像素的映射。
多步采样和潜空间编码都是历史上为了降低难度而引入的折中方案,但随着模型能力的提升和训练技巧的进步,这些“拐杖”正在变得不那么必要。
团队在结尾写道:希望这项工作能够鼓励未来对直接、端到端生成建模的探索。从实验结果来看,单步无潜空间生成已经从“是否可行”进入到“如何做得更好”的阶段了。

共同一作Yiyang Lu(陆伊炀)、Susie Lu、Qiao Sun(孙启傲)、Hanhong Zhao(赵瀚宏)为MIT本科生。
其中孙启傲是IMO金牌得主,赵瀚宏是国际物理奥林匹克竞赛IPhO金牌得主,陆伊炀是全国中学生物理竞赛CPhO金牌得主。
论文地址:
https://arxiv.org/abs/2601.22158
文章来自于“量子位”,作者 “梦晨”。


