# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
谁能想到啊,在自回归模型(Autoregressive,AR)当道的现在,一个非主流架构的模型突然杀了回马枪——
被长期视为学术玩具的扩散语言模型,直接在复杂编程任务中飙出了892 tokens/秒的速度!

你没看错,当主流大模型还在以几十token的速度逐字蹦词时,这个非主流模型已经在100B参数规模上,跑出了如此的速度。
2025年,蚂蚁集团资深技术专家赵俊博曾经带着LLaDA2.0登上量子位MEET大会的舞台,而如今,他们的最新版本LLaDA2.1来了,蚂蚁技术研究院重磅开源!

三个月前,在LLaDA2.0时代,这更多是一个充满挑战的研究性模型。
而这一次,LLaDA2.1的诞生,标志着这个路线的历史性转折。它不再只是一个“学术研究”,而是真正可用、甚至在效率上更为优越的强大工具。
那么在整个行业都在卷更大的自回归模型时,蚂蚁到底是怎么低调修了另一条“能跑通的高速公路”的?
接下来,我们就再一起扒一扒这个非共识技术背后的原理。
在深入技术之前,我们先得聊聊为什么现在的ChatGPT、Claude们总是慢条斯理。
因为它们几乎全部采用自回归架构,这种模式如同一个不能打草稿的考生,必须从左到右、一字一句地生成文本,写完即定稿,无法回头修改。
而扩散模型的理论优势在于并行,可以同时处理所有文本位置,理论上能一次成篇,拥有巨大的速度潜力。
但扩散语言模型在早期一直有个致命伤,那就是容易胡说八道,且缺乏全局一致性。因为并行生成时,各个部分可能是各玩各的,导致前后文逻辑不通。
为此,蚂蚁的LLaDA2.1先亮出了第一个技术杀手锏:
基于可纠错编辑的底层能力,LLaDA2.1引入了灵活的双模式解码策略,实现了单个模型,同时支持极速与质量两种模式:
在此之前,LLaDA-MoE和LLaDA2.0需要二次开发提供额外的加速版本,比如基于路径蒸馏的加速等;这类加速版本因为非联合训练优化,虽然实现了对基础版本的一定加速,但是精度掉点普遍严重;同时一个模型多个版本,也增加用户选择的难度以及模型管理的成本。
