# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
训练一个生成模型是很复杂的一件事儿。
从底层逻辑上来看,生成模型是一个逐步拟合的过程。与常见的判别类模型不同,判别类模型通常关注的是将单个样本映射到对应标签,而生成模型则关注从一个分布映射到另一个分布。
从大家最熟悉的扩散模型说起,扩散模型,包括一些基于流的对应方法,通常通过微分方程(随机微分方程 SDE 或常微分方程 ODE)来刻画从噪声到数据的映射。
但训练扩散模型是一件费时费力的事情,因为其核心计算过程是一个迭代过程。
为了尽可能提升生成模型的效率,大量工作致力于减少扩散的步数。比较有代表性的一类是蒸馏方法,将一个预训练的多步模型蒸馏为单步模型。另一类研究则尝试从零开始训练单步扩散模型。例如:
变分自编码器(VAE)通过优化证据下界(ELBO)进行训练,该目标由重建损失和 KL 散度项组成。在采用高斯先验时,经典 VAE 本身就是一步生成模型。然而,在当今主流应用中,VAE 往往使用由扩散模型或自回归模型学习得到的先验,此时 VAE 更多地充当分词器的角色。
正则化流(Normalizing Flows, NFs)学习从数据到噪声的映射,并通过最大化样本的对数似然进行训练。这类方法要求模型结构可逆,且能够显式计算雅可比行列式。从概念上看,正规化流在推理阶段是一步生成器,生成过程通过网络的逆映射完成。
这些方法仍然无法摆脱持续迭代的训练过程的桎梏。
相比之下,何恺明研究团队的最新工作提出了一种在概念上完全不同的范式「漂移模型(Drifting Model)」,不依赖扩散模型与流模型中常见的微分方程表述,天然支持一步推理,并构建了一种训练目标,使得神经网络优化器能够直接推动分布的演化。

论文标题:Generative Modeling via Drifting
论文链接:https://arxiv.org/abs/2602.04770v1
