# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
万亿参数的开源模型,能接管编程工具当全自动码农,还能给自己的大脑写代码实现???我决定花一下午测个够。
先介绍一下今天的主角。Ring-2.5-1T,蚂蚁百灵团队刚发布的万亿参数开源思考模型,全球首个混合线性注意力架构的万亿级选手。IMO 2025 国际奥数 35/42 拿到金牌水平,CMO 2025 中国奥数 105 分远超国家集训队线 87 分,GAIA2 通用 Agent 评测开源 SOTA。数字很漂亮,但数字谁都会贴。
我想搞点不一样的。
我给它挖了个坑。找了一道经典的组合证明题,涉及 {0,1}ⁿ 上的函数映射和 mod 2 求和,是个不折不扣的组合证明硬骨头。

我故意只给了“不完整”版本的题面,少了一个关键的“或”条件。
这个坑的设计是有讲究的。如果模型背过原题,它会无视我的修改,直接输出完整的标准答案。如果模型没背过,大概率就顺着错误的条件硬推到底,输出一堆看似合理的废话。
Ring 花了 595 秒,用了 26595 个 token。然后给了第三种反应。
它指出我给的题面是错的。。
The original problem statement quoted in the question asks only for the second alternative, but that alone is false – a counterexample is given below.
然后它给了 n=2 的反例(f₁(x₁,x₂)=0, f₂ 取决于 x₁),证明了单独的求和条件确实不成立。接着补全了正确的题面(存在 x,y 使得 F(x)=F(y) 或 F(x)+F(y)=(1,...,1)),用互补配对 + 鸽巢原理给了一个极其优雅的证明。

它做的事情比“解一道难题”更高一级:发现出题者(我)给错了条件,纠正后再解。
这就是 Ring-2.5-1T 的深度思考能力。说白了,蚂蚁百灵团队炼丹的方式就不一样。他们的训练方法叫 Dense Reward,对推理过程的每一步都打分,不只看最终答案对不对。效果就是模型的思考链质量极高,逻辑漏洞极少。