单模型双模式,避免了上述问题。用户可以根据具体需求,仅需一条config就能实现模式切换。
这种设计标志着LLaDA系列从研究模型向实用产品的关键转变。
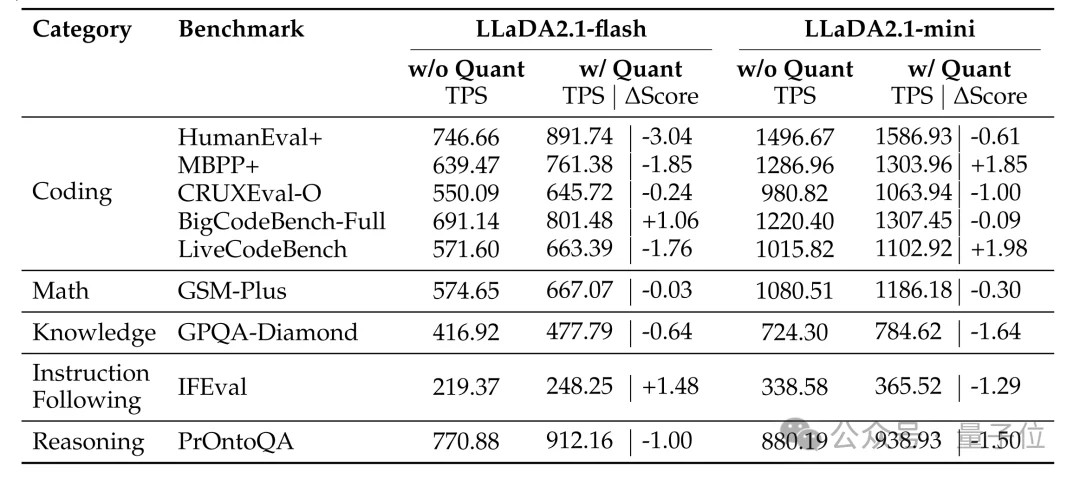
技术报告显示,在HumanEval+编程基准上,LLaDA2.1-flash(100B)在Speedy Mode下达到892 TPS的峰值速度,而Quality Mode则在多项推理任务上超越了前代模型。
为了更好的理解双模式背后的机制,我们可以回忆一下自己写作的流程。
自回归模型像是一个不允许带草稿纸、不允许带提纲的作者,它下笔无悔,不允许修改自己写好的内容。
但现实中,大部分情况下我们可能是先有了想法去写草稿,哪怕有错别字,先动笔写着;写完之后,我们再回头细读一遍,把不通顺的、有错别字的地方改掉。
LLaDA2.1工作原理正是如此,引入的机制叫做可纠错编辑(Error-Correcting Editable,ECE)。
它的推理过程被分为了两个阶段:
技术报告中的一个例子生动说明了其价值。
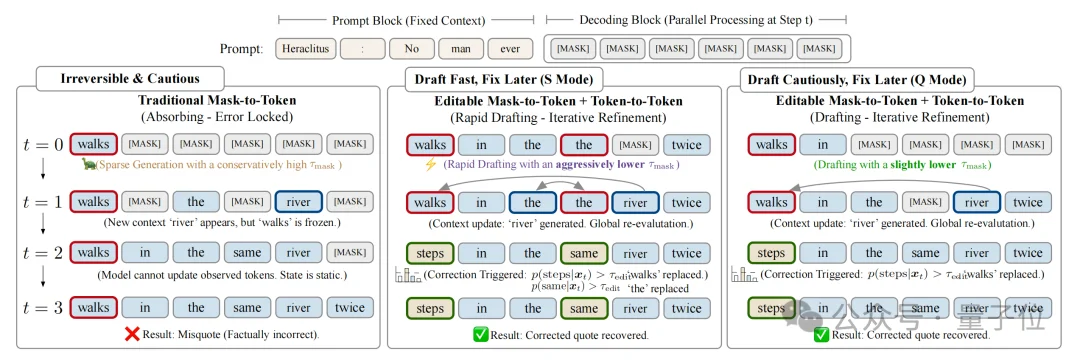
当模型尝试补全赫拉克利特名言“No man ever steps in the same river twice”时,传统扩散模型在早期步骤错误生成了“walks”,由于状态冻结,最终输出错误的“walks in the same river twice”。
而LLaDA2.1在后续步骤中检测到“steps”的置信度更高,果断将“walks”替换为“steps”,成功恢复正确引文。
这种允许自我修正的能力,从根本上解决了扩散模型的曝光偏差问题。它让模型敢于在初稿阶段追求速度,再通过编辑阶段保障质量。
它在毫秒级的闪电采样中完成了“草稿”到“正卷”的华丽转身,不再被困在序列的起点,而是直接站在全局的高度,去编辑、去重塑、去定义AGI时代的推理新范式。
这是第一次在扩散架构上实现了速度与质量的解耦。
如果说可纠错编辑解决了怎么生成的问题,那么强化学习则是解决了生成得好不好的问题。
但此前,在扩散模型上应用RL曾被视为不可能的任务。
