# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

伴随多模态大模型的发展,GUI Agent正成为人机交互的新范式。
但在实际生产环境中,构建一个高可用、跨平台的GUI Agent面临诸多工程与算法挑战。
真实环境充斥着验证码与异常弹窗导致长轨迹数据极难收集。不同平台如手机、桌面、浏览器的动作空间存在显著差异,混合训练容易引发梯度冲突。同时,真实任务通常需要模型具备长程记忆、工具调用及多Agent协作能力。
为了解决原生GUI模型在端到端落地中的技术壁垒,阿里巴巴通义实验室开源了新一代多平台GUI Agent框架Mobile-Agent-v3.5,并同步发布了其背后的原生基座模型家族GUI-Owl-1.5。
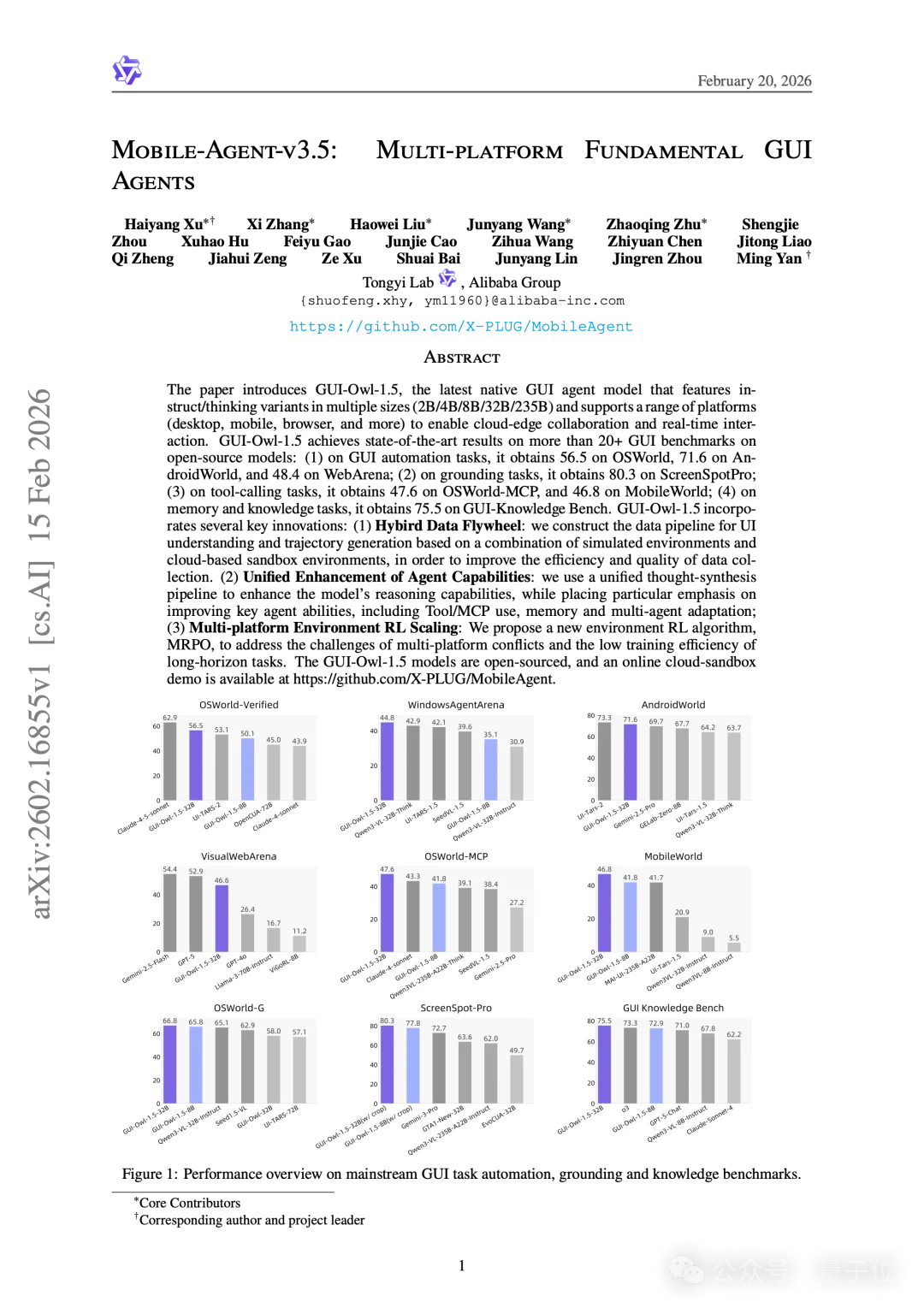
该模型家族在20多个主流GUI Benchmark上取得了开源领域领先的测试结果,实现了跨桌面、手机、浏览器等多端的统一控制。项目开放了从2B到32B的多种参数尺寸,并针对实际部署需求解耦出Instruct和Thinking两种模型变体,以支持从端侧极速响应到云端复杂推理的全链路应用。
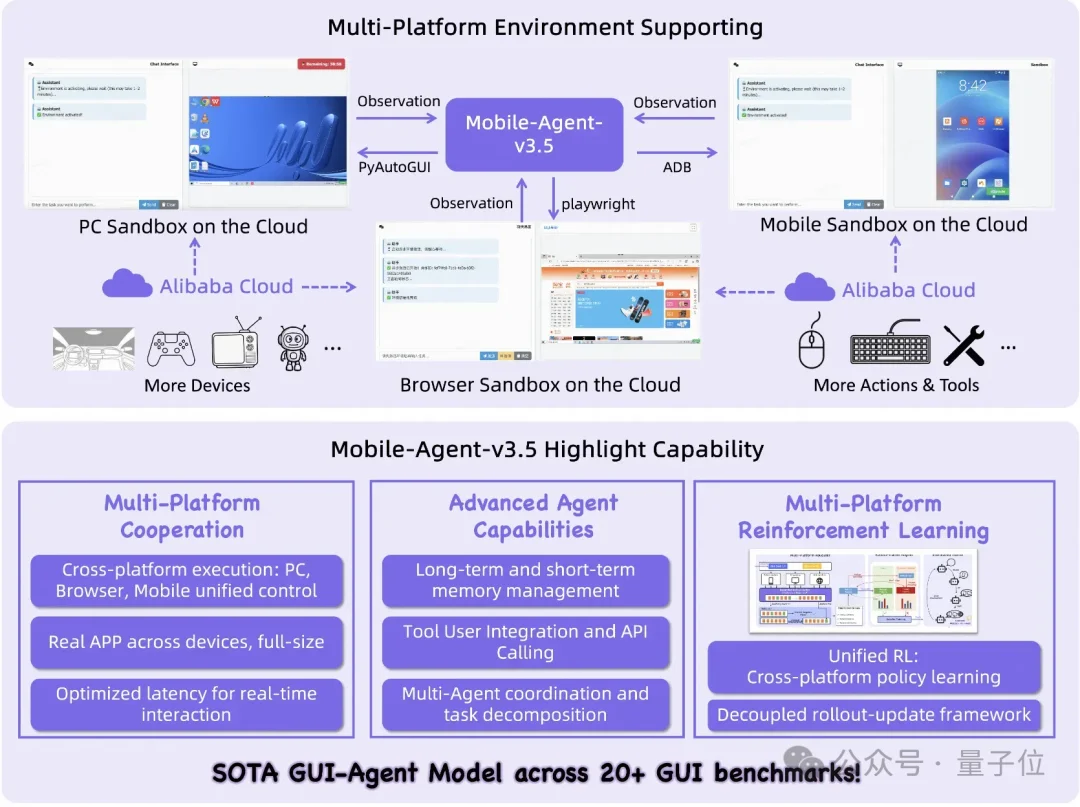
在实际的GUI自动化场景中,任务的复杂度跨度极大。为了兼顾响应延迟与推理深度,GUI-Owl-1.5提供了两种不同架构侧重点的模型变体。
Instruct模型被设计为专注极速响应与轻量化执行,它不输出思考链,直接基于当前上下文给出动作决策,非常适合部署在算力受限或隐私要求较高的端侧设备上处理高频实时交互。Thinking模型则专攻长程复杂任务,具备完整的思维链能力,能够进行详尽的规划、反思与纠错。
