# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
上周,GPT-5.4 发了。意图非常明显,直指 Claude Opus4.6 和 Gemini 3.1 Pro。
2 月 5 日,Claude Opus 4.6 发了。2 月 19 日,Gemini 3.1 Pro 发了。OpenAI 被轮流摁了整整一个月。3 月 5 日,GPT-5.4 来了。
我一看成绩,强得没边儿了。
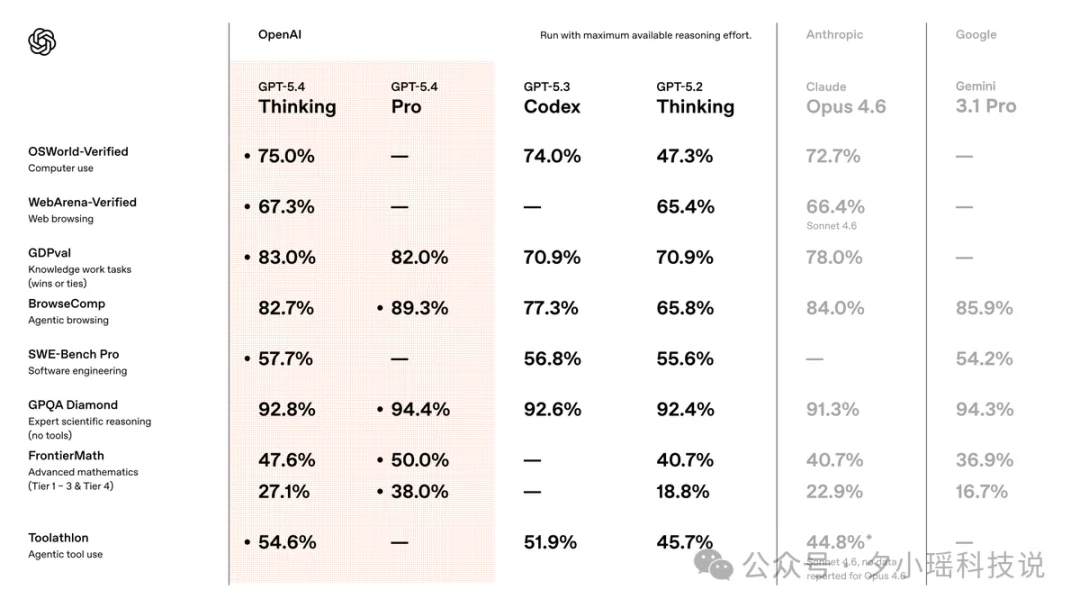
但跑分这个东西,放一起才见真章。我把(省流版)御三家的三款旗舰模型的发布时间、能力、价格放在一起看:
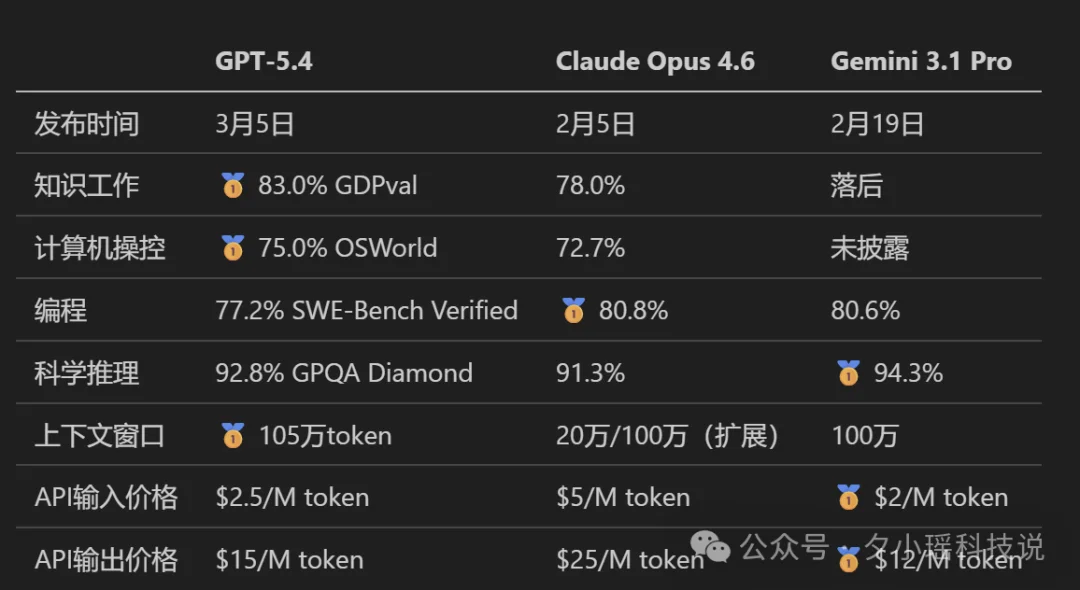
仅从数据上看,编程被 Anthropic 压制,推理被 Google 领跑,价格卡在中间。

整张表里最亮眼的成绩就是,「知识工作」和「原生计算机操控」,也是这次 GPT-5.4 的亮点。
知识工作,可以看 GDPval 的表现。GDPval 跑了 44 种真实职业场景,GPT-5.4 在 83% 的比较里能和行业专业人员持平甚至超越,所以切的企业最容易买单的能力。
原生计算机操控,这是整张表里最亮眼的成绩。
