# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2026 刚来到 2 月,无论是底层模型大厂还是初创公司统统加速开卷,其中 Agentic Memory 方向的快速进化更是把大模型的能力上限推向了 NEXT LEVEL!
OpenAI 和 Anthropic 持续推高上下文窗口的上限,Clawdbot 小虾凭借记忆能力住进了更多用户心中,AI 行业共识正在发生微妙但剧烈的转向 —— 没有记忆的 Agent 只是一个高级的自动补全工具。要让 AI 真正处理复杂项目或长期任务,它必须具备一种跨会话的、结构化的长期记忆机制。
如果说大模型提供了 “高度运转的大脑”,那么记忆层就是 Agent 真正迈向好用的 “关键能力”。
Sequoia Capital 的合伙人在近期的一次闭门会上谈到,未来的 Agent 核心挑战之一是实现 "持久化身份"(Persistent Identity)—— 让 AI 不仅能记住用户的历史交互,更要在长时间运行中保持一致的理解和上下文记忆。在 Agentic AI 的进化竞赛中,一个长期被忽视的瓶颈正成为顶级风投追逐的新风口:持久化记忆(Persistent Memory)。
刚刚,Feeling AI 团队在深夜发布 MemBrain1.0,在 LoCoMo / LongMemEval / PersonaMem-v2 等多项主流记忆基准评测中拿下全新 SOTA,反超 MemOS、Zep 和 EverMemOS 等记忆系统和全上下文模型;在 KnowMeBench Level III 两个难度等级最高的评测中更是比现有评测结果大幅提升超 300%。
Feeling AI 是 2025 年刚浮出水面不久的 AI 初创团队,创始人戴勃是生成式 AI 领域的青年科学家,他曾在 NTU 和上海 AI 实验室任职,担任生成式 AI 团队的负责人。据媒体此前报道,他们还低调的完成了两轮超亿元的融资,是国内最早在世界模型和 3D 动态交互方向进行尝试的团队之一。