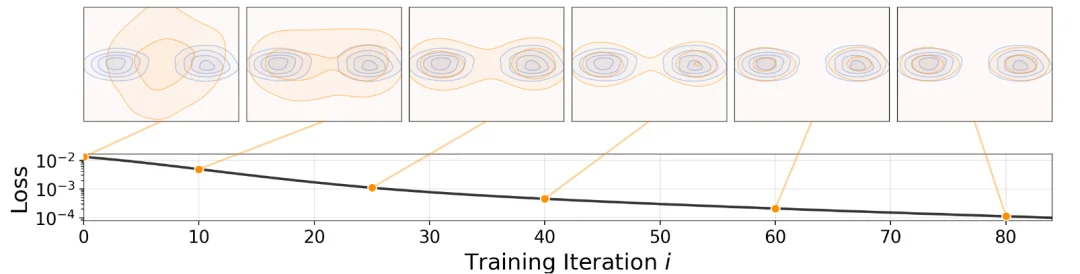
漂移模型训练示意图
在本文中,研究团队提出了一种新的生成建模范式 —— 漂移模型。

为了驱动训练阶段推送分布的演化,研究团队引入了一个漂移场(drifting field)来控制样本的运动。该漂移场依赖于生成分布和数据分布。当这两个分布一致时,根据定义漂移场为零,系统达到平衡态,样本不再发生漂移。
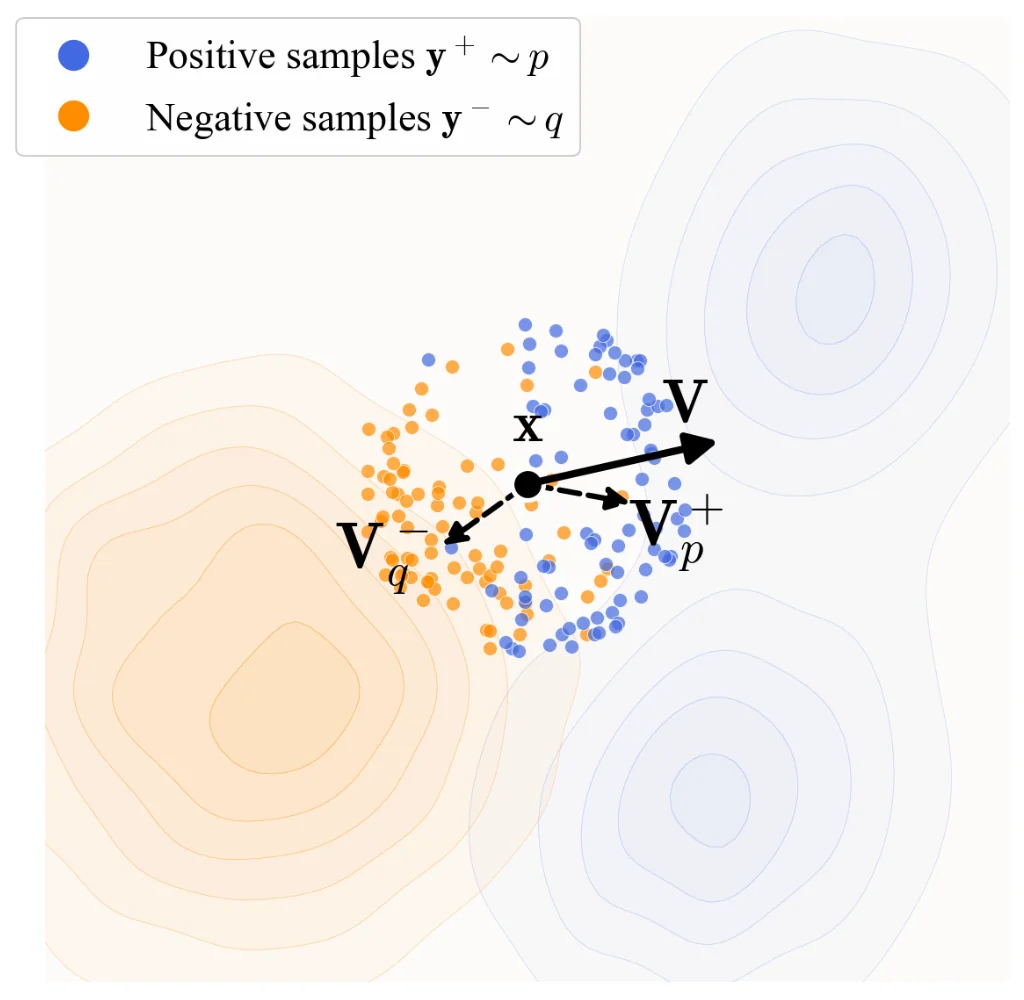
漂移场示意图:生成的样本 𝐱 (黑色)根据向量 𝐕=𝐕p+−𝐕q− 进行漂移。这里, 𝐕p+ 是正样本(蓝色)的均值偏移向量, 𝐕q− 是负样本(橙色)的均值偏移向量。 𝐱 被 𝐕p+ 吸引,同时被 𝐕q− 排斥。
基于这一表述,研究团队提出了一种简单的训练目标,用于最小化生成样本的漂移。目标函数如下:
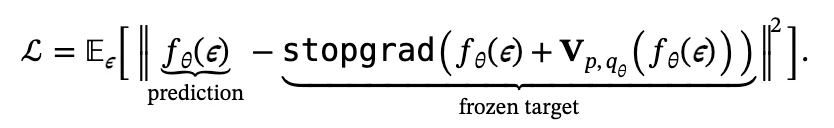