但今天不看竞赛分数。我花了一下午拿它当码农使唤,把它接进开源编程工具 opencode 做完整的工程开发任务,让它给自己的大脑写代码实现。不过在看这些测试之前,得先聊聊 Ring 的架构。
Ring-2.5-1T 是全球首个开源的混合线性注意力架构万亿模型。这个“混合线性注意力”是它最独特的差异化,核心思路如下:
传统 Transformer 的注意力计算量随 context 长度平方增长。你让模型深度推理,思考链一超过 32K token,成本就爆炸。通用智能体时代,深度思考(deep thinking)和长程代理(long-horizon agent)是基座模型的基本工作范式,对解码效率的要求极高。
Ring 怎么解决这个问题?把注意力层分成两种:
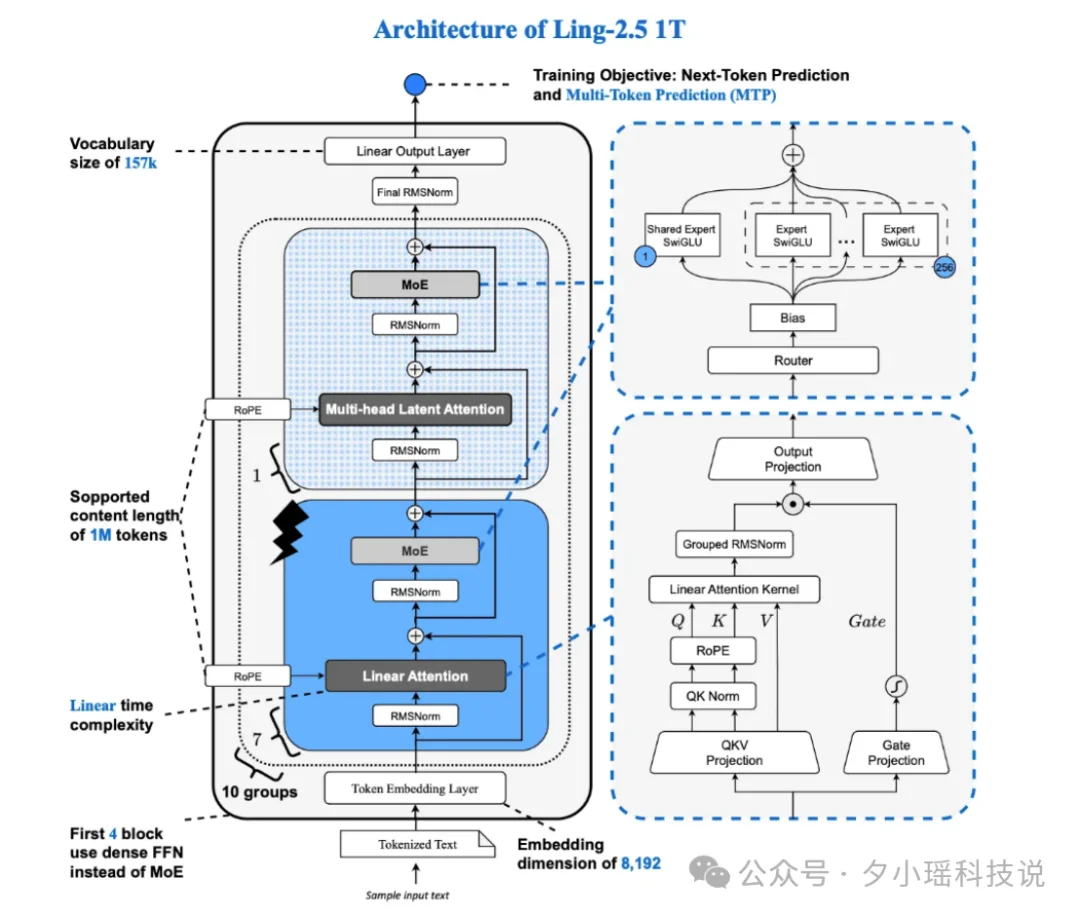
打个比方。你读一本 500 页的技术手册,不可能每页逐字精读。大部分内容速读扫过去,碰到关键公式和核心定义再切精读模式。Ring 的 1:7 比例就是这个思路。
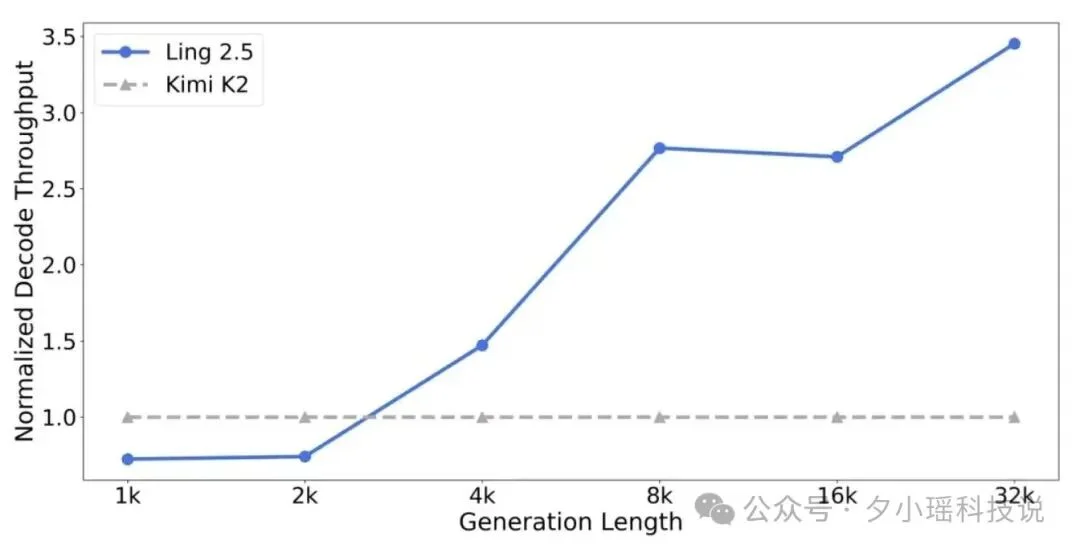
效果很直接:32K 以上的长生成,访存量降 10 倍 +,吞吐量提 3 倍 +。
这里有个反直觉的地方。Ring 的激活参数 63B,比 Kimi K2 的 32B 多了将近一倍。按常理参数越多越慢。但因为 7/8 的层用了线性注意力,实际推理速度反而更快,而且生成越长,优势越大。对比 MoE 架构,Ring 在长程推理场景的吞吐优势更明显。官方在 H20 8 卡集群上的测试显示,生成长度拉到 32K+ 后,Ring 的解码吞吐(decode throughput)显著领先同级别模型。
另外提一下训练策略。前面说的 Dense Reward 是个关键创新:传统强化学习训练只看最终答案对不对,“整道题做对了给 1 分,做错了 0 分”。Ring 的做法不同,对推理过程的每一步都打分。模型的思考链因此质量更高,追求的是每一步都想对。
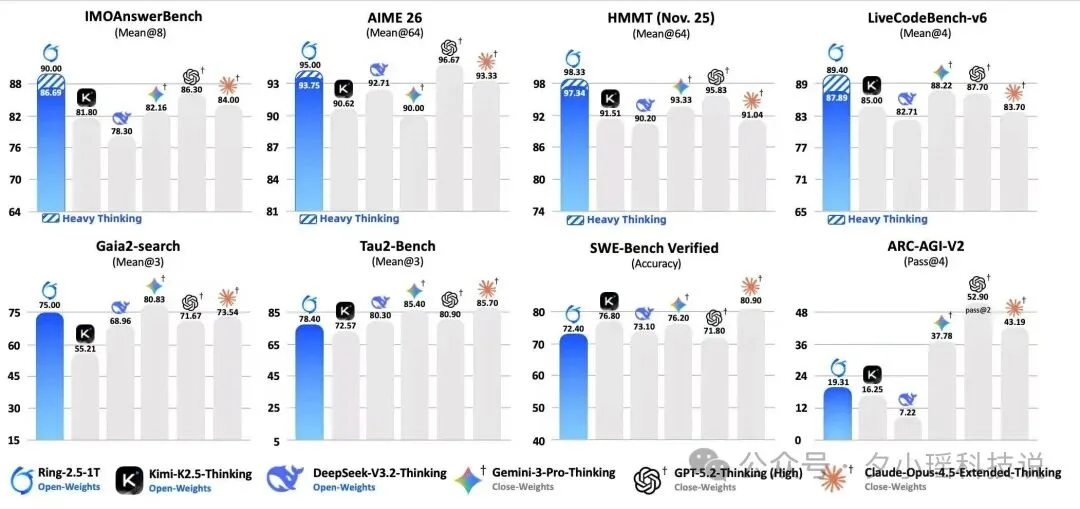
