# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
OCR模型究竟能干什么?干得怎么样?
2025年末2026年年初,科技圈最卷的技术无疑就是——O!C!R!

这不,就在前两天,智谱也下场整活儿了,发布了自家的「GLM-OCR」开源模型~
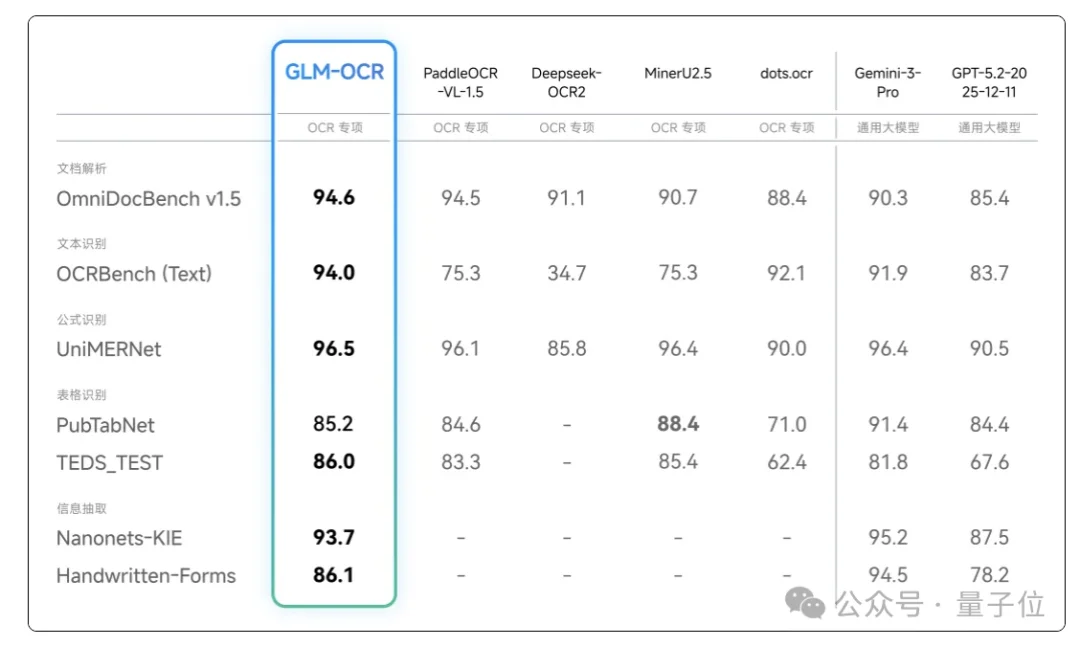
别看参数就0.9B,在OmniDocBench V1.5榜单上可是一通乱杀。
拳打Gemini-3-Pro!脚踢GPT5.2!(开玩笑
在手写体、代码文档、印章识别、跨单元格等场景的性能表现直通SOTA:
这两天处于工作的原因,我也深度上手使用了GLM-OCR一番,这波用下来的感受是:
在日常基础文档解析场景里用起来确实爽爽爽!
but,涉及到字迹不清晰或复杂排版的信息时,翻车现象还是有的……

