# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2026 马年注定迎来一个「AI 味」最浓的春节。
一个与众不同的玩家进入我们的视线,它正是国内最有活人感的生活和消费社区 —— 小红书,卷起了「感知力」。
小红书围绕着发布、评论、搜索、社交等高频互动场景,开放了多种 AI 语音新玩法,包括语音发布、语音评论、语音问一问、语音私信拜年等。
这些新奇有趣的语音玩法,带来的直观效果是:用户之间的沟通媒介不再只是图文,而开始了「动嘴」模式。
语音回帖让以往冷冰冰的评论区有了「满满的活人感」,涌进世界各地的语言、中国各地的方言,还有人秀起歌喉以及各式各样的播音腔、磁性嗓、低音炮。
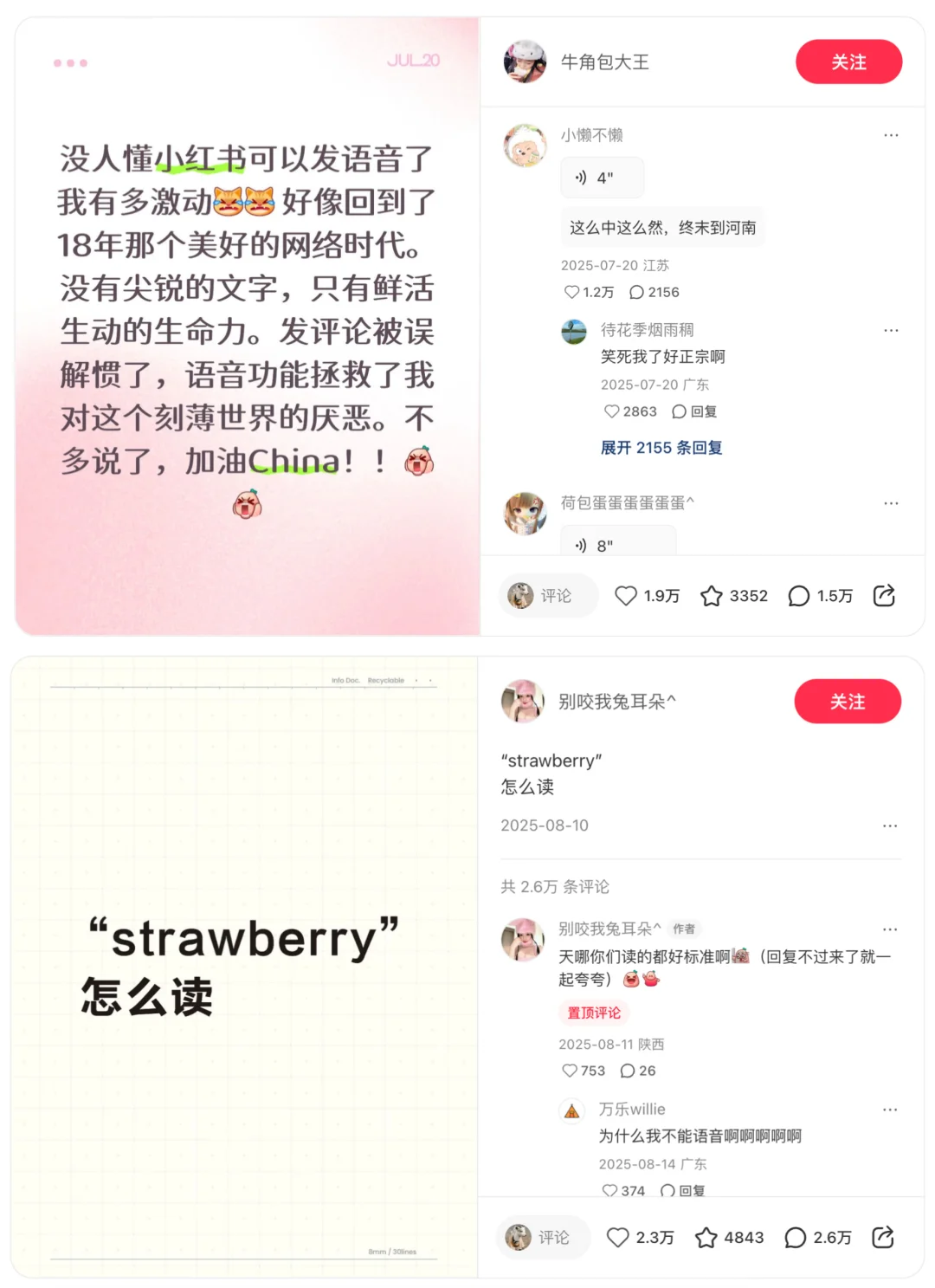
图源:@牛角包大王 @别咬我兔耳朵
如果说语音评论增强了社交趣味性,这两天正式上线的「语音问一问」则是社区搜索形态与功能的一次大变身。
它与传统 AI 搜索最大的区别是将真人经验与 AI 总结结合了起来,你搜索到的每一个答案,都是真实用户的知识与经验沉淀。
在小红书里直接搜「语音问就有活人答案」进入活动页面,便能开启该功能。这个春节,年货买什么、哪里好逛,开口问就行。
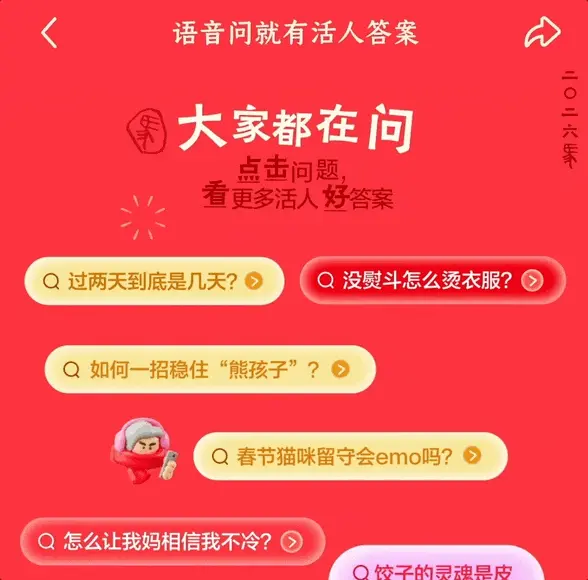
