# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
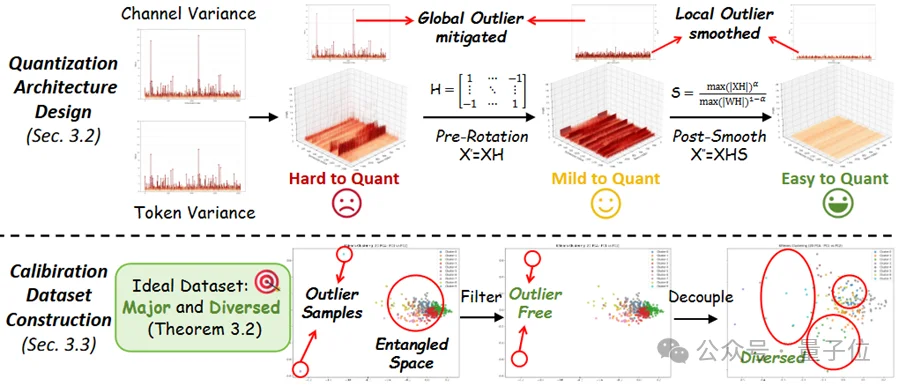
十亿参数的三维重建模型,能塞进手机吗?
以前想都不敢想——VGGT这样的庞然大物,单次前向传播就能完成深度估计、点云回归、相机预测多个任务,但部署成本高得吓人。
现在,一个名为QuantVGGT的量化框架给出了答案:4比特量化,速度提升2.5倍,内存减少3.7倍,精度保住98%。

近年来,以视觉几何基础Transformer(Visual Geometry Grounded Transformers, VGGT)为代表的基于学习的三维重建模型,借助大规模Transformer取得了显著进展。
然而,其极高的计算和内存成本严重阻碍了在实际场景中的部署。训练后量化(Post-Training Quantization, PTQ)已成为模型压缩与加速的常用技术,但通过实验发现,在对十亿参数规模的VGGT进行压缩时,PTQ面临独特挑战:数据无关的特殊令牌会导致重尾激活分布,而三维数据的多视图特性则使校准样本选择极具不稳定性。
本研究提出首个针对VGGT的量化框架QuantVGGT,主要包含两项技术贡献:其一,引入双平滑细粒度量化(Dual-Smoothed Fine-Grained Quantization),通过融合预全局哈达玛旋转(pre-global Hadamard rotation)与后局部通道平滑(post-local channel smoothing),稳健地缓解重尾分布与通道间方差问题;其二,设计噪声过滤多样采样(Noise-Filtered Diverse Sampling),利用深层统计信息过滤异常值,并构建帧感知的多样校准聚类,确保量化范围的稳定性。
大量实验表明,QuantVGGT在不同基准数据集和比特宽度下均实现了当前最优性能,大幅超越此前的通用量化方法。值得关注的是,4比特量化的QuantVGGT在真实硬件推理中可实现3.7倍内存减少和2.5倍加速,同时保持重建精度不低于全精度模型的98%。这充分证明了QuantVGGT在资源受限场景中的显著优势与实用性。相关代码已开源。

△ QuantVGGT能在不损失视觉质量的前提下,将VGGT有效量化至W4A4(4比特权重、4比特激活),同时实现2.5倍加速与3.7倍压缩。
近年来,基于学习的三维重建技术在直接从图像序列中恢复密集几何结构与相机轨迹方面展现出前所未有的能力。传统方法以几何先验知识和优化算法为基础,但对人工设计选择和迭代求解器的依赖,使其在复杂场景中往往存在扩展性有限、鲁棒性不足的问题。
与之相反,大规模深度模型将研究范式转向数据驱动框架,在不同环境中展现出优异的泛化能力。这一演进过程中的里程碑成果是视觉几何基础Transformer(VGGT)——该模型拥有12亿参数,可在单次前向传播中统一完成多个三维任务,包括密集深度估计、点云图回归、相机姿态预测与点跟踪,且性能持续超越任务专用模型。
