# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近日,一篇名为《SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks》的论文预印本引爆了海外 AI 社区,YC 总裁 Garry Tan 亲自转发,登顶 Hacker News(363 票 / 163 评论),霸榜 AlphaXiv #1, 被 HuggingFace 和 DAIR.AI 收录 weekly paper。英国老牌科技媒体《The Register》以 「AI Agents can't teach themselves new skills」进行专题报道。
这项由来自 BenchFlow、斯坦福大学、卡内基梅隆大学(CMU)、加州大学伯克利分校(UC Berkeley)、牛津大学、俄亥俄州立大学(OSU)、北京理工大学等顶尖高校,以及亚马逊(研究者以独立学术身份参与)、字节跳动、富士康、Zenity 等科技企业的 36 位学者(横跨 23 家产学研机构)联合撰写,并集结了 开源社区的 105 位领域专家共同贡献的论文,究竟揭开了 Agent 发展道路上的什么残酷真相?

Skills 生态爆发:从 Claude Code 到 OpenClaw,跨平台标准加速形成

Agent Skills(智能体技能)是一种在推理时(Inference time)动态增强 LLM Agent 的结构化程序性知识包。它通常由一个 SKILL.md 指令文件加上可选的可执行资源(如脚本、模板、代码)组成。
与传统的 System Prompts、RAG 检索和 Tool Documentation 有着本质区别 ——Skills 是目前唯一同时具备模块化复用、程序性指导、可执行资源和跨模型可移植性的增强方式。