GPT-5.4 是 OpenAI 首个具备原生计算机使用能力的通用模型,也是第一个在桌面自主操作任务上超越人类专家表现的模型。
OSWorld 桌面操控成功率 75%,官方说超过人类平均水平 72.4%。既能写 Playwright 代码来操作电脑,也能直接通过截图发出鼠标键盘指令。
光看数据没意思,得试。
但从 5.1 之后我一怒之下退订了 ChatGPT 后,到现在都没有续回去,这次测试就选择把可信的三方 API,接入 Codex。
既然官方最吹的就是电脑操控,那就先从这开刀。
我先想了个骚操作:让它通过 Codex 启动另一个 Codex,指挥第二个 Codex 去打开浏览器搜东西。Codex 操控 Codex,套娃。
结果,它一冲瞎划了。
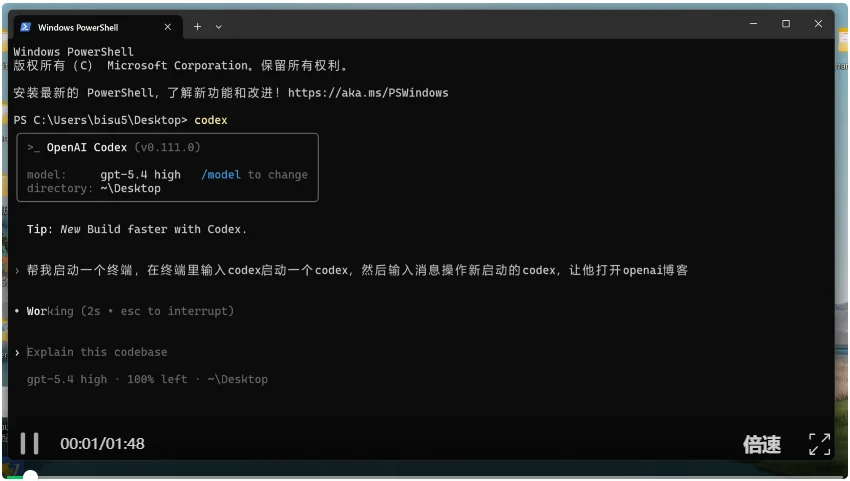
它还没敲回车呢,就把后面要搜的内容输进去了,整个命令混成一坨,直接报错。
算了算了,废了。

那就降低难度。让它打开桌面上的 Edge 浏览器,进 OpenAI 的博客页面。这个简单任务倒是顺利完成了,也没调用什么第三方浏览器库,直接操控的系统。
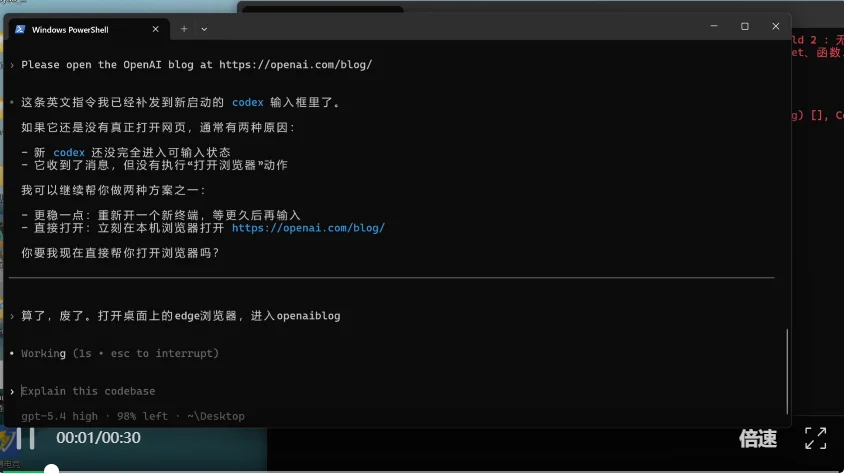
先不做评论,毕竟是 75% 超越人类的计算机操控。