尽管VGGT成效显著,但十亿级别的参数规模使其产生极高的计算与内存成本,严重限制了其在实际场景中的部署。模型量化技术通过将模型的权重和激活值从高精度浮点数转换为低精度整数,成为一种有效的压缩手段。虽然该技术已在大型语言模型和二维视觉模型中得到广泛验证,但针对VGGT这类十亿参数级三维重建Transformer的量化研究仍处于空白状态。本研究发现,VGGT存在两项模型特有属性,使其量化极具挑战性:
为应对上述挑战,本文首次对VGGT的训练后量化(PTQ)展开系统性研究,并提出定制化框架QuantVGGT。该方法引入双平滑细粒度量化(Dual-Smoothed Fine-Grained Quantization, DSFQ),通过以下两点缓解分布扭曲问题:
(1)基于哈达玛变换的预全局旋转,分散异常值并平滑重尾分布;
(2)后局部平滑步骤,在旋转空间中归一化通道级方差。此外,为解决校准不稳定性问题,本文设计噪声过滤多样采样(Noise-Filtered Diverse Sampling, NFDS),利用深层激活统计信息过滤噪声极值,并结合与VGGT归纳偏置对齐的帧感知聚类。这些组件共同作用,实现了对十亿参数级三维重建Transformer稳健、高效且高精度的量化。
本文的贡献总结如下:
△ “QuantVGGT整体框架图”,图上半部分为双平滑细粒度量化架构,下半部分为噪声过滤多样采样策略。
近年来,随着深度学习技术的发展,三维重建任务逐渐从严重依赖先验知识的传统方法转向数据驱动的基于学习的方法。得益于大规模训练过程,基于学习的方法通常具有更优的重建性能与泛化能力。DUSt3R通过对两张RGB图像进行回归,预测场景的三维点云图,为基于学习的三维重建方法奠定了基础;MASt3R进一步优化该框架,引入置信加权损失实现度量尺度逼近。
当前的VGGT模型可在单次前向传播中预测相机位置、密集深度、点云图与点跟踪;将参数规模扩展至12亿后,VGGT在各类三维任务中均实现当前最优性能,甚至超越部分任务专用模型。然而,VGGT数十亿的参数规模与巨大的计算复杂度,严重限制了其广泛部署与应用,而针对VGGT的量化等压缩方法研究仍极为有限。
模型量化通过降低数据比特宽度,显著减少内存占用并加速推理过程。模型量化主要分为量化感知训练(Quantization-Aware Training, QAT)与训练后量化(Post-Training Quantization, PTQ)两类:QAT需利用大量数据同时训练量化参数与模型权重,因此在极低比特量化下通常能保持较好性能,但往往需要庞大的训练资源;与之相反,PTQ仅需少量校准数据微调量化参数,无需调整原始全精度权重,更适用于大型模型。
