# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
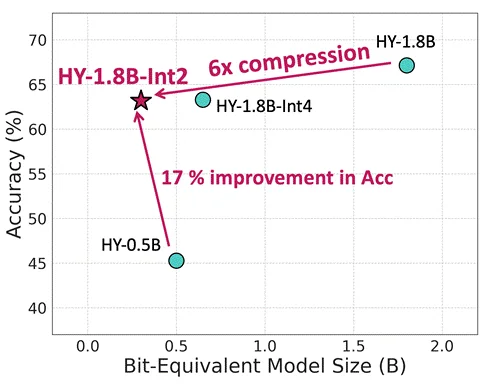
等效参数量仅0.3B,内存占用仅600MB,更适合端侧部署还带思维链的模型来了。
腾讯混元最新推出面向消费级硬件场景的“极小”模型HY-1.8B-2Bit,体量甚至比常用的一些手机应用还小。
该模型基于混元团队首创的产业级2Bit端侧量化方案,通过对此前混元的小尺寸语言模型——HY-1.8B-Instruct进行2比特量化感知训练(QAT)产出,对比原始精度模型等效参数量降低了6倍,在沿用原模型全思考能力同时,在真实端侧设备上对比原始精度模型生成速度提升2—3倍,可大幅提升使用体验。
随着大语言模型普及,如何将模型在比如手机、耳机或者智能家居设备应用,成为业界难题,尤其不少应用对模型的离线部署、私密性等都有更高的需求,这就需要更多能够在端侧运行的又小又强的模型。
端侧部署的展开,本质上是一条在“小而精,快而准”的艰难探索之路,我们既需要模型足够聪明,能应对千变万化的真实需求,又必须将它约束在极其有限的硬件资源内部署并快速推理,这就好像在给模型进行“减脂增肌,减重提质”。

比特(Bit)是计算机存储的最小单位,1比特能表示2种状态(0或1),2比特能表示4种状态,依此类推,一般模型的精度有2比特、4比特、8比特、32比特等表示方法,数值越大模型的精度更高,所占的内存就越大。
虽然2比特量化的精度损失较大,但通过QAT和先进的量化策略,已经能让2比特模型接近全精度模型的性能。
在模型能力方面,对比4比特PTQ模型版本数学、代码、科学等指标上表现相当,实现了“小而强”的设计目标。同时,这一模型已经支持了gguf格式,在真实端侧设备上对比原始精度模型生成速度提升2—3倍,可以大幅提升用户使用体验。
此外,HY-1.8B-2Bit模型还沿用了Hunyuan-1.8B-Instruct的全思考能力,用户可以灵活使用,为简单的查询提供了简洁的思维链,为复杂的任务提供了详细长思维链,用户可以根据其应用的复杂性和资源限制灵活地选择这两种模式。
技术上,量化作为大模型部署上线不可或缺的一环,肩负了降低部署成本与保精度的使命,大部分情况下对于int4、int8、fp8的压缩精度要求,采用PTQ量化策略即可实现几乎无损,但随着原始模型大小的缩小、压缩bit数的进一步降低,PTQ带来的量化损失是巨大的。
因此,对于原始模型大小只有1.8B,量化bit数只有2bit的HY-1.8B-2Bit,混元团队采用了量化感知训练策略,这显著提升了量化后模型的性能。
腾讯混元还通过数据优化、弹性拉伸量化以及训练策略创新三个方法来最大限度的提升HY-1.8B-2Bit的全科能力。
对不同类别的数据进行实验表明,提高理科数据占比和加入适当的长文数据能够明显提高QAT后模型的全面能力,推测这是由于量化后的模型对于逻辑推理和长文的损失是要远远大于其他Topic。因此,本次模型训练强化了这部分数据的比例作为HY-1.8B-2Bit的训练数据集。
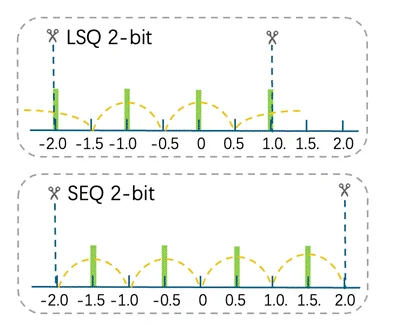
针对2-bit极低精度的挑战,HY-1.8B-2Bit在量化算法上进行了差异化布局。为了规避高bit QAT中常见方案在超低比特下导致的精度崩塌,结合前序研究,应用了“弹性拉伸量化”(SEQ)策略。
SEQ策略的核心逻辑是摒弃了传统包含0值的非对称映射(如INT2{-2, -1, 0, 1}),转而采用{-1.5, -0.5, 0.5, 1.5}的对称映射方案。这一改进旨在通过平移量化重心,解决2-bit下有效能级受限的问题,从而最大化动态范围的覆盖能力。