这两种形态为端云协同提供了基础架构。云端的大参数Thinking模型可作为规划者拆解复杂任务,端侧Instruct模型作为执行者完成原子操作,从而构建出高效的多Agent协作系统。
除了基础的纯GUI交互,Mobile-Agent-v3.5在动作空间上原生支持了外部工具调用与MCP(Model Context Protocol)协议。Agent在遇到复杂计算或数据库查询时,可以直接调用API完成工作流闭环。
GUI-Owl-1.5的性能表现不仅来源于参数规模的扩展,更在于其在数据管线构建、Agent内在逻辑重塑以及强化学习算法上的底层重构。
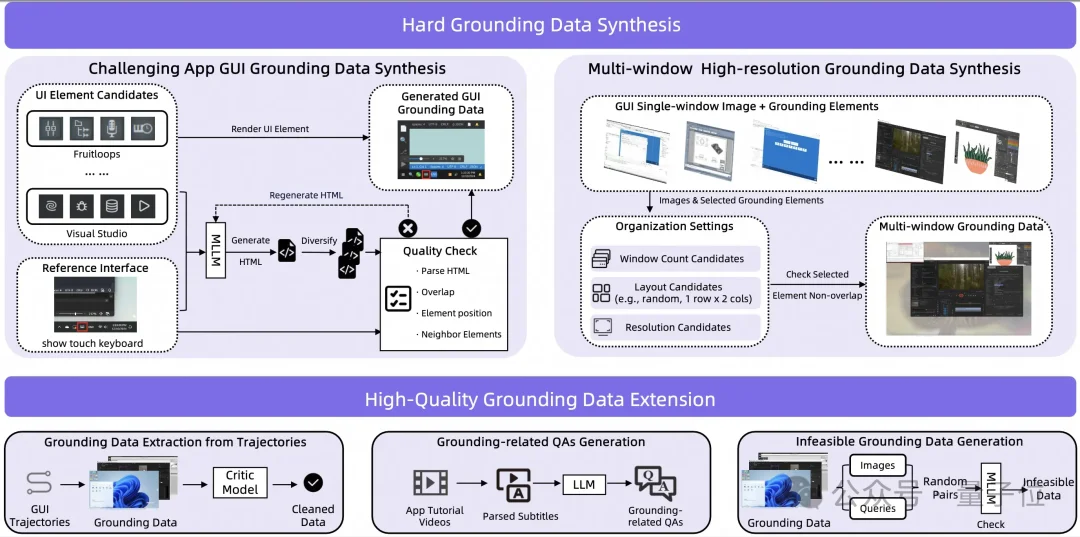
高质量的Grounding(视觉定位)和长轨迹数据是训练GUI模型的关键。研发团队放弃了单纯依赖真实设备硬采的低效路线,构建了一套混合数据生产管线。
在Grounding数据层面,针对专业软件和复杂多窗口的高难度场景,团队利用多模态模型结合参考界面进行多轮校验,直接合成高分辨率的复杂UI截图。
为了实现规模化扩展,算法通过轨迹挖掘和App教程字幕解析抽取海量交互问答。团队还特别引入了大规模的Infeasible Query(不可行查询)负样本,通过随机配对并经过多模型共识过滤,让模型学会在找不到目标控件时主动拒绝操作。
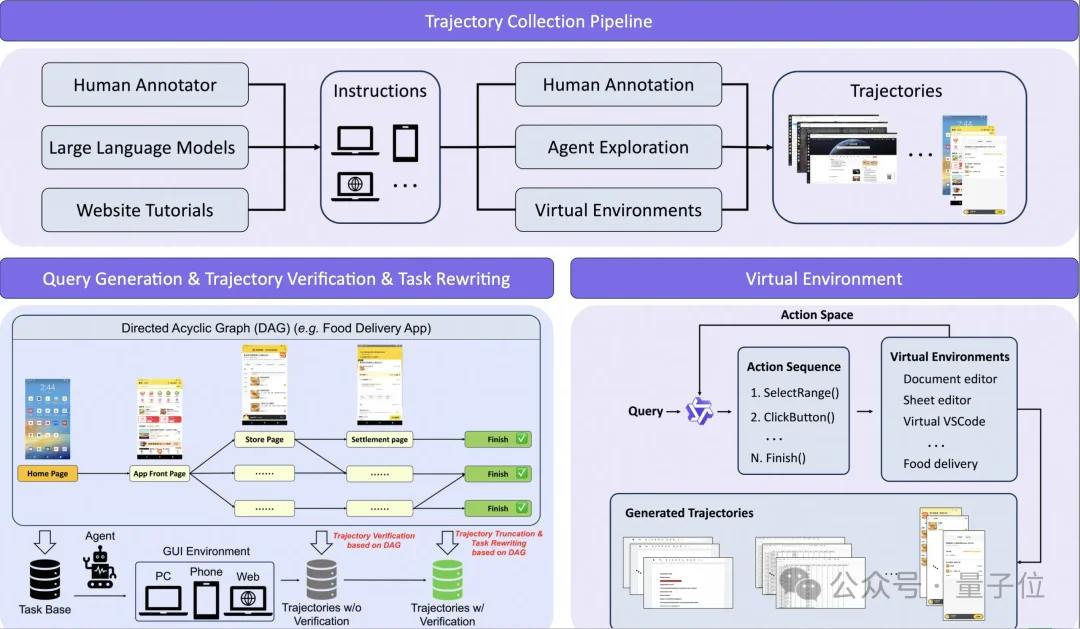
在轨迹数据生产上,研究团队引入了基于有向无环图(DAG)的任务合成机制。真实环境中动辄出现报错和反爬弹窗,为此系统设计了截断与任务修复机制。
当Agent在某一步失败时,系统会自动将轨迹回溯并截断到上一个正确的检查点,随后重写任务指令,将部分正确的轨迹转化为高质量的前缀监督数据。对于充满验证码的高频场景,团队基于Web渲染构建了大量虚拟环境,通过精准的环境反馈低成本生成了海量专家轨迹。