其架构类比非常直观:基础模型相当于 CPU,Agent Harness(智能体框架)相当于操作系统,而 Skills 则是挂载其上的应用程序。
目前,Skills 生态正在经历野蛮生长。据论文统计,研究团队从开源仓库(12847)、Claude Code 生态(28412)和企业合作伙伴(5891)三个主要来源,聚合到了高达 47150 个个去重后的独立 Skills。
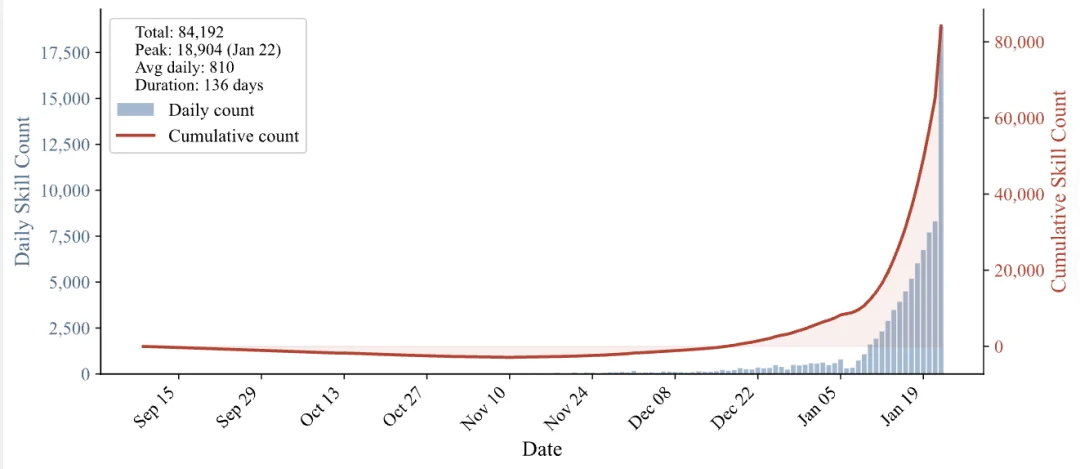
图 1:Agent Skills 数量的指数级增长趋势。在 136 天的时间跨度内,社区创建的 Skills 累计总量攀升至 84192 个,日均新增 810 个,单日新增峰值更是高达 18904 个(1 月 22 日)。
Anthropic 的 Claude Code 率先定义了 Agent Skills 规范,Google 的 Gemini CLI 和 OpenAI 的 Codex CLI 等随后跟进支持 Skills 加载,最近火爆全网的 Agent 平台 OpenClaw 更是完整采纳了该规范并使用 skills 系统实现工具调用。OpenClaw 在文档中明确表示「We follow the AgentSkills spec for layout/intent」,实现了三层 Skills 加载体系:


此外,OpenClaw 还引入了 Load-time Filtering 机制 —— 基于所需二进制、环境变量和平台条件自动筛选 Skills,每个 Skill 元数据仅约 24 tokens。与此同时,Google 的 Gemini CLI 和 OpenAI 的 Codex CLI 同样支持 Skills 加载。Skills 已从单一平台特性演变为跨生态行业标准。
然而,在此之前,业界并没有一个标准的方法来衡量这些 Skills 是否真正有效 —— 挂载 skills,究竟是让 Agent 变聪明了,还是仅仅增加了上下文的噪音?SkillsBench 正是为了回答这一核心工程问题而生。