Feeling AI 公布的评测结果,通过在 4 个业内公认的记忆基准测试来一场 "实战演练" 以验证算法的 "真功夫"。基于 EverMemOS 开源仓库搭建的一个 "公平擂台"—— 所有 “参赛选手” 都使用同一个基础大模型(GPT-4.1-mini)作为 "底座",MemBrain1.0 与其他大模型记忆增强方法在同一起跑线上的能力比拼结果先看为敬。
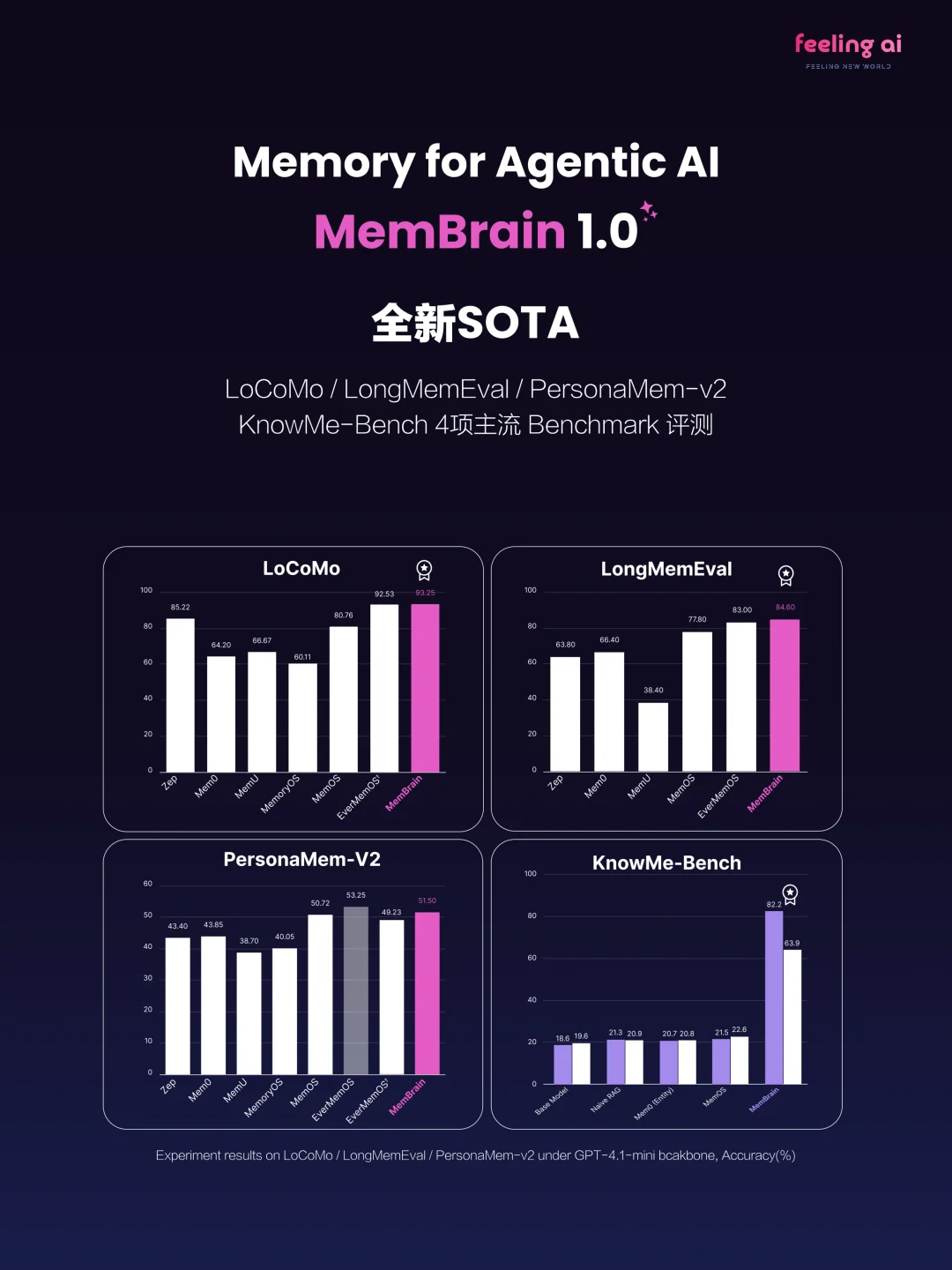
在主流测试基准 LoCoMo 和 LongMemEval 上,MemBrain1.0 分别以 93.25% 和 84.6% 的准确率斩获新的 SOTA。这部分得益于 MemBrain1.0 精细的实体 - 时间上下文管理设计, 在时序任务以及多会话场景任务下取得显著提升。
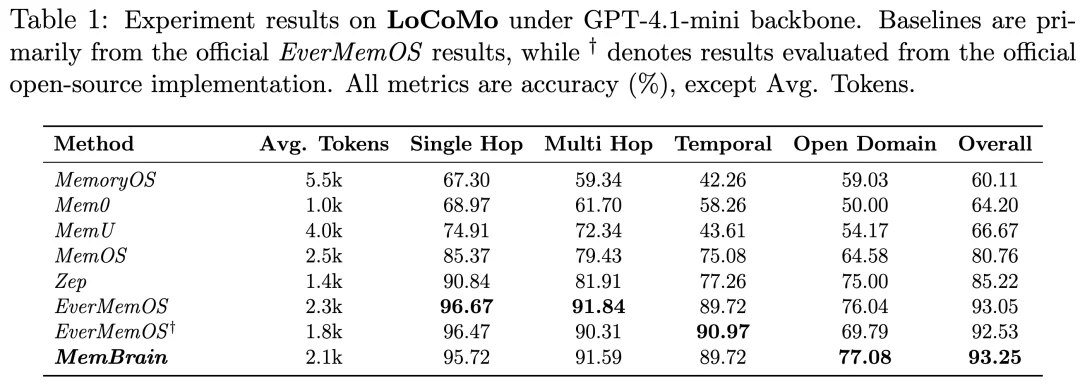
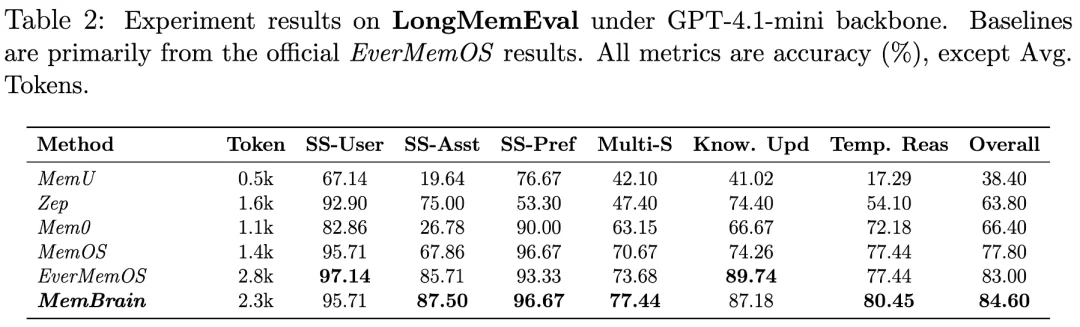
在另一个考察隐性画像捕捉能力的 PersonaMem-v2 测试基准上,MemBrain1.0 以 51.50% 的准确率超越现有公开的方法,精准实现了对用户长期偏好的深度洞察。
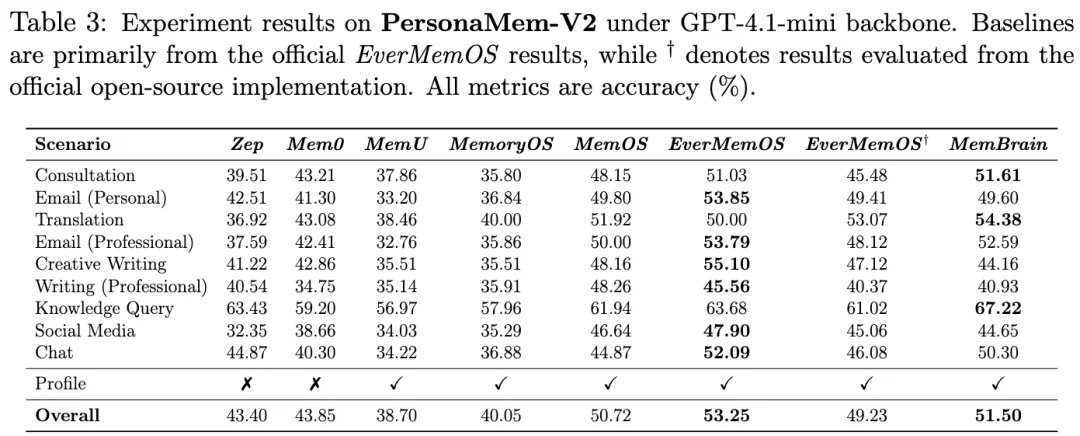
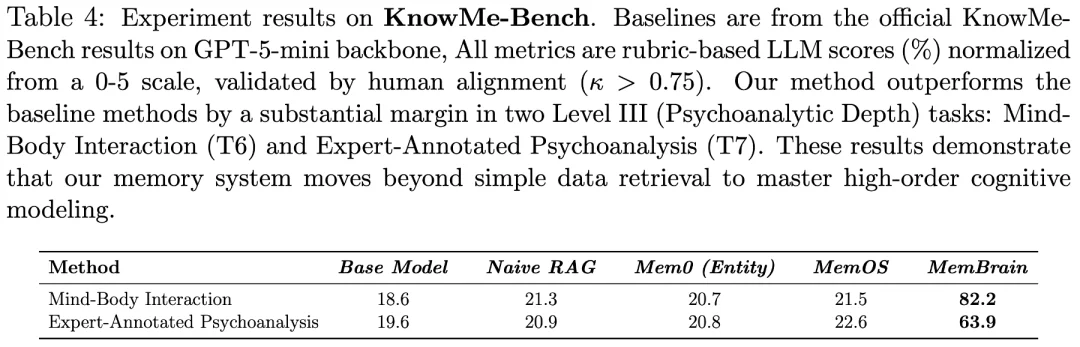
此外,在 Hugging Face 广受关注的 Knowme-Bench 基准中,MemBrain 的实验结果表明,在 KnowMeBench Level III: Psychoanalytic Depth:Mind-BodyInteraction (T6),Expert-Annotated Psychoanalysis (T7) 难度等级最高的两个评测中更是比现有评测结果大幅提升超 300%,显示出 MemBrain 在高阶认知理解任务中显著的性能优势。Knowme-Bench 的核心挑战在于要求模型超越基础的精确记忆抽取,实现基于记忆内容的深层分析与复杂推理。