在PTQ领域,BRECQ构建了块级重建框架;QDrop通过随机丢弃量化激活值进一步提升性能;为确保PTQ在大型模型中的有效性,GPTQ利用近似二阶梯度优化大型语言模型;针对分布不平衡对量化的影响,SmoothQuant引入平滑参数,将激活量化的难度转移至权重端;QuaRot则采用类似旋转的方法平滑分布。尽管这些方法在现有二维视觉模型与语言模型中表现优异,但它们在VGGT这类大规模三维模型上的泛化能力较差。据本文所知,QuantVGGT是首个专为VGGT设计的PTQ框架,可在低比特量化下仍保持模型性能。
VGGT是一种最新架构,可从任意长度的图像序列中预测所有关键三维属性,其核心组件为令牌化(tokenization)与令牌配准(token registration)。对于包含N张RGB图像的输入序列ℐ={Ii}Ni=1 ,VGGT首先通过预训练视觉骨干网络ℱ(·)(如DINOv2)对每张图像进行令牌化,得到:
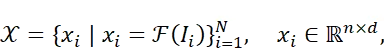
其中,n表示图像分块后的令牌长度,d为特征维度。
为实现多属性推理,VGGT为每张图像添加1个相机令牌与4个配准令牌,这些令牌负责聚合不同三维属性(如相机参数、场景几何结构)。值得注意的是,VGGT包含两组不同的特殊令牌:一组为tf∈R5×d,专为第一帧图像保留;另一组为to∈R5×d,供后续所有帧共享。形式上,令牌配准过程定义为:
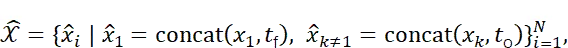
最终得到的X̂将输入至VGGT骨干网络进行后续处理。
量化的目标是将模型权重与激活值从浮点数表示转换为紧凑的低比特整数表示,从而降低计算成本与内存占用。对于浮点数向量x,对称量化过程可形式化为:
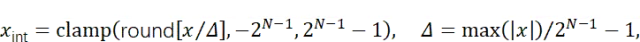
其中,N表示目标比特宽度,round为取整操作,clamp(·)确保整数值处于有效范围[-2N-1,2N-1-1]内。
在各类量化范式中,PTQ因其高效性被广泛应用。与量化感知训练(QAT)不同,PTQ无需微调模型权重,仅需通过少量校准数据集𝒟calib微调量化参数,即可保持原始全精度权重不变。这种特性使PTQ在微调资源有限的实际部署场景中极具吸引力。

其中,θf与θq分别表示全精度模型与量化模型的函数。
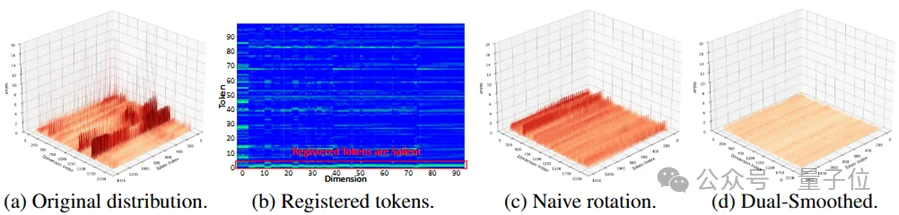
△ “双平滑细粒度量化的动机与效果”,图(a)为VGGT frame_block 9的显著分布,图(b)为配准令牌的显著性,图(c)为普通旋转后的分布,图(d)为双平滑后的分布
观察1:VGGT存在高度扭曲的数值分布,且数据无关令牌(相机令牌与配准令牌)会加剧这种扭曲,导致严重的量化误差。
如图所示,这些数据无关令牌(前5个令牌)会放大通道与令牌的数值方差:其包含大量远超常规图像块令牌的异常值,形成重尾分布。在量化过程中,少数大数值会占据大部分量化区间,导致严重的数值失真。