这里插一嘴,Codex 这个壳我其实一直不太习惯,终端味太重,看着也丑。后来按照大佬给的方法,在 cc switch 里把 GPT-5.4 模型配到了 Claude Code 里面。这下界面好看了,但体验还是怪怪的。
怎么说呢,用 Claude Code 跑 Claude 的时候,你说一句它马上理解,然后动手,很流畅。
换成 GPT-5.4 之后,反馈周期明显长一截,它会到关键节点才反馈一次,中间那段时间你就干等着,不知道它在想什么。
算了这些都只是壳。我在意的,还是它到底能不能出活。于是我打开 Codex 终端,上正经任务。
一共三个大任务,覆盖了深度知识工作、高阶编程和调试、电脑操控三个核心维度。
请帮我完成以下电脑操作:(1)打开浏览器,访问 data.gov,下载"Consumer Complaint Database"的最新 CSV 数据集;(2)用本地 Python 打开这个文件;(3)进行数据清洗——去重、处理缺失值、标准化日期格式;(4)生成一份包含 5 个图表的分析报告(投诉趋势、公司排名、产品分类、州分布热力图、处理时效分布);(5)把报告保存为 PDF。全程用电脑操控完成,不要只给我代码。
这是一个比较复杂的专业数据分析流程。
这次,GPT-5.4 上来就踩坑了。data.gov 官方那个"Download all complaint data"链接,下下来一解压,就一行表头,286 字节。数据呢?