让记忆系统学会 "主动思考"
现有记忆系统在检索机制上普遍采用多路召回与重排架构(如全文检索、向量检索与图数据库的混合检索)—— 虽然配备了一整套 "豪华工具箱",但性能很大程度上取决于预设的分支参数,系统只能按预设轨道上 "照章办事"。尽管 EverMemOS 等前沿工作尝试引入查询改写(Query Rewriting)来适配多维度的查询需求,但这种单轮触发机制本质上还是 "单次触发" 的被动响应,难以实现真正的自适应检索。
MemBrain 的破局点在于用 Agentic 思路重构整个记忆系统。它将实体提取、会话摘要生成、记忆合并、冲突消解、分层记忆压缩等核心环节,拆解为独立且能协同作战的子 Agent—— 每个 Agent 专注自己的领域,但能根据任务动态配合。传统检索手段被 "降维" 为可调用的工具,真正的决策权交给了 Agent 之间的协作调度。
这种设计让部署灵活度直接拉满,还为异步记忆更新等日常工程需求预留了充足的扩展空间。
实体与时间:记忆管理的 "细节功夫"
精确提取历史文本中的实体与时间戳信息,是记忆系统实现关联分析与逻辑推理等高阶任务的基石。然而,现有方案在长时记忆的数据组织模式与细粒度上下文管理上仍显粗放 —— 时间信息捕捉不够完整、实体关联不够清晰、时间与事件的组织方式不够规范,这些细节上的不足限制了系统在复杂下游场景中的性能上限。
MemBrain 在前沿探索的基础上,针对长时上下文进行了深度的结构化工程优化。通过精细化的字段设计与上下文对齐机制,在实体提取完整性、时间戳规范化、数据结构清晰度等多个细节层面持续打磨,确保了记忆数据的高保真度与检索时的高度相关性。
适配大模型原生能力,深度参与推理
很多研究者喜欢用图结构来描绘记忆网络 —— 毕竟现实世界中,实体之间的关系确实错综复杂。