预全局旋转(Pre-Global-Rotation):

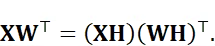
基于中心极限效应,哈达玛旋转后的数值分布更接近高斯分布,从而平滑特殊令牌引入的重尾分布。
引理表明,哈达玛旋转可将异常值分散至各通道,形成更均匀的分布,显著降低异常值影响。因此,原始分布会变得更集中、更平滑,更利于量化。如图所示,哈达玛旋转后,大量极端异常值得到缓解。
后局部平滑(Post-Local-Smooth):
尽管哈达玛旋转缓解了全局分布扭曲,但如图所示,旋转后的分布仍存在显著的局部方差。哈达玛旋转仅能将异常值分散至各通道,却无法消除单个通道内的异常值。为进一步降低量化误差,本文引入通道级缩放因子,对旋转空间中的通道分布进行归一化:
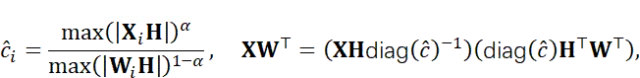
其中,α用于平衡激活值与权重的量化难度(通常设为0.5)。与传统缩放方法不同,本文方案从旋转后的分布中推导缩放因子,可有效抵御特殊令牌极端值的影响。该设计具有两项优势:
(1)缩放因子源于预旋转后的平滑分布,避免了极端值对权重量化的干扰;
(2)确保缩放后的分布更平滑——若先进行缩放再旋转,会破坏通道缩放带来的增益。此外,缩放因子可融合至相邻层中,不会增加运行时成本。
细粒度量化粒度(Fine-Grained Quantization Granularity):
上述“旋转-缩放”量化策略通过解决维度din的问题降低量化误差,但量化粒度的选择对整体误差同样至关重要。近期研究通过‘μ-coherent’定义量化难度:对于任意x,若max(x)≤μ||x||F/√g(其中g为元素数量,μ为量化难度系数),则降低量化粒度(在可行前提下)可显著降低量化误差。
从硬件角度看,只要量化矩阵乘法在求和操作中共享相同的量化参数,就无需将整数转换回浮点数,可确保效率。在矩阵乘法中,仅内通道din的数值参与求和,因此可利用外通道dout对权重进行量化,利用令牌维度n对激活值进行量化。
在实际操作中,本文对权重采用外通道级量化,对激活值采用令牌级量化。如图所示,所提双平滑细粒度量化进一步降低了数据分布的外通道方差,显著减少量化误差,且几乎不增加额外计算负担。
校准过程的目标是利用小规模校准集𝒟calib近似模型在真实数据分布X上的行为。形式上,需求解:
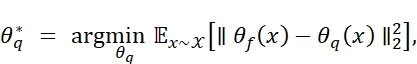
在实际操作中,通常利用𝒟calib中的样本近似上述期望。因此,校准集需在统计上能代表真实数据分布𝒳。
定理:假设𝒳可划分为多个子域𝒳={X0,X1,⋯},每个子域Xi的规模为Vi,且可进一步划分为Ni(≥2且有限)个不相交子区域{R1i,⋯,RNii},对应规模为{V1i,⋯,VNii}。考虑构造样本集𝒟={x0s,⋯,xKs}⊂X∗(其中X∗=𝔼(𝒳)表示期望输入),若对∀xis∈𝒟,均满足p(xis∈Rj∗)=Vj∗/V∗,则D在期望上能最大程度反映𝒳的信息。