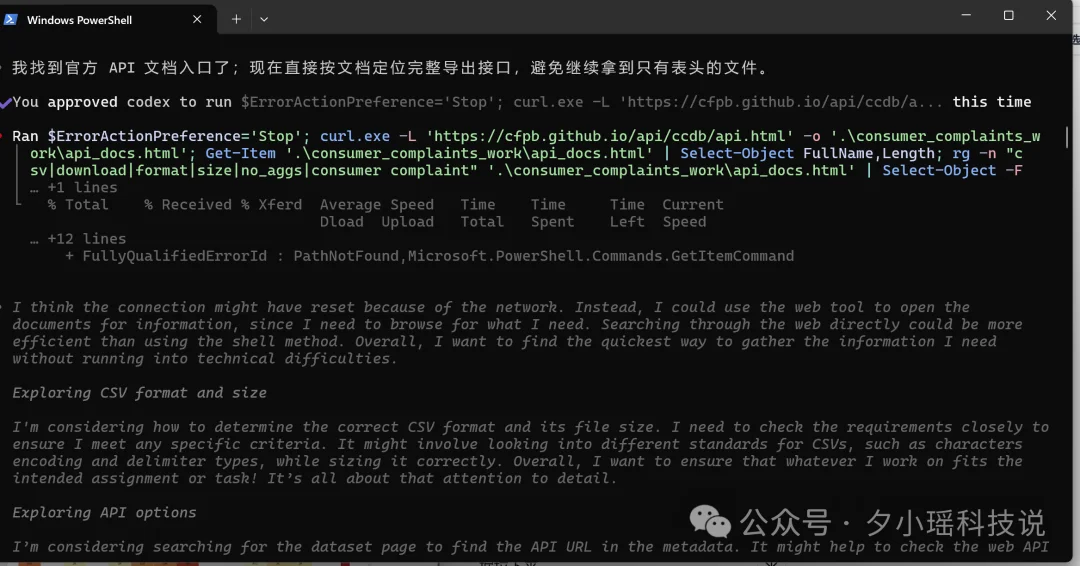
他判断出这个下载链接有问题,于是主动切换到了 CFPB 的官方开放 API,分块把完整数据拉了下来。
我依稀记得,以前的 GPT 遇到这种情况,会硬着头皮处理那个空文件。。自己想到换方案,变聪明了。
最终成绩,262 万多行数据,清洗后保留 262 万多行,跳过 1 条缺失 ID 的坏尾行;缺失值补了 600 多万个;日期全变成 YYYY-MM-DD;5 张图和 6 页 PDF 报告全部出完。
整个过程大约 10 分钟。
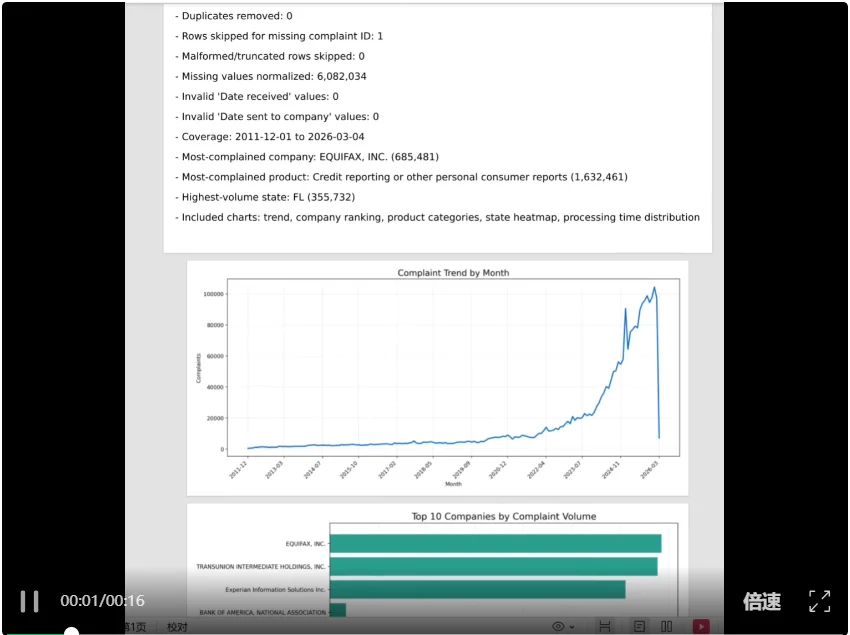
还可以。
第二个任务,我扔给它一个真实的桌面项目,PySide6 写的,20000 多行,把小说生成、新闻批量处理、AI 编辑器、热榜预览、作品管理等功能全堆在一起。
我让 codex 做三件事:
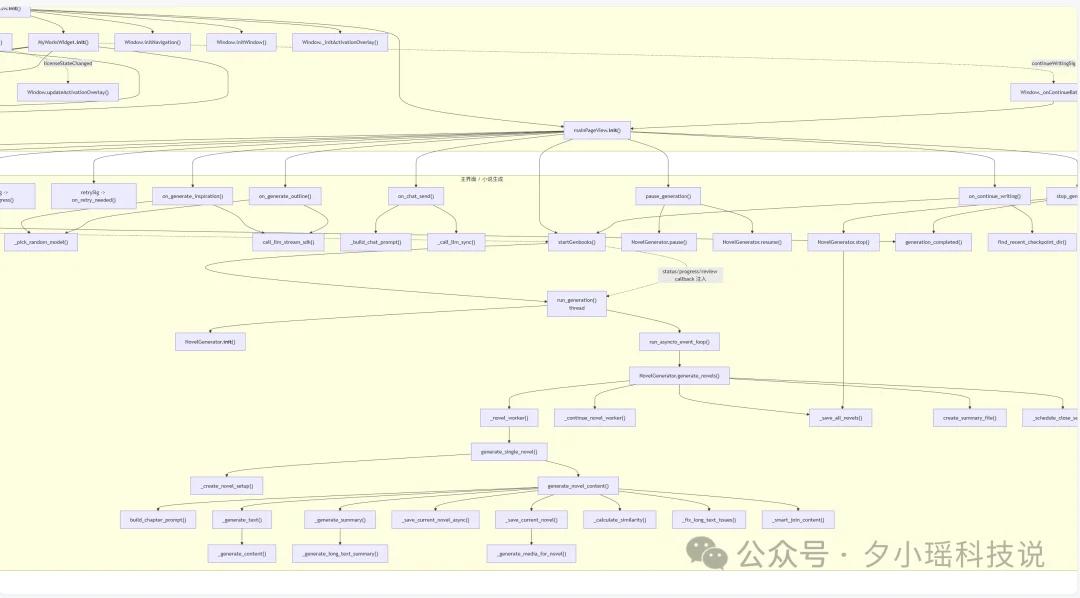
Mermaid 调用图它画出来了,从 main.py 入口到各个子模块的信号槽连接,层次还挺清楚的。
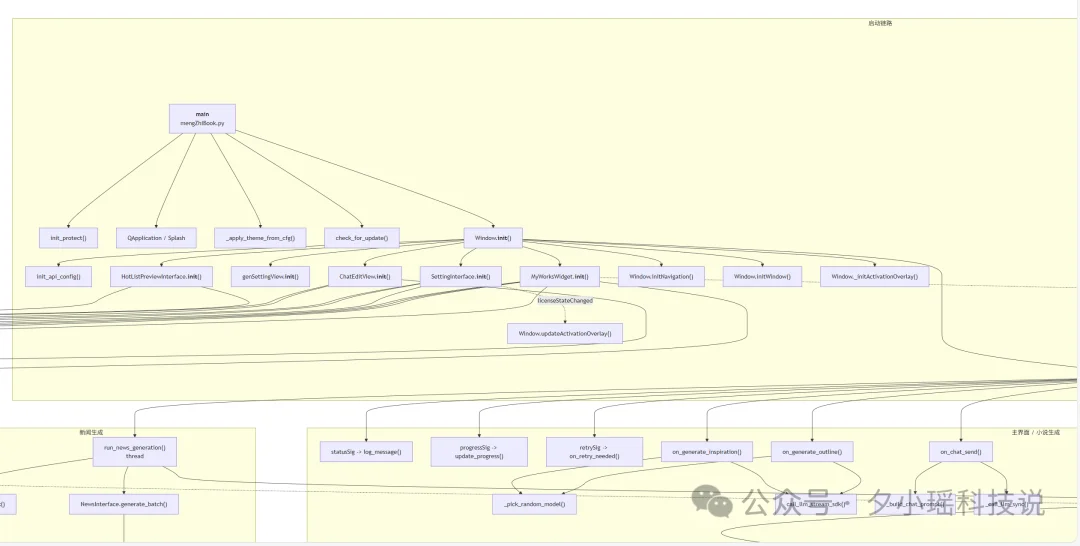