用户还可以参与「语音问一问抽新春小红盒、语音拜年、语音联欢会」等特色迎春活动,互动起来更能感受到年味。
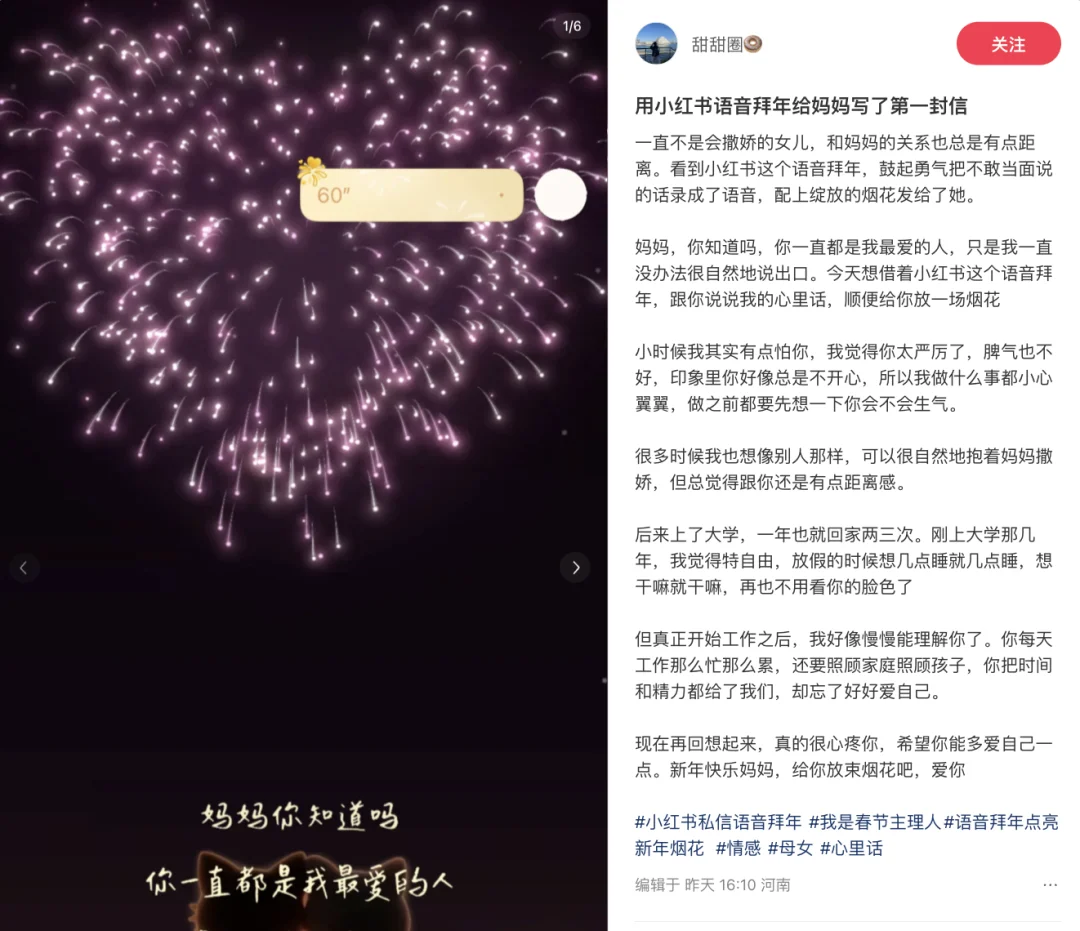
图源:@甜甜圈
作为人类最自然的交流媒介,声音的加入正在将小红书改造成更有「声」命力的社区。
先从语音评论说起,自开启该功能内测以来,各路网友脑洞大开,有人秀自己的正宗法式发音:
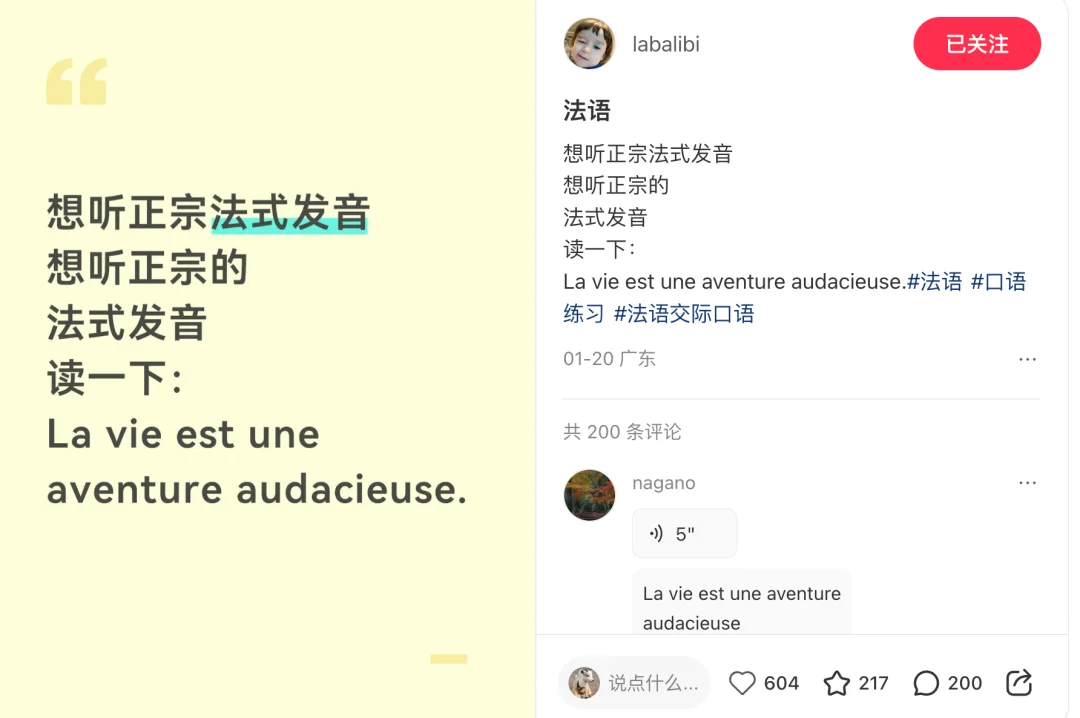
图源:@labalibi

声源:@nagono
上海话让人想到江南烟雨中的温婉女子:
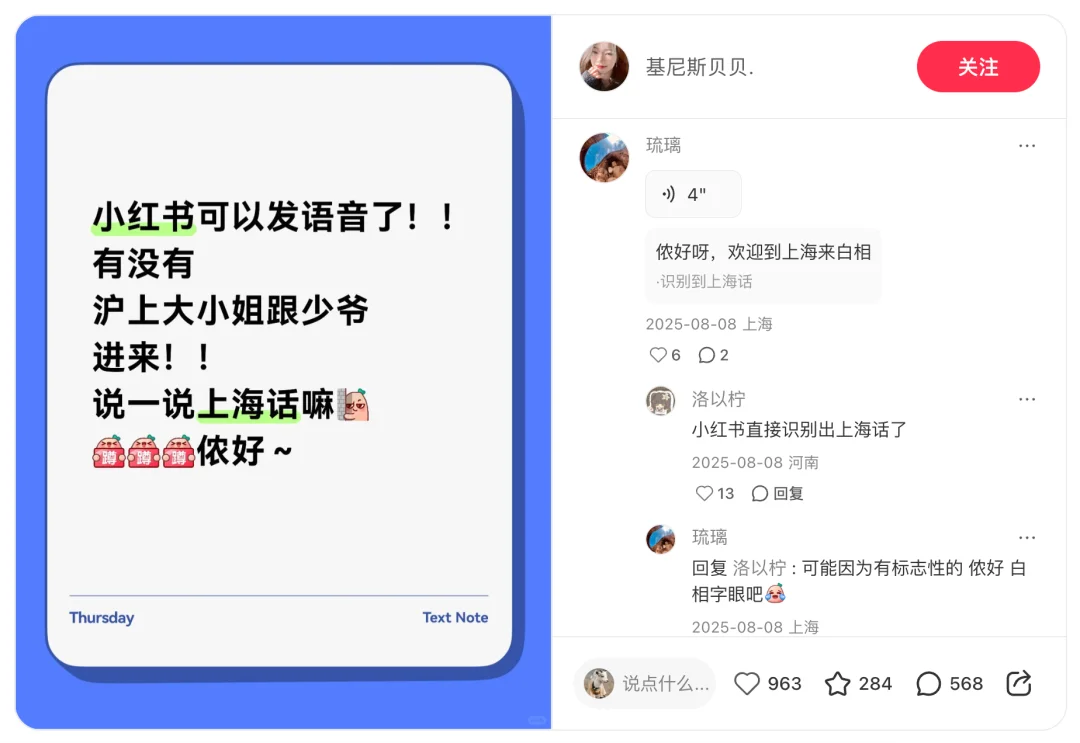