一个工程可用的Agent必须具备上下文记忆与状态预测能力。模型在训练阶段通过抓取全网软件官方文档和问答论坛数据掌握了软件常识。同时,研发团队利用轨迹记录训练模型进行状态转移预测,要求模型在执行动作前预判下一屏的UI会发生什么变化(例如焦点是否转移、弹窗是否出现),以此降低长程决策的试错成本。
更核心的改造在于统一的CoT合成流水线。收集到的所有多端轨迹数据都被进行了思维扩充。在每一步动作发生前,模型被要求输出结构化的中间状态,包括观察当前屏幕的关键信息、提取后续任务需要的记忆数值、反思上一步的操作结果是否符合预期并进行纠错,最后综合这些信息与外部工具定义来决策具体的GUI动作。这种训练方式让模型获得了优秀的全局任务规划能力。
在强化学习阶段,试图用单一策略同时控制手机、PC和浏览器极易引发梯度冲突与训练崩溃。为此,团队提出了MRPO(Multi-platform Reinforcement Policy Optimization)算法,精准解决了端到端RL训练中的几个核心工程痛点。
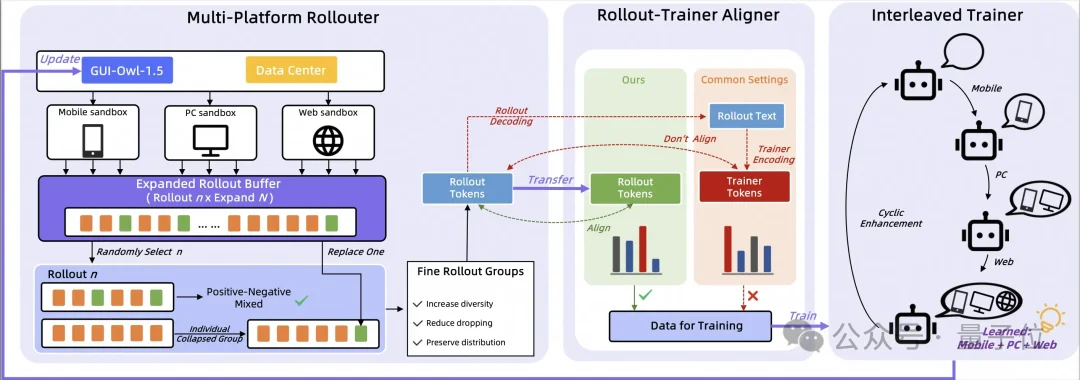
首先是克服GRPO训练中的结果坍塌问题。
GUI任务的容错率极低,这给基于GRPO的分组强化学习带来了独特挑战。在标准GRPO中,系统会为每个任务x采样一组n条轨迹{τi}ni=1,通过组内轨迹的结果差异来计算优势函数。然而在GUI场景下,这n条轨迹常常会全部成功或全部失败,导致结果坍塌,组内方差为零,优势估计失效,大量采样组被直接丢弃。
简单引入Replay Buffer虽然能增加样本多样性,但会破坏On-policy的分布假设。团队设计的在线过采样机制巧妙地在保持On-policy前提下解决了这一问题。系统先为任务x从当前策略πθ超量采样kn条轨迹(k>1)构成候选池Gkn(x)={τi}kni=1,随后从这个候选池中均匀随机下采样n条轨迹组成实际训练组Ĝn(x)。
