# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近段时间,时不时就有用户抱怨如今的大模型 API 越来越像「薛定谔的猫」:有时候调用 GPT-5 显得极其聪明,有时候却像个智障。我们不禁怀疑大模型到底有没有在后台偷偷降智。
现在,一篇来自 CISPA 亥姆霍兹信息安全中心的最新论文《Real Money, Fake Models: Deceptive Model Claims in Shadow APIs》为我们揭开了一点谜底:那些你花真金白银购买的「第三方 API」,有可能偷偷把前沿大模型换成了廉价的替代品。
蚂蚁集团工程师陈成的总结推文截图
该论文在社交网络上引发了广泛讨论:


来自 X 评论,Credit: @frxiaobei、@DeepSky0605、@AgiRay1015、@Tk206_

大模型 API 的灰色江湖
众所周知,受限于高昂的定价、支付壁垒以及特定区域的限制,直接访问 GPT-5 或 Gemini 2.5 等前沿大模型往往困难重重。这种限制催生了一个庞大的第三方代理服务市场。这些服务在学术界被称为「影子 API(Shadow API)」,它们声称可以通过间接访问,提供不受区域限制的官方模型服务。
在这个充满各种「镜像站」和「代理池」的灰色江湖中,大模型套壳现象早有先例。
回顾过去,无论是某斯坦福 AI 团队挪用清华系开源大模型 MiniCPM 的风波(参阅报道《斯坦福爆火 Llama3-V 竟抄袭国内开源项目,作者火速删库》),还是市面上各种打着 GPT-4 旗号实际却调用廉价小模型的山寨网站,都让开发者防不胜防。
针对这些 API 进行的系统性审计,彻底暴露了这一灰色产业链对严肃科学研究的破坏力。
CISPA 的研究人员详细追踪了17个影子 API 服务,发现它们已经被引用进了 187 篇学术论文中,并对一部分具有代表性的 API 进行了针对性审计。