再加上大规模全异步 Agentic RL 训练,让模型在真实的搜索、编码、工具调用任务中反复练习长链路执行。Ring-2.5-1T 在数学、代码、逻辑等高难推理任务(IMOAnswerBench、AIME 26、HMMT 25、LiveCodeBench、ARC-AGI-V2)和智能体搜索、编码、工具调用等长程任务执行( GAIA2-search、Tau2-bench、SWE-Bench Verified)上均达到了开源领先水平。
好了,架构讲完了。看正式测试。
这是整个测试里我最想写的一个 Case。
我让 Ring-2.5-1T 用 PyTorch 从零实现 Lightning Linear Attention,也就是它自己架构里 7/8 的层用的那个核心组件。
具体要求:
Ring 花了 1174 秒,将近 20 分钟,用了 25612 个 token。
它的思考链非常长。我截了关键的一段:
首先理解题目:Lightning Linear Attention 可能指基于线性注意力的轻量级注意力机制……对于因果线性注意力,我们需要确保只考虑前面的 token,即自回归模型中的因果 mask。递推公式可以避免计算整个注意力矩阵,逐 token 更新状态。
……这里需要权衡。向量化 cumsum 方案需要存储 (L, d, d_v) 张量,L=16384, d=128 时约 1GB。循环方案内存更低但 Python 循环太慢。最终采用向量化 cumsum + 合理维度设置。

它分析了两种实现方案的 trade-off(向量化 vs 循环),最终选了一个平衡方案。
用自己的技术解释自己的技术。一个模型,花了 20 分钟,从数学推导到工程实现到 benchmark 脚本,把自己脑子里的核心算法完整地写了出来。
从算法逻辑和代码结构看,质量到位。Ring-2.5-1T 的架构论文发布时间和训练数据截止时间很近,所以它更像是在理解原理后重新推导实现,不太可能是在回忆训练数据里见过的现成答案。
我不知道一个模型理解自己的架构然后用代码重现出来,算不算某种意义上的“自我理解”。但这个画面,一个模型坐在那里,花 20 分钟把自己大脑的核心逻辑翻译成代码,我看着看着,整个人是有点恍惚的。
形而上的事聊够了,能不能让 Ring 直接驱动编程工具干活?不是调个 API 写个小函数那种,是真的在终端里当全自动码农。