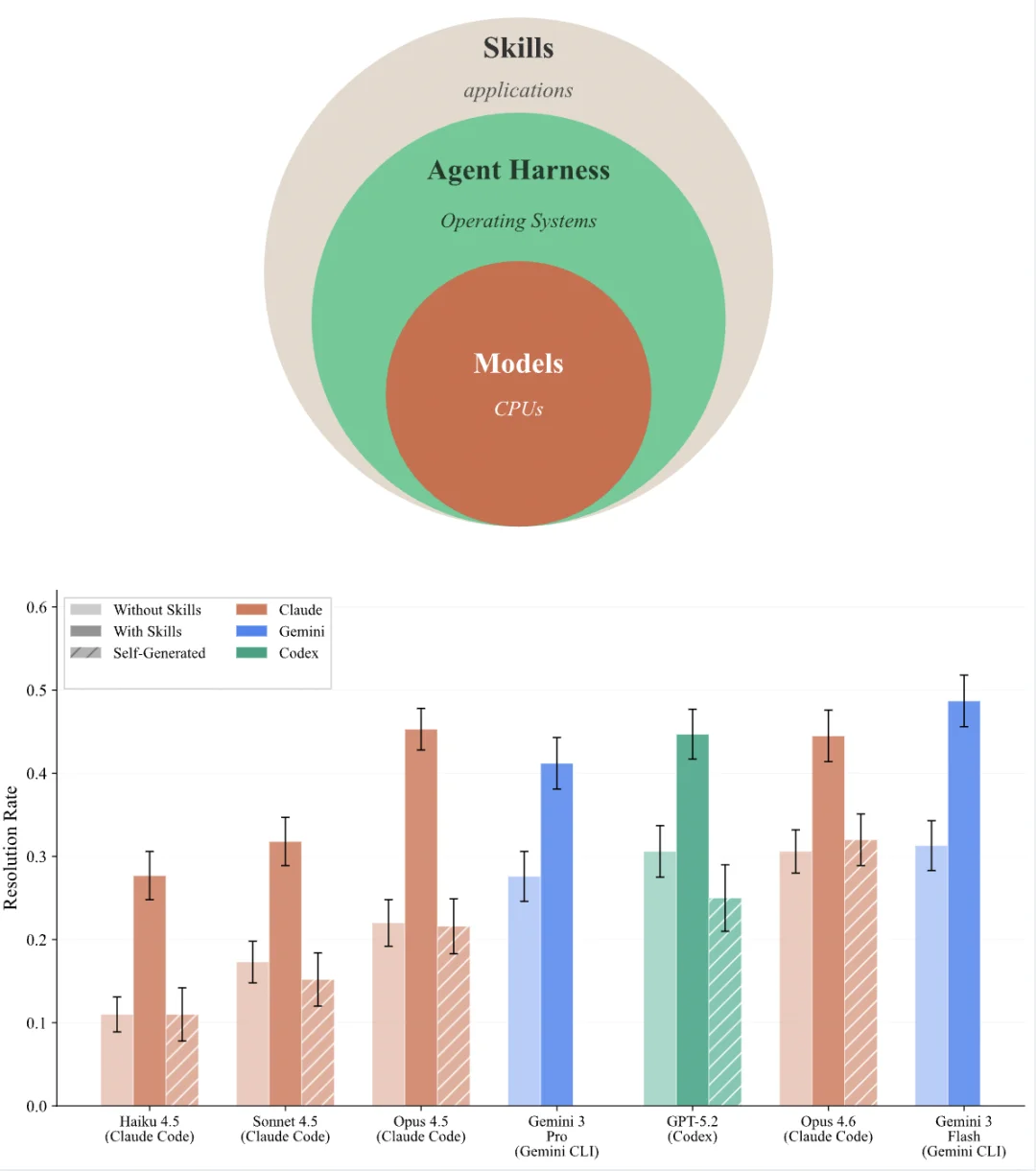
图 2:Agent 架构栈(Skills→Harness→Models 类比 Applications→OS→CPUs)与主实验结果。人类策划的 Skills 带来 + 16.2pp 平均提升,自生成 Skills 反降 - 1.3pp。
研究设计:拒绝「大模型当裁判」,打造最严苛的测试场
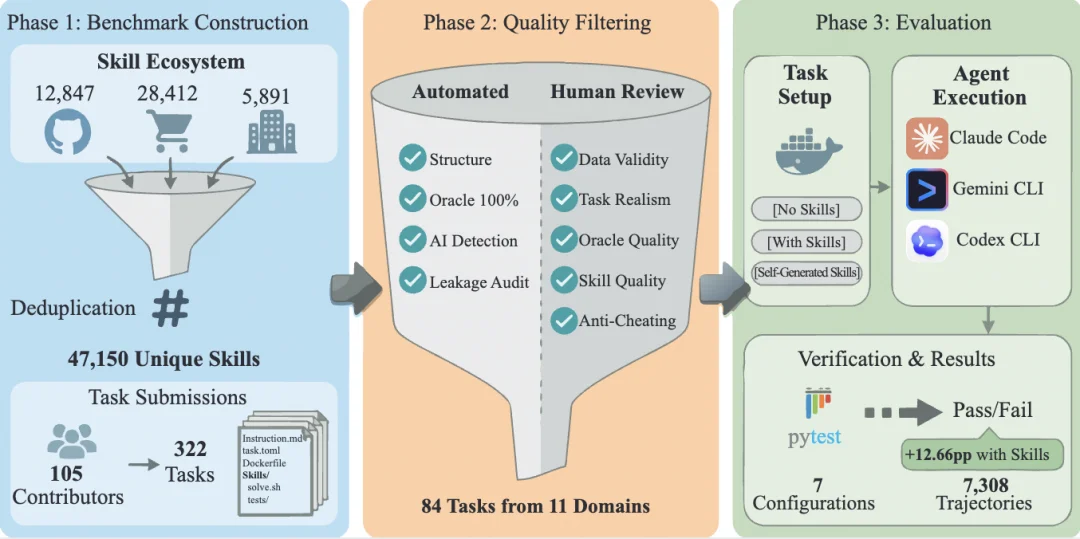
图 3:SkillsBench 端到端 Pipeline 概览。Phase 1(基准构建):从三大来源聚合 47150 个去重 Skills;105 位贡献者提交 322 个候选任务。Phase 2(质量筛选):经自动化检查(结构验证、AI 检测、泄露审计)与人工审核(数据有效性、任务真实性、Oracle 质量、Skill 质量、防作弊),筛选出 86 个任务(84 个参评),覆盖 11 个领域。Phase 3(评估):在 Docker 容器中跨 3 种条件、3 种商用 Agent(Claude Code、Gemini CLI、Codex CLI)评估,pytest 确定性验证产出 7308 条轨迹。
为了确保评估的客观性,研究团队向开源社区征集了 322 个候选任务,经过 105 位领域专家的严格筛选(涵盖自动化结构验证、标准答案 Oracle 必须 100% 通过、使用 GPTZero 确认为人类编写、泄露审计 CI 等测试),最终保留了 86 个高质量任务(84 个参评),横跨 11 个专业领域。