关键在于后续的条件替换策略。记二值结果函数为Z(τ)∈{0,1}表示成功或失败,候选池的多样性事件定义为
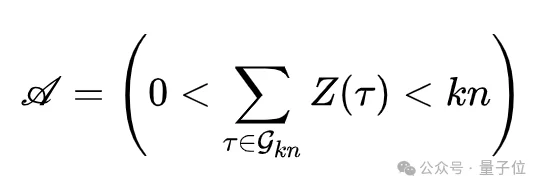
若下采样得到的训练组仍然所有轨迹结果相同而坍塌,但池中存在异质样本(即事件A发生),系统会随机替换训练组中的一条轨迹为池中结果相反的轨迹。这个操作保证了
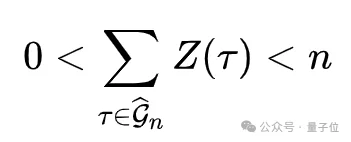
使训练组内同时包含成功和失败案例。
由于候选池中的所有kn条轨迹都是从当前策略πθ(·∣x)独立采样,均匀下采样和条件替换操作在数学上保持了边际分布的一致性:
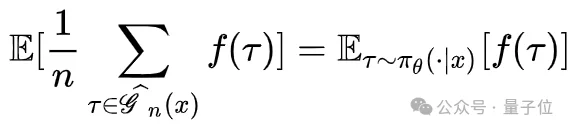
这对任意统计量f都成立。换言之,这套机制在不引入Off-policy偏差的前提下,对于成功率为p的任务,将非坍塌训练组的出现概率从
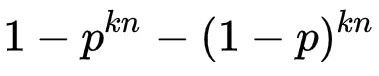
提升到接近1,大幅提升了训练效率。
其次是Token-ID对齐机制。
多平台RL训练中,环境推理服务与训练服务通常部署在不同进程甚至不同机器。环境端执行策略采样生成动作序列y,并将其作为文本返回给训练端计算策略梯度。这里隐藏着一个致命陷阱:如果推理端和训练端使用的分词器对同一文本y的切分方式不完全一致,训练端计算的对数概率log πθ(y|x)train-tokenize(y)就会与环境端实际采样时的概率log πθ(y|x)infer-tokenize(y)产生系统性偏差。这种偏差会破坏KL散度约束和策略梯度估计的数学基础,导致训练不稳定甚至发散。