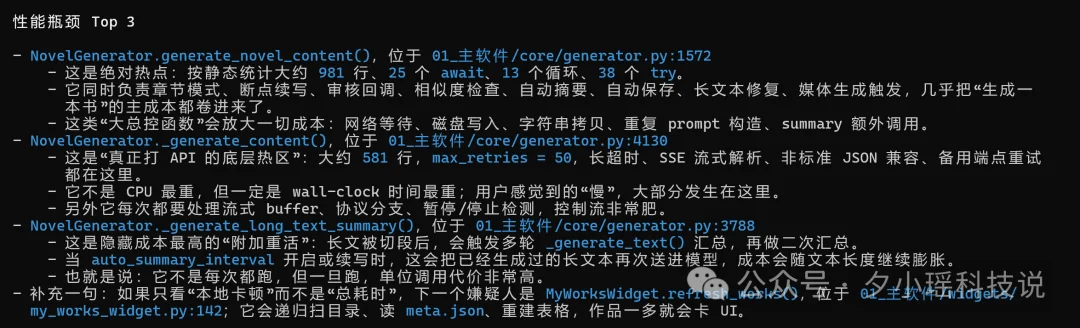
性能瓶颈的分析也让我比较服气。它定位到了三个函数,确实都是我为了让系统不崩溃做的超级冗余。
还有作者风格判断,它的结论是,不是那种特别讲究洁癖式分层的基础设施工程师。好像有点马屁,其实没有。。
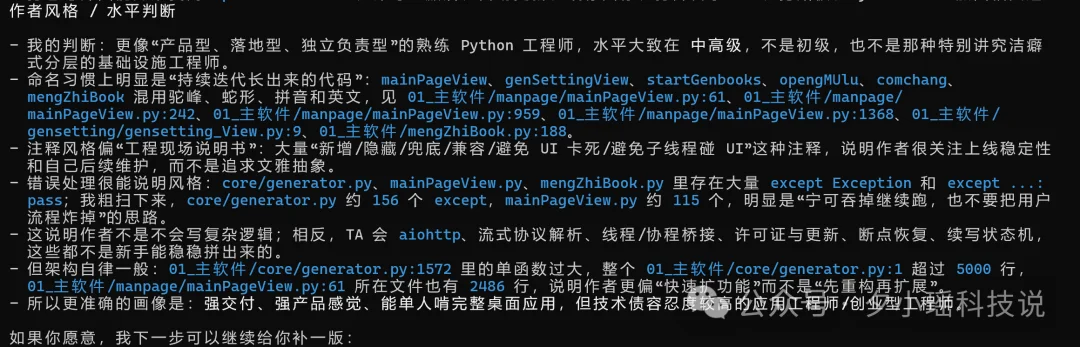
GPT-5.4 看代码,已经不只是“看函数”,而是开始“看人”了。它能顺着代码,反推出作者的工作方式、取舍习惯、甚至一点点性格倾向。
由此判断,代码能力算是稳的,至少算中层。GPT-5.4 的编程能力配合它的知识工作能力用,是加分项。单独拿出来,没赢面。
前两个任务,一个偏知识流程,一个偏工程。
第三个任务,我想看它在“高复杂度、长链条、强约束”的场景里,到底能顶到哪。
所以我直接把它拉去做 2024 年数学建模国赛 C 题,54 个地块,7 年规划,41 种作物,要考虑轮作、土地适应性、市场波动、超产滞销,最后还要形成完整论文。
这个任务也最能暴露它的上限。
因为它不是某一个点上难,而是每一步都容易出小错:读题、抽象、建模、写代码、跑优化、生成论文、处理公式、处理文件、处理中文路径,哪一步都能翻。