测试覆盖了当前最顶尖的 7 种 Agent - 模型配置(Claude Code + Opus 4.5/4.6/Sonnet 4.5/Haiku 4.5,Gemini CLI + Flash/Pro,Codex CLI + GPT-5.2)。评估彻底抛弃了饱受诟病的 LLM-as-judge 模式 —— 全部 7,308 条运行轨迹均在独立的 Docker 容器中执行,并采用进行代码级的确定性验证。
每个任务都在三种条件下进行严格的对照评估:无 Skills、专家人工构建的 Skills、AI 自生成的 Skills。
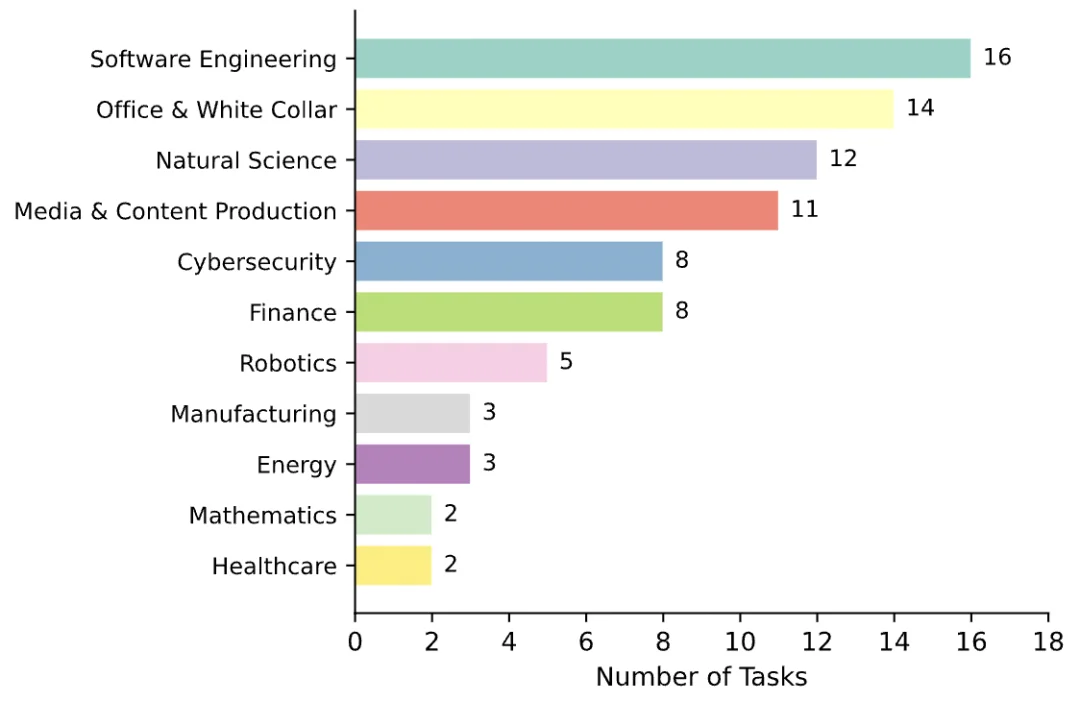
图 4:SkillsBench 任务的领域分布。涵盖 11 个领域:Software Engineering(16)、Office & White Collar(14)、Natural Science(12)、Media & Content Production(11)、Cybersecurity(8)、Finance(8)、Robotics(5)、Manufacturing(3)、Energy(3)、Mathematics(2)、Healthcare(2)。任务按人类专家完成时间分三级难度:Core(<60 分钟,17 个)、Extended(1-4 小时,43 个)、Extreme(>4 小时,26 个)。
四大核心发现
发现一:人工构建的 Skills 带来 +16.2pp 的飞跃
注入专家人工构建的 Skills 后,Agent 的平均成功率从 24.3% 跃升至 40.6%,获得了 16.2 个百分点的绝对提升。各配置的具体表现如下:
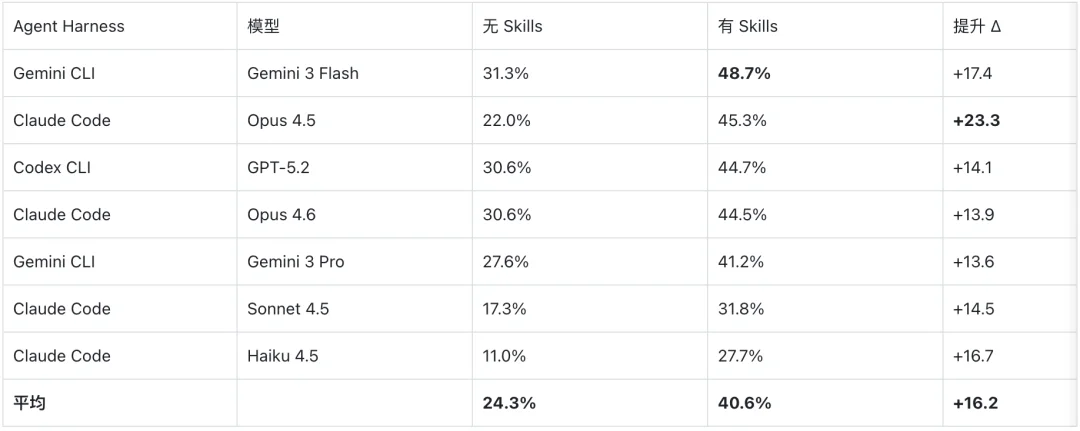
其中,Claude Code + Opus 4.5 获得了最大的性能增益(+23.3pp),反映了 Claude Code 对 Agent Skills 规范的原生优化;而 Gemini CLI + Gemini 3 Flash 达到了最高的绝对性能(48.7%)。