图源:@基尼斯贝贝.

声源:@琉璃
一些歌手已开始在评论区一展歌喉,如杨丞琳:
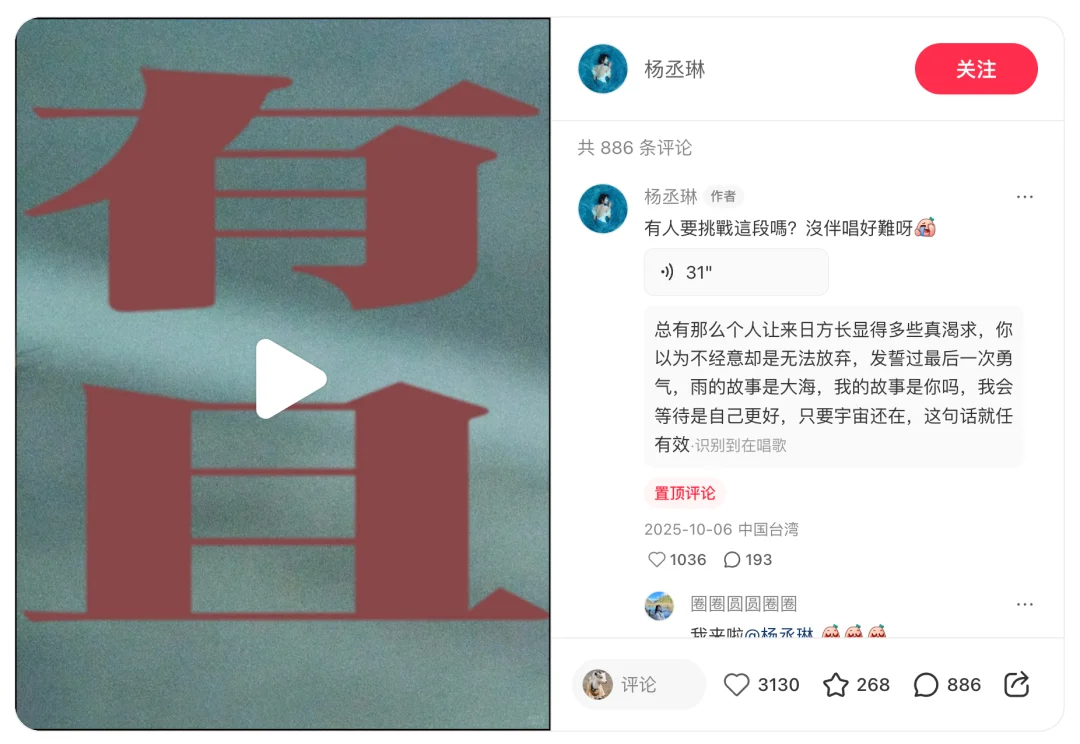

图源&声源:@杨丞琳
不同曲风的 K 歌接龙以及稀奇古怪的声音模仿让评论区充满了欢乐:
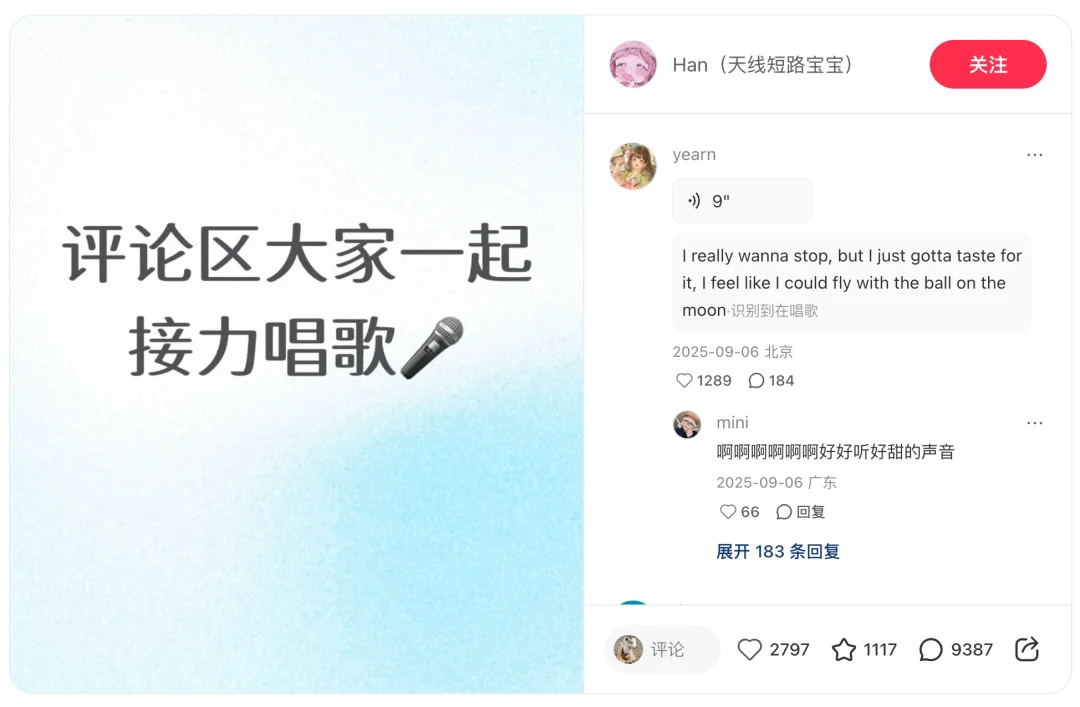
图源:@Han(天线短路宝宝)

声源:@yearn
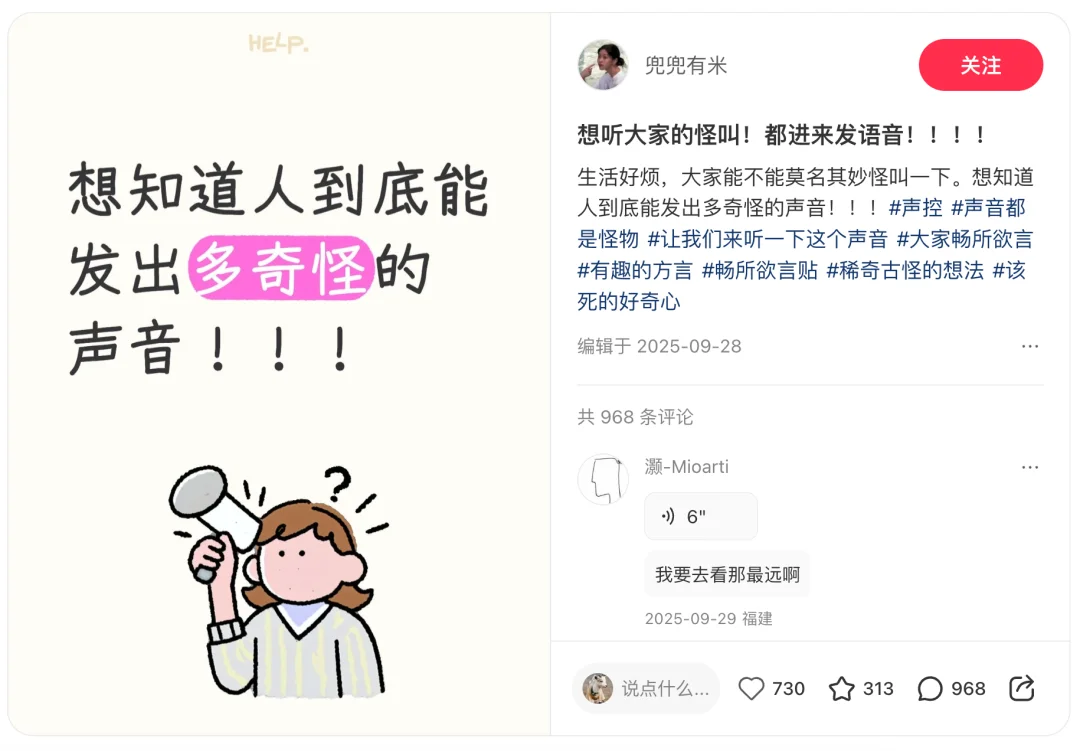
图源:@兜兜有米

声源:@灏-Mioarti
好玩之外,语音评论还可以很暖心。听障人士向外界展示他们真实的声音,这种人文关怀令人动容。
