# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在2026当下的智能体(Agent)开发体系中,“为LLM加Skills”已经成为事实上的行业标准。您的Agent表现不好,是因为底层的LLM参数量不够,还是因为您喂给它的“Skills”写得一塌糊涂?无论是日常使用的各类CLI工具,还是最近的Openclaw,其底层能力的跃升很大程度上都依赖于这些特定领域的Agent Skills。

但是,整个工程界正处于一种知其然而不知其所以然的盲目调试状态。大家在一个没有精确度量衡的黑盒子里盲目堆砌Markdown文件、代码模板和标准操作流程(SOP),却没有任何标准方法来测量这些外挂内容到底提供了多少真实的性能增益。

《SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks》这项研究终结了这种系统性盲目。研究者剥离了对基础模型原生能力的过度关注,在业界首次将“技能”本身定义为可被量化测试的独立工件。该论文的背书阵容极其强悍,研究者团队由BenchFlow领衔,汇集了来自亚马逊(Amazon)、字节跳动(ByteDance)、富士康(Foxconn)等工业界巨头,以及斯坦福大学(Stanford)、卡内基梅隆大学(CMU)、加州大学伯克利分校(UC Berkeley)、哥伦比亚大学(Columbia)、牛津大学(Oxford)等数十所顶尖学术机构的联合力量 。研究者剥离了对基础模型原生能力的过度关注,在业界首次将“技能”本身定义为可被量化测试的独立工件 。通过7,308次执行轨迹的严格测试 ,研究者强行拆解了三个被业界广泛忽视的硬核问题:
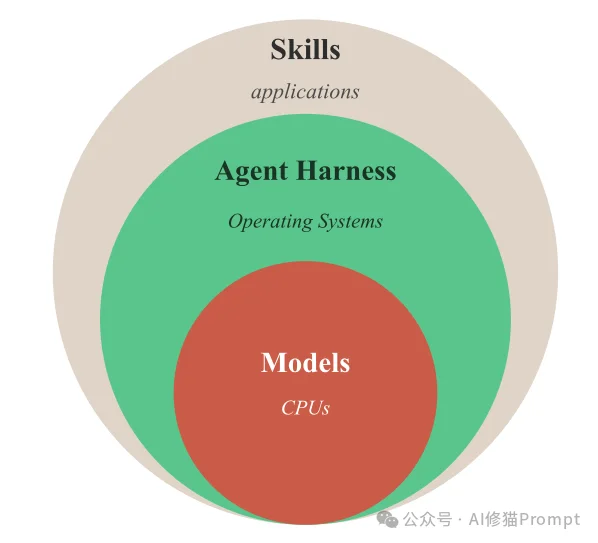
本文将依据该论文提供的实证数据,从底层架构、增益差值、Token经济学以及5,171次真实崩溃日志,为您系统性解答上述拷问。
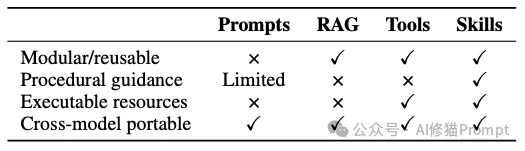
在深入测试环境之前,必须在架构层面上明确定义我们到底在向内存里注入什么。许多开发者常常将系统提示词(Prompts)、检索增强(RAG)和工具调用(Tools)与Skills混为一谈。研究者在论文中给出了极其精辟的技术边界划分:
为了确保测试基础的现实代表性,研究者对GitHub、社区市场以及企业库中的生态数据进行了扫描,去重后提取了47,150个真实技能。统计显示,这些技能文件极度轻量,中位数大小仅为2.3 KB(约1500 Tokens),且主要以Markdown格式存在。这为后续设定的8K上下文滑动窗口限制提供了直接的工程依据。
为了证明任务成功归功于注入的技能而非测评系统的偏见,研究者彻底抛弃了主流基准测试中泛滥的LLM-as-a-judge主观评估机制,构建了基于容器的、100%确定性验证的沙盒环境。
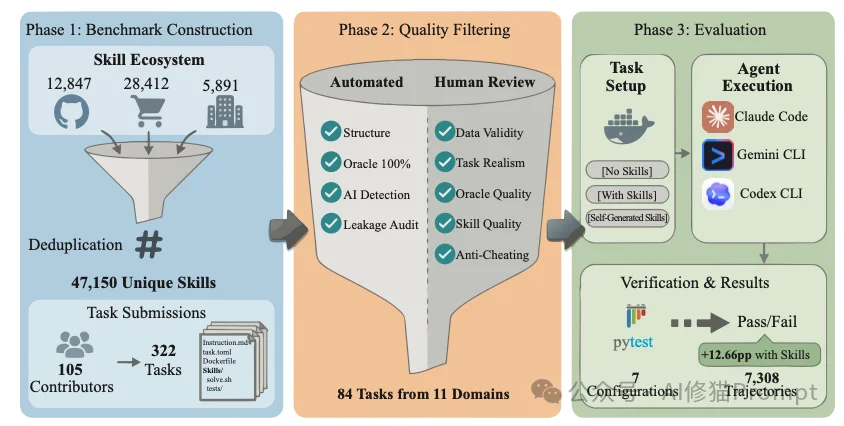
在SkillsBench中,包含86个候选任务(最终评估84个),覆盖11个专业领域。每一个任务必须作为一个自包含的目录结构运行,其内部严格规定了以下组件:
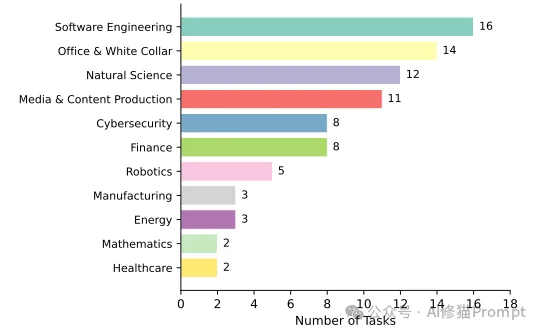
task.toml 声明容器的物理资源限制,例如设定1-4个CPU核心、2-10 GB内存,并强制限定600-1200秒的严格超时预算。solve.sh 脚本,该参考实现必须在隔离的Ubuntu 24.04容器中实现100%的测试通过率。pytest 处理,并通过CTRF(通用测试报告格式)输出JSON结果。任务仅产生二进制的0或1奖励(Pass/Fail),不存在任何部分得分(Partial credit)的模糊地带。instruction.md 绝非由AI生成。同时,技能文件内被禁止包含特定测试案例的值、常量或确切的解答命令序列。
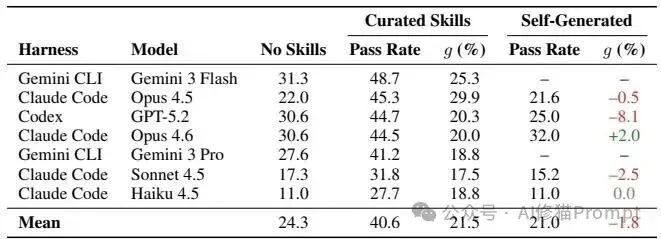
实验矩阵涵盖了Claude Code、Gemini CLI和Codex CLI三种商业外壳,搭配GPT-5.2、Claude 3家族(Opus/Sonnet/Haiku 4.5及Opus 4.6)以及Gemini 3家族(Pro/Flash)等7种模型组合。
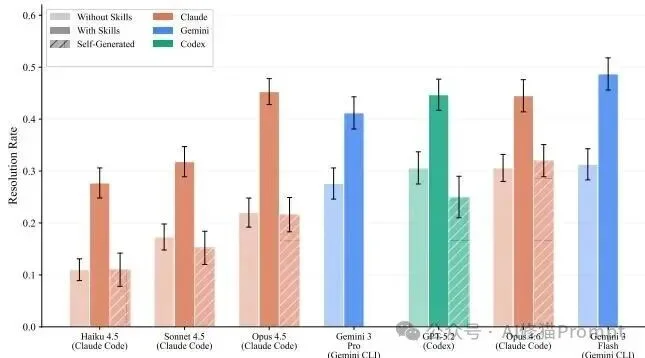
实证数据显示,人工策划的技能带来了明确的正向收益。在7种配置下,外挂技能使得平均绝对通过率提升了16.2个百分点(从24.3%提升至40.6%)。
在数据处理层面,研究者还引入了物理学教育领域的规范化增益(Normalized Gain)公式来排除天花板效应:
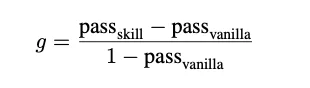
其中Opus 4.5的规范化增益达到了29.9%。
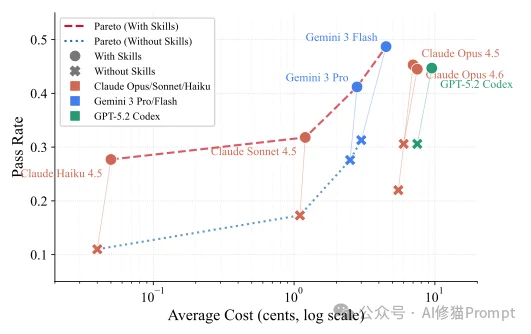
增益并非均匀分布,而是呈现出极其严重的领域异质性。
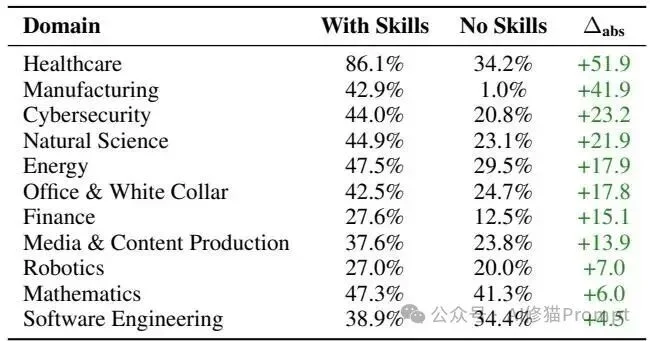
数据中最具技术价值的发现是:在评估的84个任务中,有16个任务在引入人工技能后,模型的表现反而出现了负增益(Negative Deltas)。
taxonomy-tree-merge 任务中,通过率暴跌了39.3个百分点。energy-ac-optimal-power-flow 任务中,通过率下降了14.3个百分点。 研究者的日志审查揭示了其背后的机理:当基础模型已经对某类任务拥有强大的先验知识时,强制注入的外部程序性知识如果不完全对齐模型的内部逻辑,就会引入“冲突的指导(conflicting guidance)”。此外,额外的复杂规范消耗了有限的上下文预算,导致模型在处理原本能够直接解决的问题时产生过度设计或认知过载。资深工程师深知,技能的效用不仅取决于模型智商,还取决于外壳(Harness)的调度实现。研究者在论文中揭示了深水区的技术差异:
/root/.claude/skills),让模型隐式读取 SKILL.md 的前置元数据来发现技能;而Gemini CLI则暴露出一个名为 activate_skill 的明确工具,要求模型必须主动执行显式调用。这也直接说明为什么同一个模型在不同的框架下是两种效果,对于这方面的研究感兴趣您还可以看下:

不用争CC、Codex哪个更好了,斯坦福众包设计了229个“变态”脏活已给出
既然大语言模型已经学习了GitHub上几乎所有的公开代码和StackOverflow上的工作流,开发者能否通过巧妙的系统提示词(System Prompt),让模型在执行具体任务前,先自己生成一套SOP,然后再照着执行?
研究者设置了“自生成技能(Self-Generated Skills)”条件来验证这一假设。在沙盒启动时,不提供任何人工技能,而是向模型下达明确指令要求其自行生成:
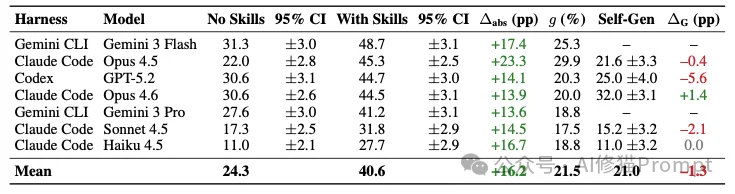
深入执行轨迹的分析表明,模型在试图输出自身所需的程序性知识时,会陷入两种致命的执行泥潭:
结论非常清晰:有效的技能必须来源于人类策划的领域专长,模型目前无法可靠地编写出它自己受益的程序性知识。
如果必须由人类工程师来编写技能包,那么其物理结构应该遵循什么规范?研究者通过量化分析,打破了“文档写得越全越好”的直觉错误。
1.数量控制与复杂度边界
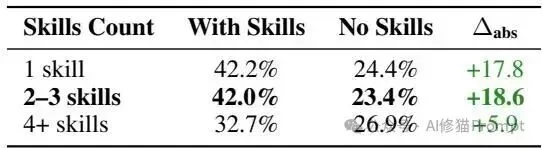
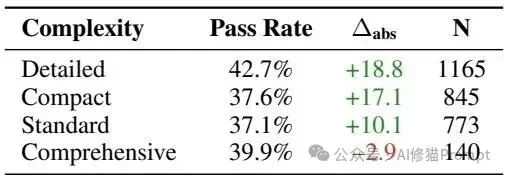
2.Token经济学与算力代偿(Token Economics) 技能的注入会显著改变模型的推理成本结构。在实际工业部署中,性能与API调用的成本权衡是不可回避的命题。