顺带,帮友友们浅浅总结了一下GLM-OCR日常帮咱干哪些活儿最合适,让大家少踩点坑:
不多说了,也把我的实测体验过程放上来,大家都帮着看看~~~
实测前先给大家伙捋捋一捋,GLM-OCR有哪些极夯的能力(官方版):
(顺带一提:GLM-OCR支持vLLM、SGLang和Ollama部署,还开源了完整SDK与推理工具链,能直接调用)
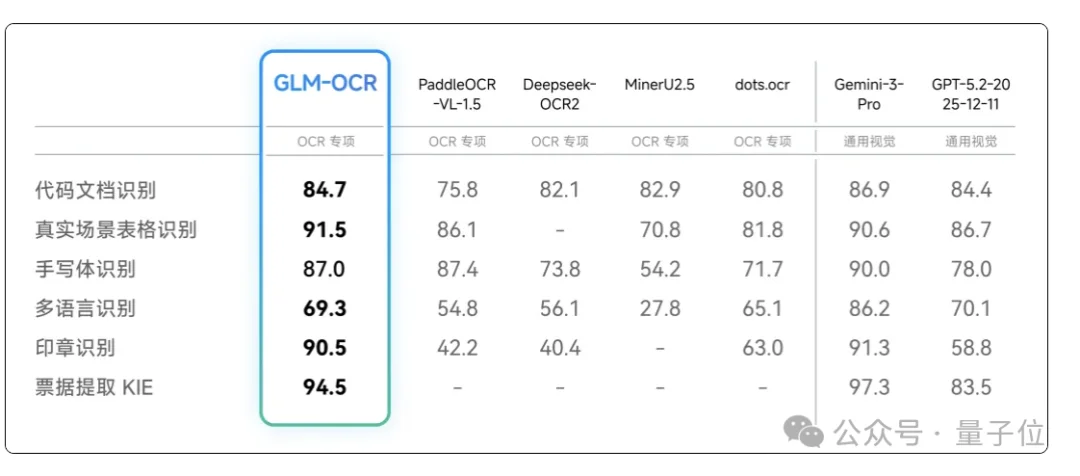
所以接下来,咱就直接围绕文本、表格、结构化提取三项核心能力实打实测一波!!!
大家发现没。
无论是扫描王这类老牌工具,还是后来出现的各种解析产品,我们判断文本识别靠不靠谱,其实就看一件事——
能不能把文字1:1原样还原出来。
听起来很简单吧,但真做起来,难点主要卡在两件事上:
第一,复杂、抽象字体能不能认对,手写体、潦草笔记、特殊符号,中英文混写时能不能稳稳识别。
第二,不同输入形态下稳不稳,照片、截图、扫描件清晰度和噪点差异很大,能不能在各种输入形态下都保持准确,才是真本事。

我们先来测一个简单点的——
看看在普通纸质形态下,GLM-OCR对的「手写解析」能力表现咋样~
这次我喂给GLM-OCR的,是我手写的一道家长、老师、学生听了都要头皮一紧的潦草手写版「多步骤公式题」:

先来唠唠不错的地方。
在这张图片里,一共涉及60多个「汉字+数学公式」混排符号,GLM-OCR给出的整体识别准确率大约在96%左右。
放在手写场景里,这个表现已经算是不错了。
咱再来看看里面的翻车点。
不难看出,图片中一共出现了3处解析错误, 当笔画写得比较潦草时,模型把X识别成了=,把成立识别成了或,另外不知道为啥还凭白无故多出来了一行公式……
为了验证是不是个例情况,我又把这张公式图原封不动丢给了ChatGPT-5.2,结果你猜怎么着:

翻车点几乎一模一样......
甚至更离谱的是GPT-5.2的错误率还略高于GLM-OCR,一共有4处解析错误……
其实也不算意外,毕竟潦草字迹一多,原本稳定的「笔画特征」就被打散了。
底层信息一模糊,模型自我纠错能力就容易跟不上…..