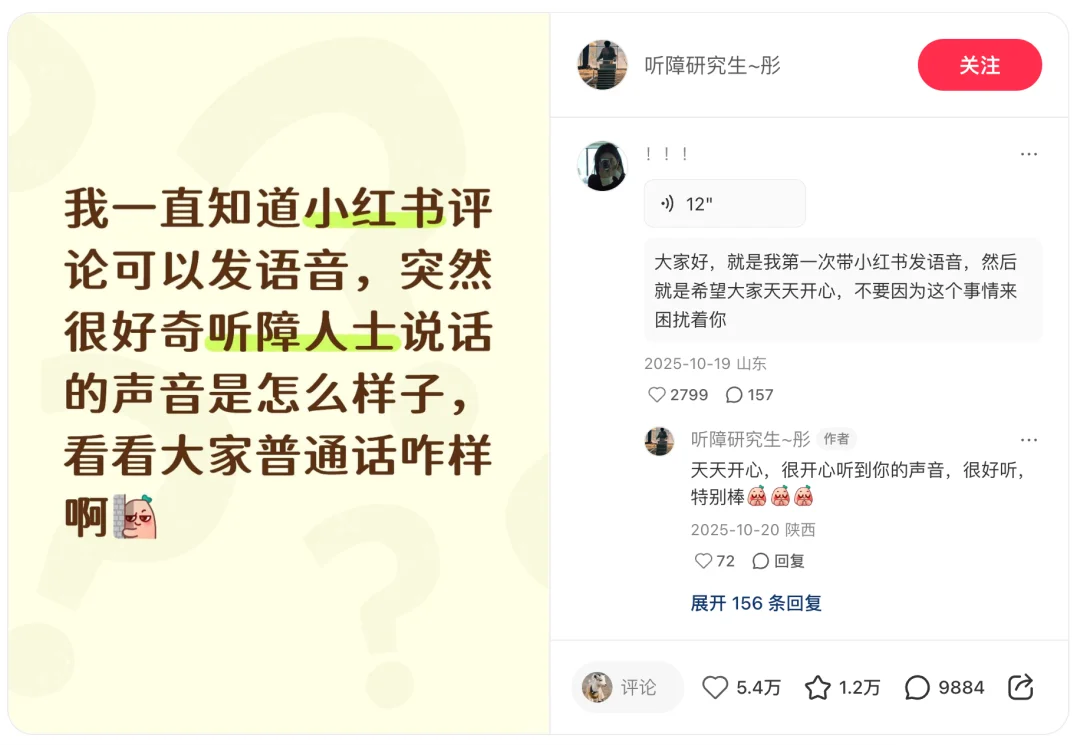
图源:@听障研究生~彤

声源:@! ! !
上线即火爆的「语音问一问」功能,其 AI 增强搜索与问答能力让体验从手动翻阅一篇篇笔记进化到一问即得。
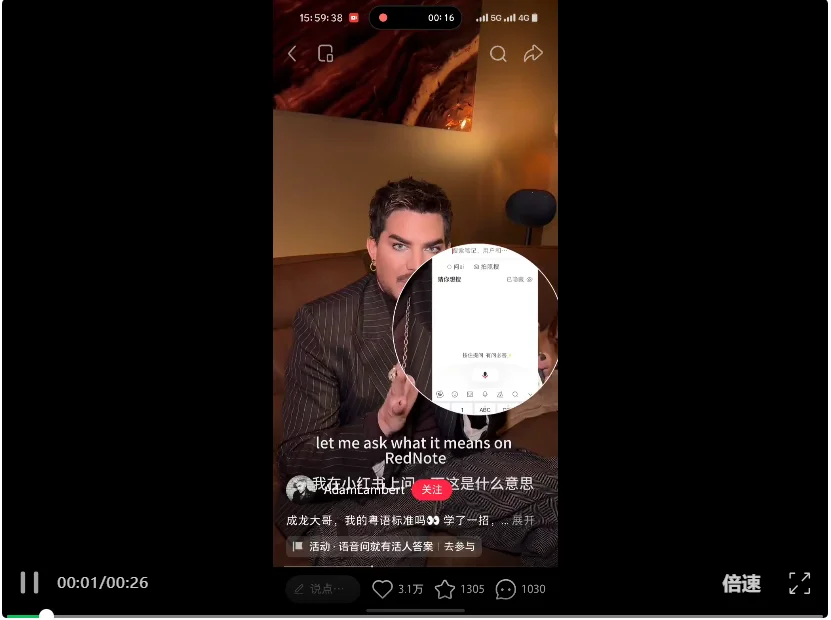
很多明星都参与了进来,比如曾参加过《歌手 2024》的美国男歌手 Adam Lambert 操着蹩脚的普通话发问「动口不动手」的含义,还请教了春节快乐的粤语表达。
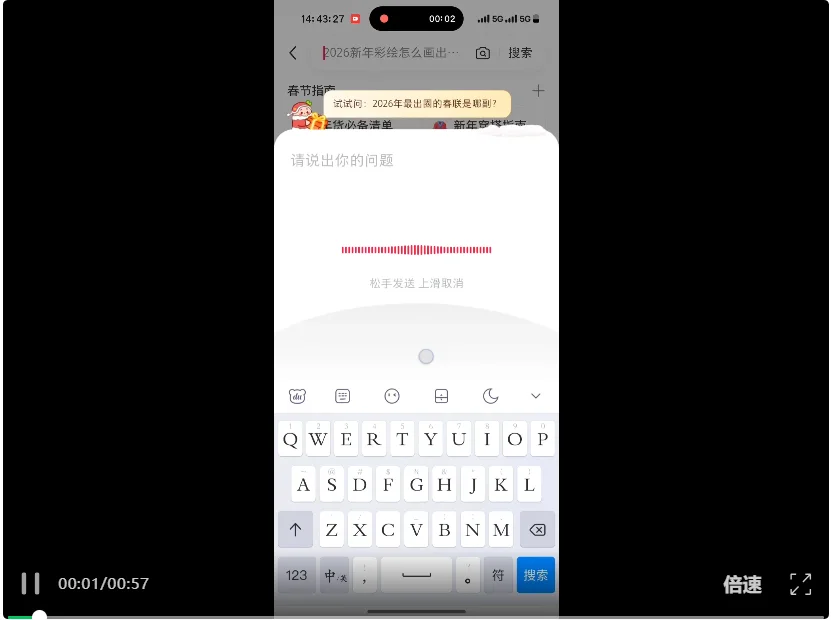