MRPO的解决方案是直接传输Token IDs而非文本。环境端在采样序列y时,将推理过程中实际使用的Token序列tinfer=(t1,t2,…,tL)与文本一同打包返回。训练端收到(tinfer,y)后,不再对文本y重新分词,而是直接在固定的Token序列上计算自回归概率:
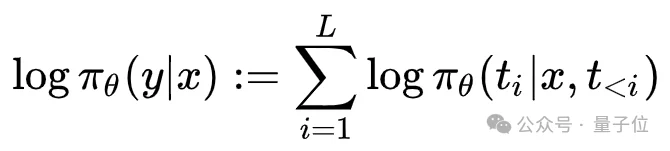
这种Token-ID传输机制从根本上锁死了采样时刻与训练时刻的离散事件空间,保证了概率计算的严格一致性。
最后是交替多平台优化策略:
统一策略πθ(a|o,d)需要同时适配移动、桌面、Web三个平台(d∈𝔻={mobile,desktop,web}),每个平台有各自的动作空间𝒜d和UI交互范式。如果在训练时混合来自不同平台的轨迹组成批次,来自平台d1的策略梯度
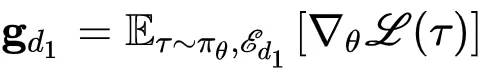
和平台d2的梯度gd₂可能频繁出现负内积⟨gd₁,gd₂⟩<0。这种梯度冲突会导致混合更新
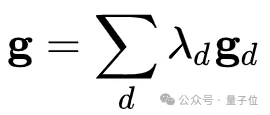
方向不稳定,优化过程陷入“拉锯战”,模型在不同平台间反复震荡而难以收敛。
MRPO采用交替优化策略来解耦平台间的梯度干扰。具体而言,训练过程被划分为多个阶段s=1,2,…,每个阶段s只从单一平台ds∈D的环境中采样轨迹并更新模型:θ(s+1)←θ(s)−ηgds。
平台按循环方式轮换(如mobile→desktop→web→mobile)或采用课程学习策略选择ds。这种交替优化隔离了设备特定的适配过程,同时保持共享骨干网络,既提升了稳定性又保留了跨设备泛化能力。
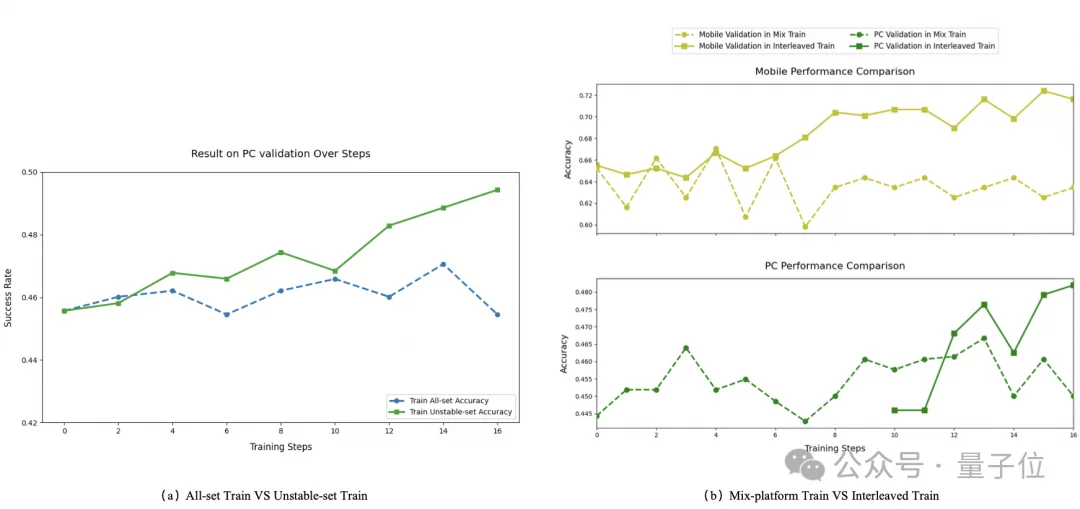
从实验结果可以看出,MRPO首先在手机端获得了效果的提升,随后切换为PC端训练,PC端效果提升的同时没有对手机端效果造成显著的影响。相比于混合训练,MRPO能够在不同端上的效果实现增长。