但这里有个有趣的矛盾:当下主流基座模型的底层架构,更适配线性或树状的信息排列方式。这种架构范式与图结构表征之间的天然差异,带来的后果是:现有的图数据库记忆系统在查询时,还是主要依赖传统图算法在唱主角,LLM 只能在一旁 "看戏",无法深度参与图推理。结果就是经常发生明显的语义转化损耗 —— 就像信息在传递过程中不断 "失真"。这无疑限制了 LLM 在复杂记忆推理场景中的真正实力。
最近备受关注的 Anthropic 推出的 Skill 机制,采用 "一切皆文件" 的设计哲学,把文件按需加载到上下文中。MemBrain 通过优化这一思路:虽然不用图结构,但把相关信息组织成可按需加载的 "语义单元"—— 就像把散落的知识点打包成一个个 "信息包",LLM 可以直接打开阅读,而不需要经过复杂的图算法转换。这样既保留了信息之间的关联关系,又让 LLM 能够深度参与推理,在推理时随用随取,灵活检索和组装知识。
是什么让这样一支成立不久的初创团队半路杀了出来,一举拿下多项基准的 SOTA?
Feeling AI 的创始人戴勃,是生成式 AI 领域的青年科学家、香港大学的助理教授,他曾在 NTU 和上海 AI 实验室任职,担任生成式 AI 团队的负责人。戴勃博士毕业于香港中文大学,在开源社区爆火的视频生成模型 AnimateDiff,以及 CityNeRF、Scaffold-GS 这几项工作都是他的代表作,AnimateDiff 可以说引领视频生成走向商业化的关键工作,据传多家大厂曾开出天价吸引其加入。
但低调创业的戴勃并没有选择在视频生成领域下钻,而是在 2024 年就押注了世界模型。戴勃带领的核心团队来自清华、港中文、NTU 和米哈游、英伟达、商汤等,团队更是不乏毕业于清华姚班的天才少年。
但作为国内最早在世界模型和 3D 动态交互方向进行尝试的团队,为什么要做 Agentic Memory?答案或许藏在其官方发布的一张海报中。
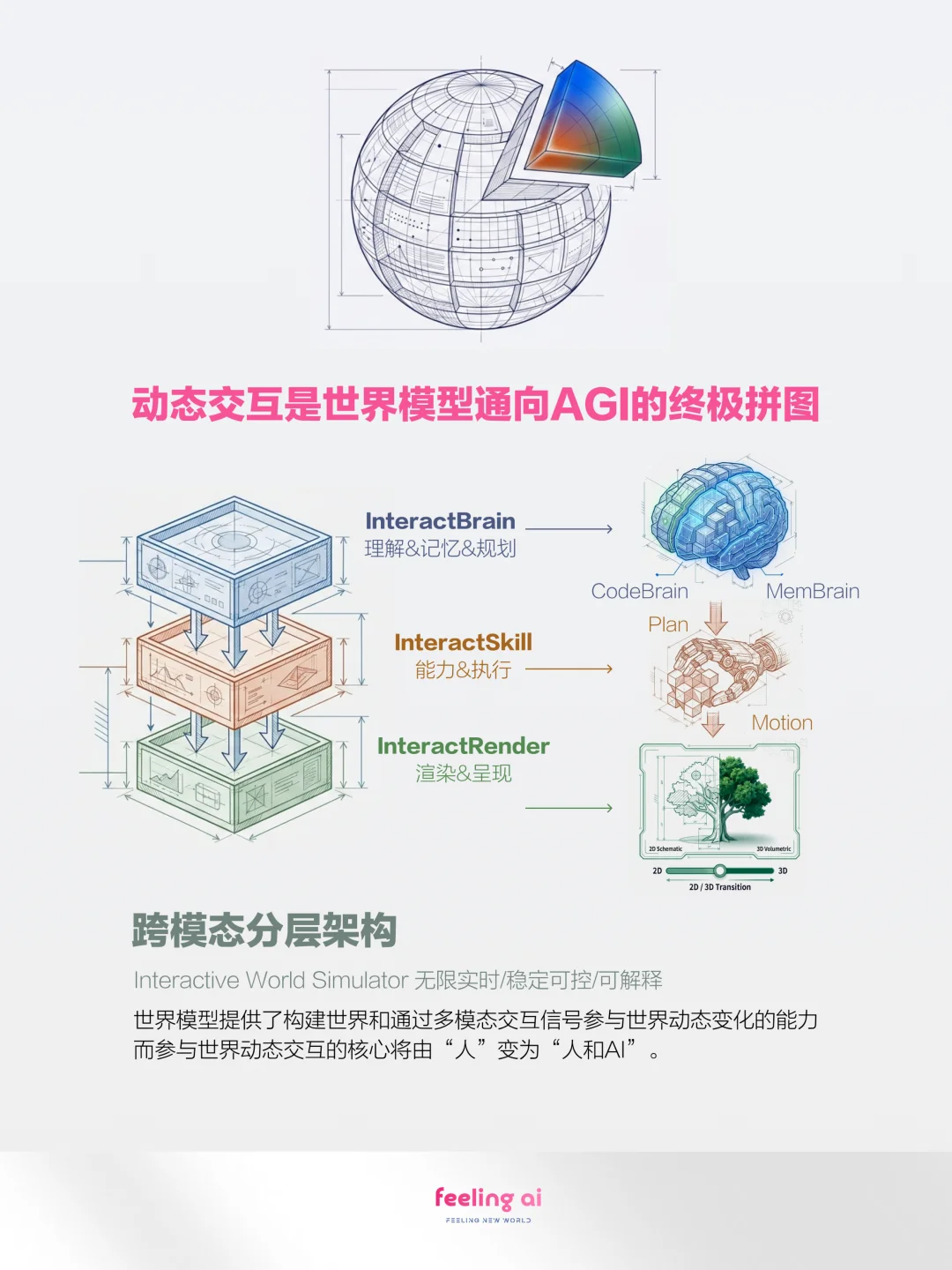