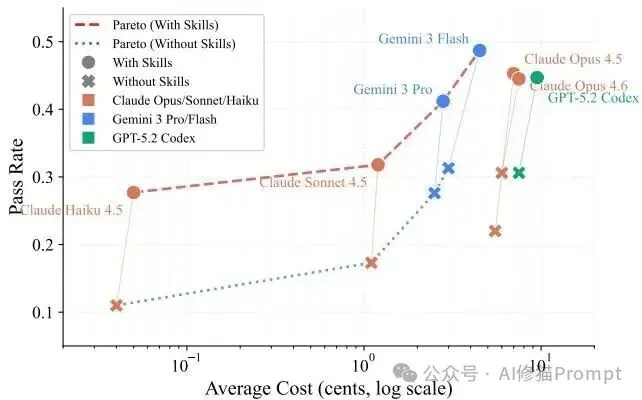
为了回答“在拥有人类高质量技能指导下,智能体为何依然失败”的问题,研究者对不涉及基础设施错误的5,171次智能体崩溃轨迹进行了详细的分类学尸检(Autopsy)。通过解析 pytest 日志和容器状态,失败被精确归入五个类别。
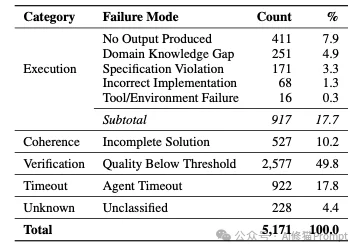
1.验证阈值失败(Quality Below Threshold) 占比49.8%这是智能体最主要的死因。模型完全遵循了指示,执行了完整的逻辑闭环,生成了目标文件,但其中的工程计算或数据抽取存在难以容忍的偏差。


2.执行超时(Agent Timeout)占比17.8%在严格限定的时间(例如900秒)内未能输出最终结果并退出。

gravitational-wave-detection(引力波探测)时,由于需要构建复杂的带通滤波和信噪比计算管线,多数模型直接耗尽了计算窗口被强行终止。3.相干性断裂(Incomplete Solution)占比10.2%模型过早地宣告任务完成,提交了结构正确但内容残缺的工程产物。

shock-analysis-supply 任务中,模型成功构建了目标Excel的基础结构,甚至完成了部分数据导入(通过了9个测试中的6个)。但它遗漏了三个计算负荷最大的步骤:加载宾州世界表(PWT)的劳动力数据、运行HP滤波优化求解器,以及计算折旧率。这反映了长上下文任务中模型规划能力的阶段性衰退。4.早期流产(No Output Produced)占比7.9%要求输出的文件完全不存在,测试断言在第一步就触发了断点。

gh-repo-analytics 任务中,测试桩提示“Missing /app/report.json”。因为该任务要求与本地Gitea服务器交互并拉取仓库,智能体在最基础的Git凭证处理或依赖环境配置上失败,导致整个工作流被彻底卡死,未执行任何实质性逻辑。5.规范违规(Specification Violation)占比3.3%模型抗拒或忽视了绝对硬性的输出格式要求。

latex-formula-extraction 任务中,指令明确要求逐行输出由 $$ 包裹的纯净LaTeX公式。然而,模型“画蛇添足”地在最终的文本文件里加上了Markdown标题和序号解释,导致基于正则表达式的测试脚本直接判零。这种自作聪明的输出习惯展示了指令微调(Instruction Tuning)中讨好人类视觉输出与严格机读约束之间的冲突。6.成功的反例证明

作为对比,能够大幅逆转局面的成功案例则清晰展现了技能的运作机理。在 sales-pivot-analysis 任务中,无技能干预时,所有测试模型(包括GPT-5.2等)全部获得了0%的通过率。模型试图使用笨拙的DataFrame变形逻辑去手写透视表逻辑,引发大面积数组越界异常。而一旦挂载了关于 openpyxl 库特定透视表创建API的技能文档,6种模型立刻获得了超过80%的通过率(平均增益达 +85.7个百分点),展现了精准挂载API规范的强大杠杆效应。
论文最有工程参考价值的界限在于,在全部84个评估任务中,有16个任务(占比19%)在挂载了完美人工技能、使用最高阶大模型的情况下,依然维持着0%的全局通关率。这揭示了当前智能体体系无法跨越的三个物理断层:

gravitational-wave-detection)以及量子数值模拟等任务,彻底耗尽了当前的迭代时间预算。《SkillsBench》的实证结果向所有构建下一代智能体的工程师传递了不容忽视的信号:
当我们在内存中向智能体注入SOP规范时,本质上是在进行一种低成本、即插即用的微调。在这个没有主观法官的确定性测试场里,数据已经证明:精准的工艺手册,依然是驾驭庞大算力野兽的最佳缰绳。
文章来自于微信公众号 "AI修猫Prompt",作者 "AI修猫Prompt"


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