我们也开口问了两个问题,第一个是「北京春节有哪些年味浓的地方」,中间还进行了追问。在识别语音之后,AI 很快根据小红书站内笔记生成结构化总结,还进行分门别类,比如经典年味地标、文艺小众去处和老北京大集,最后还附上了出行小贴士。
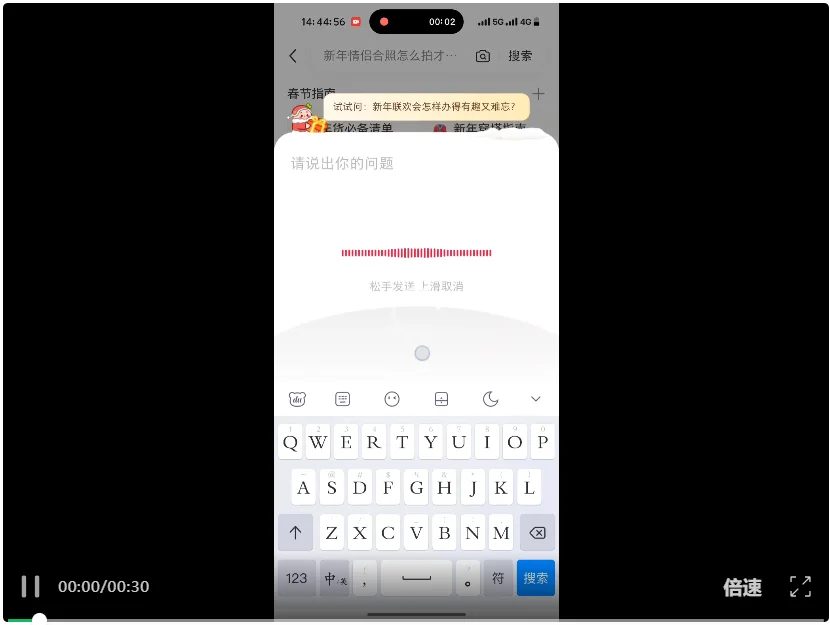
接着问「腊月 23 小年的特殊含义以及南北方的差异」。从结果来看,AI 同样调取站内笔记,将其中零散的信息重组转化为一份结构严密的答案,清楚列出了南北方小年在日期、习俗、饮食、活动等方面的差异。
当你想挑一些「看起来比较贵重,但又不是真的很贵的礼物」时,出来的这份答案能否满足你的要求呢?