咱们再来试一个学生党和码农在生活工作中用的比较多的场景——「代码解析」。
这次我喂GLM-OCR的,是一篇论文里符号密度拉满的代码信息,变量、括号、注释全挤在一起(地狱级难度):
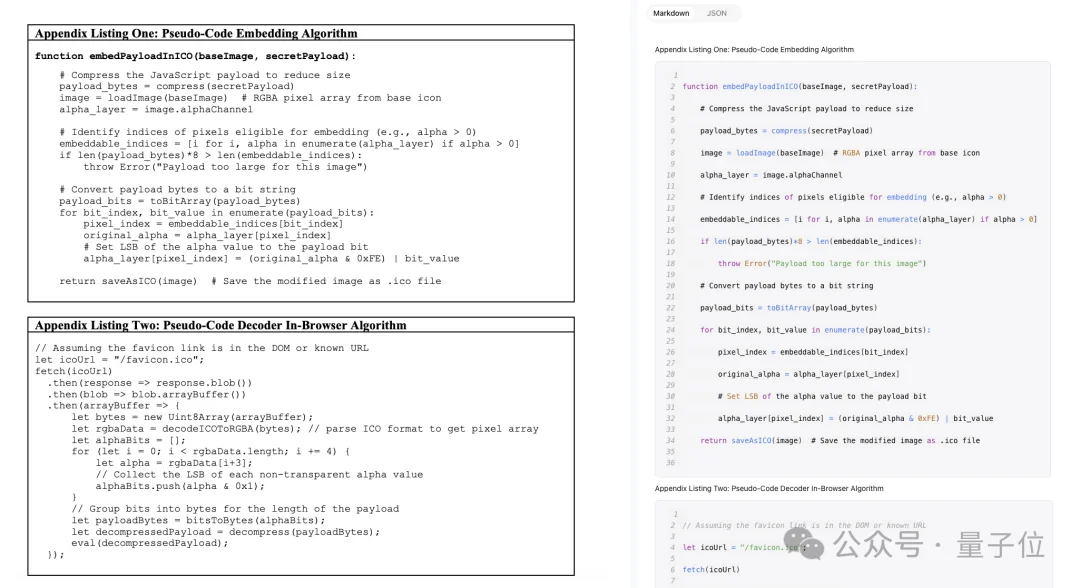
效果当然没得说,符号、缩进、排版都近乎1:1的还原了,注释位置也基本都对,蛮厉害蛮厉害。
但最让我感到意外的是,它能判断出我喂给它的是代码,输出时也会自动切到代码模式。
对于咱日常拿来做代码阅读、资料整理、论文辅助完全够用了。
测到这里,总感觉文字形式多少有点过于简单了,于是乎,我又来试了一把牛马党工作中经常用到的「盖章识别」:

过关!印章里的关键信息大概齐都能识别到位,唯一缺点是把印章外的「XX增值税电子专用发票」也一并识别了。

最后,咱再来试试GLM-OCR在「低质量输入」下的模型稳定性表现。
看看模型面对糊图的表现会不会“糊”。(doge)
这回,我喂给模型的是一份分辨率偏低、且肉眼看都有点吃力的「高糊」文字:

大家仔细看会发现,原图片本身是发糊、边缘不清、对比度低的,单个字的特征并不完整。
蛮不错的是,模型除了把「标签」错误解析为「标普」外,其他文字还原的都没啥问题,值得夸夸~
(诶,突然感觉还挺适合咱还原一些包浆&陈年的截图内容的???)
「表格解析」也是大家日常学习、工作、生活中用得非常多的一个大!场!景!
像论文里的数据表、课程表、成绩单、实验数据、预算清单、对账表……不管是学生还是打工人,几乎天天都能碰到~
其实对于OCR模型来说,表格解析能力表现我们可以大致概括为以下几个方面:
这回我直接找个比较能考察这些维度的「复杂工作表格」进行实测:
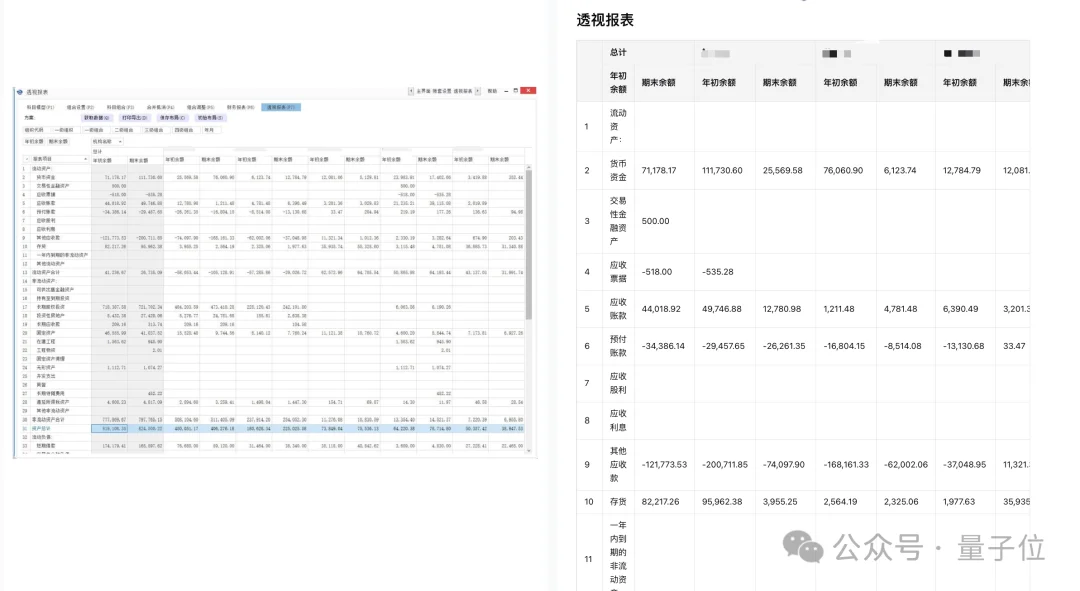
emm...怎么说呢,感觉表格解析能力的毛病和优点都很明显。
在表格中涉及大量金额、正负数和重复数值的情况下,模型依旧把绝大多数字准确还原了出来,这一点放在财务类报表里,其实已经很难得。
但相比这些优点,更值得拿出来说的,还是它暴露出来的核心问题——
行列对齐出错了。
模型把第一列的表头的「报表项目」直接吞掉了,以至于第一列整体发生错位,后面的行列关系也跟着一起乱了…
问题出现的原因,我猜可能是因为「报表项目」的表头在视觉上太像内容,不像结构。(doge
再加上它和下面货币资金、应收账款等文字,在字号、粗细、对齐方式上差别很小——
对模型而言可能缺少我是表头的明显信号???