该目标会诱导样本产生移动,并通过迭代优化过程(如 SGD)推动底层推送分布的演化。
在这里,我们不再描述漂移模型的细节,感兴趣的读者请参阅原论文。
实验验证涵盖多个领域和规模,为该方法的有效性提供了全面证据。
漂移模型天然支持单步生成(1-NFE),并在实验中展现出强大的性能。在 ImageNet 256×256 上,在标准的潜空间生成协议下,研究团队获得了 1-NFE FID = 1.54,在单步生成方法中取得了新的 SOTA,且该结果即便与多步的扩散模型相比也依然具有竞争力。
进一步地,在更具挑战性的像素空间生成协议(即不使用潜变量)下,本文方法达到了 1-NFE FID = 1.61,显著优于此前的像素空间方法。这些结果表明,漂移模型为高质量且高效率的生成建模提供了一种极具潜力的新范式。

上图展示了一个二维玩具示例:在三种不同初始化条件下,生成分布 q 在训练过程中逐步演化,并最终逼近一个双峰分布 p。在这一玩具实验中,本文的方法能够在不出现模式坍塌的情况下逼近目标分布。即使在 q 被初始化为坍塌到单一模态的状态(图中下方所示)时,这一性质仍然成立。
这为本文的方法为何对模式坍塌具有鲁棒性提供了直观解释:当 q 坍塌到某一个模态时,目标分布 p 中的其他模态仍会对样本产生 “吸引力”,促使样本继续移动,从而推动 q 持续演化。
该实验展示了对多模态目标分布的稳健收敛,同时避免了模式崩溃,即使在从崩溃状态初始化的情况下。
此外,研究团队在 ImageNet 256×256 上评估了所提出的模型。
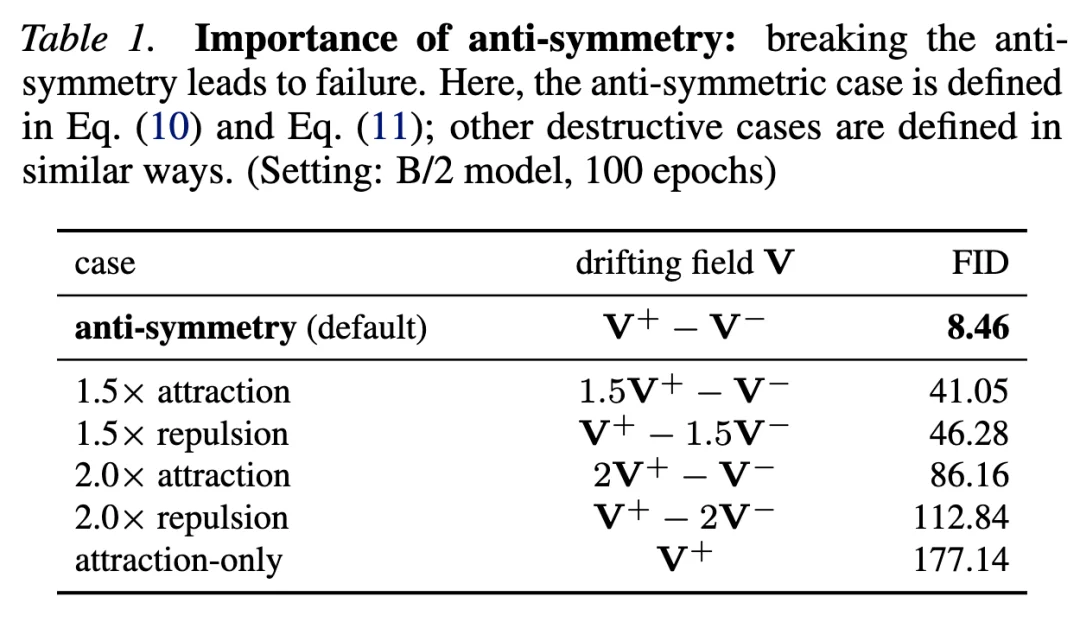
在表 1 中,研究团队进行了一个破坏性消融实验,刻意打破这一反对称性设定。结果表明:满足反对称性的情况(即默认设置)表现良好,而其他破坏该性质的设定则性能灾难性崩溃。

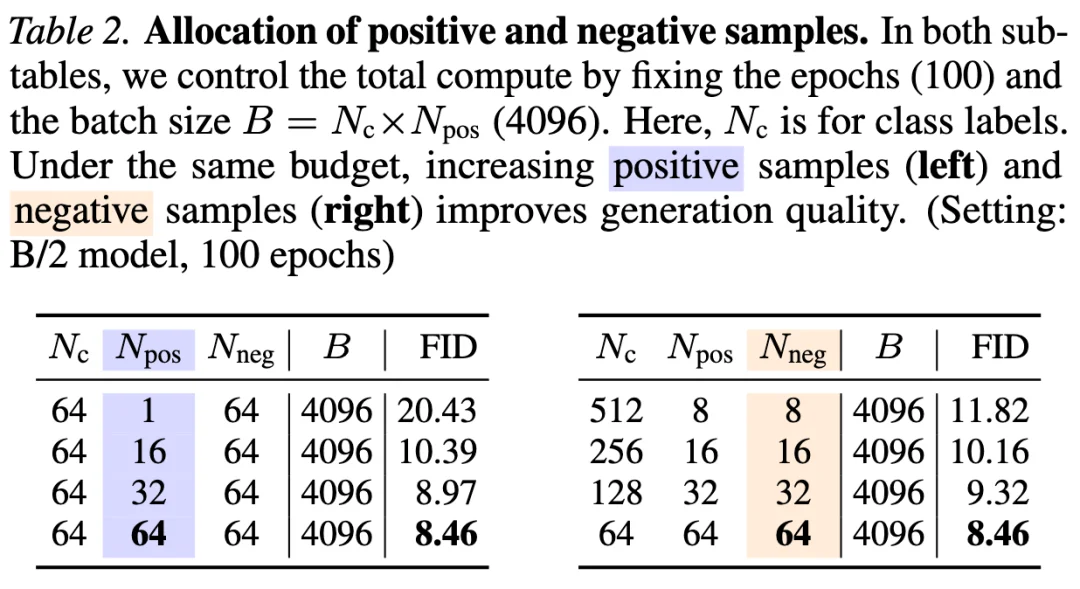

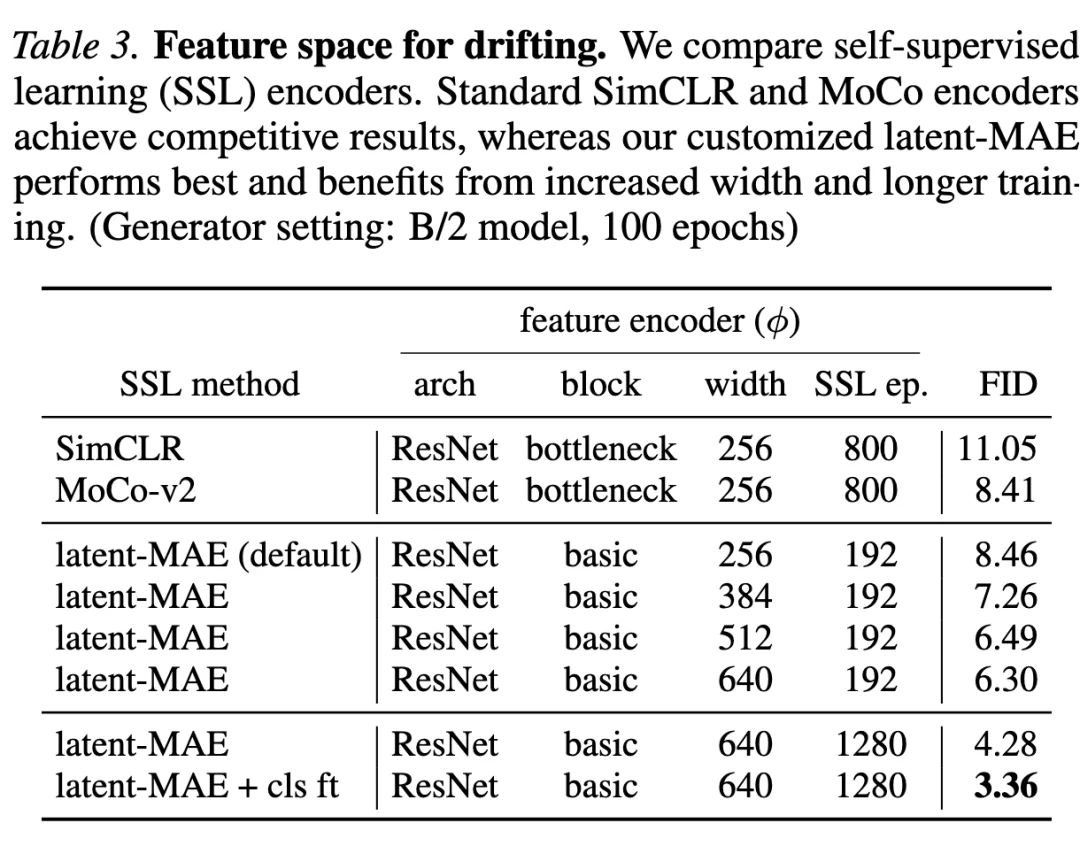