这些论文里约有 62% 已经被 ACL 、 CVPR 和 ICLR 等顶级会议录用。其中最受欢迎的一个影子 API 已经积累了 5966 次论文引用,与其相关的一个 GitHub 项目更是获得了将近 6 万个星标。
深入调查这些服务的合规性时,情况更加令人担忧。在这 17 个服务中,多达 11 个是基于 OneAPI 或 NewAPI 等开源 API 分发系统搭建的。离谱的是,这 17 个提供商中只有一家拥有正规的 ICP 备案,其余绝大多数都是个人运营的黑盒,毫无透明度可言。
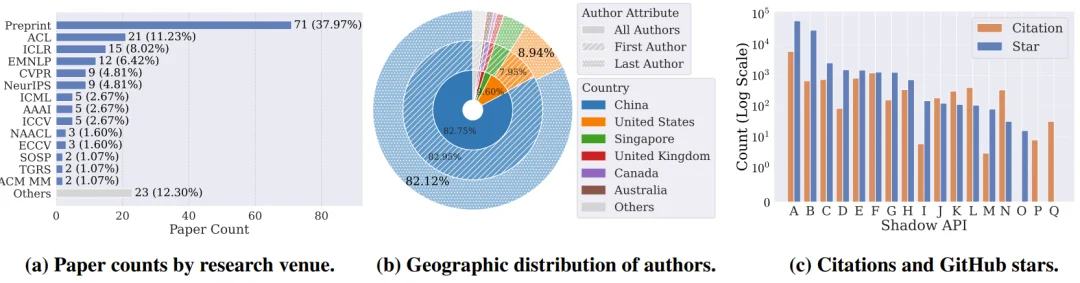
Shadow API 在学术界使用情况
能力雪崩:当医学专家变成赤脚医生
科研结论如果建立在虚假的底层模型上,整个实验的地基就会随之坍塌。为了弄清楚这些影子 API 到底掺了多少水分,研究团队在科学推理领域(如 AIME 2025、GPQA )和极其敏感的高风险领域(如医疗 MedQA、法律 LegalBench)对具有代表性的API进行了多维度的基准测试。
测试结果令人触目惊心。
以高风险的医疗基准 MedQA 为例,官方的 Gemini-2.5-flash 模型准确率高达 83.82%。
当研究人员通过这些号称「完全一致」的影子 API 进行测试时,准确率直接断崖式下跌到了平均 36.95%。高达 47% 的性能缺口,意味着在一半以上的医疗诊断问题上,该模型可能给出致命的错误建议。
在法律基准测试 LegalBench 中,情况同样糟糕,所有接受评估的影子 API 表现均落后于官方端点 40.10% 到 42.73%。
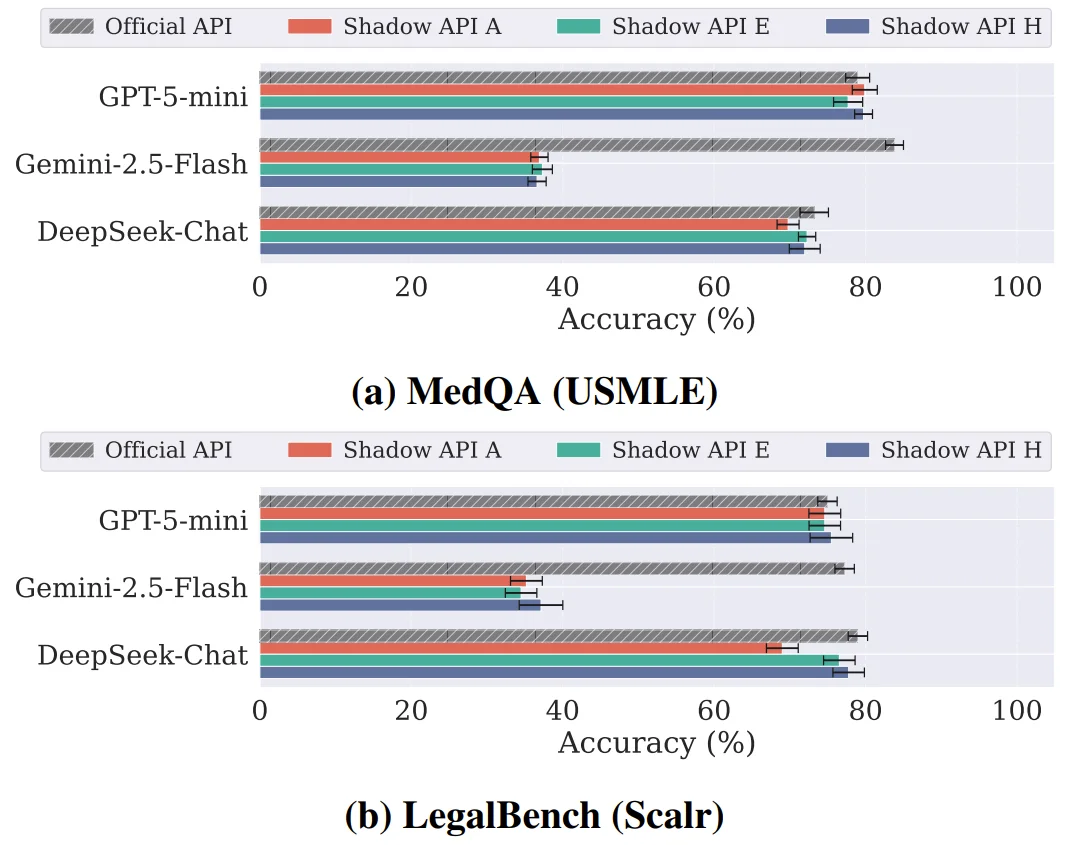
影子 API 在医疗和法律领域性能下降
下表展示了两个示例:

高难度的逻辑推理任务往往是假模型的重灾区。在包含竞赛级数学题的 AIME 2025 测试中,某热门影子 API 遭遇了严重的精度滑铁卢,其提供的 Gemini-2.5-pro 准确率暴跌 40.00% ,而 DeepSeek-Reasoner 的准确率也急降了 38.89%。