值得注意的是,Gemini 3 Flash 的策略是用迭代探索弥补推理深度 —— 它每任务消耗的输入 token 是 Pro 的 2.3 倍(1.08M vs 0.47M),但凭借 4 倍低的单价,每任务成本反而低 44%($0.55 vs $0.98)。
发现二:AI 自生成的 Skills 无效甚至「有毒」
这是引发这一发现构成了《The Register》报道的核心论点,直接挑战了当前流行的「Agent 自我进化」叙事。
测试表明,依赖 AI 自生成的 Skills 不仅毫无益处,反而导致平均成功率下降 1.3 个百分点。其中 GPT-5.2 下滑最为严重(-5.6pp),仅有 Opus 4.6 展现出极其微弱的正向收益(+1.4pp)。
机器学习视角的轨迹分析揭示了两种主要失败模式:
发现三:领域差异呈现两极分化
大模型预训练数据覆盖越薄弱的垂直领域,Skills 带来的杠杆效应越大。
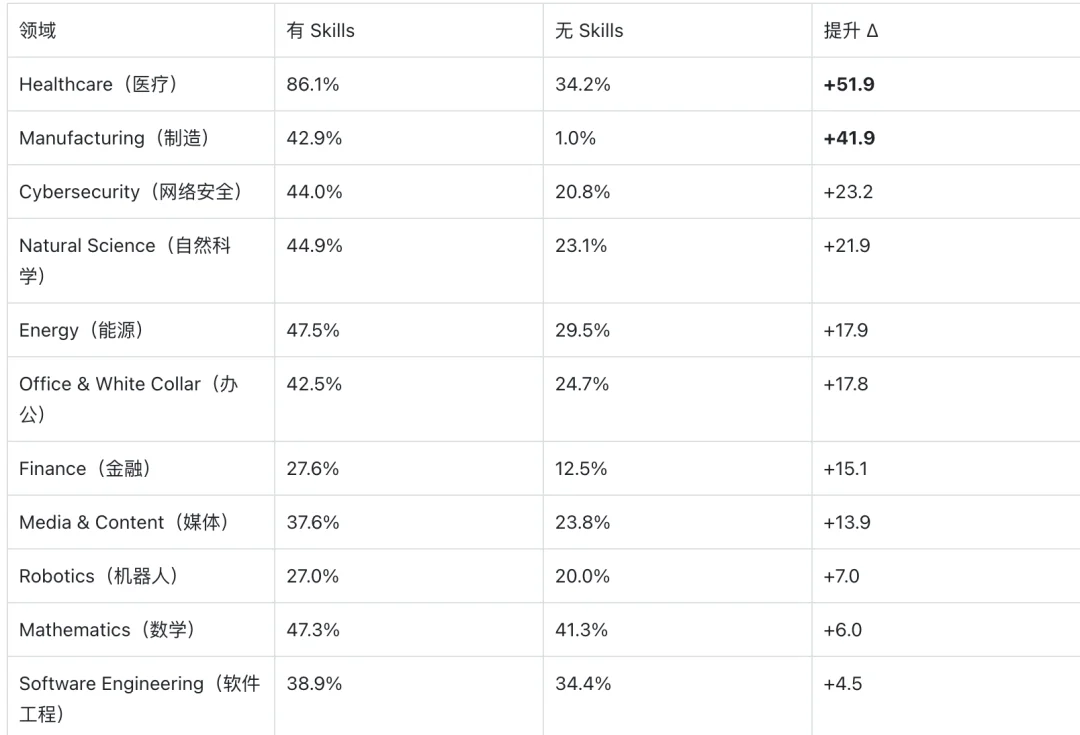
规律非常清晰:预训练数据覆盖越薄弱的垂直领域,Skills 的杠杆效应越大。

医疗和制造领域因蕴含大量非公开的业务流规范,收益极为惊人;而软件工程(+4.5pp)和数学(+6.0pp)领域的收益则微乎其微 —— 因为顶级 LLM 已在海量的代码和数学公式上得到了充分的训练。在任务级别,最大的赢家包括(+85.7pp)和(+77.1pp)。
发现四:小模型 + Skills > 大模型裸奔
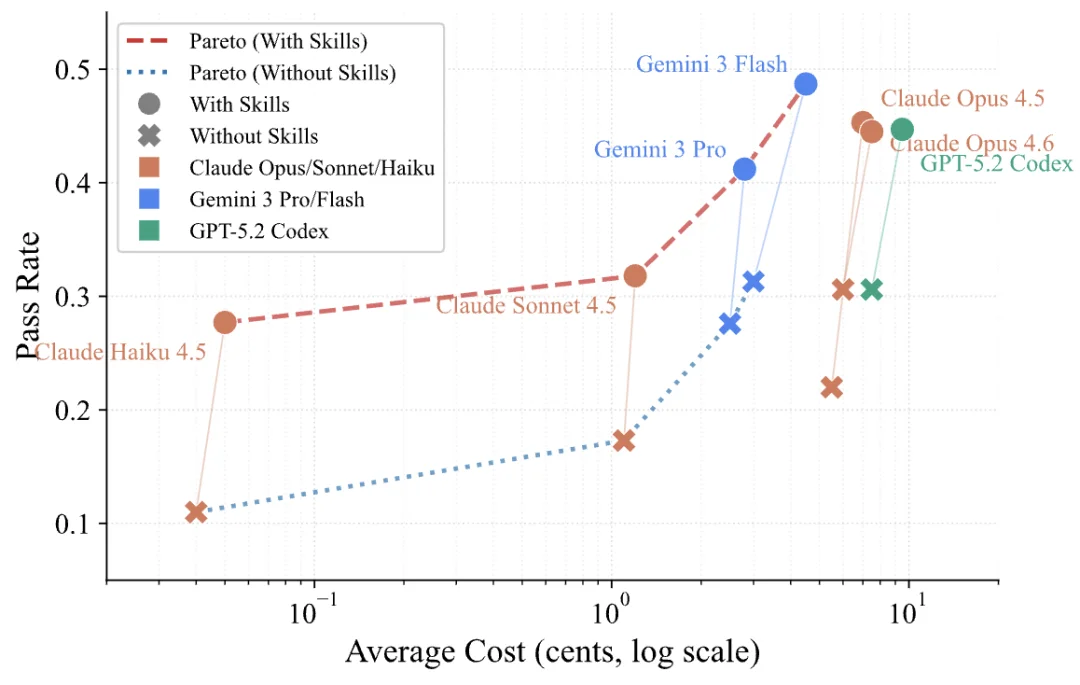
图 5:性能 - 成本 帕累托(Pareto)前沿曲线。Skills 将整条前沿上移。Haiku 4.5+Skills(27.7%)超越 Opus 4.5 无 Skills(22.0%);Gemini 3 Flash+Skills 以低 44% 成本达全场最高(48.7%)。