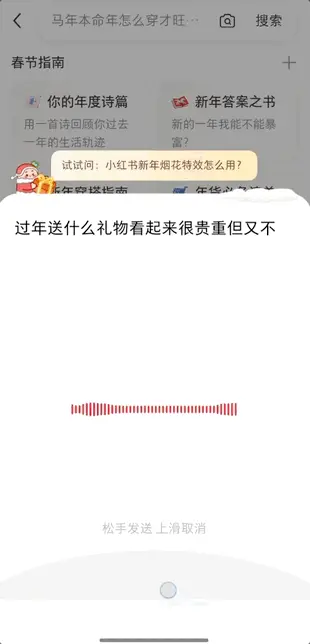
全新的玩法「语音发布」也已经上线,不少明星用它来分享日常生活、发送祝福。
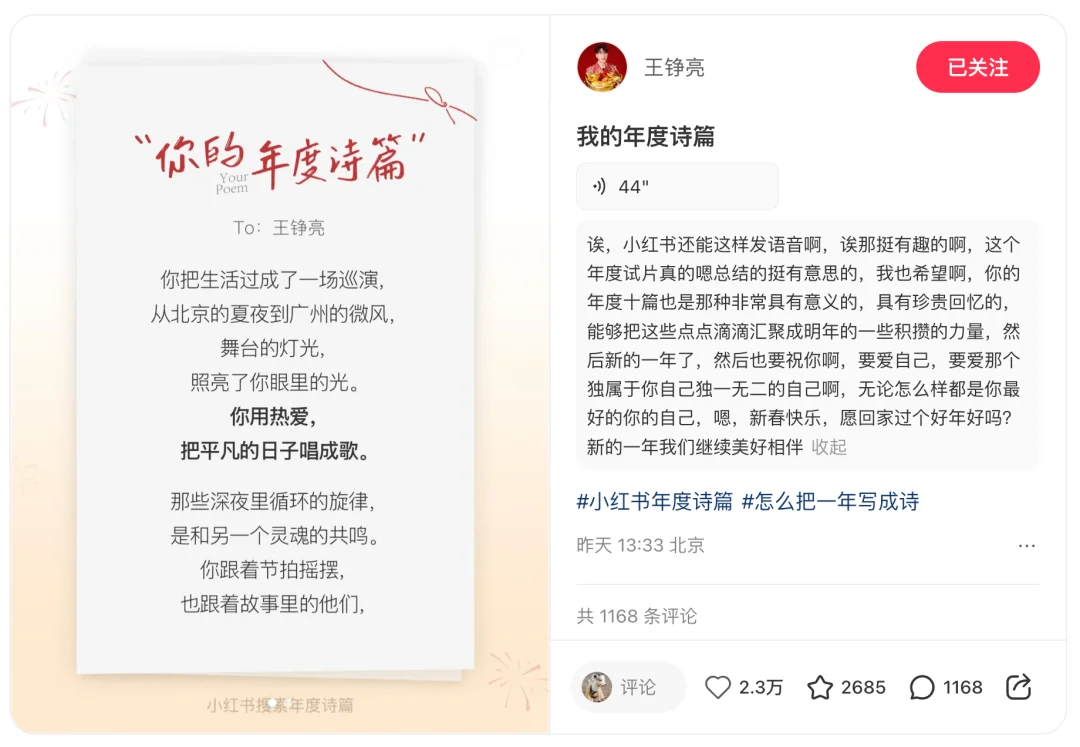

图源&声源:@王铮亮
从互动到搜索、再到笔记,AI 语音的全链路渗透,让 2026 年春节的小红书社区变成了「评论可发声、搜索语音问」。
在小红书这样用户体量庞大的社区,AI 语音的顺利落地需要解决好以下若干问题。
首先需要解决复杂场景下的音频理解。
小红书的用户分布极广,存在大量地域方言、口音、不同年龄段或用户群体的使用习惯(如耳语、中英夹杂等情况)。设备差异、背景声音、嘈杂环境、语速同样会影响识别的准确性。
除了语义内容,模型也需要感知用户语音中的情绪、音色特点;音乐歌声中的情绪、流派、风格;自然界的风声、雨声、海浪声等环境音。
如果说听懂是基础,那么有温度地回答是灵魂所在,也是实现自然交互的关键。这就要面临第二大问题:如何让音频生成具备活人感。
小红书内容场景风格「千人千面」,要求模型根据场景灵活切换,拒绝一种腔调走天下。情绪表达要「连贯流畅」,不再是孤立地朗读句子,而是能读懂上下文的起承转合;细节语气也要精准拿捏,还原语言的「弦外之音」。
这就要求模型在充分消化理解用户上下文的同时,还要具备相应的情绪感知能力。
最后,响应速度直接影响用户实际体验。
如果语音交互处理流程很长,用户说完后总要经历几秒钟的「死寂」,系统才有反应。这种非实时性会将原本连贯的对话切得支离破碎,体验十分生硬。
对于小红书而言,其打造多样化 AI 语音能力具有天然优势:
一是丰富内容形态,涵盖图文、笔记、视频等多种形式,多元内容结构可以完美承载语音作为交互的中间媒介。二是相较于单纯的短视频平台,在小红书评论区插入语音不会导致体验上的「打断感」。三是小红书的 AI 语音能力集成于主站核心场景,为技术提供了持续创新与优化的空间。
这些优势使得小红书成为 AI 语音落地的理想试炼场,但要达到如今的水平,更有坚实的技术支撑。
据了解,这些技术出自小红书 Super Intelligence-AudioLab团队,负责人为风龙。团队核心布局了语音识别、语音合成、全双工语音交互及 ALLinOne 基座模型、音乐理解生成四大方向,支撑起小红书在各业务场域的应用探索。
在语音识别领域,自研 FireRedASR 大模型取得中文语音识别开源 SOTA 效果。近期,团队也准备开源全链路 ASR 系统级解决方案 FireRedASR2S,包含静音检测、语种检测、语音识别、标点集成等模块。
在功能上,FireRedASR2 新支持 20 + 方言和口音,在中文普通话和方言公开的 24 个测试集上字错率为 9.67%,相比之下,Doubao ASR 和 Qwen3-ASR-1.7B 的字错率分别为 12.98%、10.12%。
另外,FireRedLID 语种检测模型支持 100 + 语种和 20 + 中文方言,语种准确率达 97.18%,而 OpenAI Whisper 仅为 79.41%。FireRedVAD 支持 100 + 语种,在多语言语音 Fleurs 测试集上,它的 F1 分数为 97.57%,开源 Silero-VAD 为 95.95%。

FireRedASR2 不同版本与竞品模型的平均字错率对比。
在语音合成领域,同样做到中文对话长语音合成 SOTA。自研 FireRedTTS2 大模型支持 3 分钟以上长对话生成,在多轮对话场景中,其音色稳定性和自然度显著优于多家竞品,代表了目前开源模型的最高水平。
该模型引入的情绪感知能力是语音「活人感」得以实现的关键,当感知到用户情绪低落时,语音中会自然地带有安慰的语调,摆脱机械感。
更早之前的 FireRedTTS1/1S 主打单句生成与克隆,能够精准还原参考音频的特色,目前稳居该领域的开源第一梯队。