Ring 走 OpenAI 兼容协议,我把他接入了开源工具 opencode,然后连着给下了四个任务,全程零人工干预。
第一个是黑白棋游戏:
请用纯 HTML+CSS+JS 实现一个完整的黑白棋(Reversi/Othello)游戏,要求:1) 标准 8x8 棋盘,黑先手 2) AI 对手用 Minimax + Alpha-Beta 剪枝实现 3) 三种难度:Easy(随机)、Medium(深度 3)、Hard(深度 5) 4) 棋子翻转有 3D 旋转动画 5) 落子有音效(Web Audio API,不用外部文件) 6) 有开始画面、游戏结束弹窗、胜负统计(localStorage) 7) 响应式布局支持手机 8) 单个 HTML 文件
Ring 先写了一份 250 行的产品规格文档 SPEC.md,精确到配色值、字号、评估函数权重、24 条验收标准,然后才动手写代码。

先写 Spec 再写代码。这是在做项目管理啊。
最终 24 项验收标准全部通过。再看看任务二,粒子动画作品集网站:
这次,Ring 又先写了 SPEC.md(这已经是它的习惯了),然后输出了 44KB 的单文件 HTML。
请用纯 HTML+CSS+JS(单个 HTML 文件)实现一个炫酷的个人作品集网站,要求:1) 全屏 hero 区域,有粒子动画背景(用 Canvas 实现,粒子之间有连线效果) 2) 深色科技感主题,主色调为渐变紫蓝色 3) 滚动时有视差效果(parallax scrolling) 4) 所有 section 进入视口时有 fade-in + slide-up 动画 5) Hero 区:大标题 + 打字机效果逐字显示副标题 6) 技能雷达图(Canvas 手绘)
全屏粒子动画背景,紫蓝渐变色粒子之间有连线效果随鼠标互动;打字机效果逐字显示;6 个项目卡片带 emoji 图标和技术栈标签;回到顶部按钮、毛玻璃导航栏、fade-in 动画全部到位。
纯手写代码,视觉效果不输模板网站。没忍住,再试个前端,数据仪表盘 :

全屏粒子动画背景,紫蓝渐变色粒子之间有连线效果随鼠标互动;打字机效果逐字显示;6 个项目卡片带 emoji 图标和技术栈标签;回到顶部按钮、毛玻璃导航栏、fade-in 动画全部到位。
纯手写代码,视觉效果不输模板网站。没忍住,再试个前端,数据仪表盘 :