定理表明,构建有效校准集需满足两点:(1)将数据空间划分为有意义的子区域(子域);(2)按各子区域的占比从其中采样。在Vk(子区域规模)未知的实际场景中,稳健策略是先将数据集聚类为K个区域,再在每个聚类内均匀采样(该方法在温和假设下可近似按比例采样)。

△ “噪声过滤多样采样的动机与效果”,图(a)为VGGT的层分布,图(b)为标签聚类可视化,图(c)为特征聚类可视化,图(d)为本文方法聚类可视化。
观察2:VGGT深层激活值具有显著的区分性,大多数样本高度集中,少数样本为异常值。
对于期望分布,应更关注具有代表性的分布,而异常值是密度极低的尖峰样本。若在划分子域与采样时,异常值被选中的概率增加,会破坏期望分布。因此,本文首先利用深层统计信息对每个候选样本xi∈𝒟过滤噪声异常值:
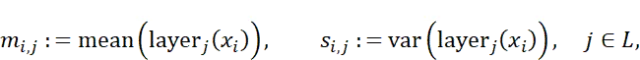
其中,L为所有使用层的集合,D为候选样本集合,layerj(·)表示第j层的激活值。随后,利用全局稳健矩计算噪声得分:
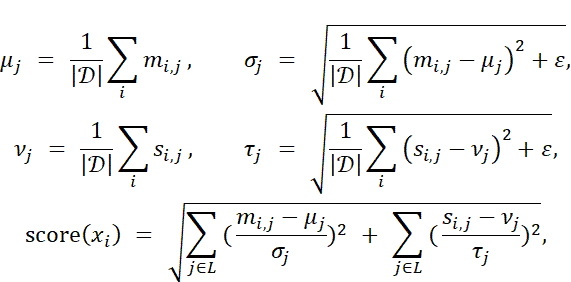
其中,ε为小常数,用于保证数值稳定性。通过设定阈值过滤高噪声样本:
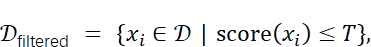
其中,T通过分位数设定(例如,保留得分最低的p%样本)。该过滤步骤可保留接近“典型”分布的样本,移除可能导致量化校准偏差的异常值。
观察3:基于原始标签的特征聚类在视觉几何任务中效果欠佳。
如图所示,样本特征高度集中,难以有效划分,直接将标签作为分类依据会导致次优结果。几何样本通常是包含多个物体的复杂场景,标签往往无法直接反映其语义信息。但本文发现,VGGT存在强烈的归纳偏置:其建模了第一帧与后续帧之间的相对关系。这一发现启发研究团队基于帧级特征设计结构度量指标。
给定样本xi的输出特征Ai∈Rn×d(其中n=s×f,s为单帧空间令牌数,f为帧数),首先将Ai重塑为帧级向量,通过计算第一帧与后续各帧的归一化相似度,构建紧凑的帧感知相关向量ci∈Rf-1:
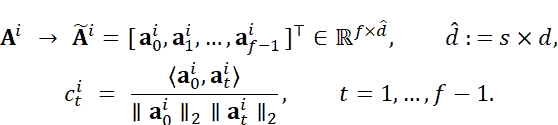
随后,采用K-Means算法对集合{ci}xi∈𝒟filtered进行聚类,得到K个区域={R1,…,RK}。根据定理,在每个区域内均匀采样可得到更能反映真实分布𝒳的校准集。具体而言:
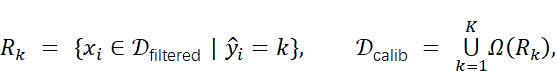
其中,ŷi为聚类分配结果,Ω(·)表示均匀采样器。该噪声过滤多样采样流程可降低噪声异常值的影响,利用VGGT的帧相对归纳偏置形成语义上有意义的聚类,最终得到更能近似真实数据分布的PTQ校准集。