研发团队在横跨GUI自动化、Grounding定位、工具调用、记忆与知识等维度的20余个主流基准上对GUI-Owl-1.5进行了严格评测。结果显示,该模型家族不仅在多平台泛化上表现优异,在多项核心指标上也确立了开源领域的新SOTA。
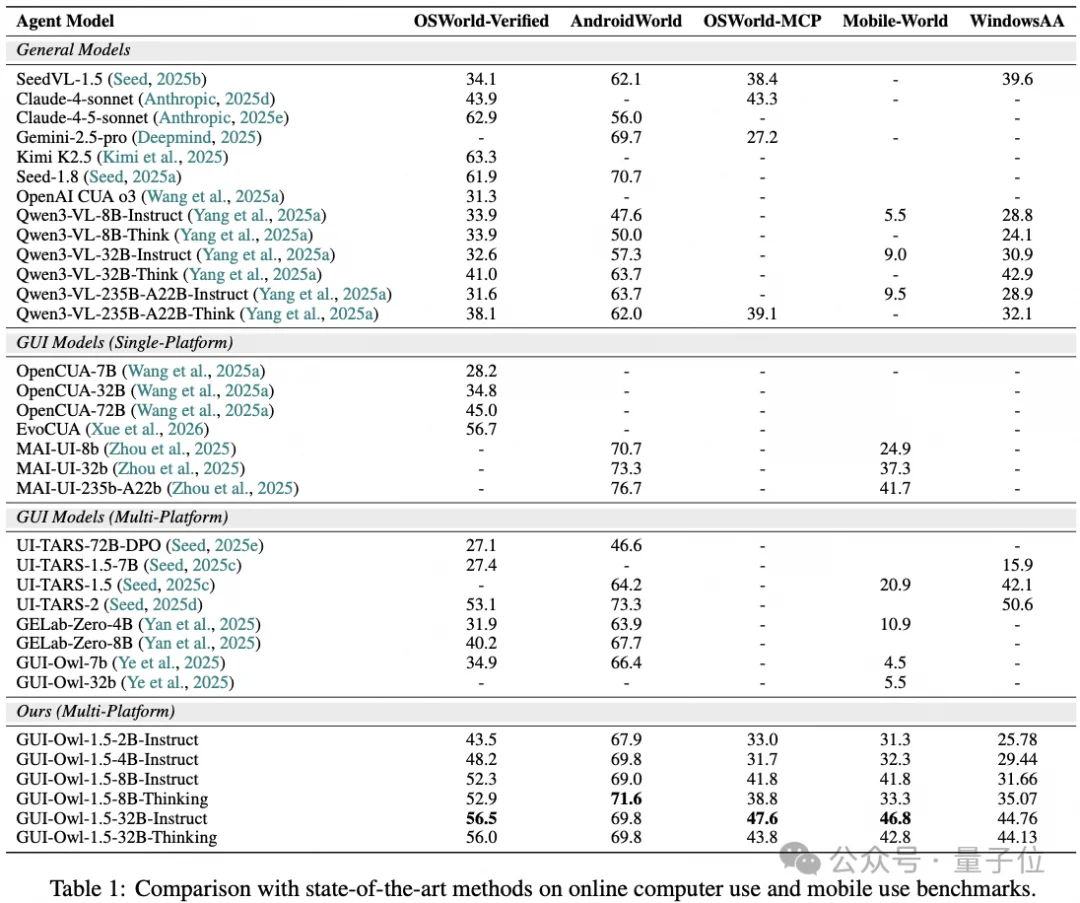
端到端交互是检验Agent真实可用性的核心标准。如上表所示,在最受关注的桌面端环境OSWorld-Verified中,GUI-Owl-1.5-32B-Instruct取得了56.5的优异成绩,设定了整体的性能天花板。
同时,模型展现出了极高的参数效率:其8B-Thinking变体达到了52.9,不仅超越了同等规模的UI-TARS-2(53.1),更越级超越了参数量大数倍的Qwen3-VL-235B-A22B-Think(38.1);轻量级的2B版本也拿到了43.5的分数,这验证了混合数据与CoT合成管线对模型基础能力的有效下放。
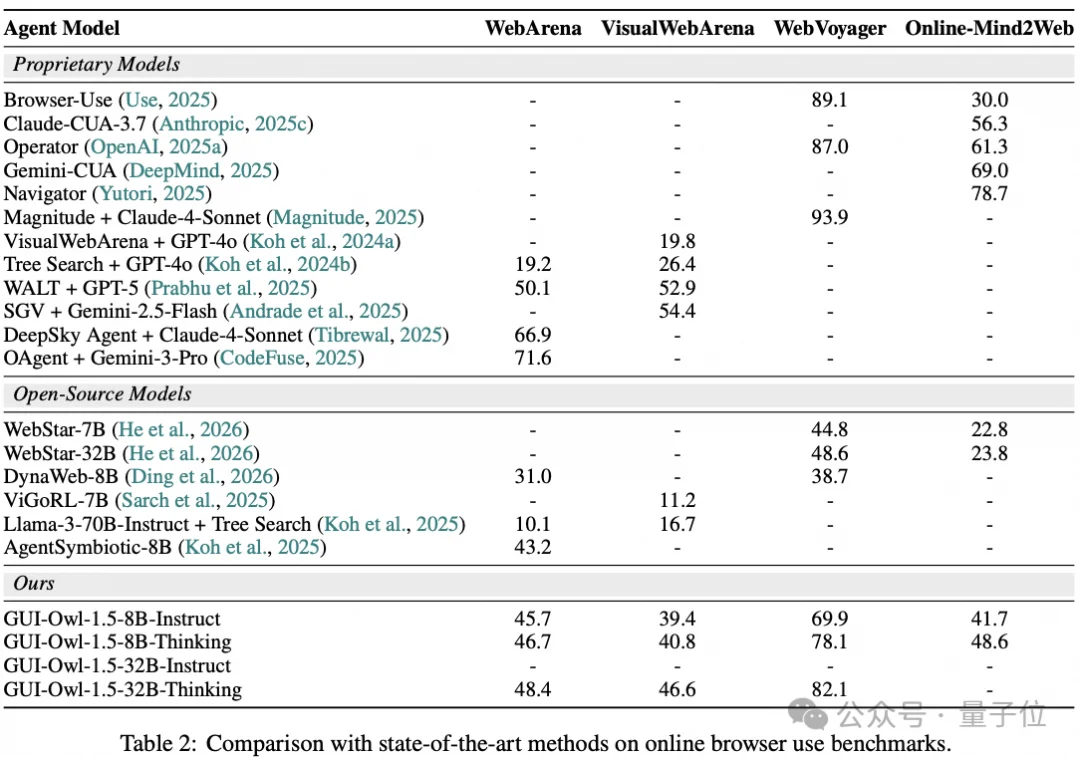
在移动端AndroidWorld中,8B-Thinking同样取得了71.6的高分。在浏览器端的WebArena与VisualWebArena中,32B-Thinking分别达到48.4和46.6,大幅领先于多数开源基座模型。值得注意的是,在需要长程规划的网页任务(如WebVoyager)中,Thinking变体的分数(82.1)显著高于Instruct变体,充分证明了强制输出思维链对复杂步骤决策的巨大增益。
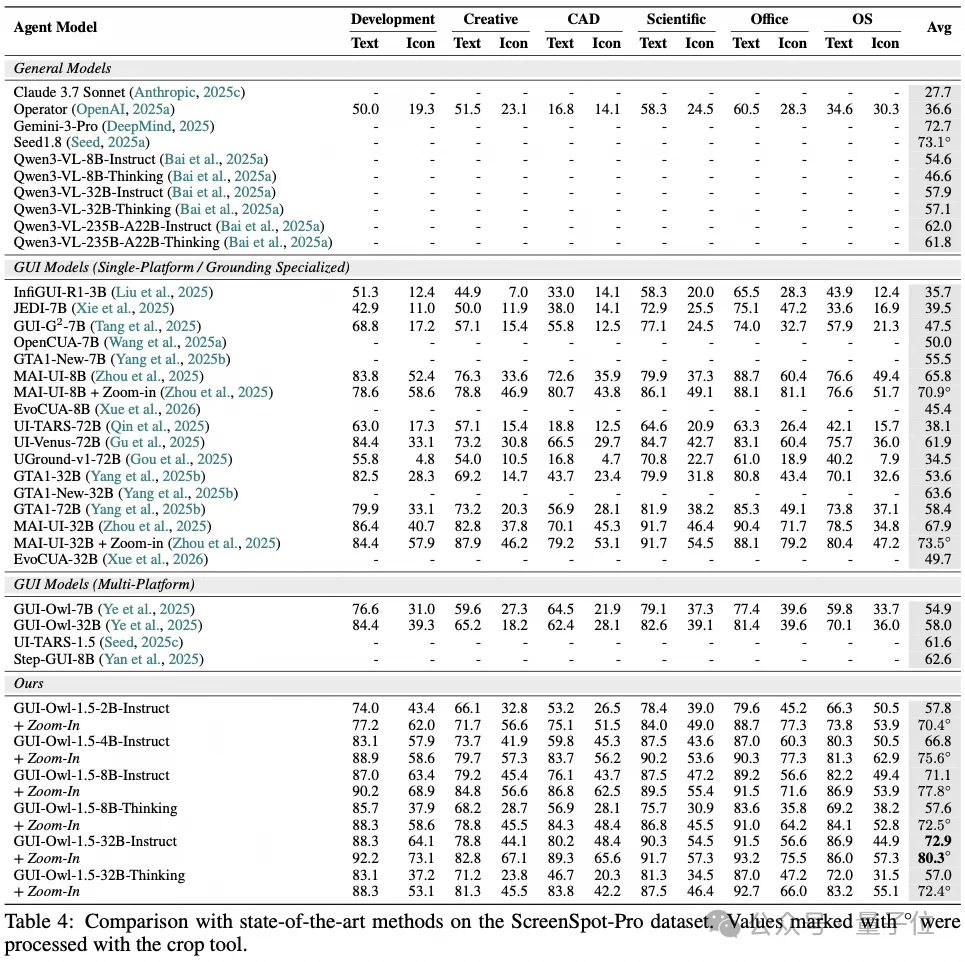