原因在于,自回归模型的序列似然可直接分解为token级概率乘积,而扩散模型基于块状采样(block-diffusion),序列级似然难以直接计算,导致传统策略梯度方法失效。
LLaDA2.1团队为此定制了EBPO(ELBO-based Block-level Policy Optimization)算法:
这是业界首次在100B规模扩散模型上成功实施大规模RL训练。
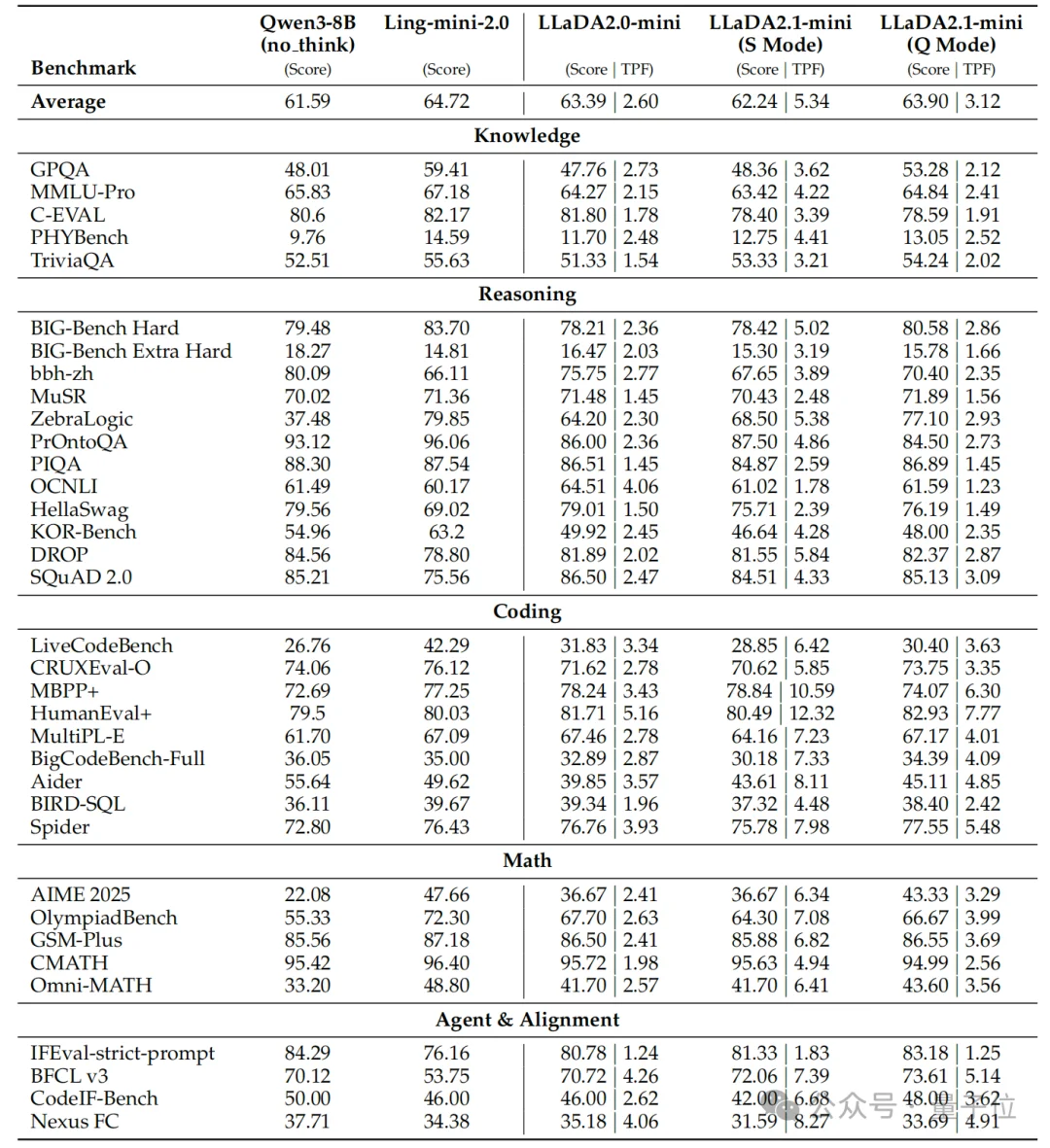
结果显而易见:LLaDA2.1在IFEval(指令遵循评估)、BFCL(函数调用)等对齐类任务上显著提升,证明扩散模型不仅能快,更能懂你。
正如我们刚才提到的,LLaDA2.1百亿参数版本在处理HumanEval+等复杂编程任务时,实现了892 tokens/秒的峰值速度。
在同级别的基准测试中,这一速度表现已经对主流自回归架构形成了显著优势。
更值得关注的是,这种速度并非以牺牲质量为代价。
在涵盖知识、推理、代码、数学及指令遵循的33个权威基准测试 中,LLaDA2.1在质量模式下全面超越了前代LLaDA2.0。
即使在追求速度的极速模式下,其性能下降也微乎其微,真正做到了 “鱼与熊掌可以兼得”。
除此之外,团队还开源了16B的Mini版本,其在部分任务上的峰值速度甚至超过1500 tokens/秒,为更轻量化的部署提供了可能。
最后,LLaDA2.1背后的哲学也是值得说道说道。
它证明了一件事:
在大模型时代,有敢把非共识走到底的耐心,亦可取得胜利。
技术报告:
https://huggingface.co/papers/2602.08676
GitHub地址:
https://github.com/inclusionAI/LLaDA2.X
项目权重:
https://huggingface.co/collections/inclusionAI/llada21https://modelscope.cn/collections/inclusionAI/LLaDA21
文章来自于微信公众号 “量子位”,作者 “量子位”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