他们把世界模型的实现分成了 InteractBrain(理解、记忆与规划),InteractSkill(能力与执行)和 InteractRender(渲染与呈现)三层,MemBrain 所代表的记忆能力则是 InteractBrain 的关键组成部分之一。当 OpenAI-o1、DeepSeek-R1 为 AI 带来的推理能力还不足以为物理世界的智能系统达成闭环时,机器像人类一样与动态变化的物理世界共存的能力就至关重要。
也许 Feeling AI 试图回答的正是 —— 如何让世界模型真正走向动态世界的智能交互,而与世界动态交互的核心也将由 “人” 变为 “人和 AI”。如此看来,在 Agentic Memory 的能力上为世界模型构建护城河也十分合理。
随着 Mem0 等项目在 GitHub 上迅速走红,DeepSeek 的论文剑指大模型记忆,以及 OpenAI 频繁更新其 “Memory” 功能接口,一个明确的信号已经释放:在 2026 年的 AI 版图中,谁能解决 Agent 的 “随时失忆症”,谁就能掌握通往 AGI 的下一把钥匙。
如果说算力是 Agent 的心脏,那么 Memory 正被公认为它的灵魂,智能大脑正在走向卓越记忆能力的比拼。正如 Nvidia 科学家 Jim Fan 所言,Agent 的下一步演进不在于参数量的无限堆砌,而在于通过高效的技能库索引与自我反思机制,让 AI 在面对全新、更复杂任务时,能够直接检索并复用此前探索中积累的技能与经验教训。随着 Memory for Agentic AI 成为基础设施层的核心标配,我们正在见证 AI 从 “无状态” 的单次调用,向 “有意识” 的持续进化跨越。
强大的记忆能力以及适配模型原生的层级化记忆系统,意味着 Agentic AI 正从模型能力逐步走向用户体验层面的全面升级,这也将成为 AI 与用户共生、共创的新起点。
MemBrain1.0 Github https://github.com/feelingai-team/MemBrain
文章来自于“机器之心”,作者 “机器之心编辑部”。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