屏幕解析与坐标映射是执行GUI动作的基石。在考验专业软件超高分辨率定位的ScreenSpot-Pro基准中,GUI-Owl-1.5-32B-Instruct在不使用任何裁剪工具(Crop)的Base设置下即达到72.9,这已经超越了包含大型闭源模型(如Gemini-3-Pro的72.7)在内的所有对比方案。当结合两阶段的Zoom-In(Crop Refine)策略后,其准确率进一步飙升至80.3,实现了断层式领先。
在需要混合GUI操作与代码/API调用的OSWorld-MCP榜单中,32B-Instruct取得了47.6的分数,优于专攻单平台的垂类模型以及部分主流闭源模型,证明其不仅能“看图点按”,还能与外部工具链深度结合。此外,在考察模型界面解析的GUI Knowledge Bench以及考察长程历史追溯的MemGUI-Bench中,该模型同样稳居Native Agent模型的第一梯队。
除了在标准化基准测试中的量化得分,研发团队在论文中还展示了几个高难度的真实链路Case,直观体现了GUI-Owl-1.5突破单步点击限制、执行复杂工作流的综合能力。
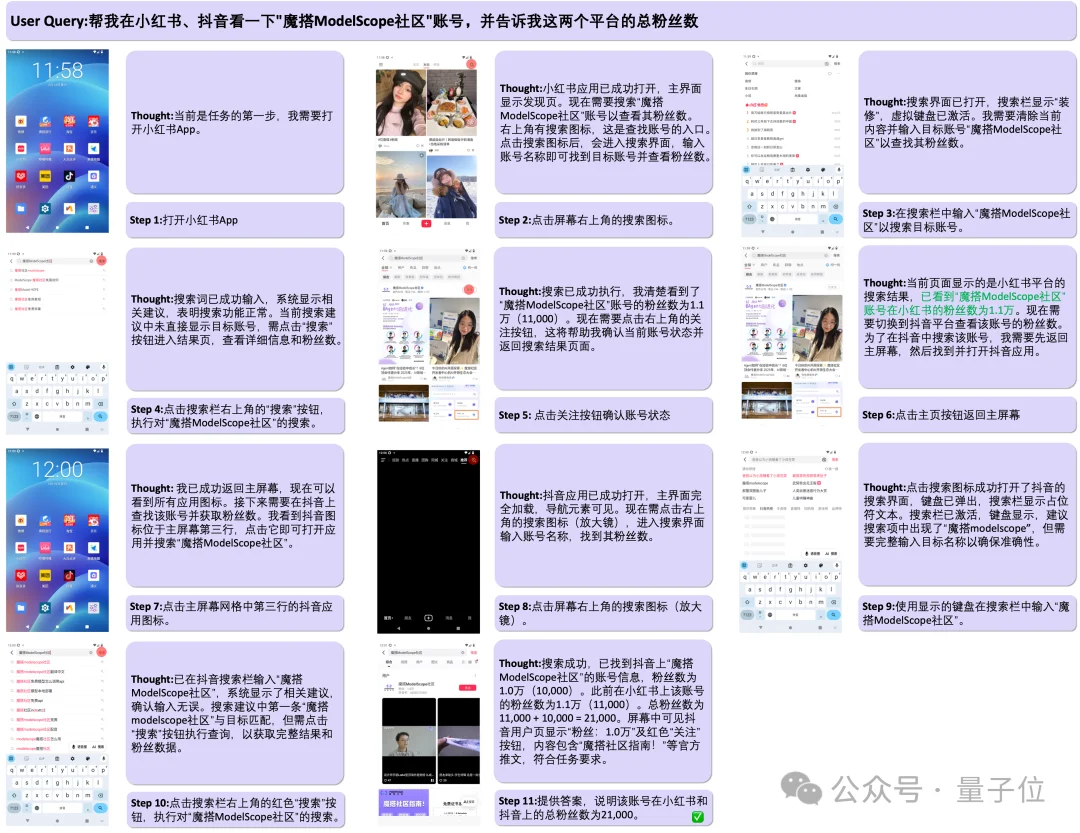
在移动端测试用例中,用户下达了一个复合指令:要求统计“魔搭社区”在小红书和抖音两个平台的总粉丝数。
面对这种非标准化的操作,GUI-Owl-1.5展现出了极强的任务拆解与记忆管理能力。模型首先唤起小红书App,通过视觉定位找到搜索框并输入账号,成功读取界面上的粉丝数据后,将其写入框架的内部记忆块(Memory)中。
随后,Agent主动退回桌面并切换至抖音App,重复搜索与提取的逻辑。在获取到第二个数据后,模型提取前序记忆中的数值进行汇总计算,最终向用户输出准确的总粉丝数。这一流程不仅验证了模型在不同UI布局下的泛化识别能力,更证明了前文提到的“统一CoT合成流水线”赋予了模型跨步信息保持与逻辑推理的真实业务价值。