FireRedTTS 系列模型与 OpenStoryline AI 视频剪辑的结合,可以提供自然人感的语音生成能力。未来,团队将持续扩展能力至播客、语音翻译等多个场景。
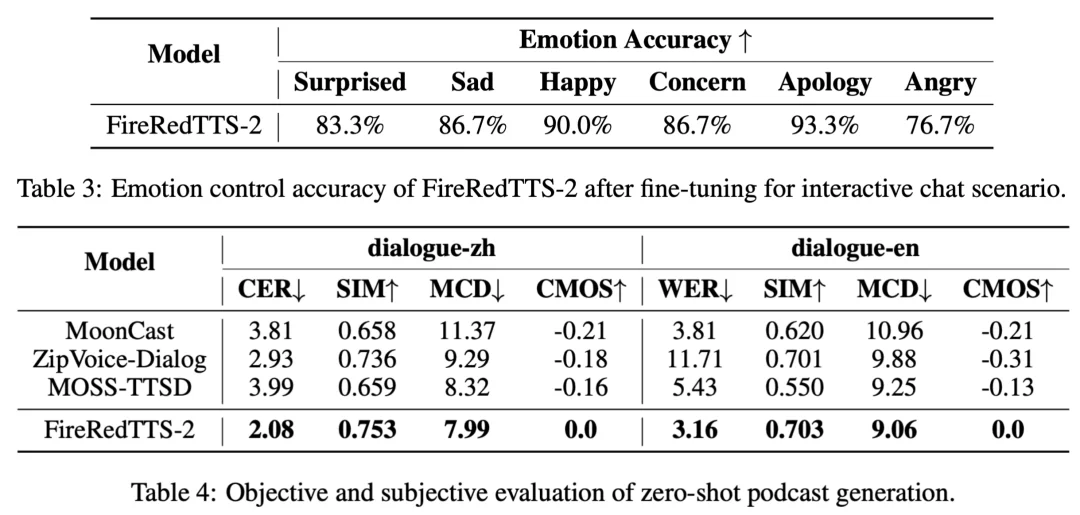
表 3 为 FireRedTTS-2 在交互式对话场景微调后的情感控制准确率,表 4 为 zero-shot 播客生成的客观与主观评估。
对于全双工语音交互及 ALLinOne 基座模型,团队推出了业内首个开源、支持私有化部署的全双工语音交互系统 FireRedChat。
针对传统 AI 反应慢、乱打断的痛点,系统通过自研的 pVAD(辨别声音)和语义判停 EoT(听懂意思) 技术,精准判断说话时机,端到端延迟低至 2 秒,反应又快又稳。其最大亮点是不依赖外部 API,即可实现一键本地部署。它让 AI 不再是冷冰冰的机器,而是能共情、有温度的伙伴。
FireRedChat 项目地址:https://github.com/FireRedTeam/FireRedChat
ALLinOne 基座模型实现语音、音效、音乐的统一编码,完美打通泛音频的理解与生成,带来了音频能力的涌现。同时通过支持多类型、深层次的标签分析,为语音评论的音频内容理解提供了坚实的基础能力。据悉团队将于今年上半年和业内分享开源模型。
在音乐理解与生成领域,自研的音乐理解与生成模型实现了对音乐的多尺度深层理解、创作意图融合与灵活可控创作,将专业音乐创作的知识融入模型的理解 - 转化 - 生成各阶段,为从音乐爱好者到专业音乐人的不同用户提供一体化音乐创作解决方案。
模型在音乐曲风、情感、场景、节拍律动等多个维度的理解能力和高品质生成能力已赋能小红书音乐人创作,据悉同样会在上半年和业内分享开源模型。
在拿到模型测试资格后,我们也小试了一下,生成的一分多钟的音乐效果不错:

正是有了以上沉淀,小红书构筑起了一套覆盖底层架构优化、高质量语音合成、情感化语音互动、智能语音问答的完整技术栈,通过语音主导的人性化表达和问搜协同,营造一个兼顾交互趣味性与情感温度的社区生态。
除了语音,整个 Super Intelligence 团队是小红书面向未来内容形态与通用智能的重要技术引擎,其负责人为汤神,目标是构建业界领先的多模态基础大模型体系,并形成可持续演进的通用智能能力。
团队包括 Audio Lab、Vision Lab、Foundation Lab 等实验室,在内容理解、视觉与多模态、图像生成与编辑、语音理解与生成、Omni Model、特效渲染与影音体验等方向长期对标行业 SOTA,同时强调模型能力在推荐、搜索、视频 & 直播、电商、商业化广告、国际化等复杂真实业务中的可用性与规模化落地。
过去两年,汤神及其团队先后主导了图搜、内容理解、创作工具升级等重大项目,并负责语音 & 多模态 & 图像生成与编辑等大模型。团队在学术与产业两端同步推进,累计发表了 40 余篇顶会与期刊论文,沉淀出 InstantID、StoryMaker、FireRedTTS、FireRedASR 等具有行业影响力的开源技术成果,成功孵化语音评论、文字大字报、长文、满屏高清等多项站内爆款功能。
小红书的 AI 语音探索,一方面让用户愿意尝试好玩的语音评论,可以提升社区活跃度;另一方面,语音搜索让用户获取信息像聊天一样简单,尤其适用于不习惯或不方便打字的群体或场景。
这样的实践也验证了:在追求技术高度之外,体验深度同样重要。就拿最近火热的 Agent 来说,用户看重的不单单是能力的强弱,也在意交互自然度、意图理解程度和服务无感化。
或许,最后拼的是能否以直观、亲和、高效的路径触达用户,让 AI 接地气,在更自然的交互中实现价值。
文章来自于“机器之心”,作者 “杜伟”。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