表 3 的对比结果表明,特征编码器的质量起着至关重要的作用。
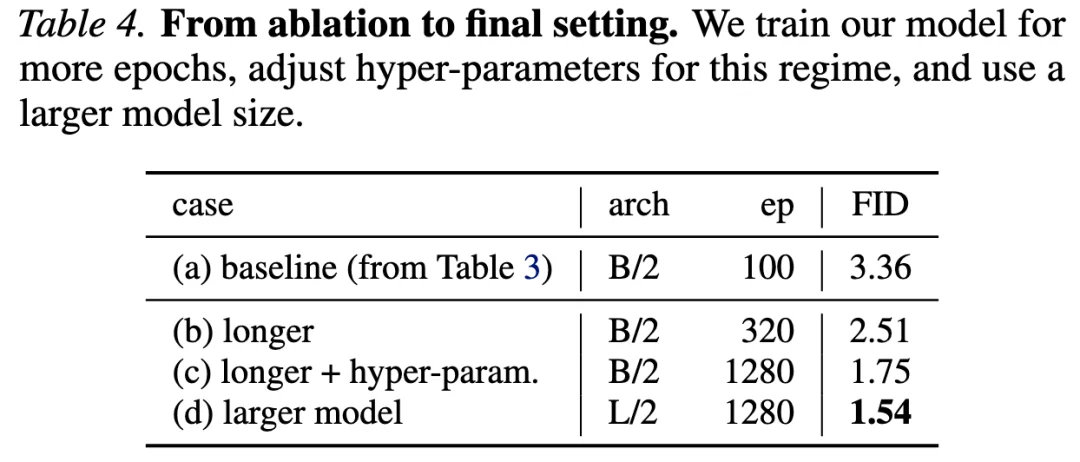
研究团队还训练了更强的模型变体,并在表 4 中进行了汇总;与以往方法的对比见表 5。
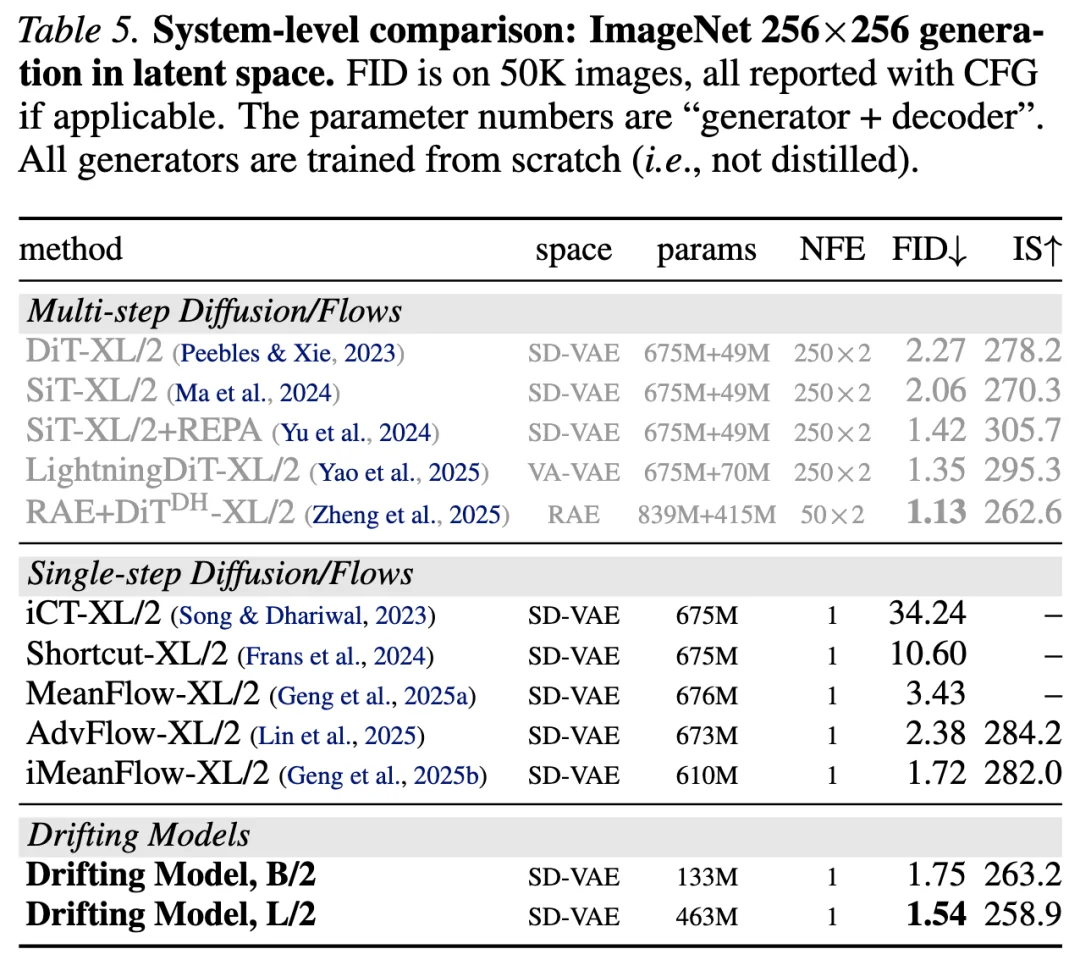
本文方法在原生 1-NFE 生成条件下取得了 1.54 的 FID,超过了此前所有基于扩散 / 流轨迹近似的 1-NFE 方法。值得注意的是,本文中的 Base 尺寸模型即可与此前的 XL 尺寸模型相竞争。
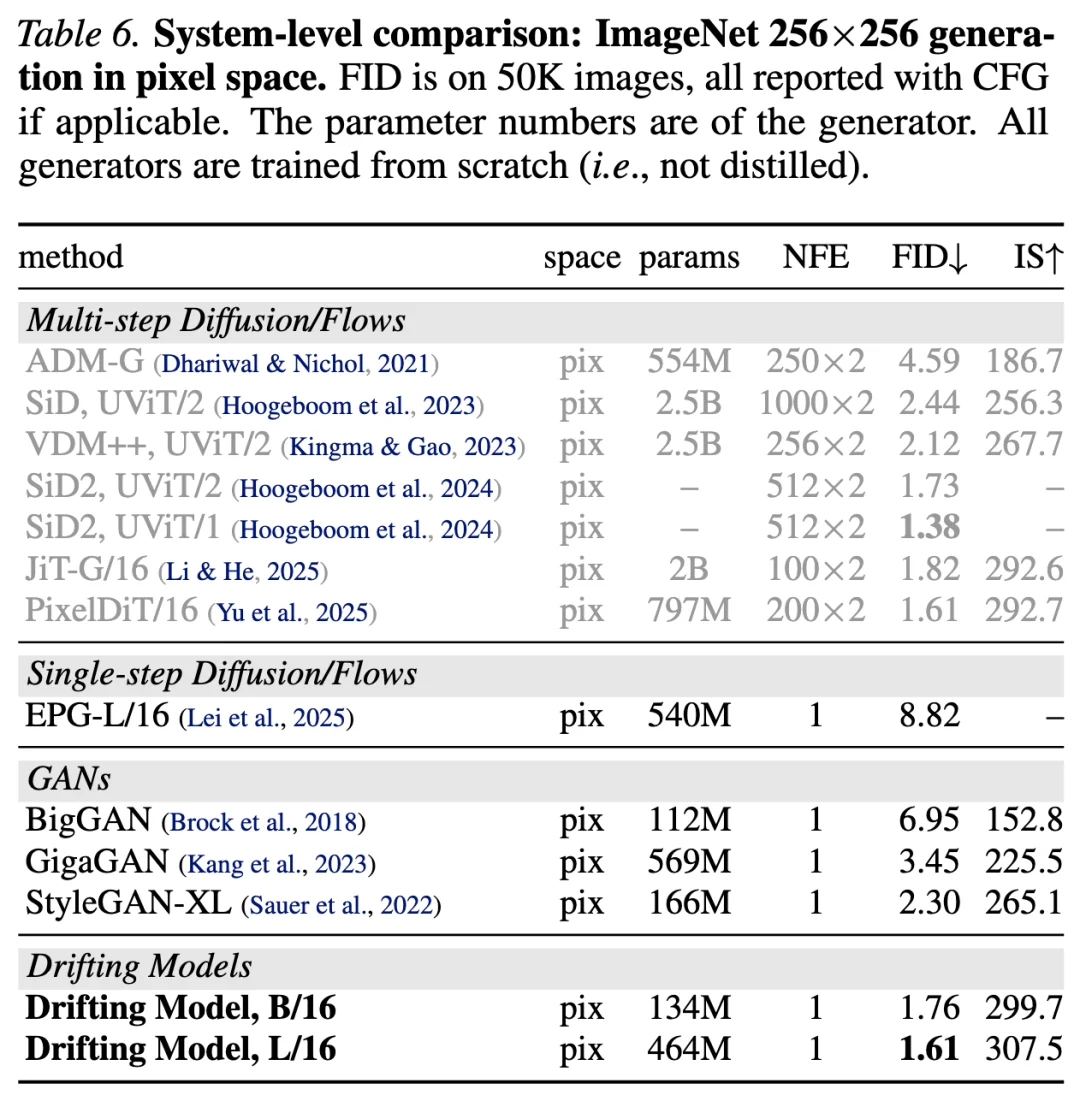
表 6 对比了不同的像素空间生成器。本文的一步像素空间方法取得了 1.61 的 FID,在性能上超过或可与此前的多步方法竞争。与其他一步像素空间方法(如 GAN)相比,本文的方法仅使用 87G FLOPs 即可达到 1.61 FID;而 StyleGAN-XL 则需要 1574G FLOPs 才能达到 2.30 FID。
漂移模型解决了生成式 AI 中质量与效率之间的基本权衡问题。传统的优质模型,如扩散模型,取得了优异的结果,但在推理过程中计算成本高昂。这项工作表明,在大幅降低计算需求的情况下,可以达到相似的质量,有可能使以前受推理速度限制的实时应用成为可能。
该方法还强调了生成建模中鲁棒特征表示的重要性。预训练特征提取器的关键作用表明,自监督学习的进步直接有益于这一范式,在表示学习和生成之间建立了协同效应。
该方法在不同领域(从高分辨率图像合成到复杂的机器人控制)的成功表明,通过漂移场进行分布演变的核心原理可能广泛适用于各种生成任务,为高效生成建模开辟了新的研究方向。
更多细节,请参阅原论文。
文章来自于微信公众号 “机器之心”,作者 :“机器之心”


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