本文以VGGT-1B(10亿参数版本)为基准模型,所有量化实验均基于该模型开展。为验证所提方法的有效性,在Co3Dv2数据集上进行相机姿态估计实验,在DTU数据集上进行点云图估计实验。
量化设置方面,选择目前研究最广泛的两种比特配置:W8A8(8比特权重、8比特激活)与W4A4(4比特权重、4比特激活),这两种配置具有更好的硬件适应性,且能带来更显著的加速与压缩效果。
基线方法:
量化基线方法包括常用的训练后量化基线——最近邻舍入(Round-To-Nearest, RTN)、BRECQ与QDrop;二维视觉Transformer基线选择性能优异的DopQ-ViT;语言Transformer基线选择性能优异的GPTQ、SmoothQuant与QuaRot。
相机姿态估计:
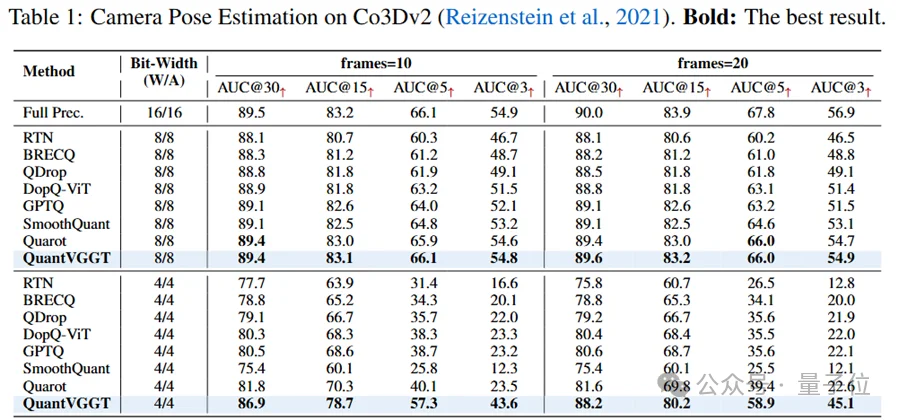
在Co3Dv2数据集上基于VGGT-1B开展相机姿态估计实验。遵循现有研究,随机采样10帧图像进行评估,并进一步扩展至20帧以验证更泛化的性能,结果如表(原文表tab:co3d)所示。
在相对简单的W8A8设置下,多数量化方法能保持较好性能,但仍不可避免地出现性能下降;而QuantVGGT在W8A8下保持了99.9%的性能,AUC@30(30像素误差下的曲线下面积)为89.4,与全精度(Full Precision, FP)模型的89.5基本持平。
在更具挑战性的W4A4设置下,所有量化方法均出现显著性能下降,例如当前最优方法QuaRot在20帧设置下的AUC@30仅为81.6;而QuantVGGT仍实现了88.2的AUC@30,保持了全精度模型98%的性能。即使在极端量化设置下,QuantVGGT相比现有方法仍能实现显著性能提升,充分证明其对三维重建模型的量化适配性。
点云图估计:
为全面评估VGGT量化的泛化性能,进一步在DTU数据集上开展点云图估计实验。评估时每5张图像采样一帧关键帧,结果如表(原文表tab:dtu)所示。值得注意的是,校准数据集全部来自Co3Dv2训练集,即DTU数据对校准过程而言是“未见”数据。
实验发现,即使在W8A8设置下,所有现有量化方法仍出现一定程度的性能下降;而QuantVGGT在点云图估计任务中泛化性能优异,在W8A8下甚至实现了比全精度模型更优的指标。
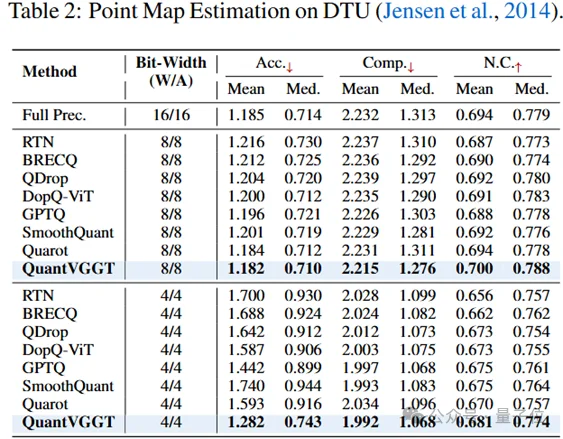
在W4A4设置下,所有现有方法性能显著下降,例如QuaRot的精度(Acc.)仅为1.593;而QuantVGGT的精度达到1.282,更接近全精度模型的1.185。这一结果证明QuantVGGT可适配VGGT这类大型三维模型的量化需求,并能通过高效的PTQ过程保持强大的泛化能力。
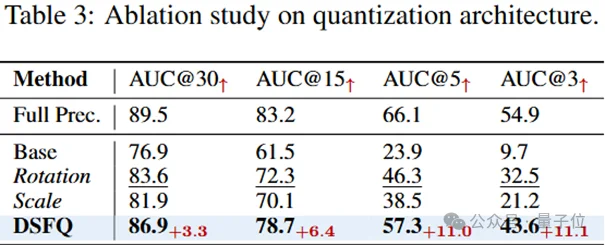