在性能 - 成本的帕累托(Pareto)前沿上,Skills 的加持将整条曲线显著上移。Claude Haiku 4.5 搭配 Skills 的通过率达到 27.7%,直接反超了处于无 Skills「裸奔」状态的旗舰模型 Claude Opus 4.5(22.0%)—— 而两者之间的 API 推理成本相差数十倍。
工程启示与行业影响
SkillsBench 的实证数据为 AI 研发工程师指明了清晰的最佳实践路径:
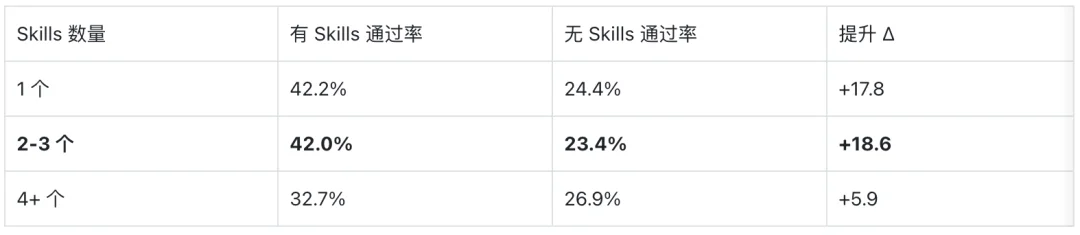
1.2-3 个 Skills 是性能甜点区: 提供 2-3 个 Skills 时性能提升达到峰值(+18.6pp);当强行塞入 4 个以上时,由于上下文干扰与认知过载,收益骤降至 +5.9pp。
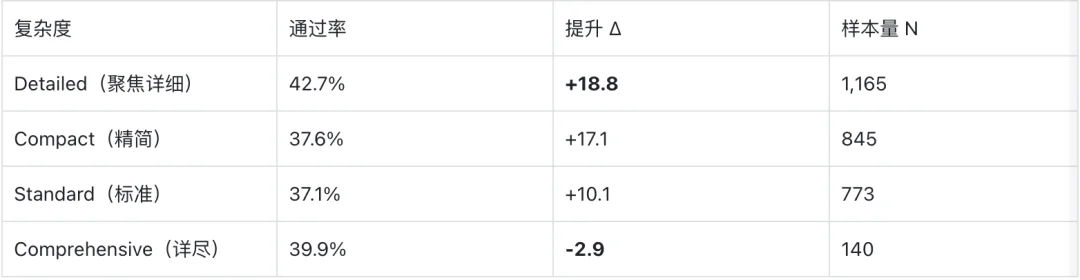
2.聚焦胜过详尽: 采用 Detailed(步骤详尽且聚焦)格式能带来 +18.8pp 的提升,而丢给模型一份 Comprehensive(详尽无遗)的长文档,反而会导致性能退化(-2.9pp)。冗长文档会白白消耗上下文预算,却无法提供精确的 API 路由指导。
这些结论与 OpenClaw 平台的底层工程设计形成了完美的互证。
OpenClaw 的 Load-time Filtering 机制以及极致精简的元数据设计(~24 tokens/Skill),正是对「精准加载、拒绝冗长」的最优工程化落地。Claude Code 率先定义了 Agent Skills 规范,OpenClaw 等开源项目的跟进,标志着 Skills 已不再是某一家的「围墙花园」—— 它正成为 Agent 基础设施层面的通用标准。
正如 SkillsBench 同时评估了 Claude Code、Gemini CLI 和 Codex CLI 三大商用平台所展示的,最优策略已从「选最强的模型」转变为「选最适配的 Skills + Harness 组合」。