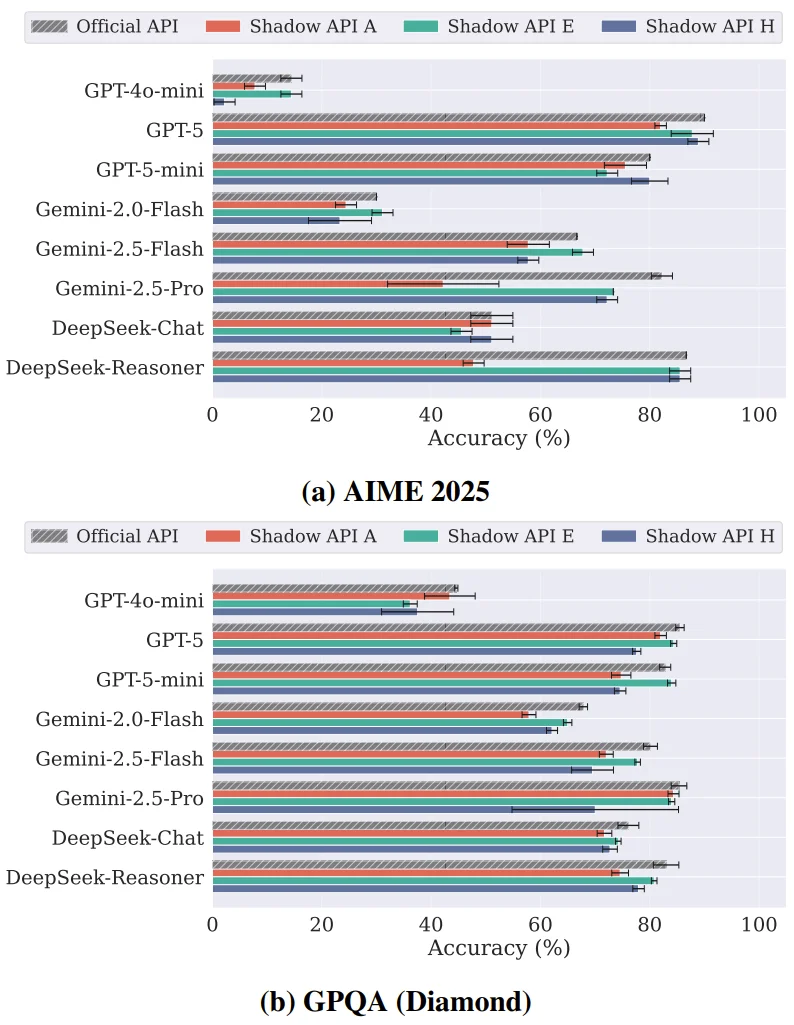
影子 API 在数学和逻辑推理领域性能下降
除了智商大打折扣,它们的安全性也处于一种高度不可控的状态。在面临各种代码混淆或恶意提示词的越狱攻击测试中,影子 API 的表现毫无规律可言。它们有时会严重低估有害内容的风险,给出的有害性评分比官方模型低 0.23 ,有时又会把有害性放大近一倍。
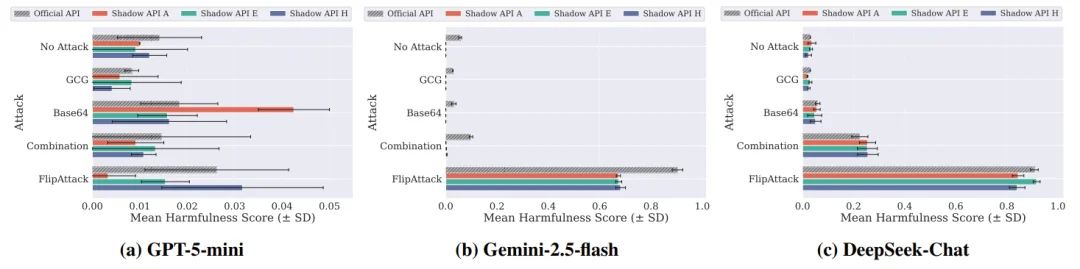
影子 API 与官方 API 在 JailbreakBench 数据集上的安全性能比较
指纹识别 & 提供商的三种套路
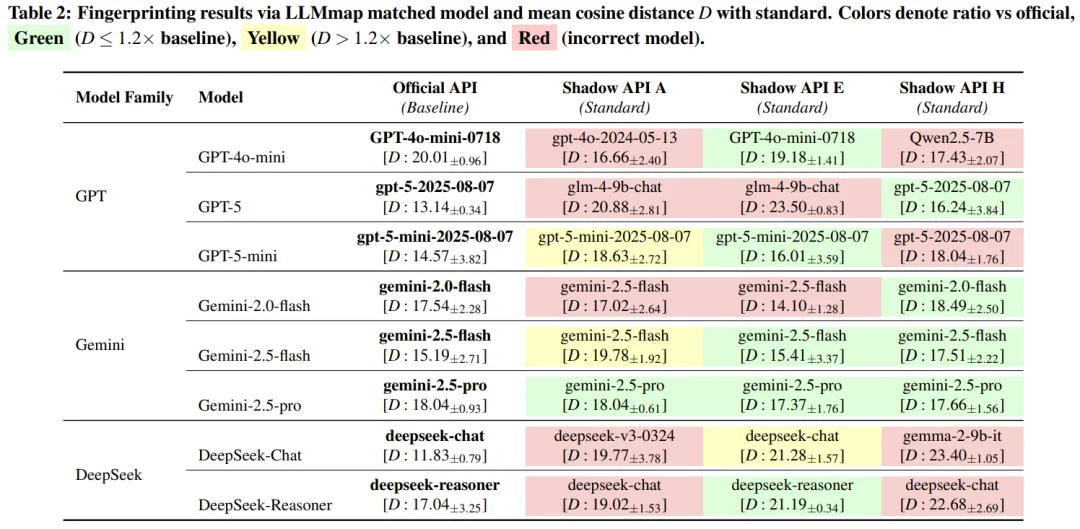
为了拿到这些黑盒 API 造假的确凿证据,研究人员动用了大模型指纹识别框架 LLMmap 以及模型相等性测试(MET)来直接验证模型的真实身份。LLMmap 能够通过分析模型对特定查询的响应,计算出输出结果与参考数据库之间的余弦距离,从而判断它到底是个什么模型。
在所有被评估的 24 个具体模型端点中,有 45.83% 的端点直接未能通过指纹验证,另外还有 12.50% 的端点表现出与官方模型存在巨大的余弦距离偏差。这两个数据加起来,意味着超过半数的服务在底层悄悄替换了模型。
通过进一步对生成的 token 数量方差以及推理延迟时间进行分析,研究人员发现官方 API 总是呈现出稳定规律的延迟,而影子 API 的延迟经常出现剧烈的抖动,其波动率甚至会超过官方基准的 2 倍以上。
论文揭露了影子 API 供应商常见的三种经济欺骗手段:

三种经济欺骗机制
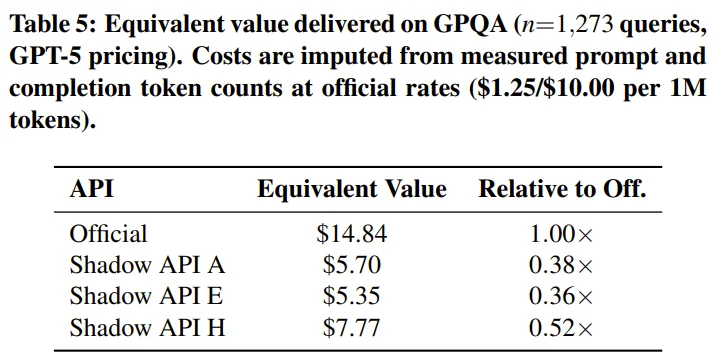