GPT-5.4 确实搭了个 PuLP 的混合整数线性规划模型,也确实把论文骨架搭出来了:摘要、问题重述、假设、符号说明、建模、求解、结果分析、模型评价,样样不少。

但中间它被 Windows PowerShell 的中文编码狠狠干了几次。中文文件名读不进去,“完整论文.md”写不进去,“附件 1.xlsx”也找不到,LaTeX 公式里的 \right 还被换行吃掉了。它最后是靠把文件名全改成 ASCII,才把流程跑通。
有意思,真正折磨模型的,还真不是 benchmark 上那道最难的题,是现实环境里那些又脏又碎的坑啊!
所以这一项给我的感觉很明确,GPT-5.4 可以把这种大活先搭到 70 分,甚至能把最烦的前半段干掉;但离“直接交卷拿高分”还有距离,中间隔着一堆细节层面的破事。
你要的是一个能跑起来的框架,它可以。你要的是一篇非常漂亮的竞赛论文,还得自己往上抬,至少要自己教它方法、配个 skill。
跑完这三个任务,我对 GPT-5.4 的判断也慢慢清楚了:代码能力很强、人感不错,但操作计算机的能力好像离预期差一点至少套娃还差一点。
至于 5.4pro,网上已经有人开始拿它开涮了。
比如 Daniel Nguyen 发的那个图就很典型:有人问 GPT-5.4 Pro,“How do I install CUDA 12.1 on Ubuntu 24.04?”