对于当前 AI 生态及 B 端落地而言,这项研究具有强烈的战略意义:在算力受限的背景下,盲目追求大模型参数规模的 Scaling Law 并非唯一出路。
「小模型 + 高质量垂直 Skills」(正如 Haiku 击败 Opus 所展示的),为工业制造(+41.9pp)和医疗(+51.9pp)等场景提供了极具性价比的解决方案。随着 Claude Code 率先定义规范,以及 OpenClaw 等开源社区的全面跟进,标志着 Skills 已彻底打破单一巨头的专属封闭生态,正加速成为 Agent 基础设施层面的通用标准。
未来 AI 应用的护城河不在于参数量,而在于谁能将行业的「暗知识」与复杂的业务 SOP,精准转化为标准化的 Agent Skills。
结语
SkillsBench 不仅仅是一个基准测试,它是对当前大模型在复杂任务中「能力边界」的一次精准测绘。感谢来自 Stanford、CMU、UC Berkeley、Oxford、Amazon、ByteDance、Foxconn 等机构的 105 位领域专家和 36 位作者为开源社区带来的卓越贡献。
在这个连 AI 都无法轻易「自学成才」的阶段,人类高质量的知识沉淀依然是点亮通用人工智能之路不可或缺的火种。
相关新闻报道与社区讨论:
The Register:「AI Agents can't teach themselves new skills」
Hacker News:#1 热帖・363 points・163 comments
YC 总裁 Garry Tan 转发:x.com/garrytan
HuggingFace Daily Papers:x.com/HuggingPapers
DAIR.AI 周刊收录:x.com/dair_ai
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