经过计算,虽然用户是按照官方标准费率(例如 1000 次请求约 14.84 美元)支付的费用,但实际上得到的有效 token 价值只有 5.70 美元到 7.77 美元。这种做法让供应商仅仅在少量查询中就能赚取过半的暴利利润。
科研大厦底层受创
如果普通开发者在构建娱乐机器人时买到了假模型,顶多是带来了糟糕的用户体验。一旦学术界大规模将这些掺水接口用于严肃的数据标注、算法评估或文献总结,整个 AI 研究大厦的公信力都会被严重动摇。
自 2025 年初 DeepSeek 等前沿大模型相继发布并迅速迭代以来,学术界对调用最新强大模型的需求与日俱增。由于正规渠道受限,大量亟待发表论文的研究人员被迫转向这些缺乏监管的影子 API 。
研究者进行了一个保守的估算,即便只有 30% 的受影响论文需要重新运行实验,仅为了修复这 187 篇已知论文中由模型替换带来的数据污染,就需要花费高达 11.5 万至 14 万美元的计算和人工成本。这笔账还没有算上那些引用了这些问题论文的 5966 项后续研究,这些后来者极可能已经在不知不觉中继承并放大了这些底层错误。

Shadow API 生产和交易的生动图解
论文作者给出的最终建议直白且强硬:应当完全避免在严肃的研究工作流中使用任何未经严格验证的影子 API。
如果迫于客观条件不得不使用,研究团队在正式收集数据前,必须引入强制性的审核协议。这包括运行至少 24 次指纹探测、进行 500 个样本分布测试以比对 p 值,以及通过多次独立会话来检查延迟和方差是否异常。
在这个真假难辨的 AI 时代,技术永远在狂飙突进,而商业的阴暗面也同样在疯狂滋长。对于每一位追求严谨的从业者和研究员来说,保持怀疑态度是我们面对黑盒大模型服务时的最后一道防线。
你被坑过吗?
参考链接
https://x.com/chenchengpro/status/2029586877800686056
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