感兴趣的朋友可以自己上手试试,看看有没有同类情况的问题,我还蛮好奇这是不是通病…
除了表格、手写文字外,还有一类信息解析场景大家会频繁接触到,那就是——结构化提取。
例如在日常报销单、发票、证件识别等场景上,那就是有时候我们需要的往往是「字段结果」,而不是整页文字。
所以就需要有个能进行信息结构化的工具帮我们干这活儿。
据官方说法,GLM-OCR能从各类卡证、票据、表格中智能提取关键字段,并输出标准的JSON格式。
不过这里有个小插曲,可能是因为我用的是在线测试版本,没找到提示词输入的入口,似乎需要在本地或部署环境下测试???(我猜)
所以,这部分我们直接参考一下官方给出的示例效果,以下为输入示例图:
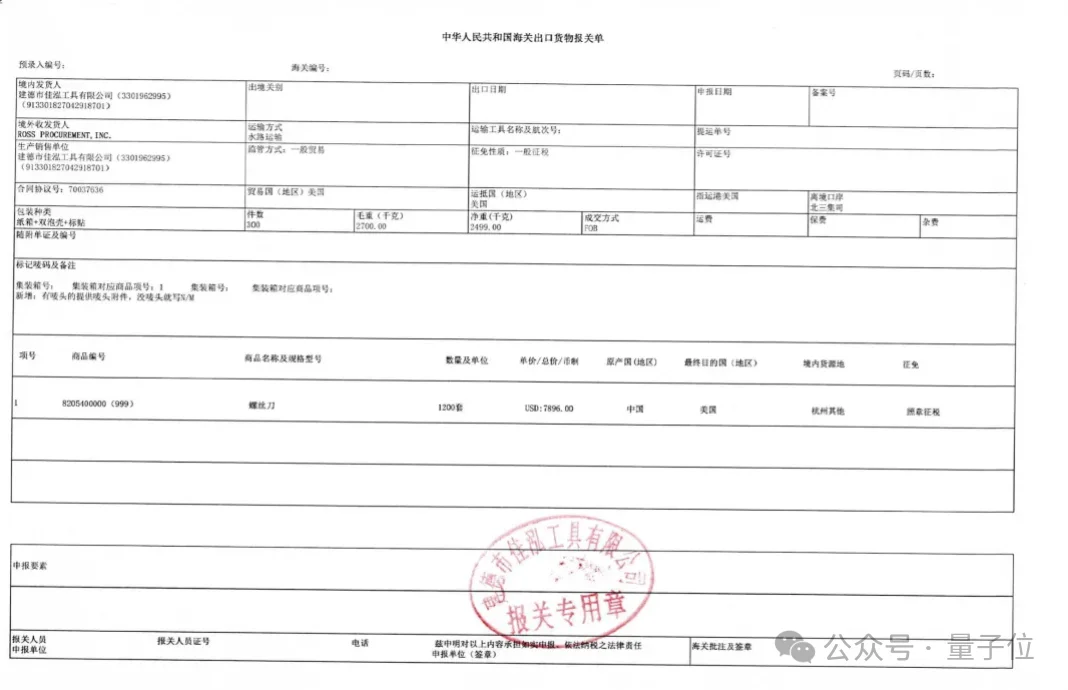
在输入对应的提示词后,模型会根据指令要求,从表格中定向抽取指定字段,并将结果整理成结构清晰、字段明确的JSON输出:
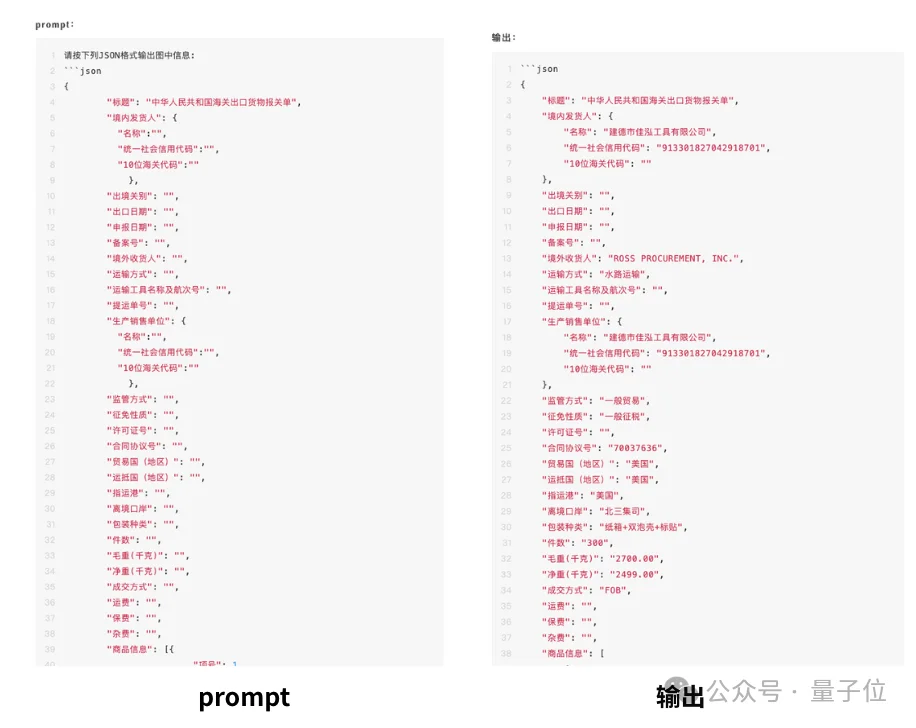
果然,一旦把结构这件事交给提示词明确约束,模型在信息抽取上的稳定性会大幅提升啊…
2025年末2026年年初,国内OCR模型可以说是《一茬接一茬》地冒出来。
去年9月的时候,百度推出了支持5种文本类型识别的超轻量模型PP-OCRv5,主打低参数、快部署。
上个月,DeepSeek发布DeepSeek-OCR2,在语义理解和像素逻辑关联上进一步加强,更偏向复杂内容的整体理解能力。
再到刚刚智谱推出的GLM-OCR,直接把参数压进1B以内,同时在手写体、复杂表格等高难场景中刷到了SOTA。

咱也不难看出,随着OCR越来越热,各家厂商也慢慢卷出了一点相似的《门道》,譬如:

咱不提具体技术细节,单从这些实用的大趋势来说,对用户确实是好事儿,毕竟——
参数小意味着好部署。
输出稳,意味着咱返工次数就少。
便宜这事儿更甭提了,谁不喜欢薅羊毛呢。
(只要是好用、性价比高、好部署的模型,俺们用户就欢迎~)
哦对。
GLM-OCR链接我放在下面了,感兴趣的友友们可以用用试试~
GLM-OCR一箩筐链接:
[1]Github:https://github.com/zai-org/GLM-OCR
[2]Hugging Face:https://huggingface.co/zai-org/GLM-OCR
[3]在线体验链接:https://ocr.z.ai(懒人省力版)
文章来自于“量子位”,作者 “梦瑶”。


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