在Windows桌面端的测试用例中,模型需要独立完成一项“网页搜索+资料整理”的综合任务。
与单屏点按不同,PC端的原生操作充斥着大量不可预测的系统反馈。为了完成目标,Agent准确执行了多步连贯的底层GUI交互。它不仅要在浏览器中完成信息的检索与定位,还需要在操作系统层面调用记事本应用,并在两个相互独立的窗口之间进行焦点的频繁切换、文本复制与编辑。
在这个过程中,基于此前注入的世界模型先验知识,Agent能够精准预判“点击后弹窗是否出现”以及“输入光标的具体位置”,从而在复杂多窗口的真实桌面环境中保持了极低的操作错误率。
从演示Demo到能在多端稳定执行长流程的工程级Agent,需要跨越诸多数据流与强化学习算法上的障碍。Mobile-Agent-v3.5的发布提供了一次系统性的技术参考。通过将底层基座模型、多端统一的动作空间设计以及经过工程验证的RL训练范式彻底开源,希望能为整个技术社区的GUI Agent探索提供一个坚实的基础。
目前模型权重、Agent框架源码以及在线云端沙箱体验Demo均已在GitHub开放,欢迎开发者前往查阅源码并进行技术交流。
项目开源及源码地址:
https://github.com/X-PLUG/MobileAgent
文章来自于“量子位”,作者 “通义千问团队”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】kimi-free-api是一个提供长文本大模型逆向API的开渔免费技术。它支持高速流式输出、智能体对话、联网搜索、长文档解读、图像OCR、多轮对话,零配置部署,多路token支持,自动清理会话痕迹等原大模型支持的相关功能。
项目地址:https://github.com/LLM-Red-Team/kimi-free-api?tab=readme-ov-file