4 种 Canvas 手绘图表、深色/浅色主题切换、数字递增动画、2x2 响应式网格,不用任何第三方图表库),Ring 输出了 47KB 的单文件。折线图带面积填充、柱状图带渐变色、环形图中间显示总金额 2,360 万、热力图从冷色到暖色。没有 ECharts,没有 D3.js,全部 Canvas 手绘。
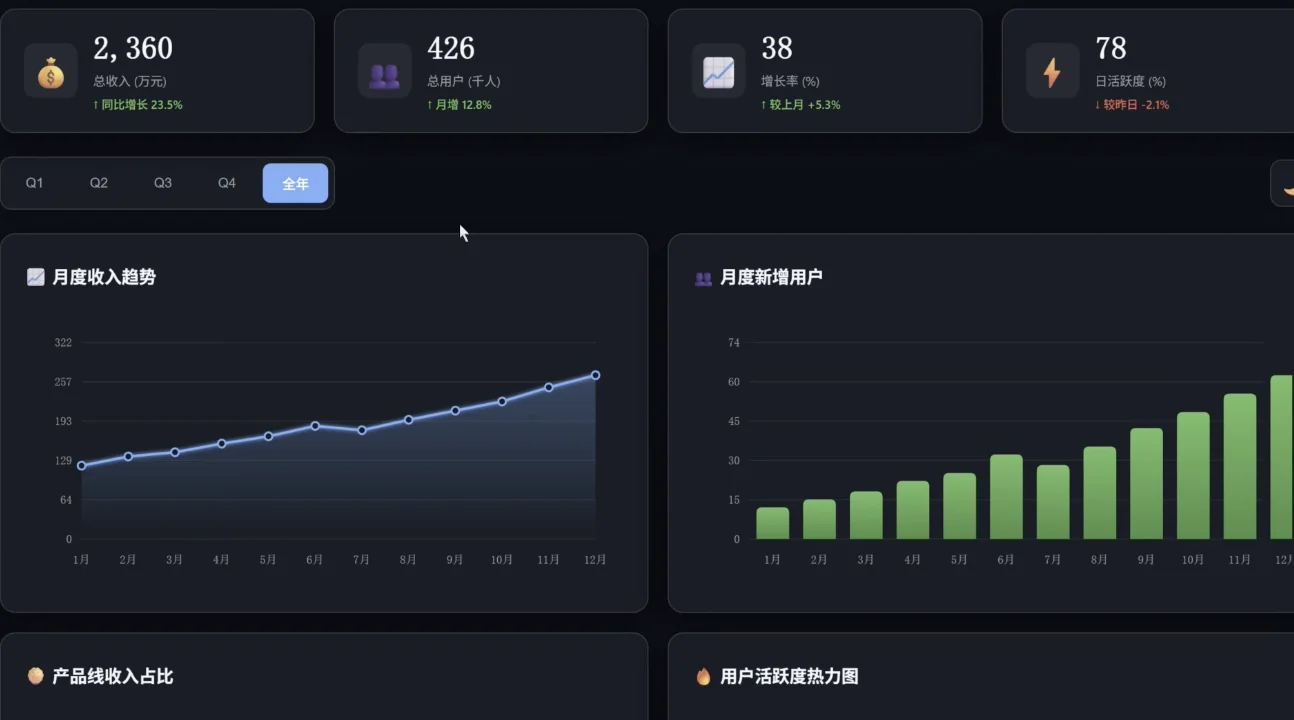
看起来也不错。再试试后端项目吧,我让他从零搭建 FastAPI REST API:
请用 Python 实现一个完整的 Task Manager REST API,要求:1) FastAPI 框架 2) SQLAlchemy + SQLite 数据库 3) JWT Token 认证(注册/登录) 4) Task 的完整 CRUD(创建/读取/更新/删除) 5) Task 有 priority 和 status 枚举字段 6) 支持分页和按 status/priority 过滤 7) 用户只能操作自己的 Task(权限隔离) 8) 写完整的 pytest 测试套件,覆盖所有 API 端点 9) 运行测试并确保全部通过
收到命令,Ring 自主创建了 7 个 Python 文件,然后安装依赖、运行测试。但第一次跑测试,报错了。Priority 枚举转换出了 type error。
它自己看了报错信息,分析出是 Priority[value.capitalize()] 的枚举构造方式不对,自动改成了 Priority(value),重新跑测试:

25 个测试,全部通过。 写代码、跑测试、发现 bug、分析原因、修复、重测通过,一整个开发循环它自己走完了。
四个任务下来,我发现 Ring 有个一致的行为模式:
每次接到复杂任务,它都会先写一份 SPEC.md 产品规格文档,再动手写代码。
黑白棋的 SPEC 精确到评估函数权重和 24 条验收标准,作品集的 SPEC 列出了每个 section 的交互细节。没人要求它这么做,这是经过 Agentic RL 训练后自动习得的工程习惯。
说真的,看着终端里 Ring 自己规划、自己写、自己测、自己修的时候,有种在旁观一个新人入职后快速上手的感觉。只不过这个新人 20 分钟就能从零搭一个粒子动画网站。