配合算法对量化区间缩放因子的自适应微调,该方案显著缓解了极低精度下的信息流失,为HY-1.8B-2Bit在有限位宽下捕捉高维特征分布提供了坚实的算法支撑。
训练感知量化,在训练阶段就让模型提前适应权重被量化到更低比特数下产生的精度损失,腾讯混元团队选定Instruct模型而不是预训练权重作为QAT模型的初始化权重,以节省训练token使模型更快收敛。
2bit量化和高bit量化(3bit以上)在QAT过程中存在显著差异,其根本原因在于3bit以上的量化信息损失并不大,QAT主要是在在“补偿”精度损失,模型权重保持在原始分布附近;而2bit量化中,QAT更多的是一种“重构”过程,权重分布会发生剧烈变化以适应新的低精度表示。因此,训练配置的搜索尤为重要。
为了快速锁定正确的训练配置,通过大量的风洞试验在小规模数据下(10B)试验确定了最优的超参配置,并通过不同token数量的对比实验确定最低限度token,以追求效率与精度的最佳平衡。最终,训练HY-1.8B-2Bit所消耗的token数量仅为Bitnet-2B的10%,这意味着低比特模型的QAT训练不需要从预训练开始做起,使用更少的训练成本就可以获得极低比特版本的模型,为极低bit的模型生产规模化带来信心。
部署方面,腾讯混元提供了HY-1.8B-2Bit的gguf-int2格式的模型权重与bf16伪量化权重,对比原始精度模型,HY-1.8B-2Bit实际模型大小直降6倍,仅有300MB,能够灵活用于端侧设备上。该模型也已在Arm等计算平台上完成适配,可部署于启用Arm SME2技术的移动设备上,并实现高效运行。
在MacBook M4芯片上,HY-1.8B-2Bit固定了线程数为2测试了不同窗口大小下的首字时延和生成速度,模型选定fp16、Q4、HY-1.8B-2Bit三种gguf格式作为对比,首字时延在1024输入内能够保持3~8倍的加速,生成速度上常用窗口下对比原始模型精度,HY-1.8B-2Bit能够实现至少2倍稳定加速。
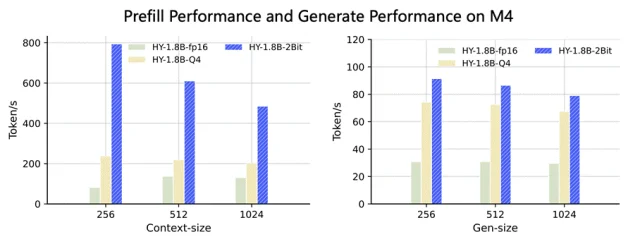
在天玑9500上同样进行了测试,对比HY-1.8B-Q4格式首字时延能够加速1.5~2倍,生成速度加速约1.5倍。
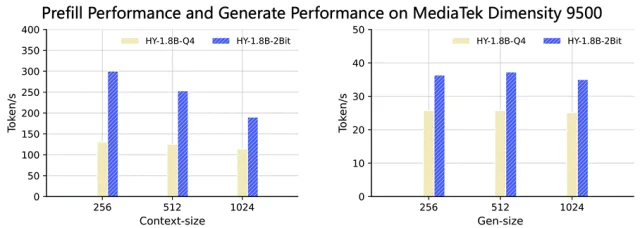
为在边缘设备上实现大语言模型的灵活部署,HY-1.8B-2Bit采用了极低比特量化技术,在保持与INT4-PTQ方法相当模型性能的同时,实现了在端侧设备上的高效稳定推理。
当前,HY-1.8B-2Bit的能力仍受限于监督微调(SFT)的训练流程,以及基础模型本身的性能与抗压能力。针对这一问题,混元团队未来将重点转向强化学习与模型蒸馏等技术路径,以期进一步缩小低比特量化模型与全精度模型之间的能力差距,从而为边缘设备上的大语言模型部署开拓更广阔的应用前景。
项目链接:
https://github.com/Tencent/AngelSlim
模型地址:
https://huggingface.co/AngelSlim/HY-1.8B-2Bithttps://huggingface.co/AngelSlim/HY-1.8B-2Bit-GGUF
技术报告地址:
https://huggingface.co/AngelSlim/HY-1.8B-2Bit/blob/main/AngelSlim_Technical_Report.pdf
文章来自于微信公众号 “量子位”,作者 :“量子位”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