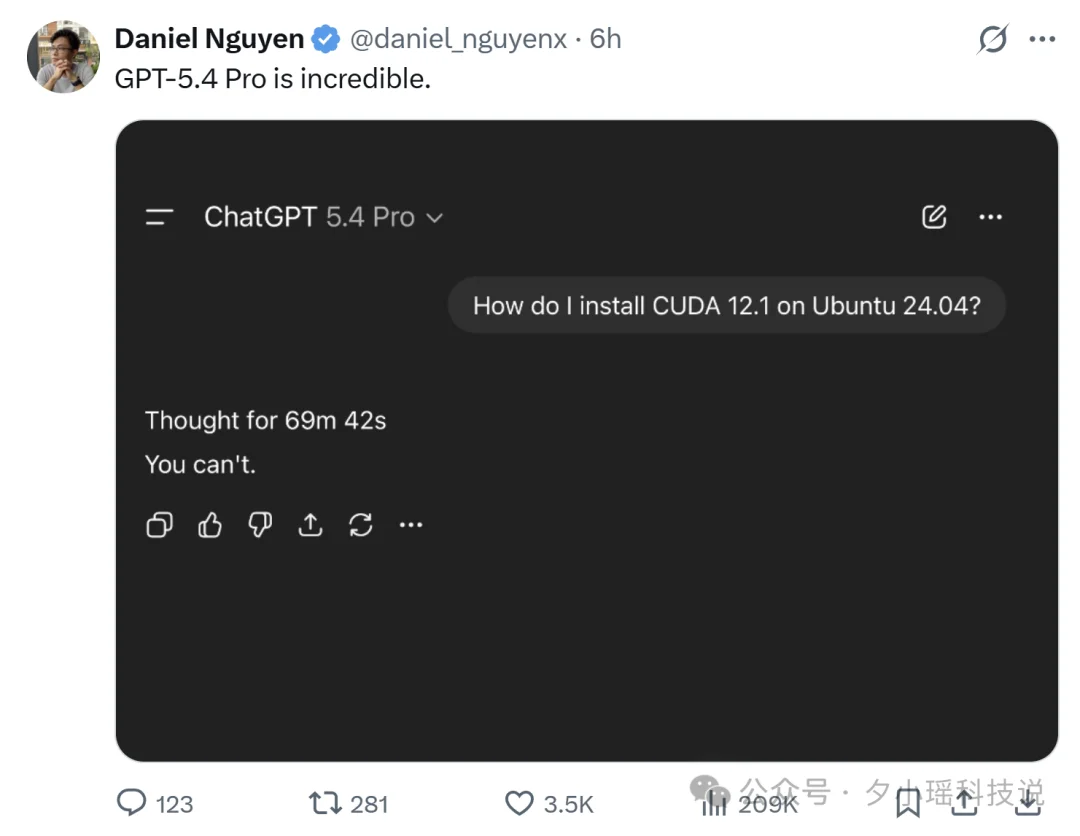
它想了 69 分 42 秒,最后回了一句:“You can’t.”
我自己也测了一下 Pro。让它扮演一个 20 年经验的 AI 行业猎头,对 Sam Altman 进行一场“GPT-5.4 产品经理”岗位的压力面试。
它想了 22 分钟 46 秒。


出来的东西说实话有点压力。这个质量,确实不是普通版能给的。你能明显感觉到,Pro 在一些高要求、高压缩、高质量输出的场景里,确实更像“高级脑力劳动者”。但代价嘛...

Pro 版输出 180 美元/百万 token,是 Claude 的 7.2 倍。之前有人对它说了句"Hi"就烧掉 80 美元,我这次一个面试题想了 22 分钟,账单也不敢细看。
所以问题来了。
如果未来两个季度,你只能让 GPT-5.4 在一个维度形成“不可逆的用户心智占领”,你会押哪一个?
A. 长周期 agent 任务完成率B. 高价值知识工作的“可直接签字”输出率C. 跨文档、跨应用、跨工具的上下文连续性D. 单位任务成本
评论区告诉我答案,我挑几个最狠的回答,整理一下,转达给 GPT-5.4 Pro。
你觉得 GPT5.4 的能力到哪了?
文章来自于“夕小瑶科技说”,作者 “丸美小沐”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