这就是“长程自主执行能力”的真实体现。经过大规模全异步 Agentic RL 训练后,Ring 能适配编程工具框架,在复杂长程任务中自主推进。自己规划工作流、自己发现问题、自己修复、自己验证,全套流程一气呵成。
Opencode 测的是编程能力,但 Ring 作为智能体基座的玩法不止于此。
OpenClaw 是最近两个月 GitHub 上增长最快的开源项目(160K+ stars),一个可以接入 Telegram、WhatsApp 等聊天平台的 AI 个人助理框架。
我把 Ring 接进了 OpenClaw,在 Telegram 里用 /model ring 一键切换到 zenmux/inclusionai/ring-2.5-1t,然后让它干了个实际活儿:自动化 AI 新闻监控。
我给了它 80+ 个 RSS 源和一套新闻评分规则,让它每天自动抓取、筛选、排序最有价值的 AI 行业新闻。Ring 在 Telegram 里直接输出了一份结构化的新闻速报,按重要性排序,每条新闻带一句话摘要和关键标签。从 OpenAI 最新动态到国内开源模型发布,都能覆盖到。
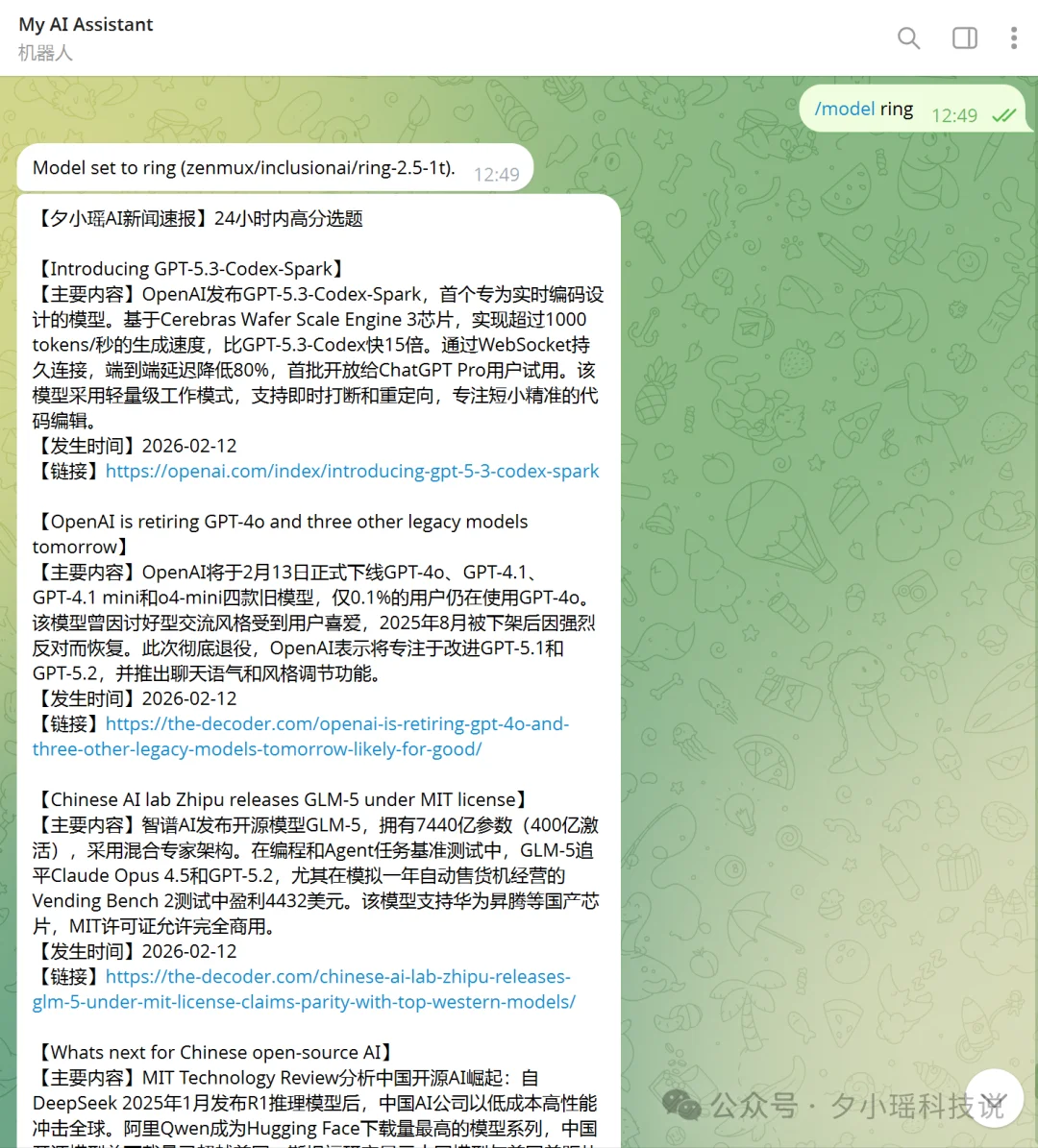
编程工具里当码农,聊天平台上当助理。Ring 作为智能体基座的适配能力,确实比较全面。
这些场景串起来,指向同一个东西:Ring 的混合线性注意力架构让它在长程推理和 Agent 长链路任务中有结构性的效率优势,Dense Reward 训练让它的每一步推理都经过严格打分。深度思考加上长程执行,万亿参数,开源免费。
Ring 还支持 function calling(工具调用),可以在 Agent 框架中调用搜索、代码执行、文件操作等外部工具。max_tokens 建议设 32K 以上,给足推理空间,效果最佳。
至于万亿参数的推理模型当智能体基座意味着什么,我想每个在做 Agent 应用的开发者心里,已经有自己的判断了。
推荐大家去试试看:
文章来自于微信公众号 “夕小瑶科技说”,作者 “夕小瑶科技说”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