为验证各提出组件的有效性,本文开展消融实验,所有实验均在Co3Dv2数据集上基于W4A4量化设置进行。
量化架构:
首先验证所提双平滑细粒度量化(DSFQ)的有效性,结果如表(原文表tab:ablation_quant)所示。将无任何平滑操作的普通量化设为基准(Base),并与仅旋转(Rotation)、仅缩放(Scale)方法及DSFQ进行对比。
普通量化性能严重崩溃,AUC@3仅为9.7;基于缩放与旋转的方法虽能进一步平滑数据分布并带来一定性能提升,但仍不可避免地出现性能下降;而DSFQ融合了旋转与缩放的优势,并利用细粒度量化粒度,大幅保留了模型性能。
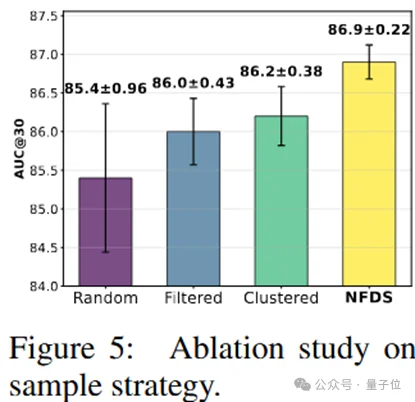
采样策略:
随后验证所提噪声过滤多样采样(NFDS)的有效性,结果如图(原文图fig:abla_sample_our)所示。将普通随机采样设为基准(Random),并与“从异常值过滤后的数据集中随机采样”(Filtered)、“从基于帧的聚类数据集中采样(无过滤)”(Clustered)进行对比。
所有实验均采用5个不同随机种子,结果以“均值±方差”形式在柱状图中呈现。随机采样不仅无法保证多样性,还因异常值影响导致方差显著;过滤后的数据质量提升,方差显著降低;本文聚类方法虽能显著提升多样性与平均性能,但因异常值存在仍有方差;而最终融合的NFDS既实现了异常值移除,又保证了良好的多样性,在确保平均性能的同时提升了稳定性。
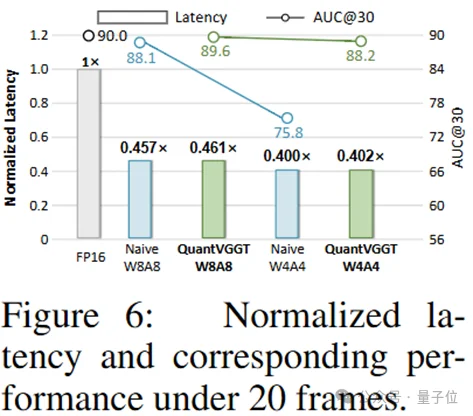
为验证量化后VGGT的部署效率,本文报告了硬件延迟(如图(原文图fig:latency)所示)。与无任何平滑技术的普通量化相比,所提双平滑细粒度量化在W4A4下仅增加0.2%的延迟,却显著保留了量化模型的性能。
此外,W4A4量化的QuantVGGT性能甚至超越普通W8A8量化模型,且与普通W4A4量化模型存在显著性能差距。这一结果表明,专为VGGT设计的量化方案相比现有普通量化,在几乎无额外负担的前提下实现了更优性能。
本文提出首个针对VGGT的训练后量化(PTQ)框架QuantVGGT。具体而言,本文明确了数据无关令牌带来的“量化不友好”分布,以及三维多视图数据固有的校准数据集不稳定性问题;随后提出双平滑细粒度量化以平滑重尾分布,设计噪声过滤多样采样构建帧感知的多样校准聚类,确保数据集稳定性。
大量实验表明,QuantVGGT在不同比特宽度下均实现当前最优性能,大幅超越现有量化方法。
论文链接:
https://arxiv.org/abs/2509.21302
代码仓库:
https://github.com/wlfeng0509/QuantVGGT
文章来自于“量子位”,作者 “QuantVGGT团队”。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
